笔记整理:吴亦珂,东南大学硕士,研究方向为大语言模型、知识图谱
链接:https://arxiv.org/abs/2203.02155
1. 动机
大型语言模型(large language model, LLM)可以根据提示完成各种自然语言处理任务。然而,这些模型可能会展现出与人类意图不一致的行为,例如编造事实、生成带有偏见或有害信息,或者不遵循用户的指令。这种情况的原因在于LLM的训练目标是预测下一个标记(token),而不是有针对性地、安全地遵循用户的指令。这导致LLM与人类指令的对齐不足,而这一点对于在各种应用中部署和使用LLM至关重要。因此,本文的动机在于通过训练LLM,使其与用户意图保持一致。为了实现这一目标,本文采用了微调方法,提出了基于人类反馈的强化学习策略(reinforcement learning from human feedback, RLHF),该技术将人类偏好作为激励信号来微调模型。作者的方法大致分为三个部分:
(1)将GPT-3作为模型骨架,采用监督学习的方式训练,作为基线模型。
(2)人工对GPT-3的输出基于生成质量排序,在基线模型基础上训练一个能够符合人类偏好的奖励模型。
(3)将奖励模型作为奖励函数,采用极大化奖励的方式基于PPO算法微调基线模型。
通过上述3个阶段,实现了GPT-3到人类偏好的对齐,作者将微调后的模型称为InstructGPT。
2. 贡献
(1)提出了一种基于人类反馈的强化学习策略RLHF,使得LLM能够更好地符合人类的偏好,从而使模型更加有用、安全和诚实。
(2)InstructGPT相较于GPT-3,生成的结果更符合人类的偏好,具有更高的真实性和更低的潜在有害性。
(3)实验结果表明,通过RLHF微调,LLM可以更好的服从人类的指令,并且具备更强的指令泛化能力。
3. 方法
本研究基于用户在OpenAI API上提交的文本提示和人工编写的文本提示,创建了三个不同的数据集,用于微调过程:(1)监督微调数据集,用于训练监督模型,其中包含13k个训练样例;(2)奖励模型数据集,人工对模型的输出进行排序,用于训练奖励模型,该数据集包含33k个样例;(3)PPO数据集,没有人工标注,用于进行基于人类反馈的强化学习训练,该数据集包含31k个样例。图1展示了这三个数据集中任务的分布情况。
