目录
1 循环神经网络介绍
1.1 什么是循环神经网络
1.2 RNN的网络结构
1.3 RNN的工作原理
编辑
1.4 RNN的应用场景
2 基于RNN实现语句生成
2.1 句子生成介绍
2.2 基于pytorch实现语句生成
2.3 完整代码
2.4 该模型的局限
3 总结
1 循环神经网络介绍
1.1 什么是循环神经网络
循环神经网络(Recurrent Neural Network,简称RNN)是一种处理序列数据的神经网络结构,它具有记忆能力,能够捕捉序列中的时序信息。RNN在自然语言处理、时间序列预测、语音识别等领域有着广泛的应用。
RNN的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。
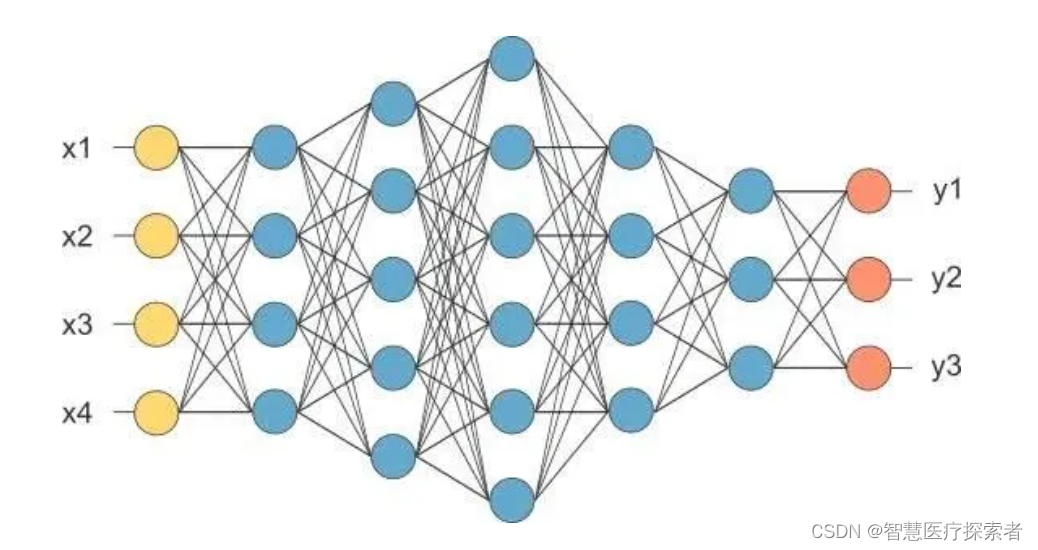
但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
1.2 RNN的网络结构
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
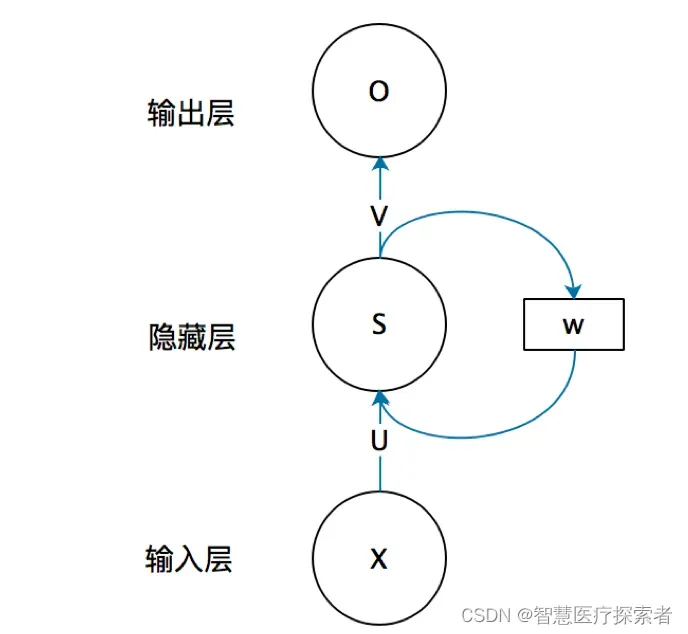
- x是一个向量,它表示输入层的值;
- s是一个向量,它表示隐藏层的值;
- U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;
- V是隐藏层到输出层的权重矩阵;
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。
从抽象到具体的展示如下:
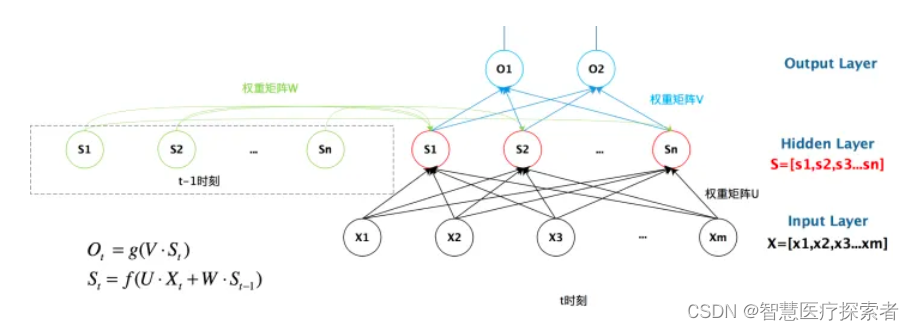
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,模型结构展开如下:
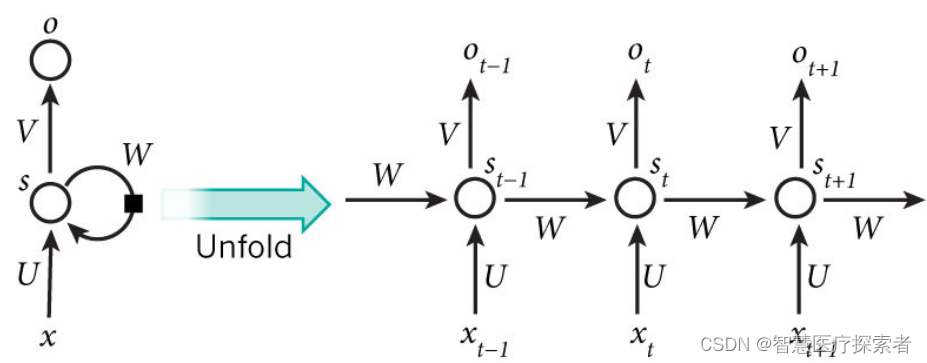
上图显示了一个RNN被展开成一个完整的网络。 例如,如果我们关心的序列是5个单词的句子,网络将被展开成5层神经网络,每个单词一层。RNN中发生的计算的公式如下:

1.3 RNN的工作原理
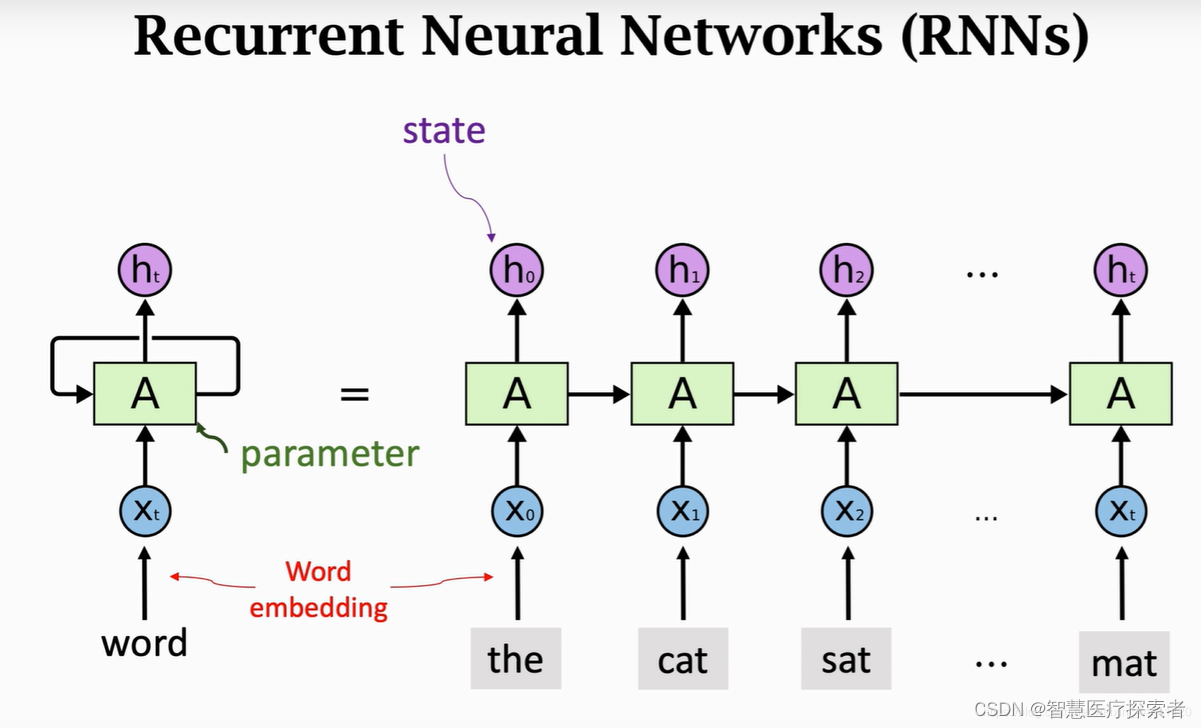
输入层:RNN能够接受一个输入序列(例如文字、股票价格、语音信号等)并将其传递到隐藏层。
隐藏层:隐藏层之间存在循环连接,使得网络能够维护一个“记忆”状态,这一状态包含了过去的信息。这使得RNN能够理解序列中的上下文信息。
输出层:RNN可以有一个或多个输出,例如在序列生成任务中,每个时间步都会有一个输出。
梯度问题:梯度消失和爆炸
由于RNN的循环结构,在训练中可能会出现梯度消失或梯度爆炸的问题。长序列可能会导致训练过程中的梯度变得非常小(消失)或非常大(爆炸),从而影响模型的学习效率。
1.4 RNN的应用场景
循环神经网络(RNN)因其在捕获序列数据中的时序依赖性方面的优势,在许多应用场景中都得到了广泛的使用。

自然语言处理(NLP):
- 文本生成:RNN可以用于生成文本,如文本生成、散文创作和诗歌生成。
- 语言建模:RNN可用于语言建模任务,如预测下一个单词或字符。
- 机器翻译:RNN的变种,如长短时记忆网络(LSTM)和门控循环单元(GRU),已广泛用于机器翻译任务。
- 情感分析:RNN可以用于分析文本情感,如判断一段文本的情感极性(正面、负面、中性)。
语音识别:
- 语音转文本:RNN被用于将语音信号转换为文本,如语音助手和语音识别系统。
- 声纹识别:RNN也可以用于声纹识别,用于验证个人的身份。
时间序列分析:
- 股票价格预测:RNN可以用于分析股票价格和预测市场趋势。
- 天气预测:RNN可用于天气预测,处理气象数据的时间序列。
- 信用风险评估:RNN可用于分析客户的信用历史和行为,进行信用评估。
2 基于RNN实现语句生成
2.1 句子生成介绍
