【今日】
孩儿立志出乡关,学不成名誓不还。

文件输入/输出流
程序运行期间,大部分数据都在内存中进行操作,当程序结束或关闭时,这些数据将消失。如果需要将数据永久保存,可使用文件输入/输出流与指定的文件建立连接,将需要的数据永久保存到文件中。
一 FilelnputStream与FileOutputStream类
文件字节流
FileInputStream类与FileOutputStream类都用来操作磁盘文件。如果用户的文件读取需求比较简单,则可以使用FileInputStream类,该类继承自InputStream类。FileOutputStream类与 FilelnputStream类对应,提供了基本的文件写入能力。FileOutputStream类是OutputStream类的子类。
FileInputStream类常用的构造方法如下:
😶🌫️FileInputStream(String name)
😶🌫️FileInputStream(File file)第一个构造方法使用给定的文件名name创建一个 FilelnputStream对象,第二个构造方法使用File对象创建 FileInputStream对象。第一个构造方法比较简单,但第二个构造方法允许在把文件连接输入流之前对文件做进一步分析。
FileOutputStream类有与FileInputStream类相同的参数构造方法,创建一个FileOutputStream对象时,可以指定不存在的文件名,但此文件不能是一个已被其他程序打开的文件。
【代码块】输出流
package mt;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt"); //在MyProject下创建文本word.txt
