目录
一、高可用(HA)的背景知识
1.1 单点故障
1.2 如何解决单点故障
1.2.1 主备集群
1.2.2 Active、Standby
1.2.3 高可用
1.2.4 集群可用性评判标准(x 个 9)
1.3 HA 系统设计核心问题
1.3.1 脑裂问题
1.3.2 数据状态同步问题
二、NAMENODE 单点故障问题
2.1 概述
2.2 解决
三、HDFS HA 解决方案--QJM
3.1 QJM—主备切换、脑裂问题解决
3.1.1 ZKFailoverController(zkfc)
3.1.2 Fencing(隔离)机制
3.2 主备数据状态同步问题解决
四、HDFS HA 集群搭建
4.1 HA 集群规划
4.2 集群基础环境准备
4.3 修改 Hadoop 配置文件
4.3.1 hadoop-env.sh
4.3.2 core-site.xml
4.3.3 hdfs-site.xml
4.4 集群同步安装包
4.5 HA 集群初始化
4.6 HA 集群启动
五、HDFS HA 集群演示
5.1 Web 页面查看两个 NameNode 状态
5.2 HA 集群下正常操作
5.3 模拟故障出现
5.3.1 HA 自动切换失败--错误解决
一、高可用(HA)的背景知识
1.1 单点故障
单点故障(英语:single point of failure,缩写 SPOF)是指系统中某一点一旦失效,就会让整个系统无法运作,换句话说,单点故障即会整体故障。
1.2 如何解决单点故障
1.2.1 主备集群
解决单点故障,实现系统服务高可用的核心并不是让故障永不发生,而是让故障的发生对业务的影响降到最小。因为软硬件故障是难以避免的问题。
当下企业中成熟的做法就是给单点故障设置备份,形成主备架构。通俗描述就是当主挂掉,备份顶上,短暂的中断之后继续提供服务。
常见的是一主一备架构,当然也可以一主多备。备份越多,容错能力越强,与此同时,冗余也越大,浪费资源。

1.2.2 Active、Standby
- Active:主角色。活跃的角色,代表正在对外提供服务的角色服务。任意时间有且只有一个 active 对外提供服务。
- Standby:备份角色。需要和主角色保持数据、状态同步,并且时刻准备切换成主角色(当主角色挂掉或者出现故障时),对外提供服务,保持服务的可用性。
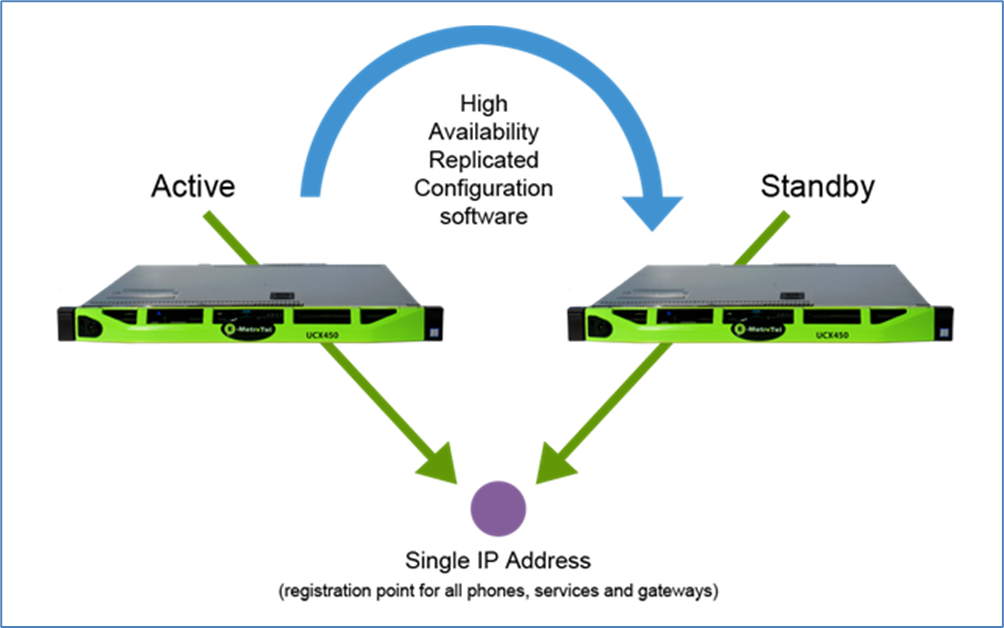
1.2.3 高可用
高可用性(英语:high availability,缩写为 HA),IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统意味着系统服务可以更长时间运行,通常通过提高系统的容错能力来实现。