绝大多数的NLP任务,文本数据都会先通过嵌入码(Embedding code),独热编码(One-hot encoding)等方式转为数字编码。在本篇文章中将使用one-hot编码标识我们的字符。首先,我们需要将把文本数据预处理为简单的表示形式——字符级别的One-hot encoding。
这种编码形式基本上是给文本中的每个字符一个唯一的向量。 例如,如果我们的文本只包含单词“GOOD”,那么只有 3 个唯一字符,G,O,D,三个,因此我们的词汇量只有 3。我们将为每个唯一字符分配一个唯一向量,其中除了索引中的一项之外,所有项都为零。 这就是我们向模型表示每个字符的方式。
对于只有三个单词的one-hot,那么维度即为3;按序编码G,O,D,那么
G为1,展开one-hot就是[1,0,0],
O为2, 就是[0,1,0],
D为3,就是[0,0,1]
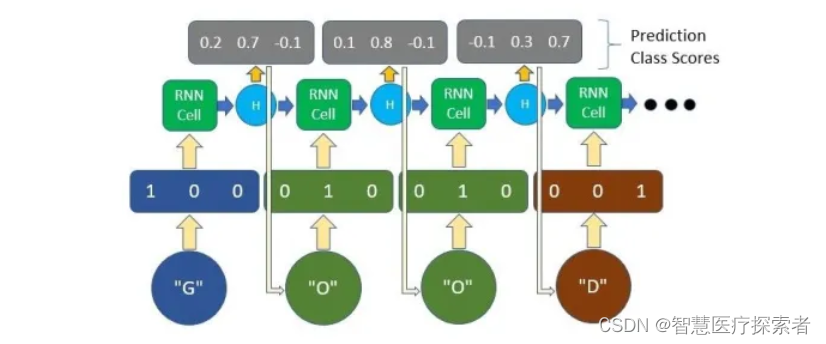
输出也可能类似,我们可以取向量中的最高数字并将其作为预测字符。在这个实现中,我们将使用 PyTorch 库,这是一个易于使用并被顶级研究人员广泛使用的深度学习平台。 我们将构建一个模型,该模型将根据传入的一个单词或几个字符来完成一个句子。
该模型将输入一个单词,并预测句子中的下一个字符是什么。 这个过程会不断重复,直到我们生成所需长度的句子。为了保持简短和简单,我们不会使用任何大型或外部数据集。 我们将只定义几个句子来看看模型如何从这些句子中学习。
2.2 基于pytorch实现语句生成
首先,我们将定义我们希望模型在输入第一个单词或前几个字符时输出的句子。
然后我们将从句子中的所有字符创建一个字典,并将它们映射到一个整数。 这将允许我们将输入字符转换为它们各自的整数(char2int),反之亦然(int2char)。
text = ['hey how are you','good i am fine','have a nice day']
# Join all the sentences together and extract the unique characters from the combined sentences
chars = set(''.join(text))
# Creating a dictionary that maps integers to the characters
int2char = dict(enumerate(chars))
# Creating another dictionary that maps characters to integers
char2int = {char: ind for ind, char in int2char.items()}char2int 字典看起来像这样:它包含我们句子中出现的所有字母/符号,并将它们中的每一个映射到一个唯一的整数。
[Out]: {'f': 0, 'a': 1, 'h': 2, 'i': 3, 'u': 4, 'e': 5, 'm': 6, 'w': 7, 'y': 8, 'd': 9, 'c': 10, ' ': 11, 'r': 12, 'o': 13, 'n': 14, 'g': 15, 'v': 16}接下来,我们将填充(padding)输入句子以确保所有句子都是标准长度。 虽然 RNN 通常能够接收可变大小的输入,但我们通常希望分批输入训练数据以加快训练过程。 为了使用批次来训练我们的数据,我们需要确保输入数据中的每个序列大小相等。
因此,在大多数情况下,可以通过用 0 值填充太短的序列和修剪太长的序列来完成填充。 在我们的例子中,我们将找到最长序列的长度,并用空格填充其余句子以匹配该长度。
# Finding the length of the longest string in our data
maxlen = len(max(text, key=len))
# Padding
# A simple loop that loops through the list of sentences and adds a ' ' whitespace until the length of
# the sentence matches the length of the longest sentence
for i in range(len(text)):
