MySQL性能优化
- 1、SQL语句及索引优化
- 1.1 EXPLAIN查看索引使用情况
- 1.2 SQL语句中IN包含的值不应过多
- 1.3 SELECT语句务必指明字段名称
- 1.4 当只需要一条数据的时候,使用limit 1,limit 是可以停止全表扫描的
- 1.5 排序字段加索引
- 1.6 如果限制条件中其他字段没有索引,尽量少用or
- 1.7 尽量用union all代替union
- 1.8 不使用ORDER BY RAND(),ORDER BY RAND() 不走索引
- 1.9 区分in和exists、not in和not exists
- 1.10 使用合理的分页方式以提高分页的效率
- 1.11 分段查询
- 1.12 不建议使用%前缀模糊查询
- 1.13 避免在where子句中对字段进行表达式操作
- 1.14 避免隐式类型转换
- 1.15 对于联合索引来说,要遵守最左前缀法则
- 1.16 必要时可以使用force index来强制查询走某个索引
- 1.17 注意范围查询语句
- 1.18 使用JOIN优化
- 2、表结构设计优化
- 2.1 设计中间表
- 2.2 设计冗余字段
- 2.3 拆表
- 2.4 主键优化
- 2.5 字段的设计
- 3、系统配置优化
- 3.1 保证从内存中读取数据
- 3.2 数据预热
- 3.3 降低磁盘写入次数
- 3..4 提高磁盘读写性能,使用SSD或者内存磁盘
数据库优化维度有四个:
硬件升级、 系统配置、 表结构设计、 SQL语句及索引
优化选择:
优化成本:硬件升级>系统配置>表结构设计>SQL语句及索引。
优化效果:硬件升级<系统配置<表结构设计<SQL语句及索引。
1、SQL语句及索引优化
1.1 EXPLAIN查看索引使用情况
使用【慢查询日志】功能,去获取所有查询时间比较长的SQL语句 3秒-5秒
使用explain查看有问题的SQL的执行计划,重点查看索引使用情况

type列,连接类型。一个好的SQL语句至少要达到range级别。杜绝出现all级别。
ikey列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式。
key_len列,索引长度。
rows列,扫描行数。该值是个预估值。
filtered列,通过查询条件获取的最终记录行数占通过type字段指明的搜索方式搜索出来的记录行数的百分比。
extra列,详细说明。注意,常见的不太友好的值,如下:Using filesort,Using temporary 。
常见的索引:
where 字段 、组合索引 (最左前缀) 、 索引下推 (非选择行不加锁) 、
覆盖索引(不回表)on 两边、排序 、分组统计
1.2 SQL语句中IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序
的。但是如果数值较多,产生的消耗也是比较大的。
1.3 SELECT语句务必指明字段名称
SELECT * 增加很多不必要的消耗(CPU、IO、内存、网络带宽);减少了使用覆盖索引的可能性;当
表结构发生改变时,前端也需要更新。所以要求直接在select后面接上字段名。
1.4 当只需要一条数据的时候,使用limit 1,limit 是可以停止全表扫描的
1.5 排序字段加索引
1.6 如果限制条件中其他字段没有索引,尽量少用or
or两边的字段中,如果有一个不是索引字段,会造成该查询不走索引的情况。
1.7 尽量用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,
增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
1.8 不使用ORDER BY RAND(),ORDER BY RAND() 不走索引
1.9 区分in和exists、not in和not exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为
驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合
于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。如何高
效的写出一个替代not exists的SQL语句?