高可用性或者高可靠度的系统不会希望有单点故障造成整体故障的情形。一般可以通过冗余的方式增加多个相同机能的部件,只要这些部件没有同时失效,系统(或至少部分系统)仍可运作,这会让可靠度提高。

1.2.4 集群可用性评判标准(x 个 9)
在系统的高可用性里有个衡量其可靠性的标准——X 个 9,这个 X 是代表数字 3-5。X 个 9 表示在系统 1 年时间的使用过程中,系统可以正常使用时间与总时间(1 年)之比。
- 3个9:(1-99.9%)*365*24=8.76小时,表示该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
- 4个9:(1-99.99%)*365*24=0.876小时=52.6分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
- 5个9:(1-99.999%)*365*24*60=5.26分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。
可以看出,9 越多,系统的可靠性越强,能够容忍的业务中断时间越少,但是要付出的成本更高。
1.3 HA 系统设计核心问题
1.3.1 脑裂问题
脑裂(split-brain)是指“大脑分裂”,本是医学名词。在HA集群中,脑裂指的是当联系主备节点的"心跳线"断开时(即两个节点断开联系时),本来为一个整体、动作协调的 HA 系统,就分裂成为两个独立的节点。由于相互失去了联系,主备节点之间像"裂脑人"一样,使得整个集群处于混乱状态。
脑裂的严重后果:
-
集群无主:都认为对方是状态好的,自己是备份角色,后果是无服务;
-
集群多主:都认为对方是故障的,自己是主角色。相互争抢共享资源,结果会导致系统混乱,数据损坏。此外对于客户端访问也是一头雾水,找谁呢?
避免脑裂问题的核心是:保持任意时刻系统有且只有一个主角色提供服务。
1.3.2 数据状态同步问题
主备切换保证服务持续可用性的前提是主备节点之间的状态、数据是一致的,或者说准一致的。如果说备用的节点和主节点之间的数据差距过大,即使完成了主备切换的动作,那也是没有意义的。
数据同步常见做法是:通过日志重演操作记录。主角色正常提供服务,发生的事务性操作通过日志记录,备用角色读取日志重演操作。
二、NAMENODE 单点故障问题
2.1 概述
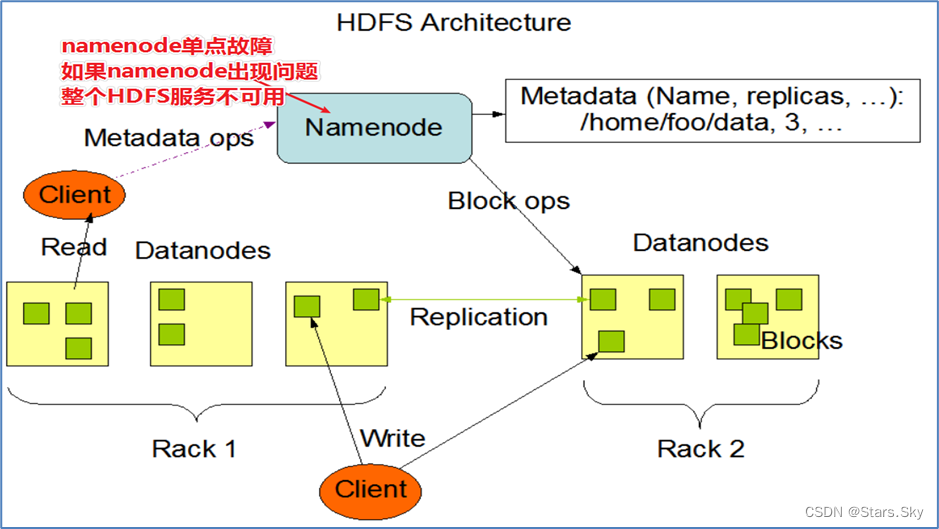
在 Hadoop 2.0.0 之前,NameNode 是 HDFS 集群中的单点故障(SPOF)。每个群集只有一个 NameNode,如果 NameNode 进程不可用,则整个 HDFS 群集不可用。
