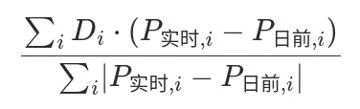目录
1 爬取58二手房信息
1.1 分析
1.2 代码
2 爬取4k图片案例
2.1 分析
2.2 代码
3 爬取城市名称案例
3.1 分析
3.2 代码
4 爬取站长素材简历模板
4.1 分析
4.2 代码
1 爬取58二手房信息
地址 请输入验证码 ws:121.36.42.44
1.1 分析
我需要标题和价格


1.2 代码
爬完了写txt里就行了


2 爬取4k图片案例
地址 4K风景壁纸_高清4K风景图片大全_彼岸图网
2.1 分析

2.2 代码

3 爬取城市名称案例
地址 PM2.5历史数据_空气质量指数历史数据_中国空气质量在线监测分析平台历史数据
3.1 分析

3.2 代码


4 爬取站长素材简历模板
4.1 分析
项目地址 整套简历-整套简历模板下载
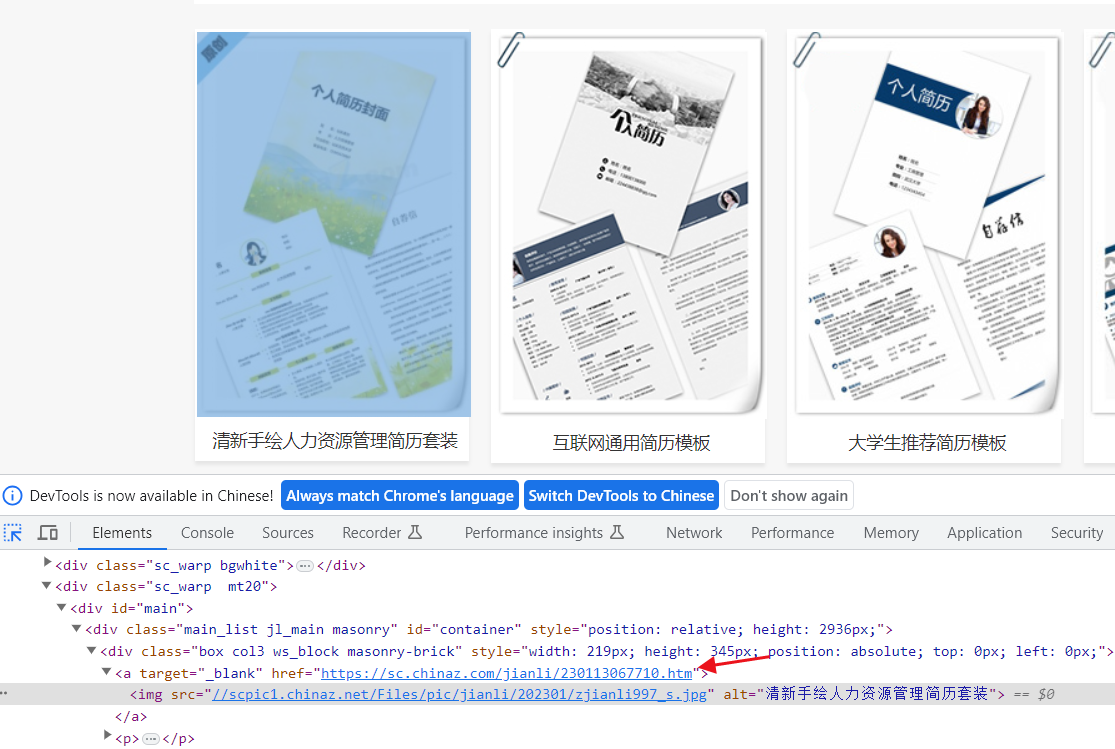
有两种页面,一种是下面这种
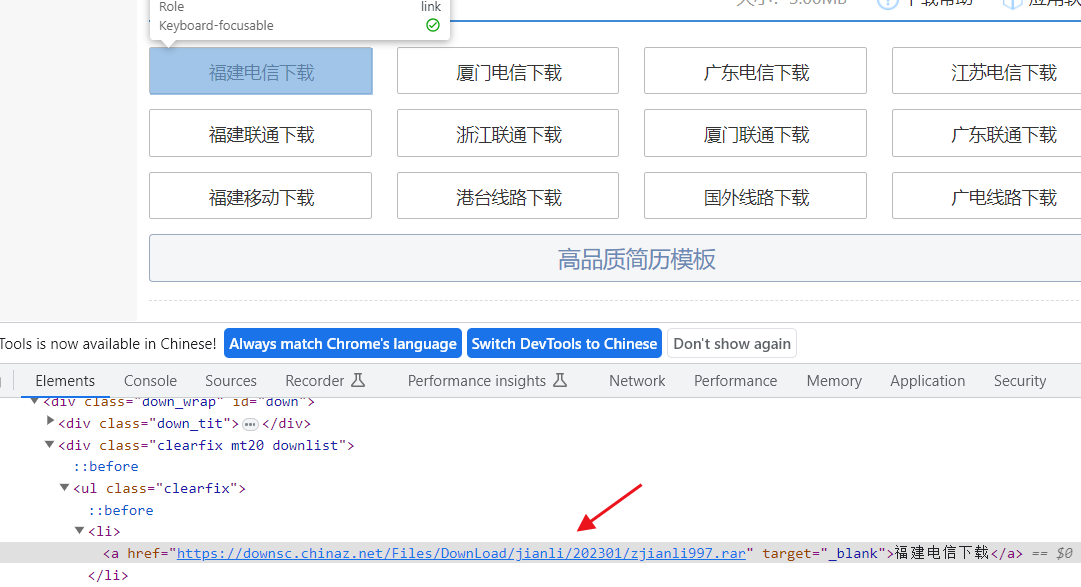
还有一种是这样的
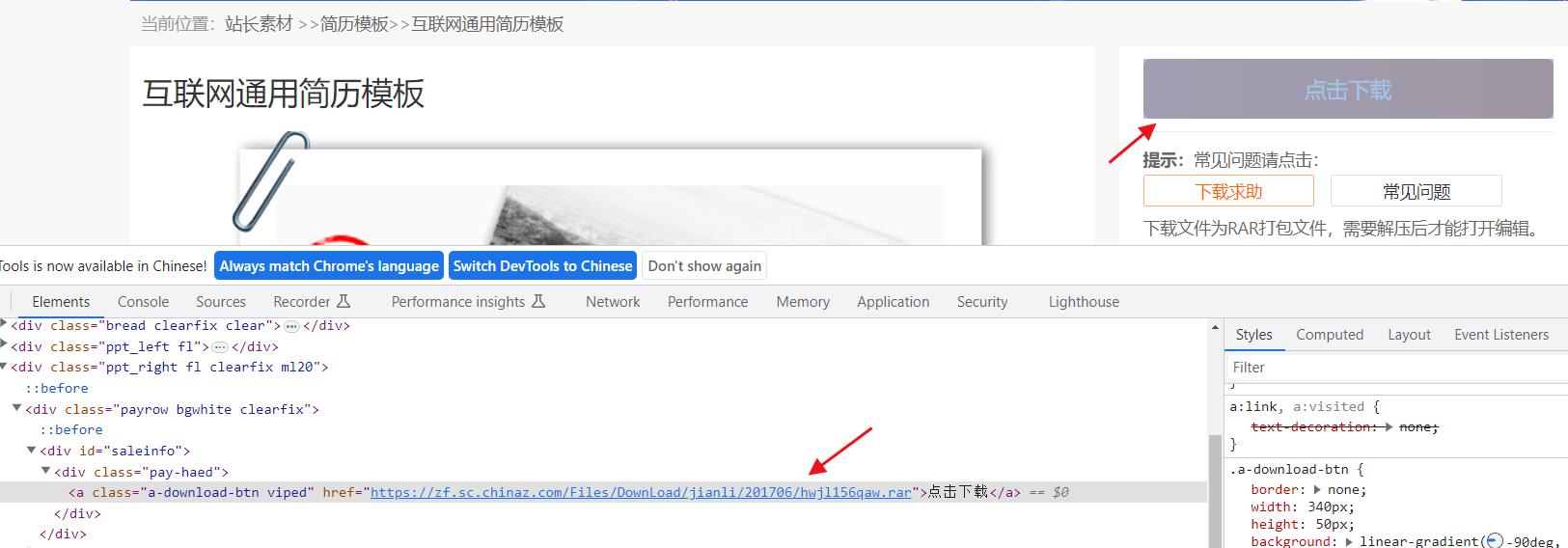
4.2 代码
两种页面需要写两种xpath表达式,然后用 或 连接
import requests
from lxml import etree
url = 'https://sc.chinaz.com/jianli/zhengtao.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
with open('./test.html','w',encoding='utf-8') as f:
f.write(response.text)
print(response)
tree = etree.HTML(response.text)
detail_htmls = tree.xpath('//div[@class="box col3 ws_block"]/a/@href')
for i in detail_htmls:
detail_response = requests.get(url=i, headers=headers)
detail_response.encoding = detail_response.apparent_encoding
with open('./sub_test.html', 'w', encoding='utf-8') as f:
f.write(detail_response.text)
detail_tree = etree.HTML(detail_response.text)
download_address = detail_tree.xpath('//div[@id="down"]/div[@class="clearfix mt20 downlist"]/ul[@class="clearfix"]/li/a/@href | //div[@id="saleinfo"]/div[@class="pay-haed"]/a/@href')[0]
# print(download_address)
print(i + ' 下载中!')
file_name = download_address.split('/')[-1]
download_response = requests.get(url=download_address,headers=headers)
with open('./result/{}'.format(file_name), 'wb') as fp:
fp.write(response.content)
print(i + ' 下载成功!')运行完毕后会得到下面这些压缩包,随便挑了一个解压发现可以解压,并且里面的word可以打开

![心法利器[99] | 无监督字面相似度cqr/ctr源码](https://img-blog.csdnimg.cn/img_convert/ac31582183c5dff390580cd1009f803d.png)