查询优化
物理查询优化
通过索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用
逻辑查询优化
通过SQL 等价变换 提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高
索引失效
- 计算、函数、类型转换(自动或手动)导致索引失效
select sql_no_cache * from student where left(sutdent_name,3)=‘abc’ type: all
优化
select sql_no_cache * from student where student_name like ‘abc%’ tyoe: range假设student_name 数据类型 varchar(5),且student_name 有普通索引
select sql_no_cache * from student where student_name =123 type:all
优化
select sql_no_cache * from student where student_name =‘123’ type:indexcreate index idx_sno on student(stuno);
select sql_no_cache * from student where stuno+1=2023008; type:all
优化
select sql_no_cahe * from student where stuno=2023007 type: index联合索引(复合索引)
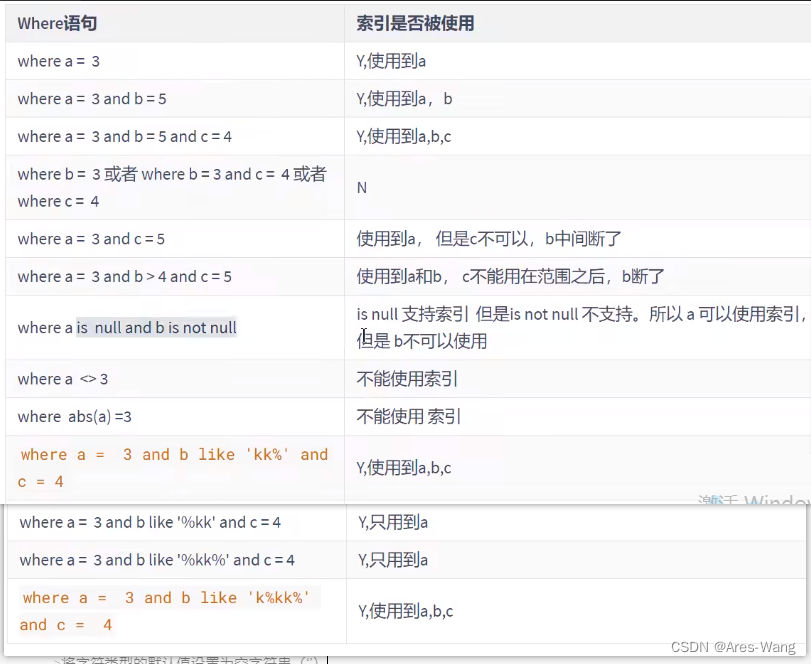
对于多列索引,过滤条件要使用索引必须按照索引建立的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
如果查询条件中没有使用这些字段中第一个字段时,多列(联合)索引不会被使用。范围条件右边的列索引失效
create index idx_age_classId_name on student(age,classId,name);
select sql_no_cache * from student where student.age=30 and student.classId>20 and student.name=‘abc’; ## name 索引就失效了
应用开发中范围查询,例如 金额查询、日期查询往往都是范围查询。应将查询条件放置where 语句最后(创建的联合索引中,务必把访问涉及到的字段写在最后) sql 语句中where 顺序 并不影响mysql 优化策略的。 联合索引的顺序影响的。is null 可以使用索引 is not null 不能使用索引
not like 页不能使用索引,导致全部扫描
<>,!= 不等于 不能使用索引
like % 开头 索引失效 stuname like ‘%123’ , 不建议 左模糊,全模糊
OR 前后存在非索引的列,索引失效
最后在设计数据表的时候将字段设置为 not null 约束,
比如你可以将int 类型的字段,默认值设置为0.
将字符类型的默认值设置为空字符串(‘’)
总结
index(a,b,c)











![[译]这8个CSS小技巧,你知道吗?](https://img-blog.csdnimg.cn/img_convert/ca2f9bece6c92cde3999d9e147e1b1aa.png)