NameNode 的单点故障从两个方面影响了 HDFS 群集的总可用性:
- 如果发生意外事件(例如机器崩溃),则在重新启动 NameNode 之前,群集将不可用。
- 计划内的维护事件,例如 NameNode 计算机上的软件或硬件升级,将导致群集停机时间的延长。
2.2 解决
在同一群集中运行两个(从 3.0.0 起,支持超过两个)冗余 NameNode。形成主备架构。这样可以在机器崩溃的情况下快速故障转移到新的 NameNode,或者出于计划维护的目的由管理员发起的正常故障转移。
三、HDFS HA 解决方案--QJM
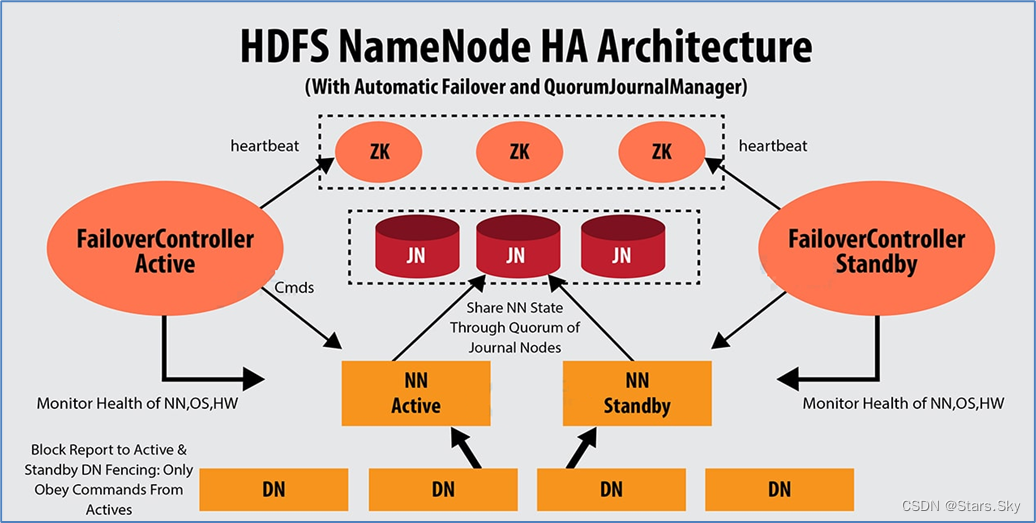
QJM 全称 Quorum Journal Manager(仲裁日志管理器),是 Hadoop 官方推荐的 HDFS HA 解决方案之一。
使用 zookeeper 中 ZKFC 来实现主备切换;使用 Journal Node(JN)集群实现 edits log 的共享以达到数据同步的目的。
3.1 QJM—主备切换、脑裂问题解决
3.1.1 ZKFailoverController(zkfc)
Apache ZooKeeper 是一款高可用分布式协调服务软件,用于维护少量的协调数据。Zookeeper 的下列特性功能参与了 HDFS 的 HA 解决方案中:
- 临时 znode
如果一个 znode 节点是临时的,那么该 znode 的生命周期将和创建它的客户端的 session 绑定。客户端断开连接 session 结束,znode 将会被自动删除。
- Path路径唯一性
zookeeper 中维持了一份类似目录树的数据结构。每个节点称之为 Znode。Znode 具有唯一性,不会重名。也可以理解为排他性。
- 监听机制
客户端可以针对 znode 上发生的事件设置监听,当事件发生触发条件,zk 服务会把事件通知给设置监听的客户端。
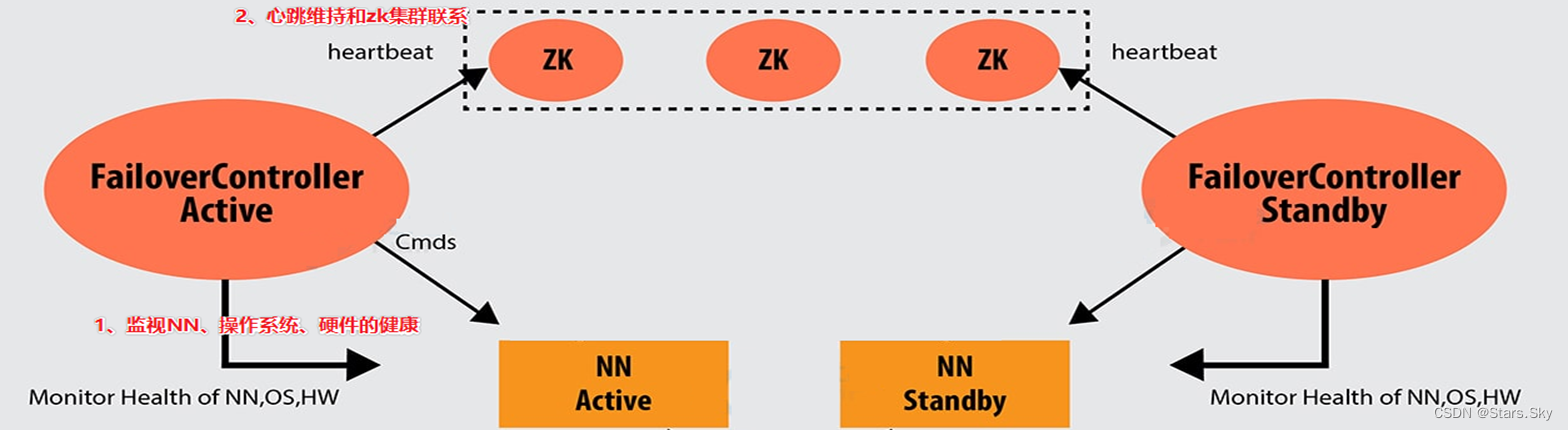
ZKFailoverController(ZKFC)是一个新组件,它是一个 ZooKeeper 客户端。运行 NameNode 的每台计算机也都运行 ZKFC,ZKFC 的主要职责:
- 监视和管理 NameNode 健康状态
ZKFC通过命令监视的 NameNode 节点及机器的健康状态。

- 维持和 ZK 集群联系
如果本地 NameNode 运行状况良好,并且 ZKFC 看到当前没有其他节点持有锁 znode,它将自己尝试获取该锁。如果成功,则表明它“赢得了选举”,并负责运行故障转移以使其本地NameNode 处于 Active 状态。如果已经有其他节点持有锁,zkfc 选举失败,则会对该节点注册监听,等待下次继续选举。
