一、主从架构
为什么我们要进行读写分离?个人觉得还是业务发展到一定的规模,驱动技术架构的改革,读写分离可以减轻单台服务器的压力,将读请求和写请求分流到不同的服务器,分摊单台服务的负载,提高可用性,提高读请求的性能。

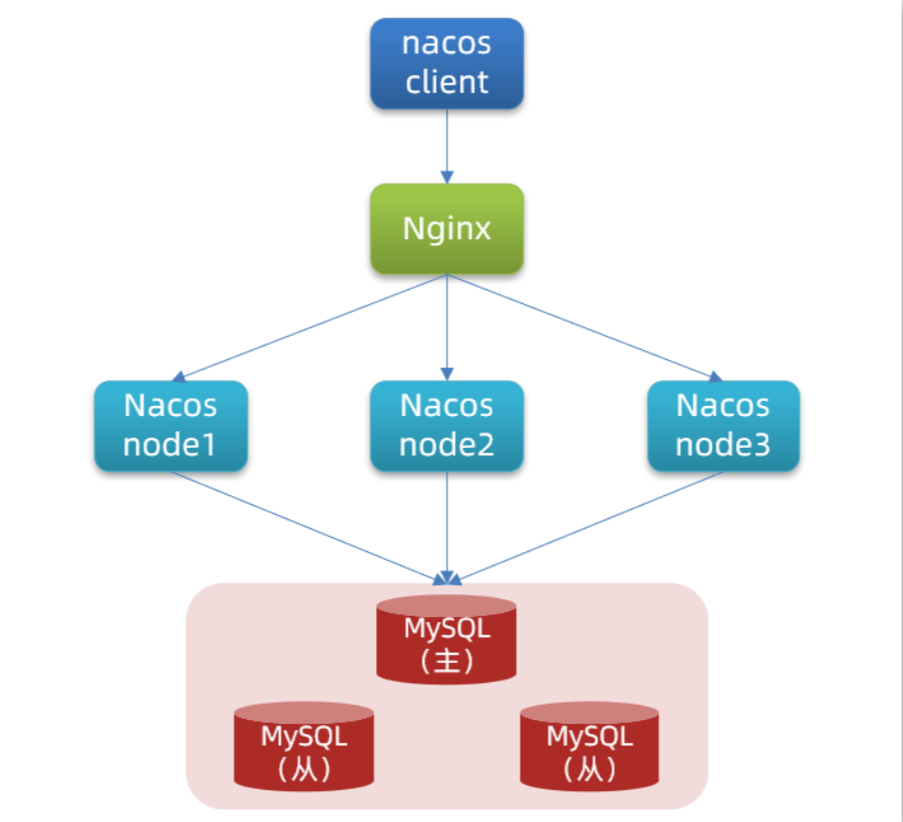
上面这个图是一个基础的Mysql的主从架构,1主1备3从。这种架构是客户端主动做的负载均衡,数据库的连接信息一般是放到客户端的连接层,也就是说由客户端来选择数据库进行读写

上图是一个带proxy的主从架构,客户端只和proxy进行连接,由proxy根据请求类型和上下文决定请求的分发路由。
两种架构方案各有什么特点:
1.客户端直连架构,由于少了一层proxy转发,所以查询性能会比较好点儿,架构简单,遇到问题好排查。但是这种架构,由于要了解后端部署细节,出现主备切换,库迁移的时候客户端都会感知到,并且需要调整库连接信息
2.带proxy的架构,对客户端比较友好,客户端不需要了解后端部署细节,连接维护,后端信息维护都由proxy来完成。这样的架构对后端运维团队要求比较高,而且proxy本身也要求高可用,所以整体架构相对来说比较复杂
但是不论使用哪种架构,由于主从之间存在延迟,当一个事务更新完成后马上发起读请求,如果选择读从库的话,很有可能读到这个事务更新之前的状态,我们把这种读请求叫做过期读。出现主从延迟的情况有多种,有兴趣的同学可以自己了解一下,虽然出现主从延迟我们同样也有应对策略,但是不能100%避免,这些不是我们本次讨论的范围,我们主要讨论一下如果出现主从延迟,刚好我们的读走的都是从库,我们应该怎么应对?
首先我把应对的策略总结一下:
- 强制走主库
- sleep方案
- 判断主从无延迟
- 等主库位点
- 等GTID方案
接下来基于上述的几种方案,我们逐个讨论一下怎么实现和有什么问题。
二、主从同步
在开始介绍主从延迟解决方案前先简单的回顾一下主从的同步

