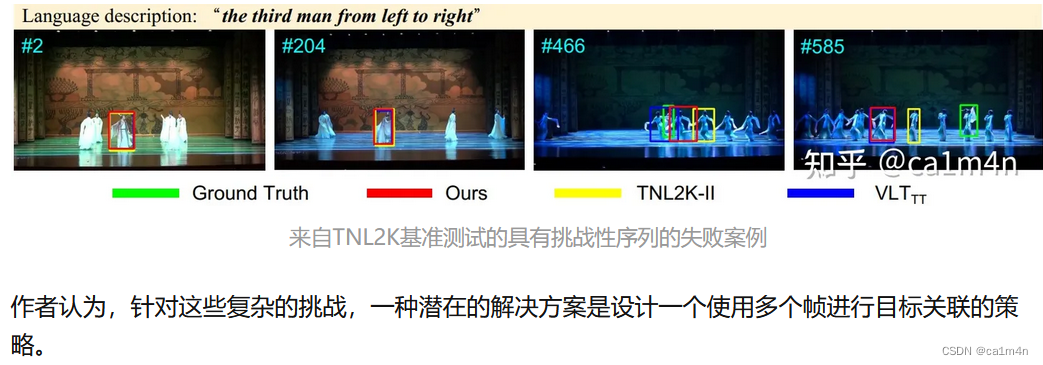
作品展示
1、使用15:15CM彩色手工纸打印(25*25的纸超过21CM的边,打印机放不下),
2、打开选择CAJ阅读器
3、纸张放在纸屉内,用三个架子缩小页面
4、哎,大不了,换不了纸

一、利用midjounery获得简笔画样式的“动物面具
Top view,Ladybug , simple stroke, cartoon, black and white outline, uncolored
NIJI 5


二、图片切割
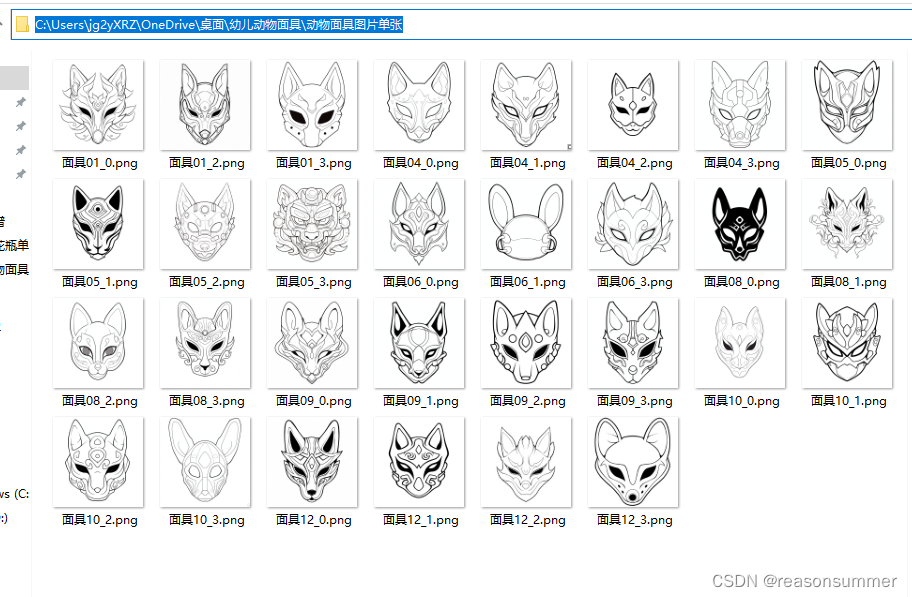
用以下代码把上面文件夹里所有的2048*2048的单张图片切割程2*2
# 参考网址:https://blog.csdn.net/weixin_42182534/article/details/125773141?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E6%88%AA%E5%8F%96%E5%9B%BE%E7%89%87%E7%9A%84%E4%B8%80%E9%83%A8%E5%88%86&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-125773141.nonecase&spm=1018.2226.3001.4187
'''
功能:把midjounery 3*3方形矩阵,5*4矩阵、3*5矩阵切割 通用公式)
作者:阿夏
时间:2023年6月26日 19:51
'''
import os
import os.path
from PIL import Image
long=int(input('图片长度像素(1024)\n'))
wide=int(input('图片宽度像素(1024)\n'))
small_long=int(input('长边切分4(4*3)\n'))
small_wide=int(input('宽边切分3(4*3)\n'))
# 目前图片都是2*2,3*3排列
# 1:1图比例是2048
# 16:9图片比例 2912:1632
wj=input('文件夹名称\n')
z=0
longall=[]
longall.append(z)
for l in range(1,small_long+1):
ll=float(long/small_long*l)
longall.append(ll)
print(longall)
# 右侧边的所有参数 长/X
# [0, 512, 1024, 1536, 2048]
wideall=[]
wideall.append(z)
for w in range(1,small_wide+1):
ww=float(wide/small_wide*w)
wideall.append(ww)
print(wideall)
# 下边的所有参数 宽/X
# [0, 682.6666666666666, 1365.3333333333333, 2048.0]
pic=[]
for x in range(0,small_wide):
for y in range(0,small_long):