FileOutputStream out = null; //赋予空值
try {
out = new FileOutputStream(f);
String str = "你见过凌晨4点的洛杉矶吗?";
byte b[] = str.getBytes();//字符串转换为字节数组
try {
out.write(b);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally {
if(out !=null) {
try {
out.close();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
}
}还没运行前可以看到左侧的项目中并没有word.txt项目。
 【运行刷新】
【运行刷新】
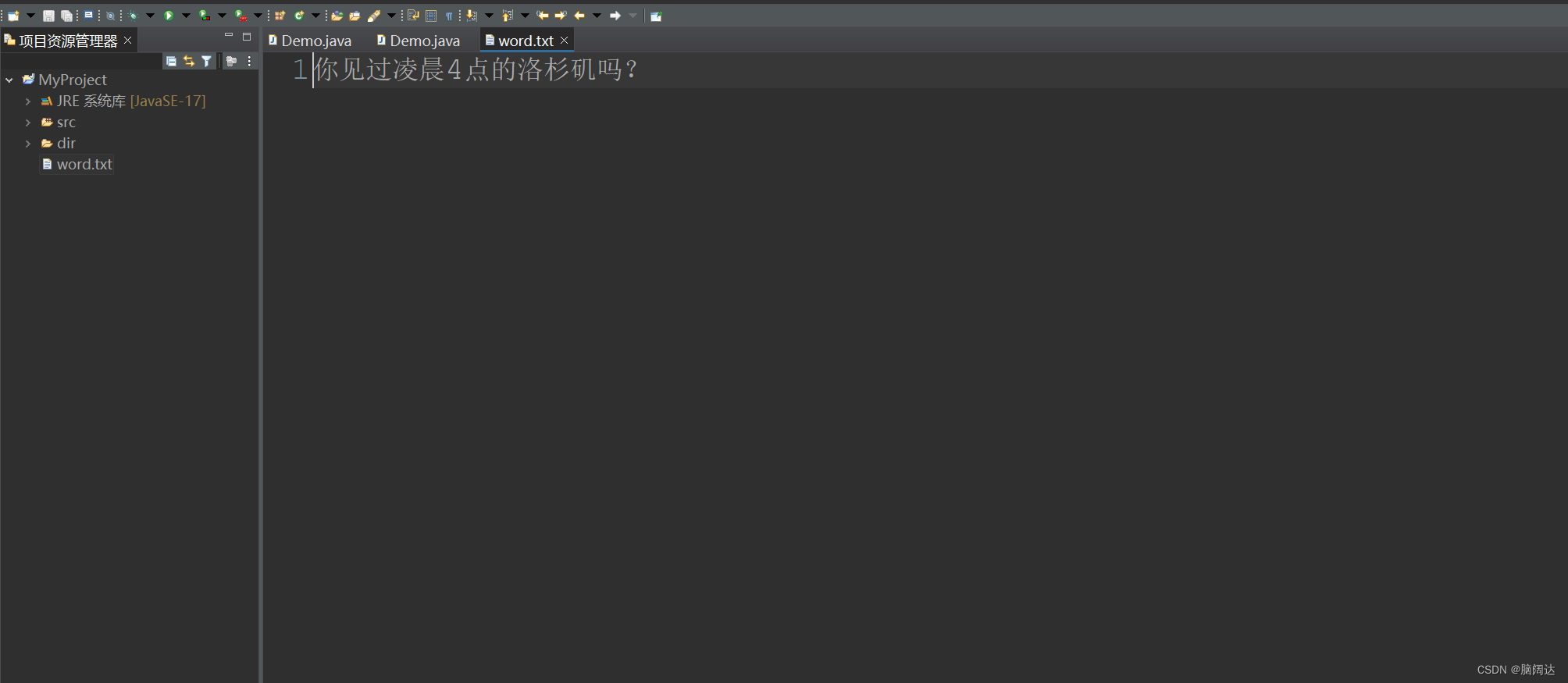
当我们反复向这个文件中写值的时候,它会覆盖前面的内容。
如果我们将out = new FileOutputStream(f);
改为out = new FileOutputStream(f,true):文件输出流,在文件末尾追加内容。
改为out = new FileOutputStream(f,true):文件输出流,替换内容。




【代码】输入流
package mt;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt"); //在MyProject下创建文本word.txt
FileOutputStream out = null; //赋予空值