while len(text[i])<maxlen:
text[i] += ' '由于我们要在每个时间步预测序列中的下一个字符,我们必须将每个句子分为:
- 输入数据
最后一个字符需排除因为它不需要作为模型的输入 - 目标/真实标签
它为每一个时刻后的值,因为这才是下一个时刻的值。
# Creating lists that will hold our input and target sequences
input_seq = []
target_seq = []
for i in range(len(text)):
# Remove last character for input sequence
input_seq.append(text[i][:-1])
# Remove first character for target sequence
target_seq.append(text[i][1:])
print("Input Sequence: {}\nTarget Sequence: {}".format(input_seq[i], target_seq[i]))输入和输出样例如下:
- 输入:hey how are yo
- 对应的标签: ey how are you
现在我们可以通过使用上面创建的字典映射输入和目标序列到整数序列。 这将允许我们随后对输入序列进行一次one-hot encoding。
for i in range(len(text)):
input_seq[i] = [char2int[character] for character in input_seq[i]]
target_seq[i] = [char2int[character] for character in target_seq[i]]定义如下三个变量
- dict_size: 字典的长度,即唯一字符的个数。它将决定one-hot vector的长度
- seq_len:输入到模型中的sequence长度。这里是最长的句子的长度-1,因为不需要最后一个字符
- batch_size: mini batch的大小,用于批量训练
dict_size = len(char2int)
seq_len = maxlen - 1
batch_size = len(text)
def one_hot_encode(sequence, dict_size, seq_len, batch_size):
# Creating a multi-dimensional array of zeros with the desired output shape
features = np.zeros((batch_size, seq_len, dict_size), dtype=np.float32)
# Replacing the 0 at the relevant character index with a 1 to represent that character
for i in range(batch_size):
for u in range(seq_len):
features[i, u, sequence[i][u]] = 1
return features同时定义一个helper function,用于初始化one-hot向量
# Input shape --> (Batch Size, Sequence Length, One-Hot Encoding Size)
input_seq = one_hot_encode(input_seq, dict_size, seq_len, batch_size)到此我们完成了所有的数据预处理,可以将数据从NumPy数组转为PyTorch张量啦。
input_seq = torch.from_numpy(input_seq)