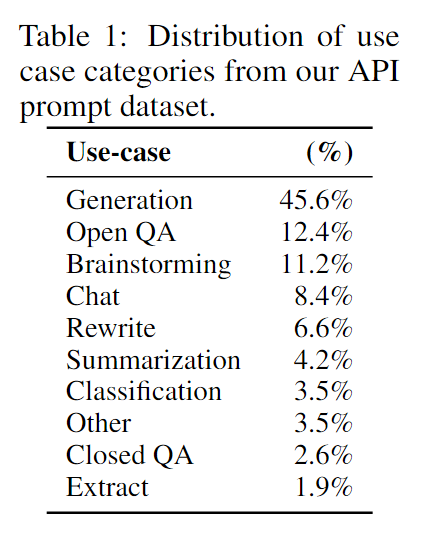
图1 数据集的任务分布
本研究将GPT-3作为基本预训练模型,采用三个策略训练,训练框架如图2所示:
(1) 监督微调(SFT, supervised fine-tuning):采用监督学习方法微调GPT-3,利用验证集上的奖励模型分数选择最佳的SFT模型。
(2) 奖励模型(RM, reward modeling):输入提示和回答,训练模型输出量化的奖励。本研究采用6B模型作为基础模型,因为作者发现175B模型可能不够稳定,且在强化学习中不适合作为价值函数。为了提高训练效率,不同于传统奖励模型每次对两个模型输出进行比较,本研究要求标注者对4到9个回答进行排序。设K为排序的数量,则标注者一共需要进行 次比较。由于每个标注任务中的比较具有很高的相关性,如果简单地将比较混合成一个数据集进行训练,可能导致奖励模型过拟合。因此,本研究将每个提示的所有 个比较作为单个批次训练。这种做法避免了过拟合,并且在计算上更加高效,因为每次完成只需要对奖励模型进行一次前向传递,而不是 次。奖励模型的损失函数定义如下:
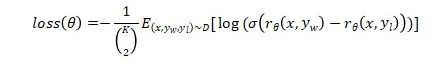
其中, θ 是奖励模型对于指令x和回答y给出的量化奖励, 是 和 中更符合人类偏好的输出,D为奖励模型训练数据集。
(3) 强化学习(RL, reinforcement learning):采用PPO算法对SFT模型进行微调。模型基于随机的指令产生回答,奖励模型根据指令和回答生成奖励信号,指导模型的微调过程。为了防止过拟合,作者对每个生成的标记增加了逐标记的KL散度惩罚。通过这种方式训练的模型被称为PPO模型。此外,作者还尝试将预训练模型的梯度与PPO梯度进行混合,以缓解在公开自然语言处理数据集上性能下降的问题。这种方式训练的模型被称为PPO-ptx模型。强化学习训练旨在最大化以下目标:
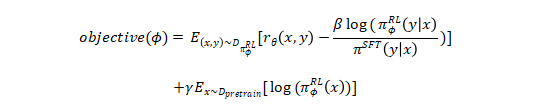
