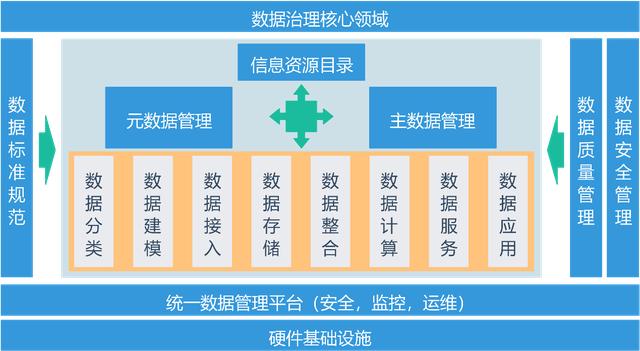
文章目录
- 引言
- 该算法能做什么
- 直观上
- 研究上
- 意义上
- 精妙之处
- 定位特点
- 弱监督学习特点
- 作者简介
- CAM算法原理
- 具体计算方法
- 巧妙之处
- 讨论
- 全卷积神经网络
- 池化简介
- 池化的作用
- 全局平均池化
- CAM总结
- SqueezeNet
- 显著性分析的意义
- 例1:工艺改进
- 例2:识别鸟
- 例3:围棋
- 扩展阅读
- 可视化工具
- CAM算法介绍
- 使用范围
- 思考题
- 总结
引言
-
CAM类激活热力图︰深度学习可解释性分析、显著性分析 经典之作
-
Learning Deep Features for Discriminative Localization, CVPR2016
-
该课程由B站同济子豪兄主讲
-
课程链接:https://www.bilibili.com/video/BV1Ke411g7gm/?vd_source=2c3e1c3086544e2bbc96712d9fb90632
该算法能做什么
直观上
利用摄像头实时交互
-
右图:显示当前拍摄到的场景
-
左上角:深度学习预测的类别
-
左图:图像对应的热力图 -> 实时分析网络每 10 秒关注图像中的哪些区域

上图实战:torch-cam工具包:CAM热力图
研究上
- 作为一个重要的创新点
- 不再只是训练了一个图像分类模型而已,可以查看训练出来的分类模型的热力图的效果
意义上
-
奠定了可解释性分析、显著性分析的基石
-
后续衍生出了若干基于CAM的算法,如下图
-
让图像分类不再是一个黑箱子
在以前,往网络输入图像,然后黑箱子给我们输出预测结果,没人知道
- 它内部的决策分布具体长什么样
- 也根本不清楚他内部的脑回路
- 它到底是怎么做出分类决策的
- 它到底学习到了哪些特征
- 是不是符合人类的常识
- 它什么时候会work?
- 什么时候不work?
- 他到底有没有过拟合?
- 该如何进一步的去改进他?
故通过CAM热力图,可以分析它和人的直觉是不是一致的,它是不是靠谱的。

精妙之处

定位特点
同一张图像的不同类别可以产生不同的CAM热力图
根据类别的不同,网络的关注点也不同
注意,此时该神经网络是一个图像分类模型,他本应该只会干分类的事情,但是现在他有了在图像上找目标、找区域、定位、画热力图这样的能力。(潜在的注意力机制,分析出神经网络对图像上的哪部分感兴趣)

弱监督学习特点
用图像分类的数据及图像分类的标签数据训练出了图像分类模型,该图像分类模型不光可以分类,还可以用来定位
以下图为例
-
孔洞 -> 福建土楼
-
水面上枝质的木干 -> 吊脚楼

飞檐斗拱 -> 北京故宫

尖塔和穹顶 -> 拜占庭建筑

作者简介
-
周博磊是汤晓鸥的学生
- 汤晓鸥是商汤的创始人。
- 在香港中文大学汤晓鸥成立了MMLab多媒体实验室。
- 很多大佬啊,比如说何凯明、周博磊都是MMLab的学生
-
周柏磊现在在UCLA(University of California, Los Angeles加利福尼亚大学洛杉矶分校)当老师
-
周博磊先是在上海交大读了本科,又去香港中文,然后写这篇论文的时候是在MIT写的,现在在UCLA当老师。

