文章目录
- 第一步:安装anaconda
- 第二步:安装虚拟环境
- 第三步:安装torch和torchvision
- 第四步: 安装mmcv-full
- 第五步: 安装mmdetection
- 第六步:测试环境
- 第七步:训练-目标检测
- 7.1 准备数据集
- 7.2 检查数据集
- 7.3 训练网络
第一步:安装anaconda
参考教程:点击
第二步:安装虚拟环境
conda create --name openmmlab python=3.8
conda activate openmmlab
第三步:安装torch和torchvision
conda install pytorch torchvision torchaudio cpuonly -c pytorch
安装的版本为

第四步: 安装mmcv-full
下载地址:点击
如果是2.*以上的版本,则为mmcv。
pip install mmcv-2.0.1-cp38-cp38-win_amd64.whl
第五步: 安装mmdetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
到这里为止,环境的配置就完成了。
第六步:测试环境
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
下载将需要几秒钟或更长时间,这取决于你的网络环境。完成后,你会在当前文件夹中发现两个文件 rtmdet_tiny_8xb32-300e_coco.py 和 rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth。
如果你通过源码安装的 MMDetection,那么直接运行以下命令进行验证:
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --device cpu
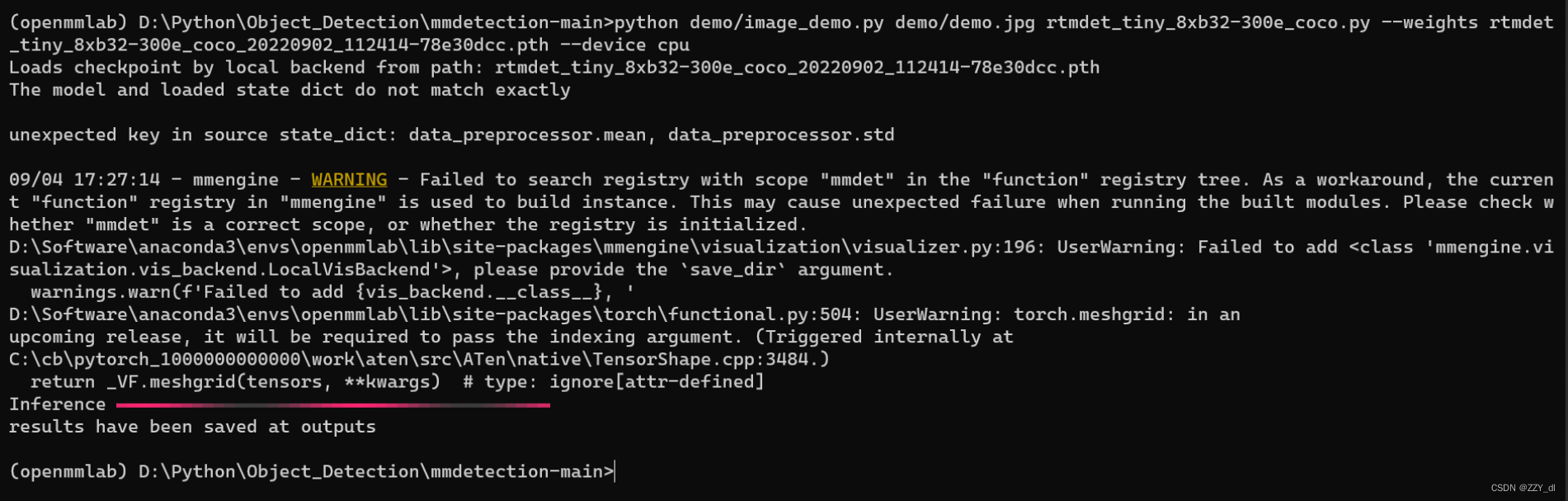
你会在当前文件夹中的 outputs/vis 文件夹中看到一个新的图像 demo.jpg,图像中包含有网络预测的检测框。

第七步:训练-目标检测