target_seq = torch.Tensor(target_seq)接下来就是搭建模型的步骤,你可以在这一步使用全连接层,卷积层,RNN层,LSTM层等等。但是我在这里使用最最基础的nn.rnn来示例一个RNN是如何使用的。
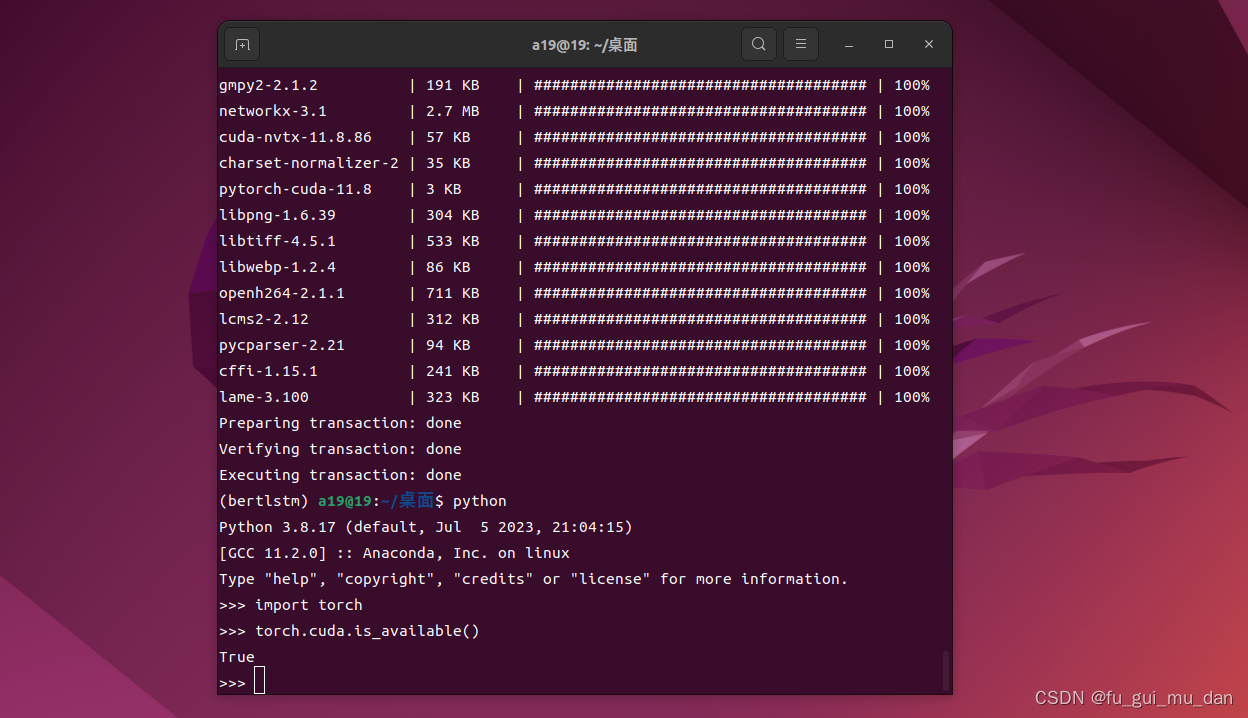
在开始构建模型之前,让我们使用 PyTorch 中的内置功能来检查我们正在运行的设备(CPU 或 GPU)。 此实现不需要 GPU,因为训练非常简单。 但是,随着处理具有数百万个可训练参数的大型数据集和模型,使用 GPU 对加速训练非常重要。
# torch.cuda.is_available() checks and returns a Boolean True if a GPU is available, else it'll return False
is_cuda = torch.cuda.is_available()
# If we have a GPU available, we'll set our device to GPU. We'll use this device variable later in our code.
if is_cuda:
device = torch.device("cuda")
print("GPU is available")
else:
device = torch.device("cpu")
print("GPU not available, CPU used")要开始构建我们自己的神经网络模型,我们可以为所有神经网络模块定义一个继承 PyTorch 的基类(nn.module)的类。 这样做之后,我们可以开始在构造函数下定义一些变量以及模型的层。 对于这个模型,我们将只使用一层 RNN,然后是一个全连接层。 全连接层将负责将 RNN 输出转换为我们想要的输出形状。
我们还必须将 forward() 下的前向传递函数定义为类方法。 前向函数是按顺序执行的,因此我们必须先将输入和零初始化隐藏状态通过 RNN 层,然后再将 RNN 输出传递到全连接层。 请注意,我们使用的是在构造函数中定义的层。
我们必须定义的最后一个方法是我们之前调用的用于初始化hidden state的方法 - init_hidden()。 这基本上会在我们的隐藏状态的形状中创建一个零张量。
class Model(nn.Module):
def __init__(self, input_size, output_size, hidden_dim, n_layers):
super(Model, self).__init__()
# Defining some parameters
self.hidden_dim = hidden_dim
self.n_layers = n_layers
#Defining the layers
# RNN Layer
self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
# Fully connected layer
self.fc = nn.Linear(hidden_dim, output_size)
def forward(self, x):
batch_size = x.size(0)
# Initializing hidden state for first input using method defined below
hidden = self.init_hidden(batch_size)
# Passing in the input and hidden state into the model and obtaining outputs
out, hidden = self.rnn(x, hidden)
# Reshaping the outputs such that it can be fit into the fully connected layer
out = out.contiguous().view(-1, self.hidden_dim)