try {
out = new FileOutputStream(f,false);
String str = "你见过凌晨4点的洛杉矶吗?";
byte b[] = str.getBytes();//字符串转换为字节数组
try {
out.write(b);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally {
if(out !=null) {
try {
out.close();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
FileInputStream in = null;
try {
in = new FileInputStream(f);//输入流读取文件
byte b2[] = new byte[1024];//创建缓冲区
in.read(b2);//将文件信息读入缓存数组中
System.out.println("文本中的内容是:"+new String(b2));
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in!=null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
【运行结果】
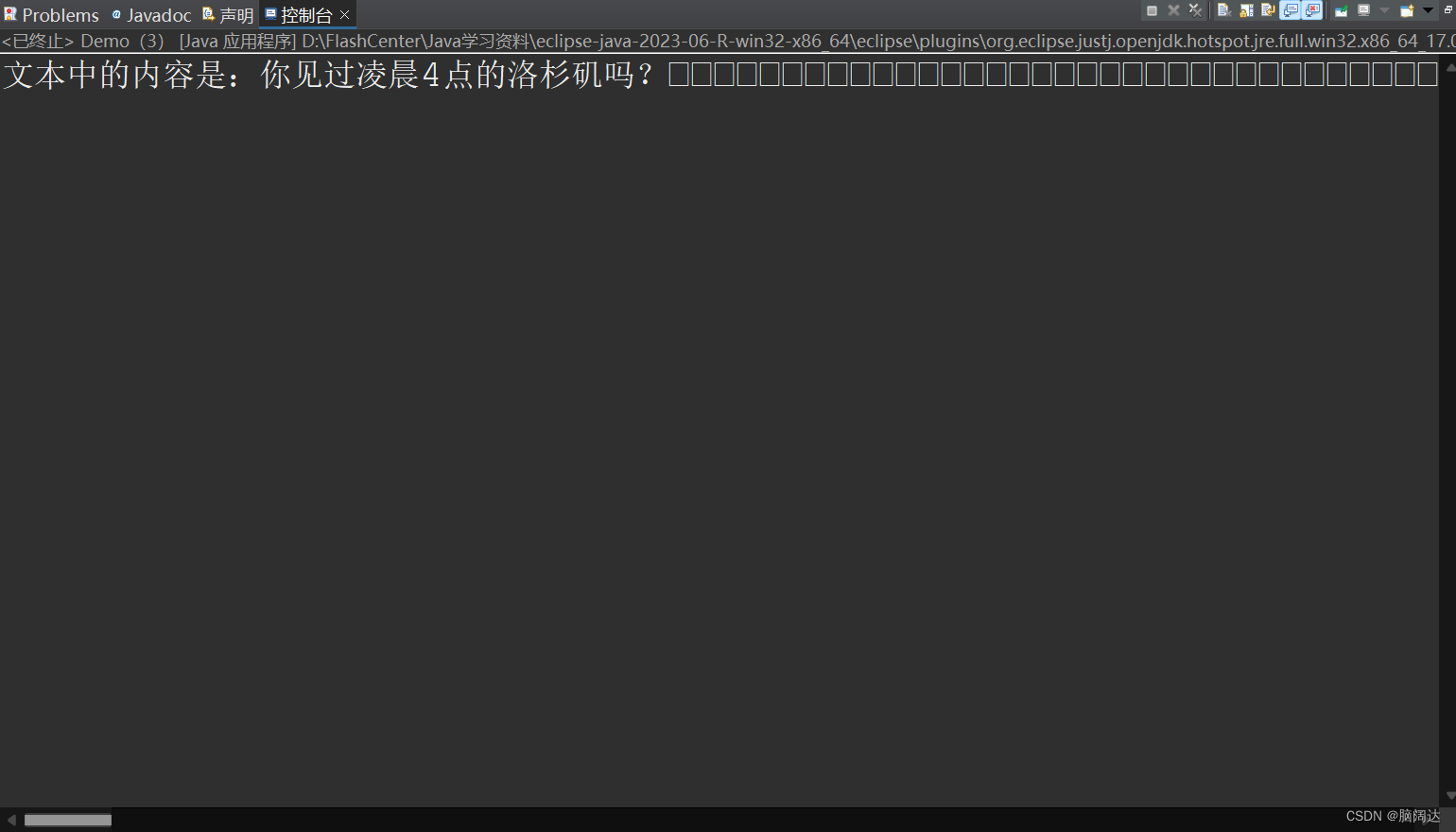
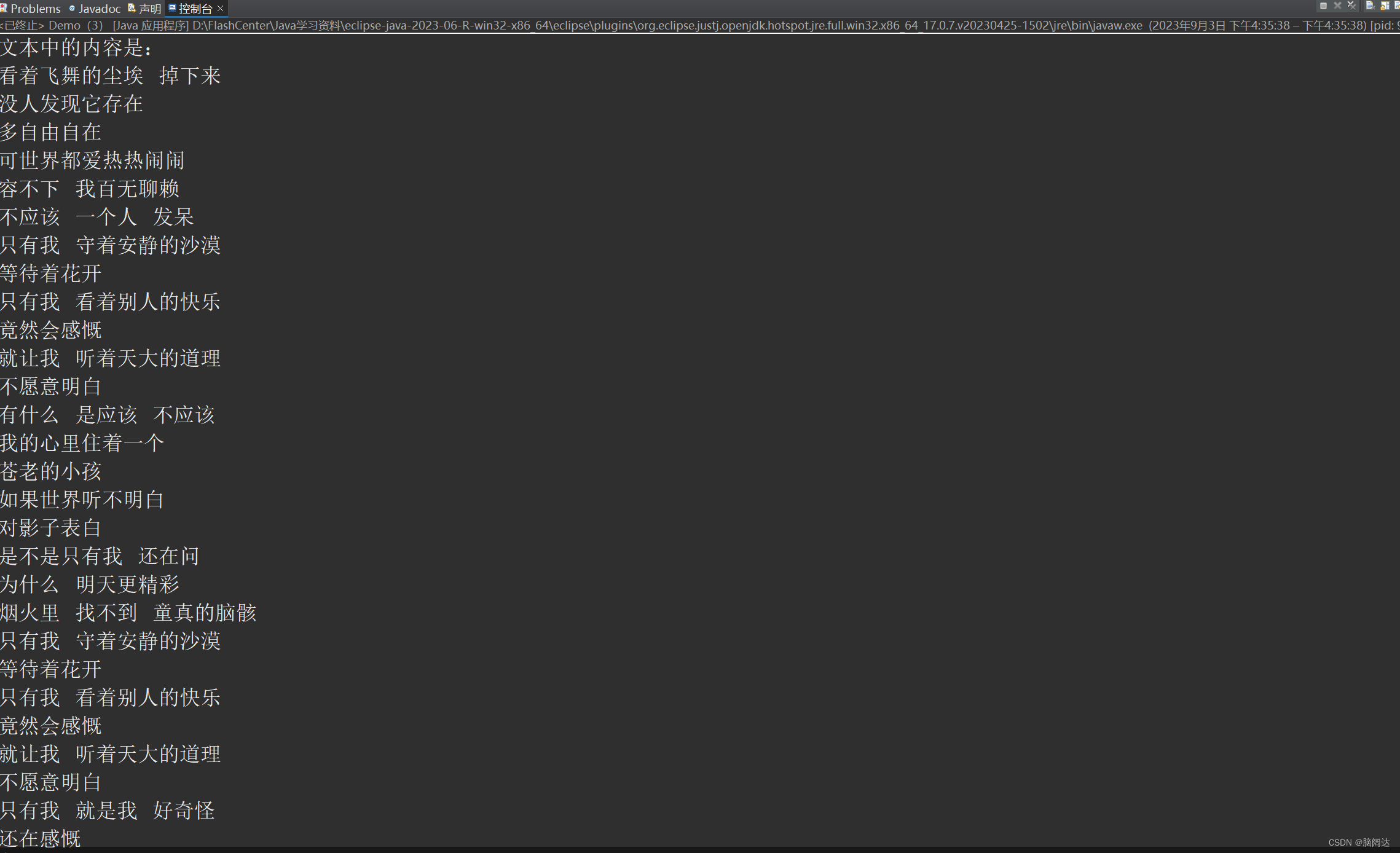
观察运行结果我们可以发现输出文本内容后,后面还跟了一串空格,这是因为我们创建的缓冲区字节数是1024远远大于这些汉字所占用的字节,如何去除这些空格呢?