下载目标检测mmyolo:https://github.com/open-mmlab/mmyolo
这个里面的yolo系列更全
7.1 准备数据集
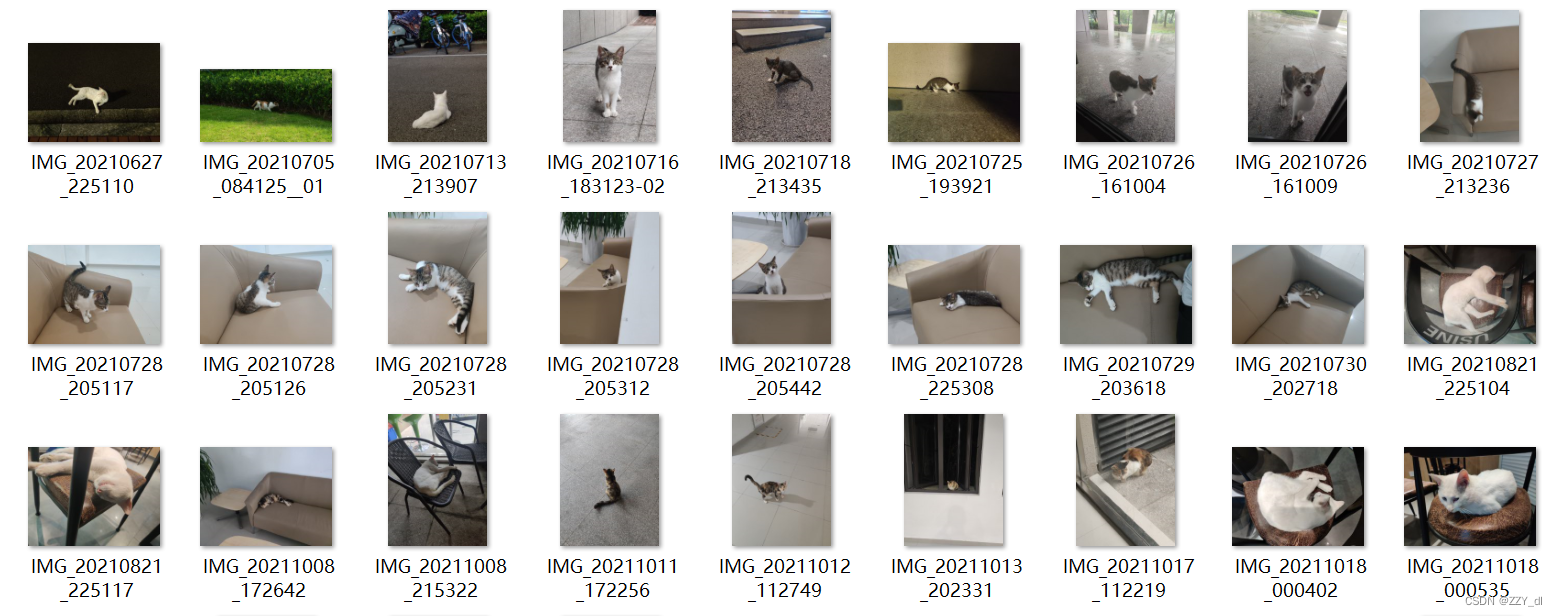
Cat 数据集是由 144 张图片组成的单类数据集(原始图片由 @RangeKing 提供,并由 @PeterH0323 清理),其中包含训练所需的注释信息。示例图像如下所示:
 您可以通过以下命令直接下载并使用它:
您可以通过以下命令直接下载并使用它:
python tools/misc/download_dataset.py --dataset-name cat --save-dir data/cat --unzip --delete
此数据集使用以下目录结构自动下载到 dir:data/cat
7.2 检查数据集
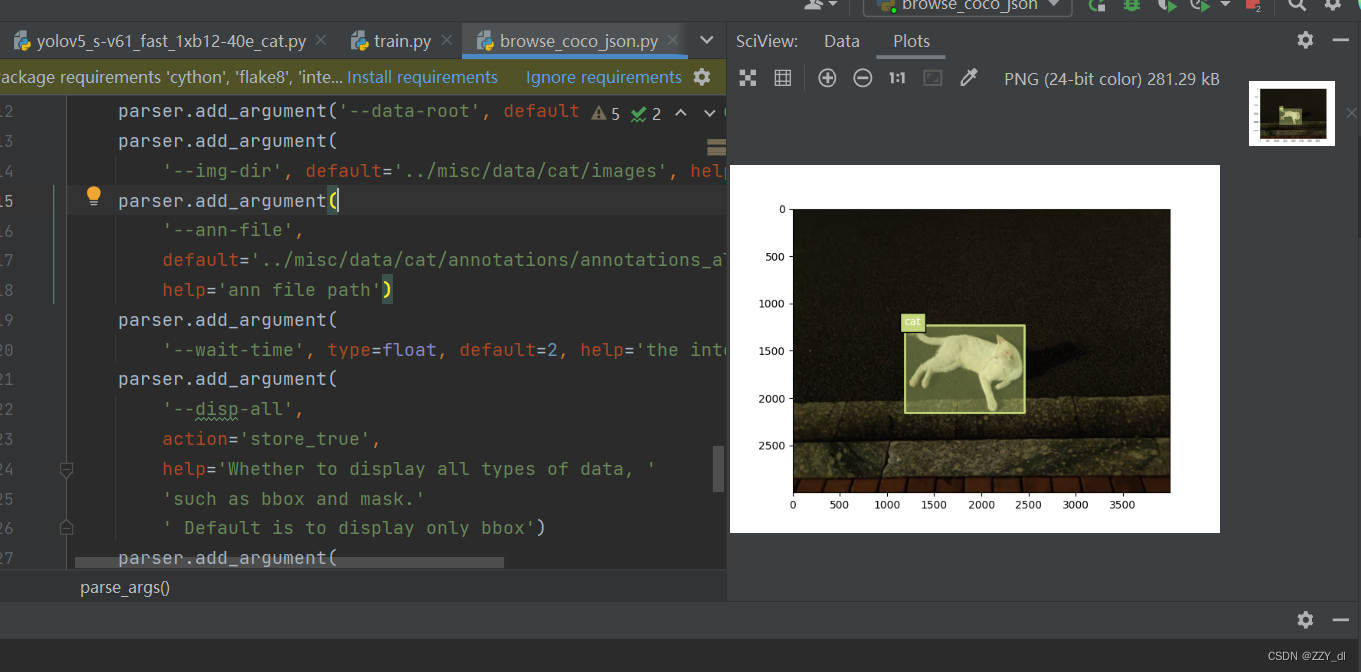
检查标签是否有问题
修改 tools/analysis_tools/browse_coco_json.py --img-dir ../misc/data/cat/images --ann-file ../misc/data/cat/annotations/annotations_all.json
7.3 训练网络
以 YOLOv5 算法为例,考虑到用户的 GPU 内存有限,我们需要修改一些默认的训练参数,使其流畅运行。需要修改的关键参数如下:
- YOLOv5 是一种基于锚点的算法,不同的数据集需要自适应地计算合适的锚点
- 默认配置使用 8 个 GPU,每个 GPU 的批大小为 16 个。现在将其更改为批处理大小为 12 的单个 GPU。
- 默认训练周期为 300。将其更改为 40 纪元
- 鉴于数据集很小,我们选择使用固定的主干权重
- 原则上,当批量大小发生变化时,学习率应相应地线性缩放,但实际测量发现这不是必需的
在文件夹中创建一个配置文件(我们提供了这个配置供您直接使用),并将以下内容复制到配置文件中。yolov5_s-v61_fast_1xb12-40e_cat.pyconfigs/yolov5
_base_ = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
data_root = 'misc/data/cat/'
class_name = ('cat', )
num_classes = len(class_name)
metainfo = dict(classes=class_name, palette=[(20, 220, 60)])
anchors = [
[(68, 69), (154, 91), (143, 162)], # P3/8
[(242, 160), (189, 287), (391, 207)], # P4/16
[(353, 337), (539, 341), (443, 432)] # P5/32
]
max_epochs = 40
train_batch_size_per_gpu = 12
train_num_workers = 4
load_from = 'https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth' # noqa
model = dict(
backbone=dict(frozen_stages=4),
bbox_head=dict(
head_module=dict(num_classes=num_classes),
prior_generator=dict(base_sizes=anchors)))
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/')))
val_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json',
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
_base_.optim_wrapper.optimizer.batch_size_per_gpu = train_batch_size_per_gpu
val_evaluator = dict(ann_file=data_root + 'annotations/test.json')