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
# This method generates the first hidden state of zeros which we'll use in the forward pass
# We'll send the tensor holding the hidden state to the device we specified earlier as well
hidden = torch.zeros(self.n_layers, batch_size, self.hidden_dim)
return hidde在定义了上面的模型之后,我们必须用相关参数实例化模型并定义我们的超参数。 我们在下面定义的超参数是:
- n_epochs: 模型训练所有数据集的次数
- lr: learning rate学习率
有关超参数,可以参考该文章作为进一步学习。
与其他神经网络类似,我们也必须定义优化器和损失函数。 我们将使用 CrossEntropyLoss,因为最终输出基本上是一个分类任务和常见的 Adam 优化器。
# Instantiate the model with hyperparameters
model = Model(input_size=dict_size, output_size=dict_size, hidden_dim=12, n_layers=1)
# We'll also set the model to the device that we defined earlier (default is CPU)
model.to(device)
# Define hyperparameters
n_epochs = 100
lr=0.01
# Define Loss, Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)现在我们可以开始训练了! 由于我们只有几句话,所以这个训练过程非常快。 然而,随着我们的进步,更大的数据集和更深的模型意味着输入数据要大得多,并且我们必须计算的模型中的参数数量要多得多。
# Training Run
for epoch in range(1, n_epochs + 1):
optimizer.zero_grad() # Clears existing gradients from previous epoch
input_seq.to(device)
output, hidden = model(input_seq)
loss = criterion(output, target_seq.view(-1).long())
loss.backward() # Does backpropagation and calculates gradients
optimizer.step() # Updates the weights accordingly
if epoch%10 == 0:
print('Epoch: {}/{}.............'.format(epoch, n_epochs), end=' ')
print("Loss: {:.4f}".format(loss.item()))Epoch: 10/100............. Loss: 2.4351
Epoch: 20/100............. Loss: 2.2388
Epoch: 30/100............. Loss: 1.8932
Epoch: 40/100............. Loss: 1.4660
Epoch: 50/100............. Loss: 1.0754
Epoch: 60/100............. Loss: 0.7707
Epoch: 70/100............. Loss: 0.5341
Epoch: 80/100............. Loss: 0.3661
Epoch: 90/100............. Loss: 0.2591