1.10 使用合理的分页方式以提高分页的效率
分页使用 limit m,n 尽量让m 小
利用主键的定位,可以减小m的值
1.11 分段查询
一些用户选择页面中,可能一些用户选择的范围过大,造成查询缓慢。主要的原因是扫描行数过多。这
个时候可以通过程序,分段进行查询,循环遍历,将结果合并处理进行展示。
1.12 不建议使用%前缀模糊查询
例如LIKE“%name”或者LIKE“%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE
“name%”。
那么如何解决这个问题呢,答案:使用全文索引或ES全文检索
1.13 避免在where子句中对字段进行表达式操作
1.14 避免隐式类型转换
where子句中出现column字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定
where中的参数类型。 where age=‘18’
1.15 对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段id、name、school,可以直接用id字段,也可以id、name这样的顺序,但是
name;school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询
字段放在最前面。
1.16 必要时可以使用force index来强制查询走某个索引
有的时候MySQL优化器采取它认为合适的索引来检索SQL语句,但是可能它所采用的索引并不是我们想
要的。这时就可以采用forceindex来强制优化器使用我们制定的索引。
1.17 注意范围查询语句
对于联合索引来说,如果存在范围查询,比如between、>、<等条件时,会造成后面的索引字段失效。
1.18 使用JOIN优化
A LEFT JOIN B:A表为驱动表,
INNER JOIN :MySQL会自动找出那个数据少的表作用驱动表,
A RIGHT JOIN B: B 表为驱动表。
所以尽量使用inner join,利用小表去驱动大表:
2、表结构设计优化
2.1 设计中间表
设计中间表,一般针对于统计分析功能,或者实时性不高的需求(OLTP、OLAP)
2.2 设计冗余字段
为减少关联查询,创建合理的冗余字段(创建冗余字段还需要注意数据一致性问题)
2.3 拆表
对于字段太多的大表,考虑拆表(比如一个表有100多个字段)
对于表中经常不被使用的字段或者存储数据比较多的字段,考虑拆表
2.4 主键优化
每张表建议都要有一个主键(主键索引),而且主键类型最好是int类型,建议自增主键(不考虑分布
式系统的情况下 雪花算法)。
2.5 字段的设计
数据库中的表越小,在它上面执行的查询也就会越快。
因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
尽量把字段设置为NOTNULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,
ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我
们又可以提高数据库的性能。
3、系统配置优化
3.1 保证从内存中读取数据
MySQL会在内存中保存一定的数据,通过LRU算法将不常访问的数据保存在硬盘文件中。
尽可能的扩大内存中的数据量,将数据保存在内存中,从内存中读取数据,可以提升MySQL性能。
扩大innodb_buffer_pool_size,能够全然从内存中读取数据。最大限度降低磁盘操作。
确定innodb_buffer_pool_size 足够大的方法:
show global status like 'innodb_buffer_pool_pages_%';
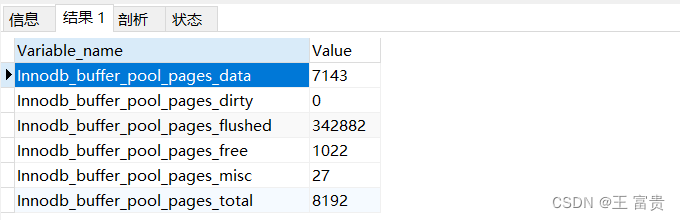
innodb_buffer_pool_size默认为128M,理论上可以扩大到内存的3/4或4/5。
修改 my.cnf
innodb_buffer_pool_size = 750M
如果是专用的MySQL Server可以禁用SWAP
#查看swap
cat /proc/swaps
Filename Type Size Used Priority
/dev/sda2 partition 1048572 0 -1
#关闭所有交换设备和文件.
swapoff -a
3.2 数据预热
默认情况,仅仅有某条数据被读取一次,才会缓存在 innodb_buffer_pool。
所以,数据库刚刚启动,须要进行数据预热,将磁盘上的全部数据缓存到内存中。
数据预热能够提高读取速度。
对于InnoDB数据库,进行数据预热的脚本是
SELECT DISTINCT
CONCAT('SELECT ',ndxcollist,' FROM ',db,'.',tb,
' ORDER BY ',ndxcollist,';') SelectQueryToLoadCache
FROM
(
SELECT
engine,table_schema db,table_name tb,
index_name,GROUP_CONCAT(column_name ORDER BY seq_in_index)
ndxcollist
FROM
(
SELECT
B.engine,A.table_schema,A.table_name,
A.index_name,A.column_name,A.seq_in_index
FROM
information_schema.statistics A INNER JOIN
(
SELECT engine,table_schema,table_name
FROM information_schema.tables WHERE
engine='InnoDB'
) B USING (table_schema,table_name)
WHERE B.table_schema NOT IN ('information_schema','mysql')
ORDER BY table_schema,table_name,index_name,seq_in_index
) A
GROUP BY table_schema,table_name,index_name
) AA
ORDER BY db,tb;
将该脚本保存为:loadtomem.sql
在需要数据预热时,执行命令
mysql -uroot -proot -AN < /root/loadtomem.sql > /root/loadtomem.sql
3.3 降低磁盘写入次数
- 增大redolog,减少落盘次数
innodb_log_file_size 设置为 0.25 * innodb_buffer_pool_size - 通用查询日志、慢查询日志可以不开 ,bin-log开
生产中不开通用查询日志,遇到性能问题开慢查询日志 - 写redolog策略 innodb_flush_log_at_trx_commit设置为0或2
如果不涉及非常高的安全性 (金融系统),或者基础架构足够安全,或者事务都非常小,都能够用 0
或者 2 来减少磁盘操作。








![[oeasy]python0030_设置路径_export_PATH_zsh_系统路径设置_export](https://img-blog.csdnimg.cn/img_convert/53db58b58f96aabb1fe328a6cee39a83.png)