周博磊b站强化学习纲要

CAM算法原理
预备知识

下图是CAM论文的核心插图
一个普通的图像分类模型,输入一张原始图像,经过若干个卷积层,最后一个卷积层输出若干个feature map。
举例:
比如说输出512个feature map,每一个feature map被称为一个channel,就是一个矩阵,每一个矩阵都是14 x14的,就是有14行14列的一个矩阵。
-
蓝、红、绿色薄片是一个channel,有14x14个元素是一个矩阵,
-
总共有512个薄片 -> 对应了卷积神经网络最后一层提取出来的512种特征 -> 每一个特征体现在每一个对应的薄片上
-
把蓝色channel取一个平均值,把这14×14=196个激活值取一个平均值,得到蓝色的标量
-
同理,512个channel / 矩阵 / feature map,共得到512个标量 / 平均数,成为全局平均池化
512个平均数会起到全连接层的作用,后面再接一层线性分类层,训练得到它对每一个类别的平均数的权重,再进行softmax操作,得到每个类别的概率
每一个概率都是0 - 1之间的,并且这每个概率求和为 1 -> 得到完整的图像分类预测结果,top 5就是图像分类的预测结果

具体计算方法
-
上图中的权重 w 1 w_1 w1是该类别对蓝色平均值(蓝色圈圈)的一个关注程度
- 蓝色平均值是由蓝色矩阵 / 蓝色channel / 蓝色feature map / 蓝色薄片计算得到的
-
权重 w 1 w_1 w1 间接的反映了该类别对蓝色feature map的关注程度
- feature map是卷积神经网络最后一层从图像中提取出来的某一种特征
-
权重 w 1 w_1 w1 间接的反映了该类别对这种特征的关注程度
又因为feature map这个14 x 14的矩阵,其实是包含一些位置信息的。
举例:图上的狗在图像的右下角,那么在矩阵的右下角,如果该特征很重要,对应了狗身上的特征,那么它右下角的激活值也会很大
- 所以蓝色矩阵既保留了语义信息,又保留了位置信息
- 而权重体现了该类别对这个矩阵的关注程度
把 w 1 w_1 w1 × 蓝色矩阵 + w 2 w_2 w2 x 红色矩阵 + …… + w n w_n wn × 绿色矩阵 -> CAM热力图
巧妙之处
全局平均池化(Global Average Pooling,GAP),把每一个channel变成了一个平均数,用该平均数的权重能间接反映出该类别对所属channel的影响程度
该权重啊,从 w 1 w_1 w1到 w n w_n wn,最后一个卷积层是14 x 14的channel得到的CAM热力图,故也是14 x 14的低分辨率的矩阵。
可以用双线性插值的方法把它缩放回原图大小(类似于word和ppt里的图像缩放),变成一个高分辨率的热力图。

讨论
全卷积神经网络
无池化
池化简介

池化是把大的feature map变成小的feature map,有称为下采样
上图:3 × 3 的池化窗口
- 最大尺化:每个窗口,只挑出最大的值,作为该池化窗口里9个数的代表。
- 平均尺化:挑出平均值叫
一般使用最大尺化

池化不需要学习任何参数的
池化的作用
-
减少计算量
大的feature map变成了小的feature map,输给下一卷积层的的数据变少,自然计算量就小了
-
防止过拟合
大的图变成一个小的图,但是核心信息仍然保留在小图上,大而化之的防止过拟合。
-
平移不变性
如下图:一个人的脸偏右,一个人的脸偏左,假如一个识别眼睛特征的卷积核,它产生的feature map是眼睛区域的,那么有两块是高亮的,剩下的是低值的,眼睛不管在右还是左,得到的输出是一模一样的,这正是池化的引入使得卷积神经网络,对输入的位置不敏感,产生了平移不变性。
卷积神经网络就是要在变化的输入中找到不变的东西,那在平移不变性这个领域,就是由池化来实现的
缺点:平易不变性的引入也意味着丢失了空间信息。

池化(下采样)引入了平移不变性,也意味着丢失了长宽方向的位置信息。因此在CAM热力图中,不使用带池化的卷积神经网络。
全局平均池化
薄片/channel -> 平均数的过程(多图预警)




GAP这个操作,可以取代全连接层
- 在传统卷积神经网络里面,最后一层卷积层产生了若干个channel,需要把每一个channel展平成一个长向量,再把这个长向量输入给全连接层,这种操作太消耗计算量、也太消耗参数量了,参数量会爆炸,比如说在VGG中,共有100003500万个参数。第一层卷积层就消耗了1亿多个参数,网络总共才1315755692万个参数,这是非常不经济的。
- 用全局平均池化取代全连接层能大大减少参数量,以前需要512 x 14 x 14个元素,现在只要512个元素就可以了