Epoch: 100/100............. Loss: 0.1939现在让我们测试我们的模型,看看我们会得到什么样的输出。 作为第一步,我们将定义一些辅助函数来将我们的模型输出转换回文本。
# This function takes in the model and character as arguments and returns the next character prediction and hidden state
def predict(model, character):
# One-hot encoding our input to fit into the model
character = np.array([[char2int[c] for c in character]])
character = one_hot_encode(character, dict_size, character.shape[1], 1)
character = torch.from_numpy(character)
character.to(device)
out, hidden = model(character)
prob = nn.functional.softmax(out[-1], dim=0).data
# Taking the class with the highest probability score from the output
char_ind = torch.max(prob, dim=0)[1].item()
return int2char[char_ind], hidden# This function takes the desired output length and input characters as arguments, returning the produced sentence
def sample(model, out_len, start='hey'):
model.eval() # eval mode
start = start.lower()
# First off, run through the starting characters
chars = [ch for ch in start]
size = out_len - len(chars)
# Now pass in the previous characters and get a new one
for ii in range(size):
char, h = predict(model, chars)
chars.append(char)
return ''.join(chars)让我们测试一下good
sample(model, 15, 'good')[Out]: 'good i am fine '正如我们所看到的,如果我们用“good”这个词输入到模型,该模型能够提出“good i am fine”这个句子。
2.3 完整代码
import torch
import torch.nn as nn
import numpy as np
text = ['hey how are you', 'good i am fine', 'have a nice day']
chars = set(''.join(text))
int2char = dict(enumerate(chars))
char2int = {char: ind for ind, char in int2char.items()}
print(char2int)
maxlen = len(max(text, key=len))
for i in range(len(text)):
while len(text[i]) < maxlen:
text[i] += ' '
input_seq = []
target_seq = []
for i in range(len(text)):
input_seq.append(text[i][:-1])
