最佳左前缀法则
最佳左前缀法则: 如果创建的是联合索引,就要遵循该法则. 使用索引时,where后面的条件需要从索引的最左前列开始使用,并且不能跳过索引中的列使用。
最左匹配原则是什么?
简单来讲:在联合索引中,只有左边的字段被用到,右边的才能够被使用到。
左边是带头大哥, 必须在
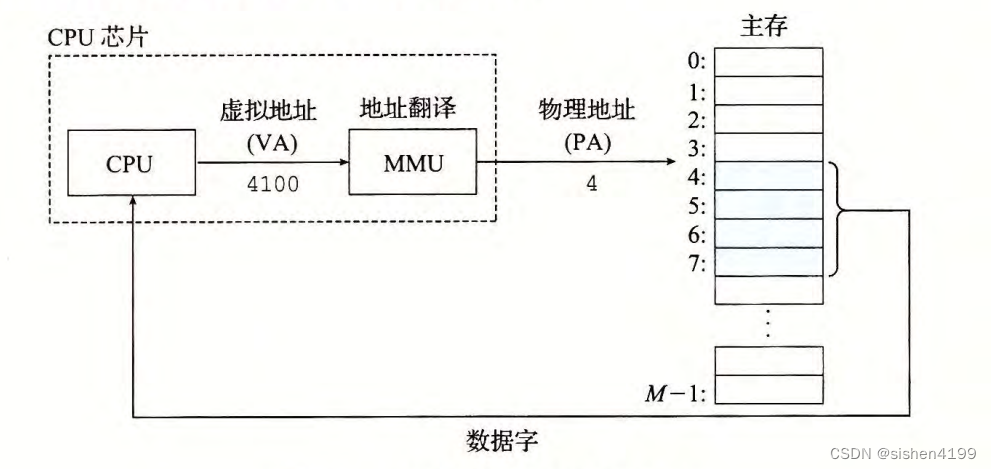
假如我们创建联合索引 create index idx_a_b on shopTable(a,b);
有如下B+树
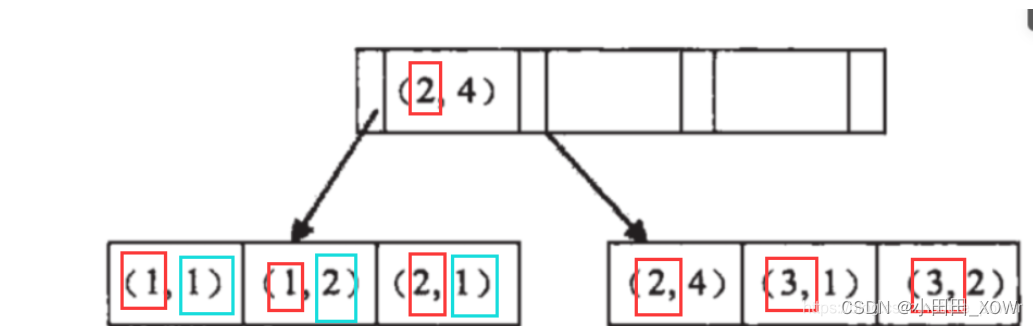
我们看到 最左边的a 都是有序的,分别是 : 1,1,2,2,3,3 但是右边的b 不一定有序: 1,2,1,4,3,2
但是在a都为 1 的情况下 b是有序的, 如: a=1时 b =1,2 ; a=2时, b= 1,4; a=3时 ,b=1,2;
如果我们筛选数据的时候, 直接筛选b ,整个就是无序的,需要做全表扫描
如果先a,再b 那么 ,就可以利用树来加快查找速度。
那么我们就基本可以得出最左匹配原则的定义:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
场景1: 按照索引字段顺序使用,三个字段都使用了索引,没有问题。
EXPLAIN SELECT * FROM users WHERE user_name = 'tom' AND user_age = 17 AND user_level = 'A';
场景2: 直接跳过user_name使用索引字段,索引无效,未使用到索引。
EXPLAIN SELECT * FROM users WHERE user_age = 17 AND user_level = 'A';
场景3: 不按照创建联合索引的顺序,使用索引
EXPLAIN SELECT * FROM users WHERE user_age = 17 AND user_name = 'tom' AND user_level = 'A';
where后面查询条件顺序是 `user_age`、`user_level`、`user_name`与我们创建的索引顺序 `user_name`、`user_age`、`user_level`不一致,为什么还是使用了索引,原因是因为MySql底层优化器对其进行了优化。
最佳左前缀底层原理