我们可以这样做:
这样做是因为in.read()可以返回所读取的数组的总长度,在让它从索引0到len进行输出就可以 去除空格,看一下运行结果:

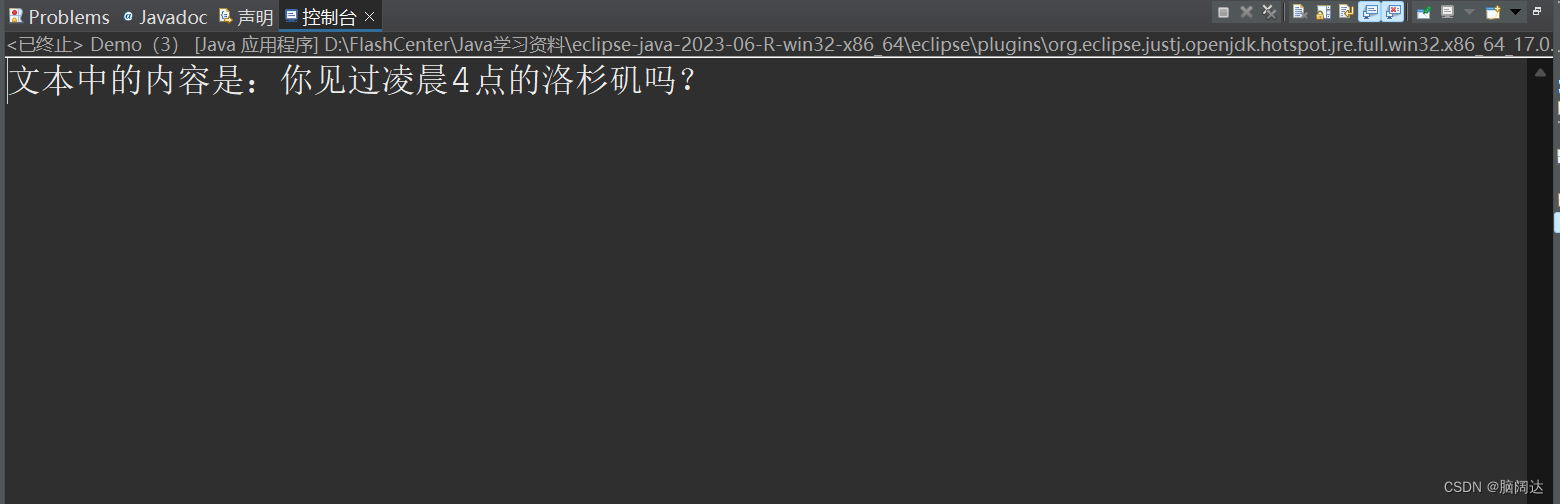
我们也可以直接对文本的内容进行修改,只用输入流进行输出:
我们先在word.txt里面写入歌词:
【运行的代码】
package mt;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt"); //在MyProject下创建文本word.txt
FileInputStream in = null;
try {
in = new FileInputStream(f);//输入流读取文件
byte b2[] = new byte[1024];//创建缓冲区
int len = in.read(b2);//读入缓冲区的总字节数
System.out.println("文本中的内容是:\n"+new String(b2,0,len));
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in!=null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}【运行结果】
二 FileReader和 FileWriter 类
文件字符流
使用FileOutputStream类向文件中写入数据与使用FileInputStream类从文件中将内容读出来,都存在一点不足,即这两个类都只提供了对字节或字节数组的读取方法。由于汉字在文件中占用两个字节,如果使用字节流,读取不好可能会出现乱码现象,此时采用字符流FileReader类或 FileWriter类即可避免这种现象。
FileReader类和 FileWriter类对应了 FilelnputStream类和 FileOutputStream类。FileReader类顺序地读取文件,只要不关闭流,每次调用read(方法就顺序地读取源中其余的内容,直到源的末尾或流被关闭。

【代码】输出流
package mt;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt");
FileWriter fw = null;
try {
fw = new FileWriter(f);
String str ="只是一场烟火散落的尘埃";
fw.write(str);
} catch (IOException e) {
e.printStackTrace();
}finally {
if(fw!=null) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
【运行结果】 
【代码】输入流
package mt;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt");
FileReader fr = null;
try {
fr = new FileReader(f);
char ch[] = new char[1024];
int len = fr.read(ch);
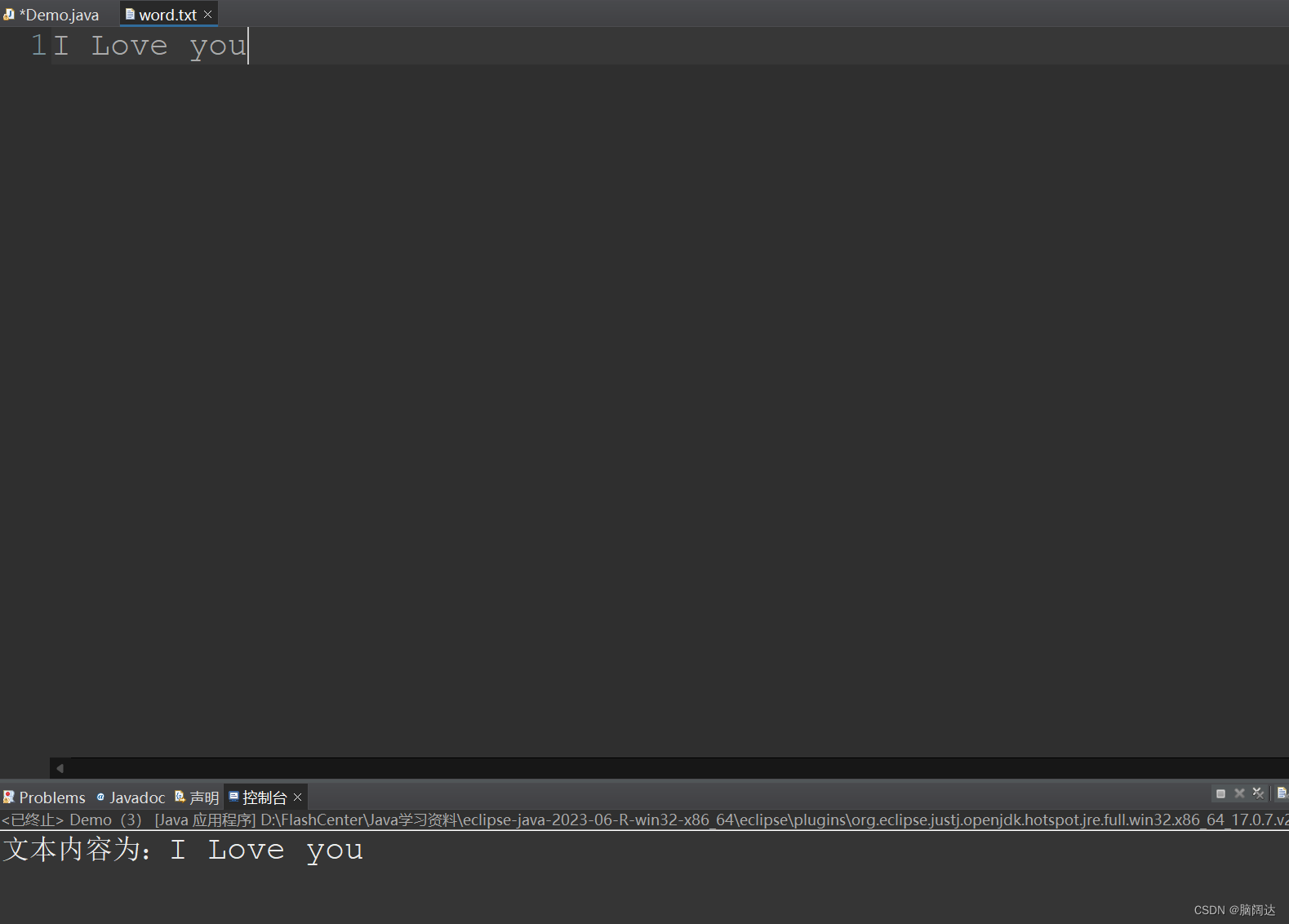
System.out.println("文本内容为:"+new String(ch,0,len));
} catch (IOException e) {
e.printStackTrace();
}finally {
if(fr!=null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}【运行结果】
带缓存的输入/输出流
首先我们了解一下什么是缓冲区:
我们要将一推箱子由A运到B地,如果我们派人一次一次的去搬运,是十分慢的。如果直接用货车运输,那么方便许多。这里货车就充当了缓冲区的功能。

缓存是I/O的一种性能优化。缓存流为I1O流增加了内存缓存区,使得在流上执行skip)、mark()和reset()方法都成为可能。