target_seq.append(text[i][1:])
print("Input Sequence: {}\nTarget Sequence: {}".format(input_seq[i], target_seq[i]))
for i in range(len(text)):
input_seq[i] = [char2int[character] for character in input_seq[i]]
target_seq[i] = [char2int[character] for character in target_seq[i]]
dict_size = len(char2int)
seq_len = maxlen - 1
batch_size = len(text)
def one_hot_encode(sequence, dict_size, seq_len, batch_size):
features = np.zeros((batch_size, seq_len, dict_size), dtype=np.float32)
for i in range(batch_size):
for u in range(seq_len):
features[i, u, sequence[i][u]] = 1
return features
input_seq = one_hot_encode(input_seq, dict_size, seq_len, batch_size)
input_seq = torch.from_numpy(input_seq)
target_seq = torch.Tensor(target_seq)
is_cuda = torch.cuda.is_available()
if is_cuda:
device = torch.device("cuda")
print("GPU is available")
else:
device = torch.device("cpu")
print("GPU not available, CPU used")
class RnnModel(nn.Module):
def __init__(self, input_size, output_size, hidden_dim, n_layers):
super(RnnModel, self).__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_size)
def forward(self, x):
batch_size = x.size(0)
hidden = self.init_hidden(batch_size)
out, hidden = self.rnn(x, hidden)
out = out.contiguous().view(-1, self.hidden_dim)
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers, batch_size, self.hidden_dim)
return hidden
model = RnnModel(input_size=dict_size, output_size=dict_size, hidden_dim=12, n_layers=1)
model.to(device)
n_epochs = 100
lr = 0.01
# Define Loss, Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(1, n_epochs + 1):
optimizer.zero_grad()
input_seq.to(device)
output, hidden = model(input_seq)
loss = criterion(output, target_seq.view(-1).long())
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print('Epoch: {}/{}.............'.format(epoch, n_epochs), end=' ')