z1=longall[y]
z2=wideall[x]
z3=longall[y+1]
z4=wideall[x+1]
pic.append(z1)
pic.append(z2)
pic.append(z3)
pic.append(z4)
print(len(pic))
# # 4*3图为例hang
# 第1行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[0]
# z3=longall[1] [2] [3] [4]
# z4=wideall[1]
# 第2行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[1]
# z3=longall[1] [2] [3] [4]
# z4=wideall[2]
# 第3行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[2]
# z3=longall[1] [2] [3] [4]
# z4=wideall[3]
# 总结:
# z1=long[0:4] 每张图左侧的坐标会变 ,索引数字不断从0,1/4,2/4,3/4
# z2=宽数量 宽的索引,不断增加
# z3=long[0+1:4+1] 每张图右侧 索引数+1 从1/4,2/4,3/4,4/4(=长)20
# z4=宽+1 宽的索引+1
# 定义文件所在文件夹
image_dir = r'C:\Users\jg2yXRZ\OneDrive\桌面\{}'.format(wj)
for parent, dir_name, file_names in os.walk(image_dir): # 遍历每一张图片
for filename in file_names:
print(filename)
pic_name = os.path.join(parent, filename)
image = Image.open(pic_name)
_width, _height = image.size
print(_width, _height)
qfall=4
# 每张图有4个坐标
n=0
for p in range(int(len(pic)/4)):
pp=pic[p*4:p*4+4]
print(pp)
# 定义裁剪范围(left, upper, right, lower)1024
# # box = image.crop((0,0,123,123))
box = image.crop((pp[0],pp[1],pp[2],pp[3]))
name = filename[:-4]+'_'+str(n) +'.png'
print(name)
# # # ,pp[3],pp[4],pp[5],pp[6],pp[7],pp[8],pp[9]))
# # name = filename[:-4]+'_'+str(p) +'.png'2048
box.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\{}\{}'.format(wj,name))
n+=1
# print('Done!')