3.1.2 Fencing(隔离)机制
故障转移过程也就是俗称的主备角色切换的过程,切换过程中最怕的就是脑裂的发生。因此需要 Fencing 机制来避免,将先前的 Active 节点隔离,然后将 Standby 转换为 Active 状态。
Hadoop 公共库中对外提供了两种 Fenching 实现,分别是 sshfence 和 shellfence(缺省实现)。
-
sshfence 是指通过 ssh 登陆目标节点上,使用命令 fuser 将进程杀死(通过 tcp 端口号定位进程 pid,该方法比 jps 命令更准确);
-
shellfence 是指执行一个用户事先定义的 shell 命令(脚本)完成隔离。
3.2 主备数据状态同步问题解决
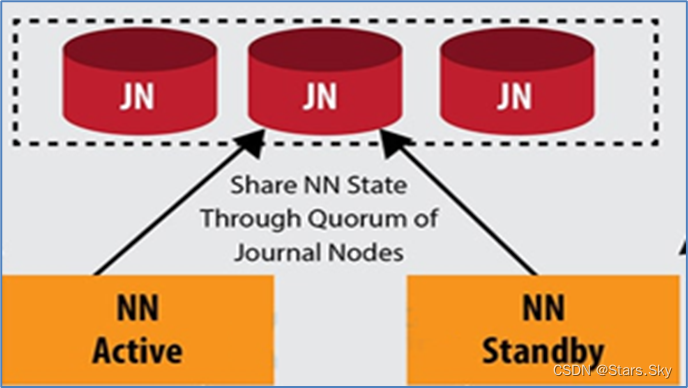
Journal Node(JN)集群是轻量级分布式系统,主要用于高速读写数据、存储数据。通常使用 2N+1 台 JournalNode 存储共享 Edits Log(编辑日志)。底层类似于 zk 的分布式一致性算法。
任何修改操作在 Active NN 上执行时,JournalNode 进程同时也会记录 edits log 到至少半数以上的 JN 中,这时 Standby NN 监测到 JN 里面的同步 log 发生变化了会读取 JN 里面的 edits log,然后重演操作记录同步到自己的目录镜像树里面。
当发生故障 Active NN 挂掉后,Standby NN 会在它成为 Active NN 前,读取所有的 JN 里面的修改日志,这样就能高可靠的保证与挂掉的 NN 的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
四、HDFS HA 集群搭建
4.1 HA 集群规划
| IP | 机器 | 运行角色 |
| 192.168.170.136 | hadoop01 | namenode zkfc datanode zookeeper journal node |
| 192.168.170.137 | hadoop02 | namenode zkfc datanode zookeeper journal node |
| 192.168.170.138 | hadoop03 | datanode zookeeper journal node |
4.2 集群基础环境准备
-
修改 Linux 主机名 /etc/hostname
-
修改 IP /etc/sysconfig/network-scripts/ifcfg-ens33
-
修改主机名和IP的映射关系 /etc/hosts
-
关闭防火墙
