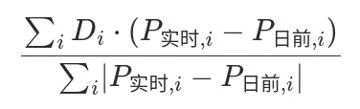心法利器
本栏目主要和大家一起讨论近期自己学习的心得和体会,与大家一起成长。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。
2022年新一版的文章合集已经发布,累计已经60w字了,获取方式看这里:CS的陋室60w字原创算法经验分享-2022版。(2023在路上了!)
往期回顾
心法利器[89] | 实用文本生成中的解码方法
心法利器[90-95] | 谈校招:合集
心法利器[96] | 写了个向量检索的baseline
心法利器[97] | 判断问题是否真的需要大模型来解决
心法利器[98] | 除了训练,大模型还有很多重要工作
很早之前,我曾经分享过一套字面相似度的方案:心法利器[18] | cqr&ctr:文本匹配的破城长矛,这套方案其实在我的日常中是经常被用到的,效果也还凑合,相比于经典的BM25,这种可归一化的计算一定程度缓解了因为长度导致的计算准确性问题,这次我也写了一套代码,方便大家快速使用。
先回顾
快速起见,我直接给出加权的计算方法。
给定query,有对应的权重和title,以及对应权重,现在计算cqr和ctr:
有关词权重的计算,我之前是已经有写文章,给出一个baseline很高的方案,并附带源码了:心法利器[33] | 快速的关键词抽取baseline,这里就不赘述了,当然了,简单起见,其实直接用idf就可以,例如jieba的源码内就有一份用人民日报训练的idf词典数据(idf.txt)。
有关这块的优缺点,为方便大家做方案权衡选择,可以参考下:
首先说优点:
能够体现字面的相似度,在一些领域下体验比较好。
性能耗时比语义相似度模型好很多。
无监督甚至不用训练,词权重的话用语料就可以训练了。
效果稳定可追踪,也方便快速增加一些策略,灵活性高。
准确率其实挺高的。
当然,还是有缺点的。
文本层面的匹配无法体现语义,同义词、统一表达之类的无法体现,导致召回率会比较低。
对切词敏感,类似“充不进去电”和“充电”就完全匹配不上。
这类型的方法,非常适合前期在时间不足时做的baseline,毕竟前期开荒时间上很紧张,各个功能和基础工作需要花很多时间,且数据资源不够,别说训练集了,测试集都很难,此时模型很难做起来。先上cqrctr计算把baseline做好,然后进行深度学习实验,用加权的方式进行融合,然后加入模型中作为特征(在一些场景,尽量还是不要扔掉字面的特征的),整个流程十分顺滑,冷启动速度也比较快。
代码
终于到了代码环节,我这里直接上代码了,正式代码其实也没几行。
import jieba
import numpy as np
class TokenDistance():
def __init__(self, idf_path):
idf_dict = {}
tmp_idx_list = []
with open(idf_path, encoding="utf8") as f:
for line in f:
ll = line.strip().split(" ")
idf_dict[ll[0]] = float(ll[1])
tmp_idx_list.append(float(ll[1]))
self._idf_dict = idf_dict
self._median_idf = np.median(tmp_idx_list)
def predict_jaccard(self, q1, q2):
# jaccard距离,根据idf加权
if len(q1) < 1 or len(q2) < 1:
return 0
q1 = set(list(jieba.cut(q1)))
q2 = set(list(jieba.cut(q2)))
print(q1.intersection(q2))
print(q1.union(q2))
numerator = sum([self._idf_dict.get(word, self._median_idf) for word in q1.intersection(q2)])
denominator = sum([self._idf_dict.get(word, self._median_idf) for word in q1.union(q2)])
return numerator / denominator
def predict_left(self, q1, q2):
# 单向相似度,分母为q1,根据idf加权
if len(q1) < 1 or len(q2) < 1:
return 0
q1 = set(list(jieba.cut(q1)))
q2 = set(list(jieba.cut(q2)))
numerator = sum([self._idf_dict.get(word, self._median_idf) for word in q1.intersection(q2)])
denominator = sum([self._idf_dict.get(word, self._median_idf) for word in q1])
return numerator / denominator
def predict_cqrctr(self, q1, q2):
# cqr*ctr
if len(q1) < 1 or len(q2) < 1:
return 0
cqr = self.predict_left(q1, q2)
ctr = self.predict_left(q2, q1)
return cqr * ctr
if __name__ == "__main__":
import sys
q1 = sys.argv[1]
q2 = sys.argv[2]
token_distance = TokenDistance("./data/idf.txt")
print(q1, q2)
print(token_distance.predict_jaccard(q1, q2))
print(token_distance.predict_left(q1, q2))
print(token_distance.predict_cqrctr(q1, q2))说明:
此处的加权,用的jieba的idf.txt,直接加载成dict就能查了。
对于未登录词,词权重词典里没有的,一般用整个词典的中位数来计算。
这里附上jaccard距离,和ctr、cqr不同的是,他的分母用的是q1和q2的并集,而不只是q1或者q2本身。
因为cqr和ctr本质上只是分母的选择不同,所以我写成一个函数,要把谁做分母,就把谁放q1的位置就行。
cqrctr的计算,其实就是把两者相乘,这个是比较简单的。
后记
真不要小看每一个方法,很多时候这些看起来没什么技术含量的方法,其实会有奇效,而且在现阶段,可能反而是经验的体现,从现在的新人来看,往往对前沿的知识有比较好的了解,然而在实际应用中,会出现很多问题,导致新方法并不那么适合。最近是又重新用起来了这个方案,发现还挺适合,所以记录下来,希望对大家有帮助吧。