MySQL创建联合索引的规则是: 首先会对联合索引最左边的字段进行排序( 例子中是 `user_name` ), 在第一个字段的基础之上 再对第二个字段进行排序 ( 例子中是 `user_age` ) .
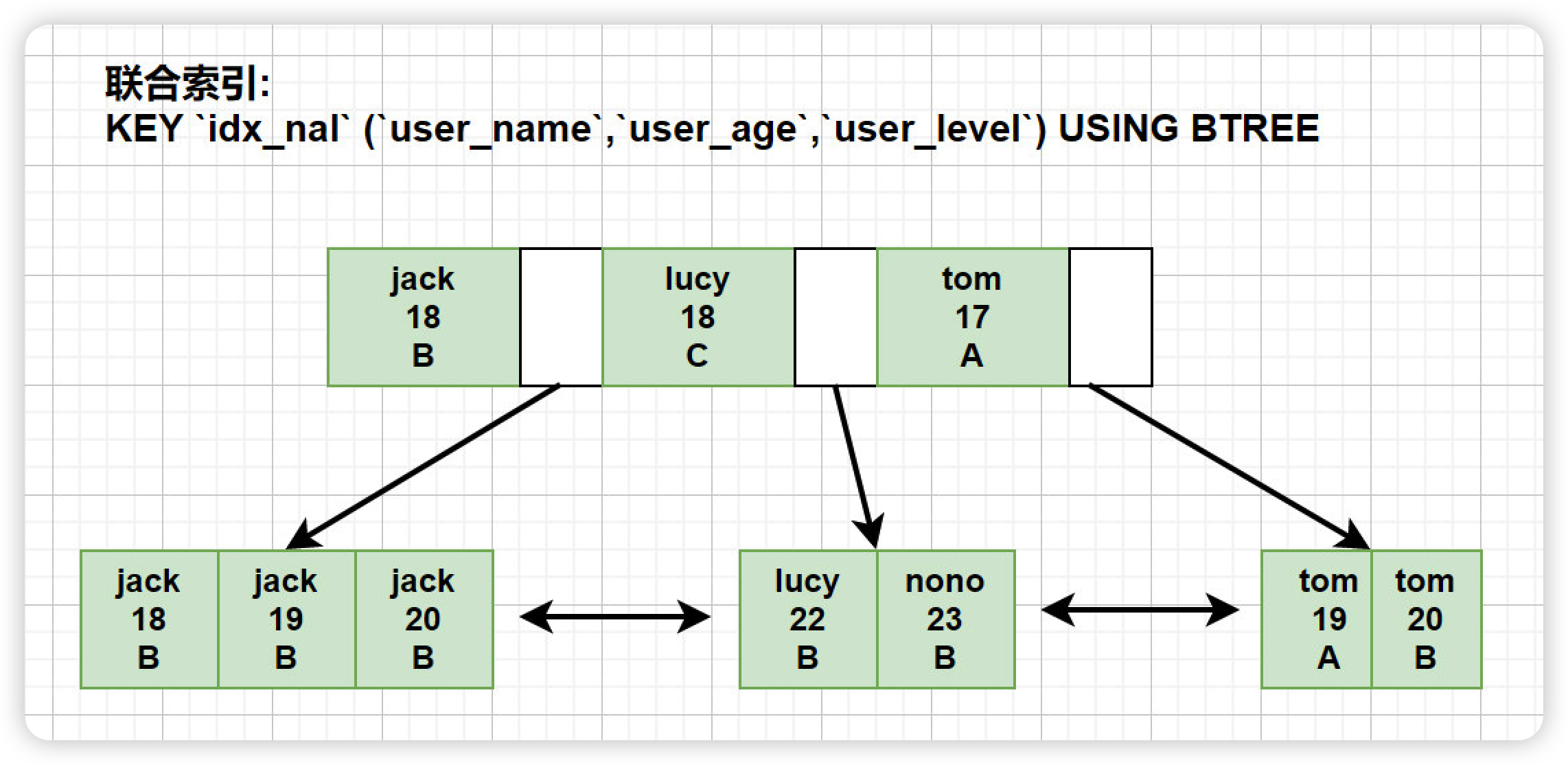
最佳左前缀原则其实是和B+树的结构有关系, 最左字段肯定是有序的, 第二个字段则是无序的(联合索引的排序方式是: 先按照第一个字段进行排序,如果第一个字段相等再根据第二个字段排序). 所以如果直接使用第二个字段 `user_age` 通常是使用不到索引的.
实战分析
首先我们来创建一个数据表tb_score,设置score和age字段组合成一个联合索引,索引的名称是“score_age_index”,在mysql中,int类型占4个字节,所以这个索引的长度是8个字节,这里计算索引的长度是为了判断sql语句是否走了索引
插入一些测试数据
CREATE TABLE tb_student (
`stu_id` int NOT NULL PRIMARYKEY AUTO_INCREMENTCOMMENT'主键id',
`name` VARCHAR(100) NOT NULL COMMENT '姓名',
`score` int NOT NULL COMMENT '成绩',
`age` int NOT NULL COMMENT '年龄',
INDEX score_age_index (`score`,`age`)
) ENGINE = InnoDB DEFAULT CHARSET=utf8;insert into tb_student(name, score, age) value('张三',40,21);
insert into tb_student(name, score, age) value('王五',20,23);
insert into tb_student(name, score, age) value('李四',90,26);
insert into tb_student(name, score, age) value('赵六',60,19);我们在分析查询语句是否走索引可以用到mysql提供的一个命令explain,如下图我们做了一个查询,根据分数查询学生的姓名,可以得出结论,查询走了我们定义的索引,并没有进行全表扫描,下面我们就根据各种情况进行分析。

