作者:ADRIEN GRAND
实现向量数据库有不同的方法,它们有不同的权衡。 在本博客中,你将详细了解如何将向量搜索集成到 Elastisearch 中以及我们所做的权衡。
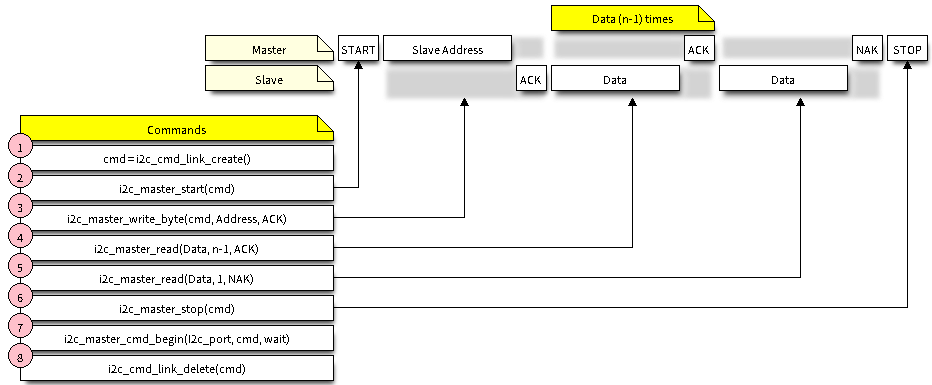
你有兴趣了解 Elasticsearch 用于向量搜索的特性以及设计是什么样子吗? 一如既往,设计决策有利有弊。 本博客旨在详细介绍我们如何选择在 Elasticsearch 中构建向量搜索。
向量搜索通过 Apache Lucene 集成到 Elasticsearch 中
首先是有关 Lucene 的一些背景知识:Lucene 将数据组织成定期合并的不可变段。 添加更多文档需要添加更多段。 修改现有文档需要自动添加更多段并将这些文档的先前版本标记为已删除。 段内的每个文档都由文档 ID 标识,文档 ID 是该文档在段内的索引,类似于数组的索引。 这种方法的动机是管理倒排索引,倒排索引不擅长就地修改,但可以有效地合并。
除了倒排索引之外,Lucene 还支持存储字段(文档存储)、文档值(列式存储)、术语向量(每个文档的倒排索引)以及段中的多维点。 向量已以相同的方式集成:
- 新向量在索引时缓冲到内存中。
- 当超出索引时间缓冲区的大小或必须使更改可见时,这些内存中的缓冲区将被序列化为段的一部分。
- 分段会在后台定期合并在一起,以控制分段总数并限制每个分段的整体搜索时间开销。 由于它们是段的一部分,因此向量也需要合并。
- 搜索必须组合索引中所有段的顶部向量命中(top vector hits)。
- 对向量的搜索必须查看实时文档集,以便排除 token 为已删除的文档。
上面的系统是由 Lucene 的工作方式驱动的。
Lucene 目前使用分层可导航小世界 (Hierachical Navigable Small World - HNSW) 算法来索引向量。 在较高层次上,HNSW 将向量组织成一个图表(graph),其中相似的向量可能会连接起来。 HNSW 是向量搜索的热门选择,因为它相当简单,在向量搜索算法的比较基准上表现良好,并且支持增量插入。 Lucene 对 HNSW 的实现遵循 Lucene 将数据保留在磁盘上并依靠页面缓存来加速对频繁访问的数据的访问的准则。
近似向量搜索通过 knn 部分在 Elasticsearch 的 _search API 中公开。 使用此功能将直接利用 Lucene 的向量搜索功能。 向量还集成在 Elasticsearch 的脚本 API 中,允许执行精确的强力搜索(exact brute force search),或利用向量进行重新评分。
现在让我们深入探讨通过 Apache Lucene 集成向量搜索的优缺点。
缺点
利用 Apache Lucene 进行向量搜索的主要缺点是 Lucene 将向量与段联系起来。 然而,正如我们稍后将在 “优点” 部分中看到的,将向量与段联系起来也是实现高效预过滤、高效混合搜索和可见性一致性等主要功能的原因。
合并需要重新计算 HNSW 图
段合并需要采用 N 个输入段(默认合并策略通常为 10 个),并将它们合并为单个段。 Lucene 当前从没有删除的最大输入段创建 HNSW 图的副本,然后将来自其他段的向量添加到此 HNSW 图。 与在索引的生命周期内就地改变单个 HNSW 图相比,这种方法会产生索引时间开销,因为段是合并的。
搜索需要合并多个细分的结果
由于索引由多个段组成,因此搜索需要计算每个段上的 top-k 向量,然后将这些每个段的 top-k 命中合并为全局 top-k 命中。 通过并行搜索段可以减轻对延迟的影响,但与搜索单个 HNSW 图相比,这种方法仍然会产生一些开销。
RAM 需要随着数据集的大小进行扩展以保持最佳性能
遍历 HNSW 图会产生大量随机访问。 为了高效执行,数据集应适合页面缓存,这需要根据所管理的向量数据集的大小调整 RAM 的大小。 除了 HNSW 之外,还存在其他用于向量搜索的算法,它们具有更适合磁盘的访问模式,但它们也有其他缺点,例如更高的查询延迟或更差的召回率。
优点
数据集可以扩展到超出 RAM 总大小
由于数据存储在磁盘上,Elasticsearch 将允许数据集大于本地主机上可用的 RAM 总量,并且随着页面缓存中可容纳的 HNSW 数据比例的降低,性能将会下降。 如上一节所述,注重性能的用户需要根据数据集的大小来调整 RAM 大小,以保持最佳性能。