一 BufferedInputStream与 BufferedOutputStream类
缓冲字节流
BufferedInputStream 类可以对所有InputStream类进行带缓存区的包装以达到性能的优化。BufferedInputStream类有两个构造方法:
1.BufferedInputStream(InputStream in)
2.BufferedInputStream(InputStream in,int size)第一种形式的构造方法创建了一个有32个字节的缓存区。
第二种形式的构造方法按指定的大小来创建缓存区。
一个最优的缓存区的大小,取决于它所在的操作系统、可用的内存空间以及机器配置。从构造方法可以看出,BufferedInputStream对象位于InputStream类对象之后。
BufferedInputStream读取文件过程 
使用 BufferedOutputStream类输出信息和仅用OutputStream类输出信息完全一样,只不过BufferedOutputStream有一个flush)方法用来将缓存区的数据强制输出完。BufferedOutputStream类也有两个构造方法:
BufferedOutputStream(OutputStream in)。
BufferedOutputStream(OutputStream in,int size)。
第一种构造方法创建一个有32个字节的缓存区。第二种构造方法以指定的大小来创建缓存区。
缓冲输入流
不使用缓存区效果:
【代码】
package mt;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("D:\\FlashCenter\\歌词.txt");
FileInputStream in = null;
long start = System.currentTimeMillis();//获取流开始的毫秒值
try {
in = new FileInputStream(f);
byte b[] = new byte[1024];//缓冲区字节数组(这个缓冲区与Buffered不同)
while(in.read()!=-1) {//当有值时循环输出
}
long end = System.currentTimeMillis();//获取流结束的毫秒值
System.out.println("运行经历的毫秒数:"+(end-start));
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in !=null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
【 运行效果】
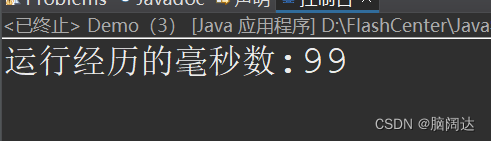
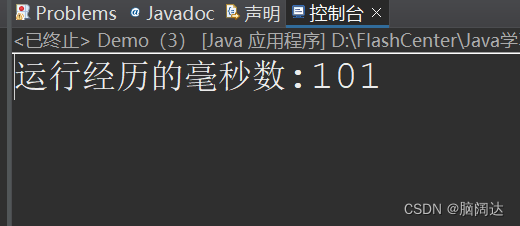
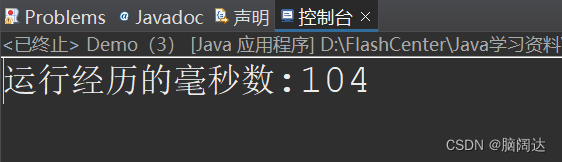
使用缓冲流效果:
【代码】
package mt;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("D:\\FlashCenter\\歌词.txt");
FileInputStream in = null;
BufferedInputStream bi = null;
long start = System.currentTimeMillis();//获取流开始的毫秒值
try {
in = new FileInputStream(f);
bi = new BufferedInputStream(in);//将文件字节流包装成缓冲字节流
byte b[] = new byte[1024];//缓冲区字节数组(这个缓冲区与Buffered不同)
while(bi.read()!=-1) {//当有值时循环输出
}
long end = System.currentTimeMillis();//获取流结束的毫秒值