1.全值匹配
mysql>explain select name from tb_student where age=20 and score=90;

根据结果可以得知,key_len 为8 ,type为ref,本次查询用到了索引,虽然我们定义索引的顺序是(score, age),mysql可以进行优化,自动帮我们改变顺序。
2.匹配左边的列
mysql>explain select name from tb_student where score=90;
上面这条sql语句,都是走索引的,因为他是从最左也就是score开始,连续匹配的。
而下面这条sql语句显然是不会走索引的,因为它并没有从最左连续匹配,这里走的是全表扫描,根据执行结果我们也可以看出,type是ALL代表全表扫描,没有使用到索引。
mysql>explain select name from tb_student where age=19;

3.匹配列前缀
如果列是字符型的话它的比较规则是先比较字符串的第一个字符,第一个字符小的哪个字符串就比较小,如果两个字符串第一个字符相同,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小,依次类推,比较字符串。
如果score是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描了。
mysql>select * from tb_student where name like 'As%'; //前缀都是排好序的,走索引查询
mysql>select * from tb_student where name like'%As'//全表查询
mysql>select * from tb_student where name like'%As%'//全表查询
4.匹配范围值
可以对最左边的列进行范围查询,结果是一定会走索引的。
mysql>explain select name from tb_student where score >60 and score <90;

多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,可以看到key_len为4,也就是只有score用到了索引,在90>score>60的情况下,age是无序的,不能用索引,找到90>score>60的记录后,只能根据条件 age>20 继续逐条过滤.
mysql>explain select name from tb_student where score >60 and score <90 and age >20;

5.精确匹配某一列并范围匹配另一列
如果左边的列是精确查找的,右边的列可以进行范围查找,如果score=90,age是有序的,并且我们可看到key_len是8,说明走的是联合索引。
mysql>explain select name from tb_student where score =90 and age >20;

6.排序
因为b+树索引本身就是按照上述规则排序的,order by的子句后面的顺序也必须按照索引列的顺序给出,就会走索引。
mysql> explain select name from tb_student order by score, age;

这里和我们预想的结果 不太一致,经过一番查证,如果数据库中的数据量过小的时候,mysql数据库会自动为我们做优化,它会认为全表扫描要比索引更快,所以就采用全表扫描方式。
如果我们颠倒顺序去排序,那么肯定不会走索引。
mysql> explain select name from tb_student order by age,score;
如果最左边列的值是定值,则对其他列顺序排序是可以用到索引的。
mysql> explain select name from tb_student where score =60 order by age;
知识来源:马士兵教育
最左匹配原则_the_power的博客-CSDN博客
mysql索引最左匹配原则的理解 - 简书