这个操作最早是在NIN network这篇论文里面,
这是一篇伟大的论文,它里面提出了两个操作,一个叫1x1卷积,一个叫全局平均池化。一直沿用到今天,很多算法都在使用

CAM总结
- 全局平均池化(GAP)取代全连接层
- 减少参数量、防止过拟合
- 每个GAP平均值,间接代表了卷积层最后一层输出的每个channel
- CAM算法中,必须有GAP层
- 无法计算每个channel的权重
- 如果没有GAP层,需把全连接层替换为GAP,再重新训练模型
- CAM算法的缺点
- 必须得有GAP层,否则得修改模型结构后重新训练
- 只能分析最后一层卷积层输出,无法分析中间层
SqueezeNet
- 轻量化卷积神经网络
- SqueezeNet的分类层是最后一个卷积层,输出1000个channel/薄片片,对应着1000个类别的CAM图(直接对应了类别数)
- 对每一个channel做GAP,global average pooling,得到了该类别的logit,1000个channel变成了1000个平均值,再直接进行softmax就得到了1000个类别的softmax置信度。
优点:
- 一步到位,不需要再过一个线性分类层,直接GAP得到的值就是GAP分数,对于SqueezeNet而言,这个channel就是CAM热力图,只需要一次前项运算,取出最后一层卷积层对应的每一个类别的channel,就直接获得了每一个类别的CAM热力图。
- 用squeeze的速度很快,它本身是轻量化网络,而且它不需要进行加权求和的操作,直接一步到位的从网络输出中获取某一个类别的CAM热力图。

显著性分析的意义
从machine learning到machine teaching
例1:工艺改进
知乎上的一篇文章:德国的一家激光加工企业的博士,他做了一个卷积神经网络预测工艺参数的数据集,训练出了一个远超人类水平的ai,对该ai做可解释性分析和显著性分析。他发现ai学到的特征,反过来可以指导普通的工人去改进工艺的参数,ai展示出它通过大量的数据学习到的特征、它在图像上关注的区域
- 哪些特征、哪些区域是ai重点关注的区域?
- 对某一个类别特别重要,影响特别大的区域是哪里?

例2:识别鸟
machine teaching教普通人去识别鸟的一个工作
一个细粒度的图像识别,因为各种鸟,都是鸟,很难学,很难判别他们的差异,都是两个翅膀、一个尾巴、一个喙、两个眼睛。有鸟类专家先标注一些权威的鸟类图像分类数据集,用它去训练一个ai,图像分类模型把它用大量数据学习到的特征以注意力图的形式显示在原图上,如右边第三行第二个,ai更关注他的喙、脑袋还有尾巴,正是这些区域使得ai预测出它是一个加利福尼亚的一个海鸥到码头整点薯条。
不光是鸟类,各种的植物、动物、甲虫、蘑菇,大自然的万事万物都可以通过这种方法让ai去教我们去识别。

例3:围棋
同理,AlphaGo下围棋,它远超人类水平,可以战胜人类最顶尖的职业棋手,反过来,AlphaGo也可以向我们展示它下棋的思路,这些思路可能是非常复杂、高深的。机器学习、强化学习,通过几亿轮的迭代次数学习到的特征。这是一个普通的职业棋手可能一辈子都达不到的境界,那他把这个思路展现给普通下围棋的人,是不是能够帮我们提升棋艺呢?
但是我们再怎么提升棋艺,也干不过AlphaGo了。
看到过一篇文章说AlphaGo使得围棋这项运动本身的意义受到了怀疑、受到了挑战,人工智能让很多事情变得没有意义了。一个职业棋手苦心钻研围棋几十年,像达摩组师一样,闭关修行之后发现一辈子修行的结果是下不过AlphaGo,那么他就变成了一个可笑的行为艺术,本来是受人尊敬的禅修现在变成了一个可笑的loser。
所以。不懂ai技术的人,会觉得ai特别厉害,但是实际上,我们打开ai的黑箱子,赋予它可解释性和显著性,让它展示到它学习到的特征,看看关注的区域是不是和我们人是一致的,这样我们才能改进他、了解他、信赖他,甚至把生命托付给他,

扩展阅读

可视化工具
CAM算法介绍
https://mp.weixin.qq.com/s/lOR3OQTkr1nu3ERBawZ1kw
使用范围
- transformer的模型
- 基于卷基神经网络CNN的模型
- 自然源处理的模型
- 强化学习的模型
思考题
值得思考的一些问题

总结
学习CAM算法的基本原理,了解其来源以及使用范围,非常期待未来它的代码实战练习