System.out.println("运行经历的毫秒数:"+(end-start));
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in !=null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bi!=null) {
try {
bi.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}【 运行效果】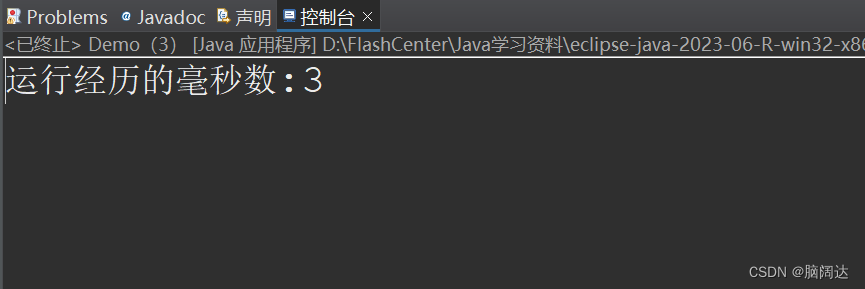
从运行效果来看,可以看出大大的提高了运行的效率。
缓冲输出流
【代码】
package mt;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo2 {
public static void main(String[] args) {
File f =new File("word.txt");
FileOutputStream out = null;
BufferedOutputStream bo = null;
try {
out = new FileOutputStream(f);
bo = new BufferedOutputStream(out);//包装文件输出流
String str = "天生我才必有用,千金散尽还复来!";
byte b[] = str.getBytes();
bo.write(b);//这里也能够提高效率
//使用缓冲字节流输出时,要多进行刷新操作。
bo.flush();//刷新。强制将缓存区数据写入文件,即使缓冲区没有写满。
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}【运行结果】
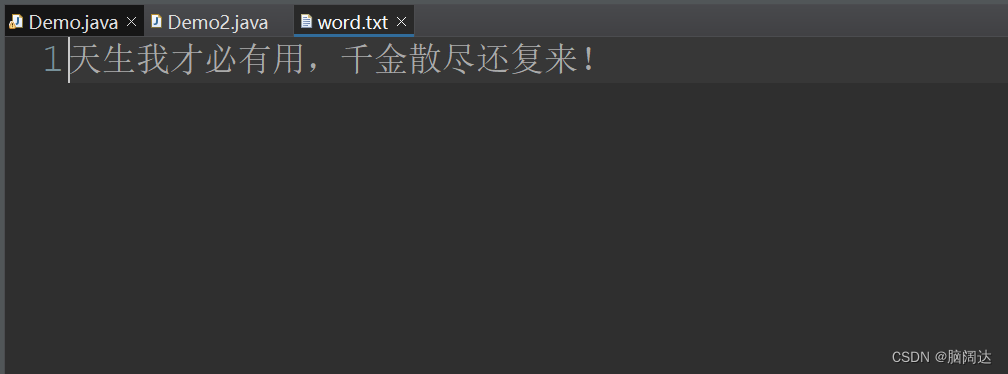
总结:
无论BufferedInputStream与 BufferedOutputStream类,在这里都有提高运行效率的结果。
二 BufferedReader与BufferedWriter类
缓冲字符流
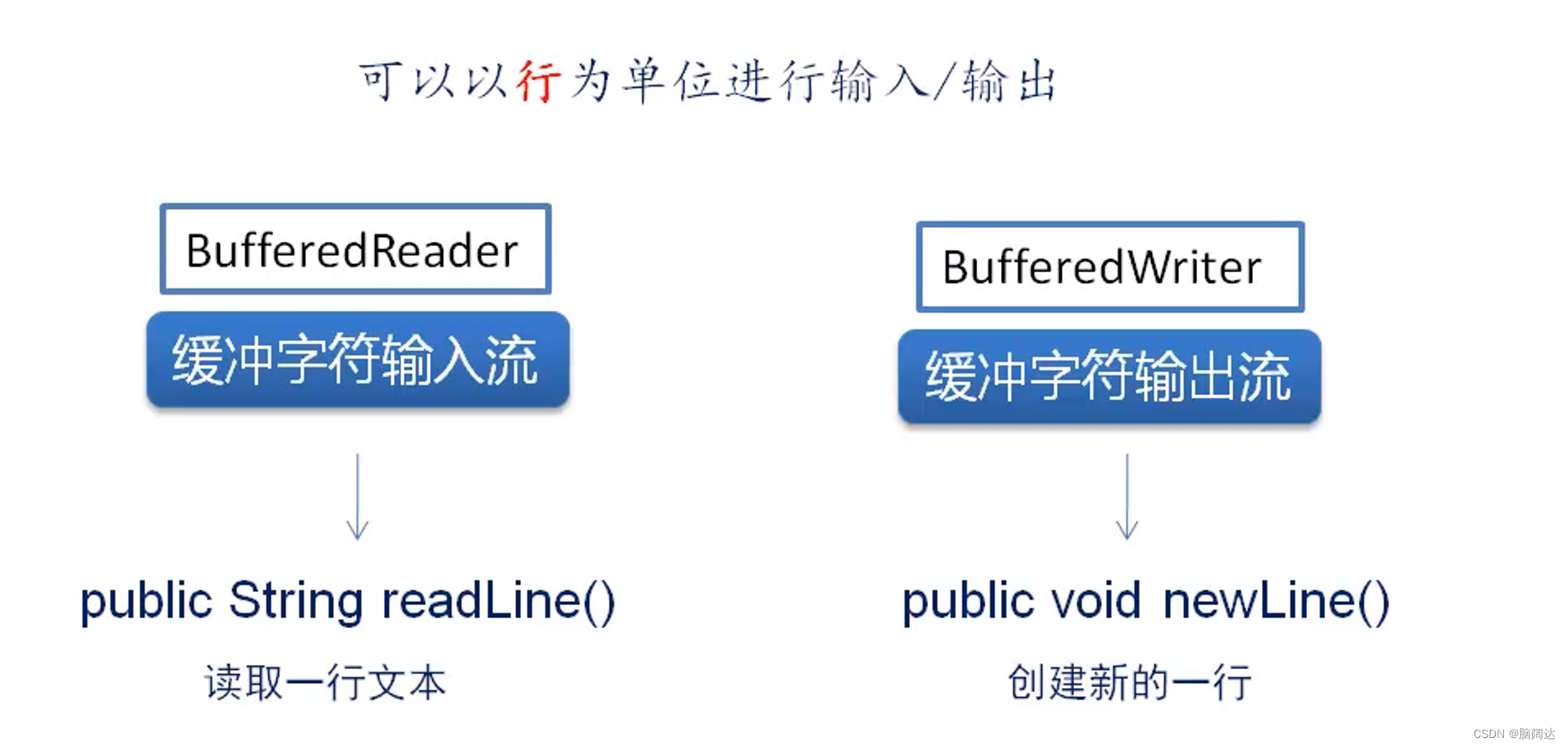
BufferedReader类与BufferedWriter类分别继承Reader类与Writer类。这两个类同样具有内部事机制,并能够以行为单位进行输入/输出。
BufferedReader类常用的方法如下:
read0方法:读取单个字符。
readLine()方法:读取一个文本行,并将其返回为字符串。若无数据可读,则返回null。
BufferedWriter类中的方法都返回void。常用的方法如下:
write(String s,int offint len)方法:写入字符串的某一部分。
flush()方法:刷新该流的缓存。
newLine(方法:写入一个行分隔符。
在使用BufferedWriter类的Write()方法时,数据并没有立刻被写入输出流,而是首先进入缓存区中如果想立刻将缓存区中的数据写入输出流,一定要调用flush)方法。
缓冲字符输出流代码实列:
package mt;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt");
FileWriter fw = null;
BufferedWriter bw = null;
try {
fw = new FileWriter(f);
bw = new BufferedWriter(fw);//将文件字符输出流包装成缓存字符流
String str1 = "世界那么大";
String str2 = "我想去看看";
bw.write(str1);//第一行
bw.newLine();//创建新行
bw.write(str2);//第二行
} catch (IOException e) {
e.printStackTrace();