test_evaluator = val_evaluator
default_hooks = dict(
checkpoint=dict(interval=10, max_keep_ckpts=2, save_best='auto'),
# The warmup_mim_iter parameter is critical.
# The default value is 1000 which is not suitable for cat datasets.
param_scheduler=dict(max_epochs=max_epochs, warmup_mim_iter=10),
logger=dict(type='LoggerHook', interval=5))
train_cfg = dict(max_epochs=max_epochs, val_interval=10)
# visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='WandbVisBackend')]) # noqa
然后修改tools/train.py。主要修改config就行了
parser.add_argument('--config', default="../configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py", help='train config file path')
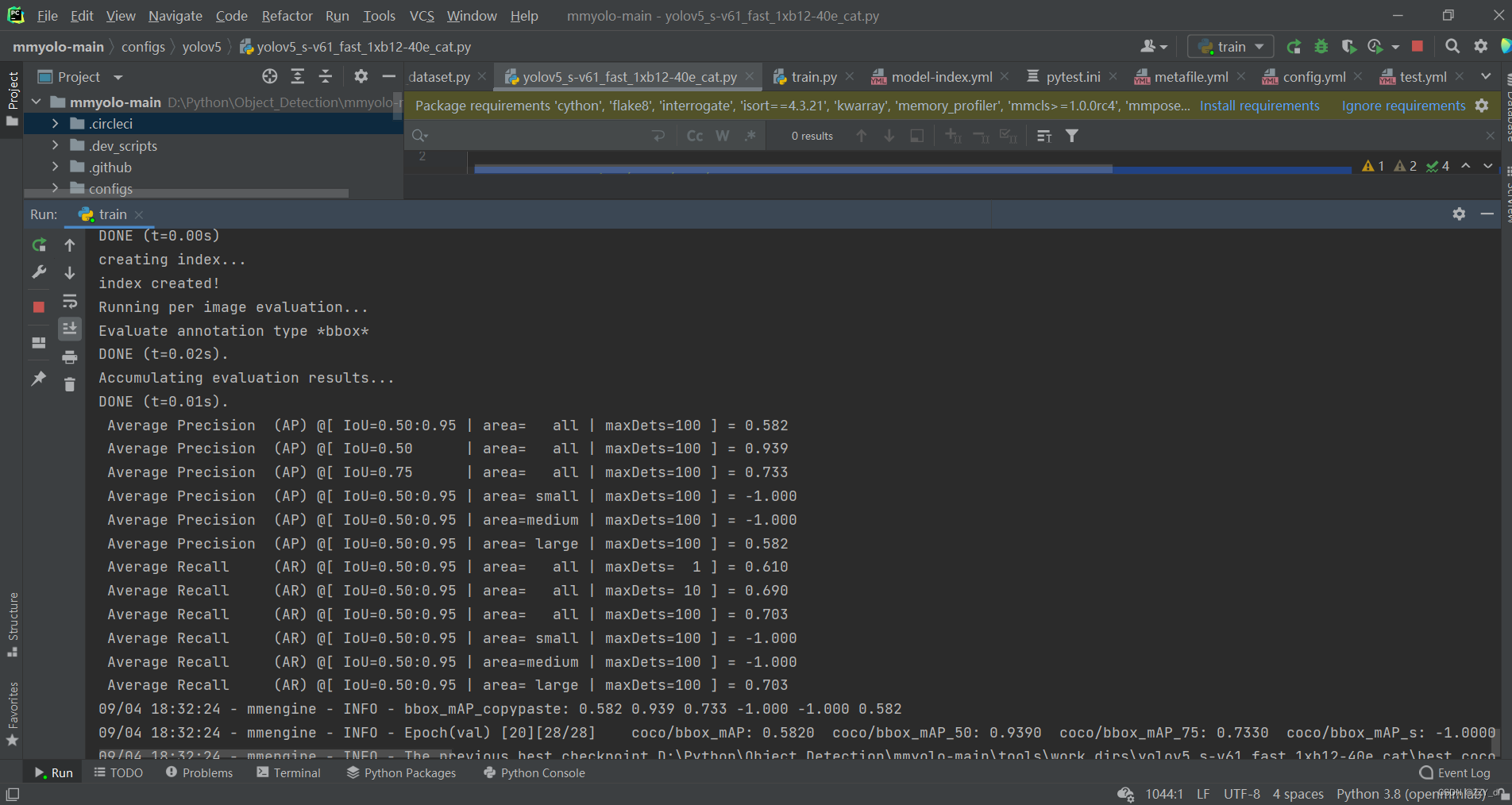
报错需要安装pip install albumentations -i https://pypi.tuna.tsinghua.edu.cn/simple 和pip install prettytable -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完运行后成功训练:

![[译]这8个CSS小技巧,你知道吗?](https://img-blog.csdnimg.cn/img_convert/ca2f9bece6c92cde3999d9e147e1b1aa.png)
![[Linux]编写一个极简版的shell(版本1)](https://img-blog.csdnimg.cn/img_convert/4500ee5e9f9e63c866098156cafc1b00.gif)