-
ssh 免登陆
-
安装 JDK,配置环境变量等 /etc/profile
-
集群时间同步
-
配置主备 NN 之间的互相免密登录
具体步骤参考这篇文章:Hadoop 3.2.4 集群搭建详细图文教程_Stars.Sky的博客-CSDN博客
注意:下面我会在这篇文章中搭建的 Hadoop 集群的基础上进行修改操作,只把有改动的地方写出来,其他未改动的地方则跟原来的一样。
4.3 修改 Hadoop 配置文件
4.3.1 hadoop-env.sh
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hadoop-env.sh
# 配置JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_381
# 设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root4.3.2 core-site.xml
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim core-site.xml
<configuration>
<!-- HA 集群名称,该值要和 hdfs-site.xml 中的配置保持一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- hadoop 本地数据存储目录 format 时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/data/tmp</value>
</property>
<!-- 在 Web UI 访问 HDFS 使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- ZooKeeper 集群的地址和端口-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
4.3.3 hdfs-site.xml
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hdfs-site.xml
<configuration>
<!--指定 hdfs 的 nameservice 为 mycluster,需要和 core-site.xml 中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster 下面有两个 NameNode,分别是 nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<!-- nn1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop01:9870</value>
</property>
<!-- nn2 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<!-- nn2 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop02:9870</value>
</property>
<!-- 指定 NameNode 的 edits 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/data/journaldata</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定该集群出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- 开启短路本地读取功能 -->
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<!-- 需手动创建目录 mkdir -p /var/lib/hadoop-hdfs -->
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>
<!-- 开启黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/excludes</value>
</property>
</configuration>
4.4 集群同步安装包
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp -r hadoop-env.sh root@hadoop02:$PWD
hadoop-env.sh 100% 16KB 6.9MB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp -r hadoop-env.sh root@hadoop03:$PWD
hadoop-env.sh 100% 16KB 991.1KB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp -r core-site.xml root@hadoop02:$PWD
core-site.xml 100% 1404 507.9KB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp -r core-site.xml root@hadoop03:$PWD