print("Loss: {:.4f}".format(loss.item()))
def predict(model, character):
# One-hot encoding our input to fit into the model
character = np.array([[char2int[c] for c in character]])
character = one_hot_encode(character, dict_size, character.shape[1], 1)
character = torch.from_numpy(character)
character.to(device)
out, hidden = model(character)
prob = nn.functional.softmax(out[-1], dim=0).data
# Taking the class with the highest probability score from the output
char_ind = torch.max(prob, dim=0)[1].item()
return int2char[char_ind], hidden
def sample(model, out_len, start='hey'):
model.eval()
start = start.lower()
chars = [ch for ch in start]
size = out_len - len(chars)
for ii in range(size):
char, h = predict(model, chars)
chars.append(char)
return ''.join(chars)
result = sample(model, 15, 'good')
print(result)2.4 该模型的局限
虽然这个模型绝对是一个过度简化的语言模型,但让我们回顾一下它的局限性以及为了训练更好的语言模型需要解决的问题。
- 局限一、过拟合 over-fitting
我们只为模型提供了 3 个训练句子,因此它基本上“记住”了这些句子的字符序列,从而返回了我们训练它的确切句子。 但是,如果在更大的数据集上训练一个类似的模型,并添加一些随机性,该模型将挑选出一般的句子结构和语言规则,并且能够生成自己独特的句子。
尽管如此,使用单个样本或批次运行模型可以作为对工作流程的健全性检查,确保您的数据类型全部正确,模型学习良好等。
- 局限二、处理未见过的字符
该模型目前只能处理它之前在训练数据集中看到的字符。 通常,如果训练数据集足够大,所有字母和符号等应该至少出现一次,从而出现在我们的词汇表中。 然而,有一种方法来处理从未见过的字符总是好的,例如将所有未知数分配给它自己的索引。
- 局限三、文本标识的方式
在这个实现中,我们使用 one-hot 编码来表示我们的字符。 虽然由于它的简单性,它可能适合此任务,但大多数时候它不应该用作实际或更复杂问题的解决方案。 这是因为:
- 对于大型数据集,计算成本太高
- one-hot向量中没有嵌入上下文/语义信息
以及许多其他使此解决方案不太可行的缺点。
相反,大多数现代 NLP 解决方案依赖于词嵌入(word2vec、GloVe)或最近在 BERT、ELMo 和 ULMFit 中的独特上下文词表示。 这些方法允许模型根据出现在它之前的文本来学习单词的含义,并且在 BERT 等的情况下,也可以从出现在它之后的文本中学习。
3 总结
循环神经网络是一种强大的模型,特别适合于处理具有时间依赖性的序列数据。然而,标准RNN通常难以学习长序列中的依赖关系,因此有了更多复杂的变体如LSTM和GRU,来解决这些问题。





![[C++][pcl]pcl安装后测试代码3](https://img-blog.csdnimg.cn/dbf314fb0ce14ba48024618155cb166c.jpeg)