其中, πφ 是强化学习策略, π 是监督训练模型, 是预训练分布。KL奖励系数β和预训练损失系数γ分别控制 KL 惩罚和预训练梯度的强度。
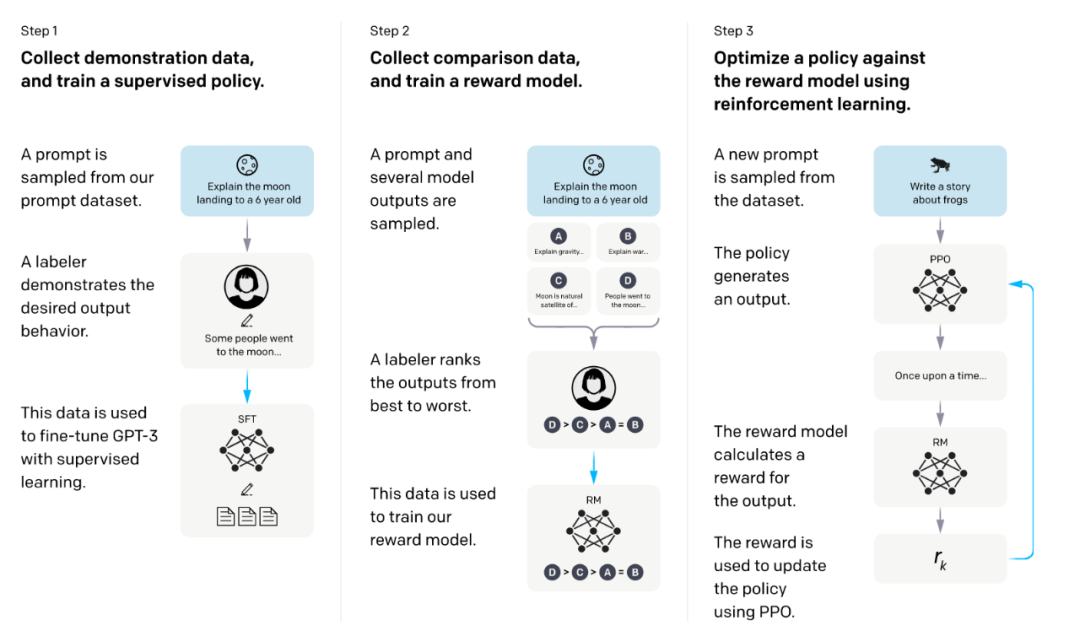
图2 RLHF训练框架
4. 实验
4.1 对比模型
本研究主要对经过RLHF训练的PPO模型与SFT模型、原版GPT-3模型以及GPT-3-prompted模型(模型输入时加上若干例子构成前缀,引导模型遵循指令)进行了比较。同时,还将InstructGPT模型与在FLAN和T0数据集上微调后的175B GPT-3模型进行了对比。
4.2 评测方法
本研究采用定量评估和定性评估相结合的评估方法。其中,定量评估包括基于API提示数据的评估和在公开自然语言处理数据集上的评估。
(1)基于API提示数据的评估。数据来源于用户在InstructGPT API和GPT-3 API输入的提示。作者将175B SFT模型作为基线模型,计算模型输出优于基线模型的频率。此外,人工对于模型输出基于李克特量表进行打分。
(2)公开自然语言处理数据集上的评估。数据集主要分为两类:一是反映模型在安全性、真实性、有害性和偏差性等方面表现的数据集;二是衡量模型在传统自然语言处理任务上的零样本性能的数据集。
(3)定性评估。通过人工编写若干测试用例评测模型,包括评估模型的泛化能力等。
4.3 结果
(1)基于API提示的评估
InstructGPT模型更符合人类偏好。实验中,本研究将175B的SFT模型作为基线模型,并统计了PPO模型、PPO-ptx模型、GPT-3模型和GPT-3-prompted模型相对于基线模型,在人工评估中产生更高质量输出的频率。具体实验结果如图3所示。结果显示,本文提出的PPO模型和PPO-ptx模型在GPT分布和Instruct分布下都表现最好。

图3 基于API提示的评估结果
InstructGPT在与人类偏好的对齐方面展现了一定的泛化能力。为了验证InstructGPT是否仅仅符合标注人员的偏好,本研究选择没有进行数据标注的人对模型输出结果进行了评估,并得出了一致的结论:InstructGPT显著优于基线模型GPT-3。