core-site.xml 100% 1404 386.9KB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp -r hdfs-site.xml root@hadoop02:$PWD
hdfs-site.xml 100% 3256 1.1MB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp -r hdfs-site.xml root@hadoop03:$PWD
hdfs-site.xml 100% 3256 2.4MB/s 00:004.5 HA 集群初始化
安装好 zookeeper 集群:【Zookeeper 初级】02、Zookeeper 集群部署_Stars.Sky的博客-CSDN博客
#1. 首先启动 zookeeper 集群
[root@hadoop01 /bigdata/hadoop/zookeeper]# zk.sh start
#2. 手动启动 JN 集群(3台机器)
hdfs --daemon start journalnode
#3. 在 hadoop01 执行格式化 namenode 并启动 namenode
[root@hadoop01 ~]# hdfs namenode -format
[root@hadoop01 ~]# hdfs --daemon start namenode
#4. 在 hadoop02 上进行 namenode 元数据同步
[root@hadoop02 ~]# hdfs namenode -bootstrapStandby
#5. 格式化 zkfc。注意:在哪台机器上执行,哪台机器就将成为第一次的 Active NN
[root@hadoop01 ~]# hdfs zkfc -formatZK4.6 HA 集群启动
在 hadoop01 上启动 HDFS 集群:
[root@hadoop01 ~]# start-dfs.sh
[root@hadoop01 ~]# jps
6355 QuorumPeerMain
6516 JournalNode
7573 DataNode
7989 DFSZKFailoverController
8040 Jps
7132 NameNode
[root@hadoop02 ~]# jps
4688 JournalNode
5201 NameNode
5521 Jps
5282 DataNode
4536 QuorumPeerMain
5482 DFSZKFailoverController
[root@hadoop03 ~]# jps
4384 DataNode