上图表示了一个update语句从节点A同步到节点B的完整过程
备库B和主库A维护了一个长连接,主库A内部有一个线程,专门用来服务备库B的连接。一个事务日志同步的完整流程是:
1.在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量。
2.在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是图中的 io_thread 和 sql_thread。
3.其中 io_thread 负责与主库建立连接。
4.主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。备库 B 拿到 binlog 后,写到本地文件,称为中转日志(relay log)。
5.sql_thread 读取中转日志,解析出日志里的命令,并执行。
上图中红色箭头,如果用颜色深浅表示并发度的话,颜色越深并发度越高,所以主从延迟时间的长短取决于备库同步线程执行中转日志(图中的relay log)的快慢。总结一下可能出现主从延迟的原因:
1.主库并发高,TPS大,备库压力大执行日志慢
2.大事务,一个事务在主库执行5s,那么同样的到备库也得执行5s,比如一次性删除大量的数据,大表DDL等都是大事务
3.从库的并行复制能力,Msyql5.6之前的版本是不支持并行复制的也就是上图的模型。并行复制也比较复杂,就不在这儿赘述了,大家可以自行复习了解一下。
三、主从延迟解决方案
1.强制走主库
这种方案就是要对我们的请求进行分类,通常可以将请求分成两类:
1.对于必须要拿到最新结果的请求,可以强制走主库
2.对于可以读到旧数据的请求,可以分配到从库
这种方案是最简单的方案,但是这种方案有一个缺点就是,对于所有的请求都不能是过期读的请求,那么所有的压力就又来到了主库,就得放弃读写分离,放弃扩展性
2.sleep方案
sleep方案就是每次查询从库之前都先执行一下:select sleep(1),类似这样的命令,这种方式有两个问题:
1.如果主从延迟大于1s,那么依然读到的是过期状态
2.如果这个请求可能0.5s就能在从库拿到结果,仍然要等1s
这种方案看起来十分的不靠谱,不专业,但是这种方案确实也有使用的场景。
之前在做项目的时候,有这样么一种场景,就是我们先写主库,写完后,发送一个MQ消息,然后消费方接到消息后,调用我们的查询接口查数据,当然我们也是读写分离的模式,就出现了查不到数据的情况,这个时候建议消费方对消息进行一个延迟消费,比如延迟30ms,然后问题就解决了,这种方式类似sleep方案,只不过把sleep放到了调用方
3.判断主从无延迟方案
- 命令判断
show slave status,这个命令是在从库上执行的,执行的结果里面有个seconds_behind_master字段,这个字段表示主从延迟多少s,注意单位是秒。所以这种方案就是通过判断当前这个值是否为0,如果为0则直接查询获取结果,如果不为0,则一直等待,直到主从延迟变为0
因为这个值是秒级的,但是我们的一些场景下是毫秒级的请求,所以通过这个方式判断,不是特别精确
- 对比位点判断主从无延迟

上图是执行一次show slave status 部分结果
- Master_Log_File和Read_Master_Log_Pos表示读到的主库的最新的位点
- Relay_Master_Log_File和Exec_Master_Log_Pos表示备库执行的最新的位点
如果Master_Log_File和Relay_Master_Log_File,Read_Master_Log_Pos和Exec_Master_Log_Pos这两组值完全一致,表示主从之间是没有延迟的
3)对比GTID判断主从无延迟
- Auto_Position:1表示这对主从之间启用了GTID协议
- Retrieved_Gtid_Set:表示从库接收到的所有的GTID的集合
- Executed_Gtid_Set:表示从库执行完成的所有的GTID集合
通过比较Retrieved_Gtid_Set和Executed_Gtid_Set集合是否一致,来确定主从是否存在延迟。
可见对比位点和对比GTID集合,比sleep要准确一点儿,在查询之前都可以先判断一下是否接收到的日志都执行完成了,虽然准确度提升了,但是还达不到精确,为啥这么说呢?
先回顾一下binlog在一个事物下的状态
1.主库执行完成,写入binlog,反馈给客户端
2.binlog被从主库发送到备库,备库接收到日志
3.备库执行binlog
我们上面判断主备无延迟方案,都是判断备库收到的日志都执行过了,但是从binlog在主备之间的状态分析,可以看出,还有一部分日志处于客户端已经收到提交确认,但是备库还没有收到日志的状态