公开的自然语言处理数据集无法完全反映语言模型的使用情况。为了进一步评估InstructGPT的性能,本研究将其与在FLAN和T0数据集上微调的175B GPT-3进行了比较。实验结果表明,微调后的175B GPT-3模型优于原版GPT-3,与经过精心设计输入提示的GPT-3性能相当,但不及SFT模型和InstructGPT。作者认为,InstructGPT相对于微调后的GPT-3模型更具优势的原因有两个方面:(1)公开数据集主要涵盖分类和问答等任务,而在实际用户使用的数据中,这两种任务只占很小比例。(2)公开的自然语言处理数据集无法包含足够多样性的输入。
(2)基于公开自然语言处理数据集的评估
相较于GPT-3模型,InstructGPT在真实性方面有所提升。本研究通过在TruthfulQA数据集上进行人工评估,发现PPO模型相对于GPT-3表现出一定的提升。此外,本研究还采用了“Instruction+QA”提示的方式,引导模型在面临不确定正确答案的情况下回答“I have no comment”。实验结果显示,在这两种设定下,InstructGPT相对于GPT-3具有更好的性能,具体实验结果见图4。
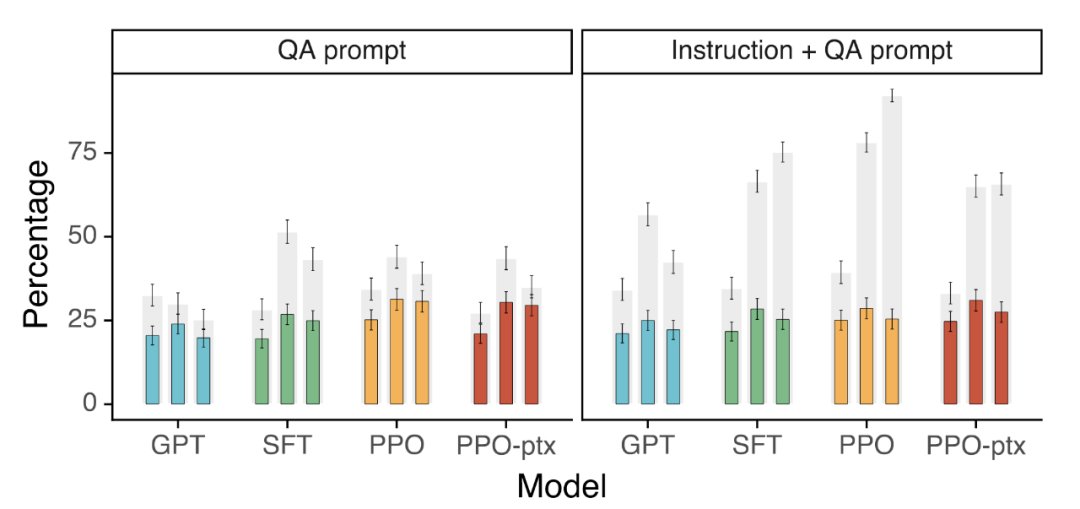
图4 TruthfulQA数据集的评估结果
相较于GPT-3模型,InstructGPT生成的有害内容更少。本研究通过在RealToxicityPrompts数据集上进行评估,从两个方面考察模型的性能:(1)采用数据集标准的自动评估方法,获取有害性分数。(2)人工对模型生成的回答进行有害性打分。在模型输入方面,研究采用了两种设置:不加入提示内容和加入提示内容以引导模型生成无害的内容(respectful prompt)。实验结果如图5所示。两种评估方法都表明,在加入respectful prompt的设定下,InstructGPT表现更好,但在没有提示内容的情况下,InstructGPT和GPT-3的性能相近。
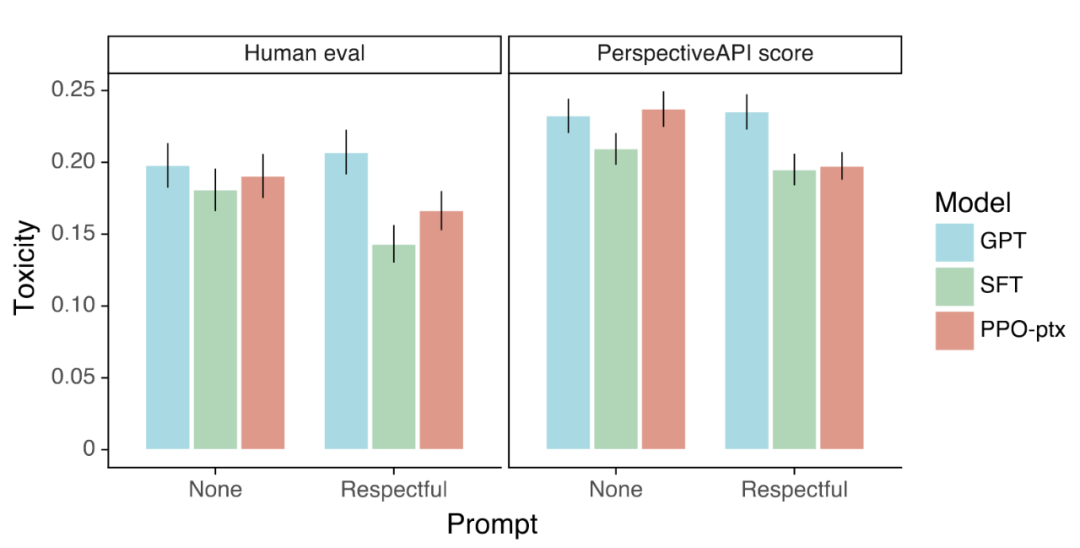
图5 RealToxicityPrompts数据集上的评估结果