把切割好的图片,挑选符合要求的放到”动物面具图片单张“

三、学具生成
文件夹准备:
第1类:正方形15*15厘米手工纸
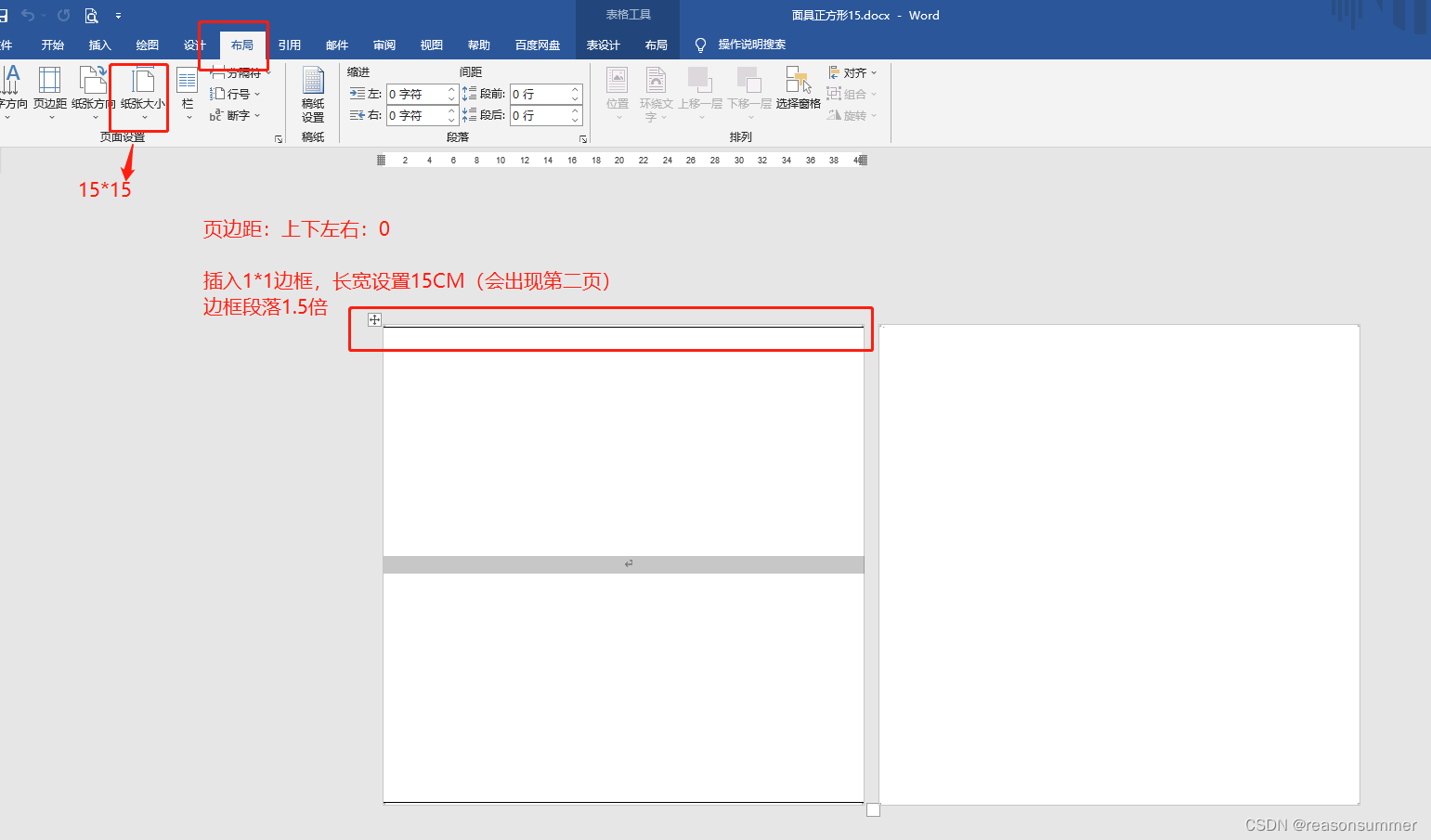
一个面具图片插入一个框,图案尽量放到最大。
# '''
# 15*15正方形手工纸面具
# 目的:动物面具(挖空)
# 作者:阿夏
# 时间:2023年7月7日17:27)
# '''
print('----------第1步:提取所有的幼儿照片的路径------------')
import os
path=[]
p=r"C:\Users\jg2yXRZ\OneDrive\桌面\幼儿动物面具\动物面具图片单张"
# 过滤:只保留png结尾的图片 31张(多几张备用)
imgs=os.listdir(p)
for img in imgs:
if img.endswith(".png"):
path.append(p+'\\'+img)
# 所有图片的路径
print(path)
# 提取动物名字倒数第4个字之前的动物名字
print(imgs)
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\幼儿动物面具\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# # from docx.enum.text import WD_VERTICAL_ALIGNMENT
# from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT #用来设置单元格垂直对齐方式
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,int(len(path))): # 读取图片的全路径 的数量 31张
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\幼儿动物面具\面具正方形15.docx')
figures=path[nn] # 图片的全路径的第一张
table = doc.tables[0] # 4567(8)行
#
# 写入照片
run=doc.tables[0].cell(0,0).paragraphs[0].add_run() # # 图片位置 第一个表格的0 3 插入照片
run.add_picture(r'{}'.format(figures),width=Cm(15),height=Cm(15))
table.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\幼儿动物面具\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/幼儿动物面具/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/幼儿动物面具/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/幼儿动物面具/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/幼儿动物面具/(打印合集)动物面具15制作({}人共{}份).pdf".format(len(path),len(path)))
file_merger.close()
# doc.Close()
# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/幼儿动物面具/零时Word') #递归删除文件夹,即:删除非空文件夹
效果展示:


(以上是15*15彩色手工纸打印(打印时需要对打印机参数进行设置)
图案最高长度:15CM
感悟:
1、WORD模板出现第二页,我都会想尽办法调整段落(固定值1磅)来消除第2页,今天发现完全可以默认第二页的存在,只要确保第二页为空白,。在打印时,注意选择:奇数页打印,或者默认双面打印,也同样可以获得一张学具。
2、MJ的图案很丰富多样,有些面具眼睛部分还是需要教师手画××,提示幼儿镂空剪。
3、每个面具不一定正好符合幼儿的眼距。教学实验一次后,再挑选出一些比较实用的的面具图案,
教学目的:
1、自由涂色
2、沿边裁剪
3、面具眼睛部分镂空剪
4、制作“手持面具”、“双面胶黏贴面具”、”头套式面具“
学具打印:
打印机设置





唯一默认,如果纸张尺寸是“”A4,打印默认是A4纸
如果纸张尺寸是15,打印默认15*15,这是唯一一个选择,所以打印完15的纸后,要把纸张尺寸改回A4,否则a4大小的纸张内容只能打印出15*15一小块。
打印过程




修补:部分面具眼睛需要涂成黑色,便于幼儿了解“镂空剪”的位置