3990 QuorumPeerMain
4136 JournalNode
4511 Jp五、HDFS HA 集群演示
5.1 Web 页面查看两个 NameNode 状态
在 hadoop01 上,显示 namenode 是 active 状态:
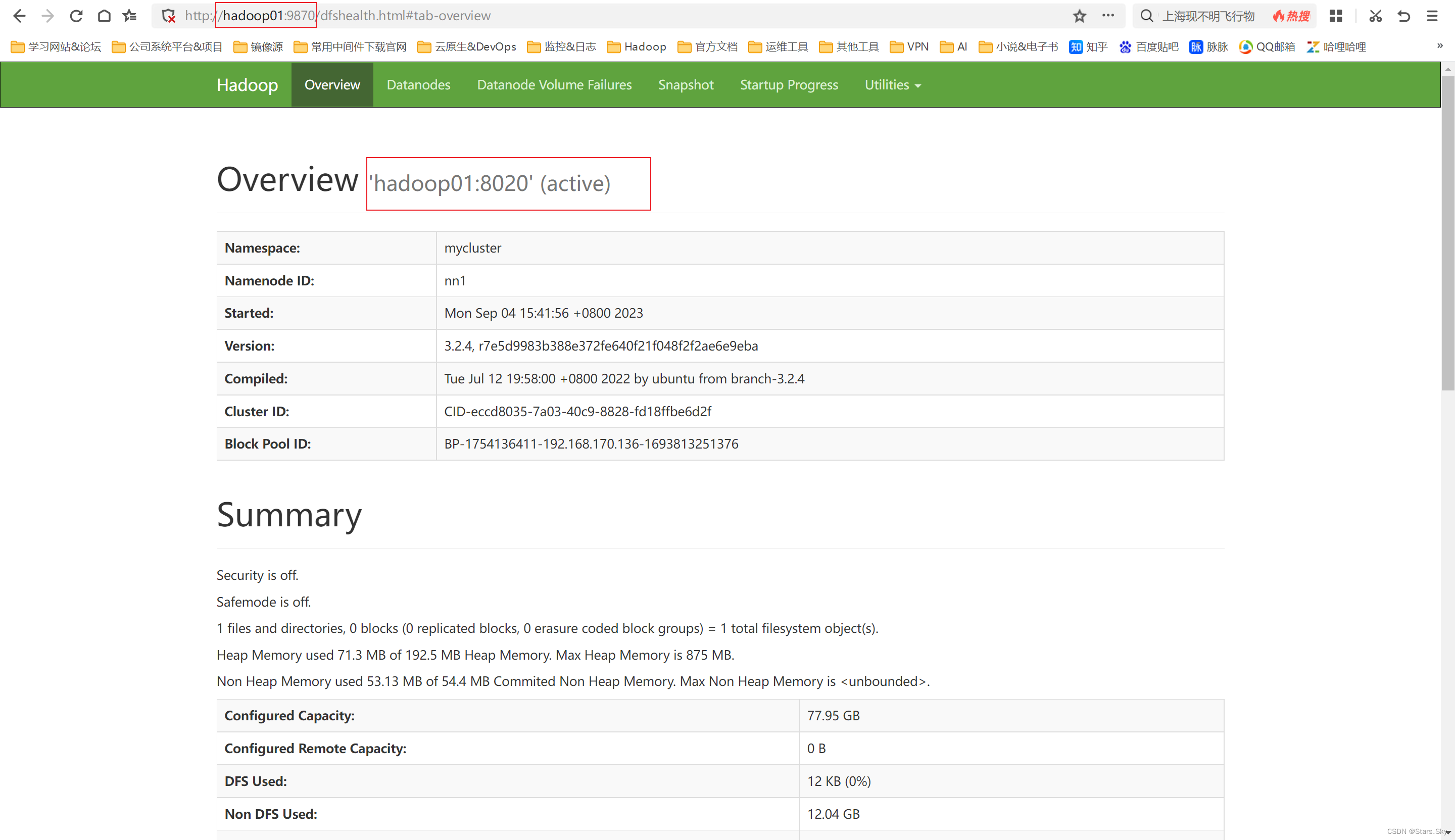
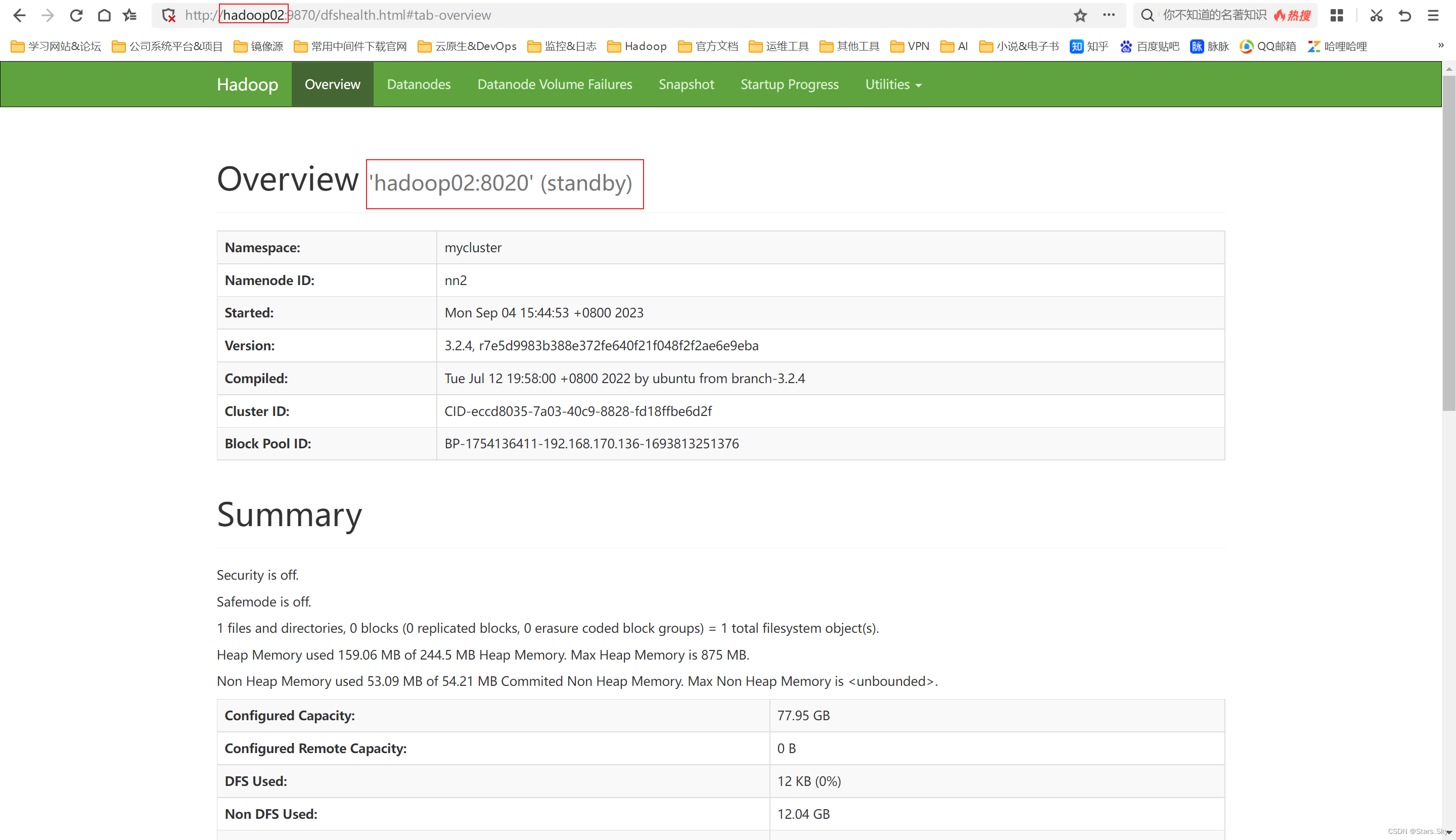
在 hadoop02 上,显示 namenode 是 standby 状态:
5.2 HA 集群下正常操作
[root@hadoop01 ~]# hadoop fs -mkdir /test02
[root@hadoop01 ~]# hadoop fs -put apache-zookeeper-3.7.1-bin.tar.gz /test02
Active 上可以正常操作,Standby 上无法预览:

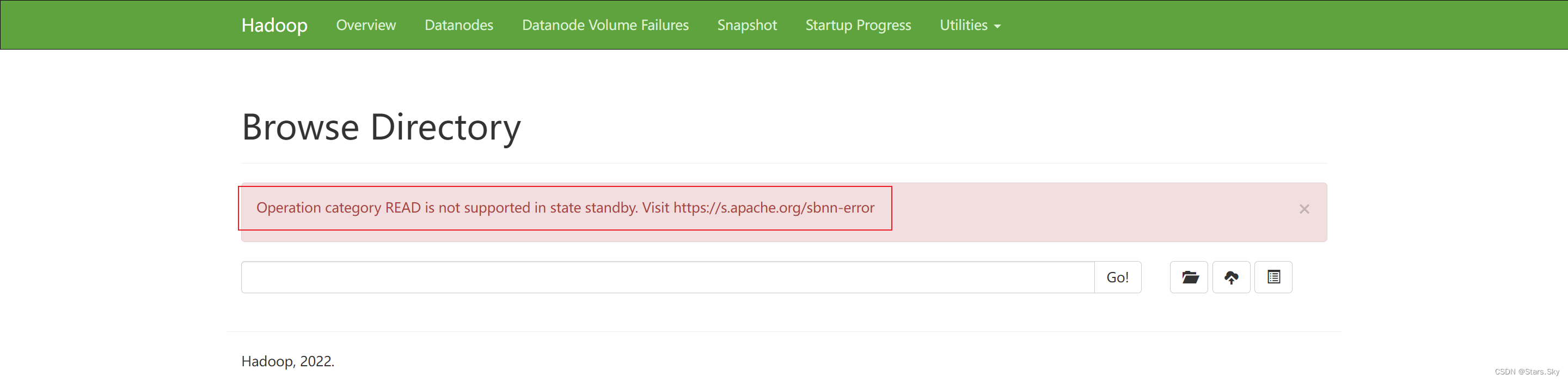
5.3 模拟故障出现
在 hadoop01,手动 kill 杀死 namenode 进程。此时发现 hadoop02 上的 namenode 切换成为 Active 状态 hdfs 服务正常可用。
[root@hadoop01 ~]# jps
6355 QuorumPeerMain
6516 JournalNode
7573 DataNode
7989 DFSZKFailoverController
8267 Jps
7132 NameNode
[root@hadoop01 ~]# kill -9 7132
5.3.1 HA 自动切换失败--错误解决
使用 kill -9 模拟 JVM 崩溃。或者重新启动计算机电源或拔出其网络接口以模拟另一种故障。另一个 NameNode 应在几秒钟内自动变为活动状态。检测故障并触发故障转移所需的时间取决于ha.zookeeper.session-timeout.ms 的配置,但默认值为 5 秒。
如果测试不成功,检查 zkfc 守护程序以及 NameNode 守护程序的日志,以便进一步诊断问题。如果错误信息如下:

提示未找到 fuser 程序,导致无法进行隔离,所以可以通过如下命令来安装,Psmisc 软件包中包含了 fuser 程序(两个 NN 机器上都需要进行安装)
[root@hadoop01 ~]# yum install psmisc -y
[root@hadoop02 ~]# yum install psmisc -y最后再重新启动 hdfs 集群,重新模拟故障出现则可以实现自动切换了!!!
上一篇文章:HDFS 集群动态节点管理_Stars.Sky的博客-CSDN博客