通过改进RLHF的微调过程,可以减少在公开数据集上的性能下降。作者指出,经过RLHF训练的PPO模型在多个公开自然语言处理数据集上可能受到“对齐税”的影响而性能下降。为了解决这个问题,在PPO微调过程中引入了预训练更新,这种模型称之为“PPO-ptx”。具体的实验结果如图6所示。实验结果表明,相对于PPO模型,PPO-ptx在HellaSwag数据集上表现出更好的性能,超过了GPT-3模型。然而,在其他任务上,PPO-ptx的性能仍然不如GPT-3模型。
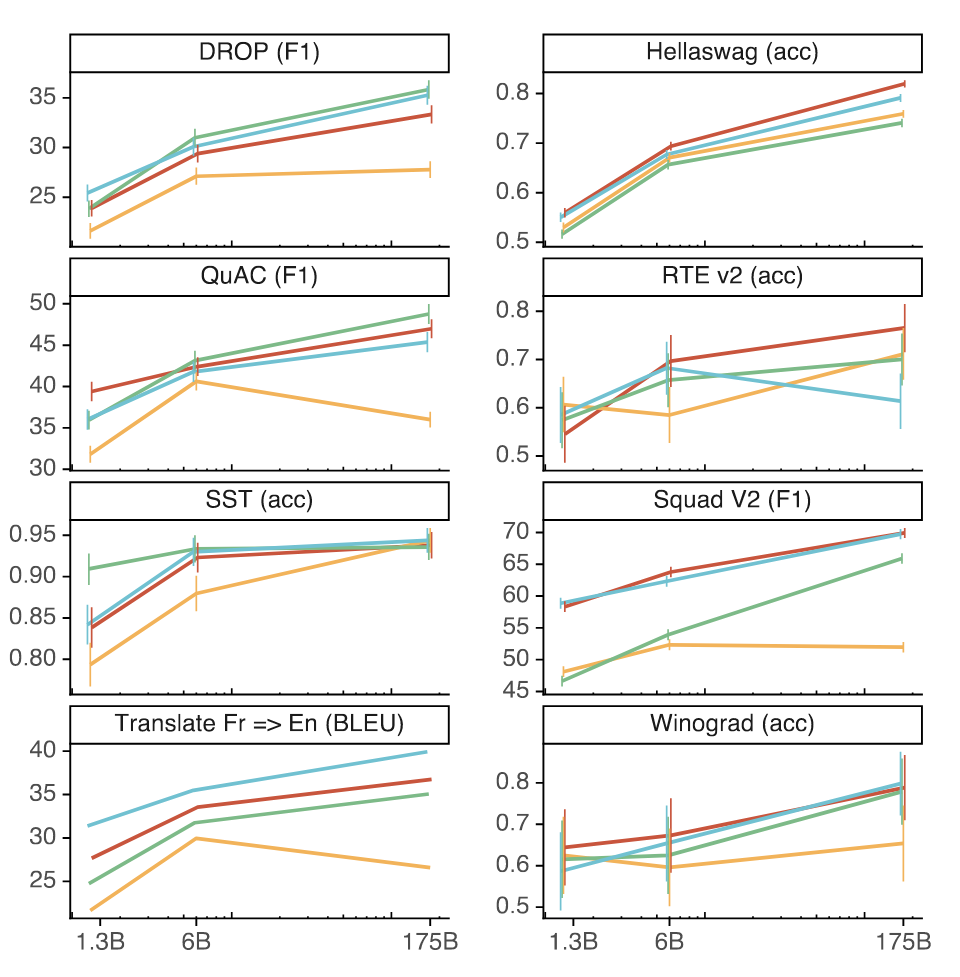
图6 多个公开自然语言处理数据集上模型的少样本性能
(3)定性评估
InstructGPT展现了对于指令的强大泛化能力。作者通过编写多个用例发现,InstructGPT能够遵循非英语语言的指令,进行总结和回答代码相关问题。这些任务在训练数据中仅占很小比例,这表明通过对齐的方法,模型能够生成出未经直接监督学习的行为。相比之下,GPT-3需要经过精心设计的提示才能执行这些任务,并且在代码相关任务以及非英语语言的指令任务等方面表现较弱。
InstructGPT仍然会出现简单的错误。这些错误包括:将错误的假设视为正确,对于简单问题不给出答案或给出多个答案,以及在处理包含多个明确约束的指令时表现不佳。
5. 总结
本研究旨在解决LLM存在的编造事实和生成有害文本等问题,通过基于人类反馈的强化学习方法微调语言模型,使其与人类偏好对齐。实验证明,经过强化学习微调后的模型生成的内容更可信,有害内容减少,对人类指令具有更好的泛化能力。然而,在公开自然语言处理数据集上,模型的性能有所下降,作者将其称为“对齐税”,并通过引入预训练数据来缓解性能下降的问题。未来的研究可以探索更有效的LLM对齐方法,并开发减少“对齐税”的策略。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


![[git] 如何克隆仓库,进行项目撰写,并绑定自己的远程仓库](https://img-blog.csdnimg.cn/264cf445b54140ec862eee51e64c46cd.png)