无锁搜索
就地更新数据结构的系统通常需要加锁,以保证并发索引和搜索下的线程安全。 Lucene 基于段的索引从不需要在搜索时锁定,即使在并发索引的情况下也是如此。 相反,索引所组成的段集会定期以原子方式更新。
支持增量更改
可以随时添加、删除或更新新向量。 其他一些近似最近邻搜索算法需要提供整个向量数据集。 然后,一旦提供了所有向量,就执行索引训练步骤。 对于这些其他算法,对向量数据集的任何重大更新都需要再次完成训练步骤,这可能会导致计算成本高昂。
与其他数据结构的可见性一致性
在如此低的级别集成到 Lucene 的一个好处是,在查看索引的时间点视图时,我们可以与其他开箱即用的数据结构保持一致。 如果你执行文档更新以更新其向量和某些其他关键字字段,则并发搜索保证会看到向量字段的旧值和关键字字段的旧值 - 如果时间点 视图是在更新之前创建的,或者是向量场的新值和关键字字段的新值(如果时间点视图是在更新之后创建的)。 同样,对于删除,如果文档被标记为已删除,那么包括向量存储在内的所有数据结构都将忽略它,或者如果它们对删除之前创建的时间点视图进行操作,则它们将看到它。
增量快照
向量是段的一部分,这一事实有助于快照通过利用两个后续快照通常共享其大部分段(尤其是较大的段)的事实来保持增量。 使用就地更改的单个 HNSW 图不可能实现增量快照。
过滤和混合支持
直接集成到 Lucene 中还可以与其他 Lucene 功能高效集成,例如使用任意 Lucene 过滤器预过滤向量搜索或将来自向量查询的命中与来自传统全文查询的命中组合起来。
通过拥有自己的与段关联的 HNSW 图,并且其中节点由文档 ID 索引,Lucene 可以就如何最好地预过滤向量搜索做出有趣的决定:要么通过线性扫描与过滤器匹配的文档(如果有选择性), 或者通过遍历图并仅考虑与过滤器匹配的节点作为 top-k 向量的候选节点。
与其他功能的兼容性
由于向量存储与任何其他 Lucene 数据结构一样,因此许多功能与向量和向量搜索自动兼容,包括:
- 聚合
- 文档级安全性
- 字段级安全
- 索引排序
- 通过脚本访问向量(例如,从 script_score 查询或重新排序)
展望未来:索引和搜索分离
正如另一篇博客中所讨论的,Elasticsearch 的未来版本将在不同的实例上运行索引和搜索工作负载。 该实现本质上看起来就像你不断在索引节点上创建快照并在搜索节点上恢复它们。 这将有助于防止向量索引的高成本影响搜索。 使用单个共享 HNSW 图而不是多个段来实现索引和搜索的这种分离是不可能的,除非每次需要在新搜索中反映更改时通过网络发送完整的 HNSW 图。
结论
总的来说,Elasticsearch 提供了出色的向量搜索功能,并与其他 Elasticsearch 功能集成:
- 向量搜索可以通过任何支持的过滤器进行预过滤,包括最复杂的过滤器。
- 向量命中可以与任意查询的命中相结合。
- 向量搜索与聚合、文档级安全性、字段级安全性、索引排序等兼容。
- 包含向量的索引仍然遵循与其他索引相同的语义,包括 _refresh、_flush 和 _snapshot API。 它们还将支持无状态 Elasticsearch 中索引和搜索的分离。
这是以一些索引时间和搜索时间开销为代价完成的。 也就是说,向量搜索通常仍然以数十或数百毫秒的数量级运行,并且比强力精确搜索快得多。 更一般地说,与现有比较基准*中的其他向量存储相比,索引时间和搜索时间开销似乎都是可控的(查找 “luceneknn” 行)。 我们还相信,通过将向量搜索与其他功能相结合,可以释放向量搜索的许多价值。 此外,我们建议你查看 KNN 搜索调整指南,其中列出了许多有助于减轻上述缺点的负面影响的措施。
我希望你喜欢这个博客。 如果你有疑问,请随时通过讨论与我们联系。 你可以随意在现有部署中尝试向量搜索,或者在 Elastic Cloud 上免费试用 Elasticsearch Service(始终具有最新版本的 Elasticsearch)。
*在撰写本文时,这些基准测试尚未利用向量化。 有关向量化的更多信息,请阅读此博客。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Vector search in Elasticsearch: The rationale behind the design — Elastic Search Labs