这个时候主库执行了3个事物,trx1,trx2,trx3,其中
- trx1,trx2已经传到从库,并且从库已经执行完成
- trx3主库已经执行完成,并且已经给客户端回复,但是还没有传给从库
这个时候如果在从库B执行查询,按照上面我们判断位点的方式,这个时候主从是没有延迟的,但是还查不到trx3,严格说就是出现了"过期读"。那么这个问题有什么方法可以解决么?
要解决这个问题,可以引入半同步复制,也就是semi-sync repliacation(参考:https://dev.mysql.com/doc/refman/8.0/en/replication-semisync.html)。
可以通过
show variables like '%rpl_semi_sync_master_enabled%'
show variables like '%rpl_semi_sync_slave_enabled%'
这两个命令来查看主从是否都开启了半同步复制。
semi-sync做了这样的设计:
1.事物提交的时候,主库把binlog发给从库
2.从库接收到主库发过来的binlog,给主库一个ack确认,表示收到了
3.主库收到这个ack确认后,才给客户端返回一个事物完成的确认
也就是启用了semi-sync,表示所有返回给客户端已经确认完成的事物,从库都收到了binlog日志,这样通过semi-sync配合判断位点的方式,就可以确定在从库上的查询,避免了过期读的出现。
但是semi-sync配合判断位点的方式,只适用一主一备的情况,在一主多从的情况下,主库只要收到一个从库的ack确认,就给客户端返回事物执行完成的确认,这个时候在从库上执行查询就有两种情况
- 如果查询刚好是在给主库响应ack确认的从库上,那么可以查询到正确的数据
- 但是如果请求落到其他的从库上,他们可能还没收到日志,所以依然可能存在过期读
其实通过判断同步位点或者GTID集合的方案,还存在一个潜在的问题,就是业务高峰期,主库的位点或者GITD集合更新的非常快,那么两个位点的判断一直不相等,很可能出现从库一直无法响应查询请求的情况。
上面的两种方案在靠谱程度和精确性上都差了一点儿,接下来介绍两种相对靠谱和精确一点儿的方案
4.等主库位点
要理解等主库位点,先介绍一条命令
select master_pos_wait(file, pos[, timeout]);
这条命令执行的逻辑是:
1.首先是在从库执行的
2.参数file和pos是主库的binlog文件名和执行到的位置
3.timeout参数是非必须,设置为正整数N,表示这个函数最多等到N秒
这个命令执行结果M可能存在的情况:
- M>0表示从命令执行开始,到应用完file和pos表示的binlog位置,一共执行了M个事务
- 如果执行期间,备库的同步线程发生异常,则返回null
- 如果等待超过N秒,返回-1
- 如果刚开始执行的时候,发现已经执行了过了这个pos,则返回0
当一个事务执行完成后,我们要马上发起一个查询请求,可以通过下面的步骤实现:
1.当一个事务执行完成后,马上执行show master status,获取主库的File和Position

2.选择一个从库执行查询
3.在从库上执行 select master_pos_wait(File,Poistion,1)
4.如果返回的值>=0,则在这个从库上执行
5.否则回主库查询
这里我们假设,这条查询请求在从库上最多等待1s,那么如果1s内master_pos_wait返回一个大于等于0的数,那么就能保证在这个从库上能查到刚执行完的事务的最新的数据。
上述的步骤5是这类方案的兜底方案,因为从库的延迟时间不可控,不能无限等待,所以如果超时,就应该放弃,到主库查询。
可能有同学会觉的,如果所有的延迟都超过1s,那么所有的压力都到了主库,确实是这样的,但是按照我们设定的不允许出现过期读,那么就只有两种选择,要么超时放弃,要么转到主库,具体选择哪种,需要我们根据业务进行具体的分析。
5.等GTID方案
如果数据库开启的GTID模式,那么相应的也有等GTID的方案
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑是:
1.等待,直到这个库执行的事务中包含传入的giid_set集合,返回0
2.超时返回1
在前面等待主库位点的方案中,执行完事务后,需要到主库执行show master status。从mysql5.7.6开始,允许事务执行完成后,把这个事务执行的GTID返回给客户端,这样等待GTIID的方案就减少了一次查询。
这时等GTID方案的流程就变成这样:
1.事务执行完成后,从返回包解析获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询
3.在从库上执行select wait_for_executed_gtid_set(gtid1,1)
4.如果返回0,则在这个从库上执行查询
5.否则回到主库查询
和等待主库位点方案一样,最后的兜底方案都是转到主库查询了,需要综合业务考虑确定方案
上面的事物执行完成后,从返回的包中解析GTID,mysql其实没有提供对应的命令,可以参考Mysql提供的api(https://dev.mysql.com/doc/c-api/8.0/en/mysql-session-track-get-first.html),在我们的客户端可以调用这个函数获取GTID
四、总结
以上简单介绍了读写分离架构,和出现主从延迟后,如果我们用的读写分离的架构,那么我们应该怎么处理这种情况,相信在日常我们的主从还是或多或少的存在延迟。上面介绍的几种方案,有些方案看上去十分不靠谱,有些方案做了一些妥协,但是都有实际的应用场景,需要我们根据自身的业务情况,合理选择对应的方案。
但话说回来,导致过期读的本质还是一写多读导致的,在实际的应用中,可能有别的不用等待就可以水平扩展的数据库方案,但这往往都是通过牺牲写性能获得的,也就是需要我们在读性能和写性能之间做个权衡。
文中有不太严谨或者错误的地方还望大家多多指正。
作者:京东零售 尚有智
来源:京东云开发者社区 转载请注明来源





![java八股文面试[JVM]——JVM性能优化](https://img-blog.csdnimg.cn/img_convert/944a51e6faf749f92a3778a203c66a1b.png)