}finally {//要注意流关闭的顺序,先创建的后关闭
if(bw!=null) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fw!=null) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行效果: 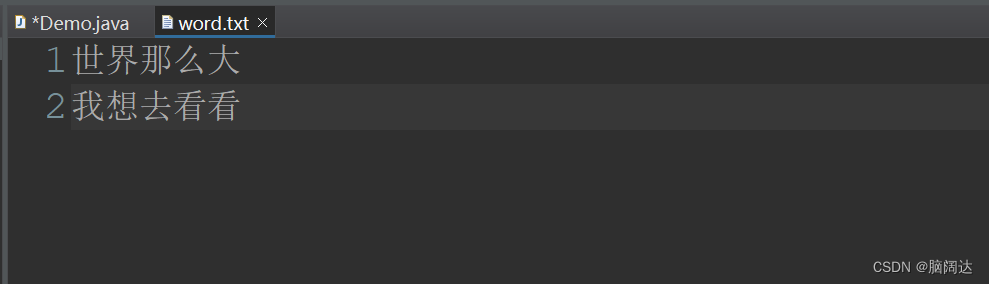
缓冲字符流输入代码实列:
package mt;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt");
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader(f);
br = new BufferedReader(fr);
String tmp = null;
int i = 1;
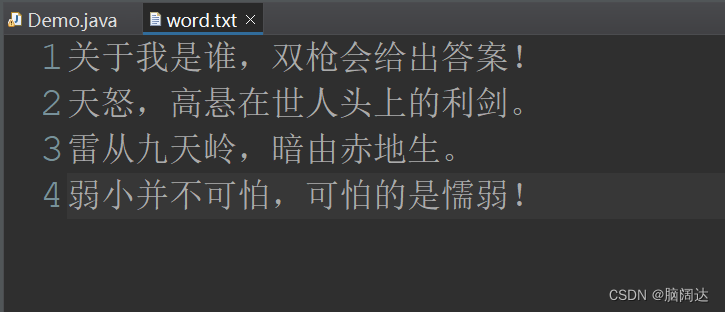
while((tmp = br.readLine())!=null) {//循环读取文件中的内容
System.out.println("第"+i+"行:"+tmp);
i++;
}
br.readLine();//读一行
} catch (IOException e) {
e.printStackTrace();
}finally {
if(br!=null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}if(fr!=null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}运行效果:
文本内容:
输出效果:
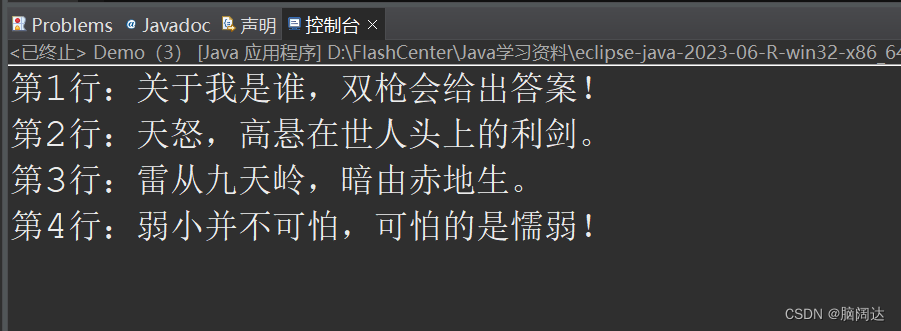
总结:
BufferedReader与BufferedWriter类除了提高效率以外,它还可以以行为单位,来对字符数据进行操作。比如:BufferedReader的readLine()方法,BufferedWriter的newLine()方法。
数据的输入/输出流
数据输入/输出流(DataInputStream类与DataOutputStream类)允许应用程序以与机器无关的方式从底层输入流中读取基本Java数据类型。也就是说,当读取一个数据时,不必再关心这个数值应当是哪种字节。
一 DataInputStream类与DataOutputStream类
DatalnputStream类与DataOutputStream类的构造方法如下。
DataInputStream(InputStream in):使用指定的基础InputStream对象创建一个 DataInputStream对象。
DataOutputStream(OutputStream out):创建一个新的数据输出流,将数据写入指定基础输出流。
DataOutputStream类提供了将字符串、double数据、int数据、boolean数据写入文件的方法。其中,将字符串写入文件的方法有3种,分别是writeBytes(String s)、writeChars(String s)、writeUTF(Strings)。由于Java中的字符是Unicode编码,是双字节的,writeBytes0方法只是将字符串中的每一个字符的低字节内容写入目标设备中;而writeCharsO方法将字符串中的每一个字符的两个字节的内容都写到目标设备中;writeUTFO方法将字符串按照UTF编码后的字节长度写入目标设备,然后才是每一个字节的UTF编码。
DataInputStream类只提供了一个readUTF0方法返回字符串。这是因为要在一个连续的字节流读取一个字符串,如果没有特殊的标记作为一个字符串的结尾,并且不知道这个字符串的长度,就无法知道读取到什么位置才是这个字符串的结束。DataOutputStream类中只有writeUTFO方法向目标设备中写入字符串的长度,所以也能准确地读回写入字符串。
API中的部分方法:
输入流:
输出流:

代码实列:
package mt;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt");
FileOutputStream out = null;
DataOutputStream dos = null;
try {
out = new FileOutputStream(f);
dos = new DataOutputStream(out);//将文件流包装为数据流
dos.writeUTF("这是写入字符串数据。"); //写入字符串数据
dos.writeDouble(3.14); //写入浮点型数据
dos.writeBoolean(false); //写入布尔类型
dos.writeInt(123); //写入整型数据
} catch (IOException e) {
e.printStackTrace();
}finally {
if(out!=null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(dos!=null) {
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}我们运行以后发现运行结果为乱码:

这是因为通过数据输出流写入文本的是字节码,我们想要得到里面的数据就需要用数据输入流将里面的数据读出来。然后通过对应的方法进行解析得到结果。
我们添加上数据的输入流在来进行:
代码如下:
package mt;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
File f = new File("word.txt");
FileOutputStream out = null;
DataOutputStream dos = null;
try {
out = new FileOutputStream(f);
dos = new DataOutputStream(out);//将文件流包装为数据流
dos.writeUTF("这是写入字符串数据。"); //写入字符串数据
dos.writeDouble(3.14); //写入浮点型数据
dos.writeBoolean(false); //写入布尔类型
dos.writeInt(123); //写入整型数据
} catch (IOException e) {
e.printStackTrace();
}finally {
if(out!=null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(dos!=null) {
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
DataInputStream di = null;
FileInputStream in = null;
try {
in = new FileInputStream(f);
di = new DataInputStream(in);
System.out.println("readUTF()读取数据:"+di.readUTF());
System.out.println("readdouble()读取数据:"+di.readDouble());
System.out.println("readBoolean()读取数据:"+di.readBoolean());
System.out.println("readInt()读取数据:"+di.readInt());
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in!=null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(di!=null) {
try {
di.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
} 运行结果: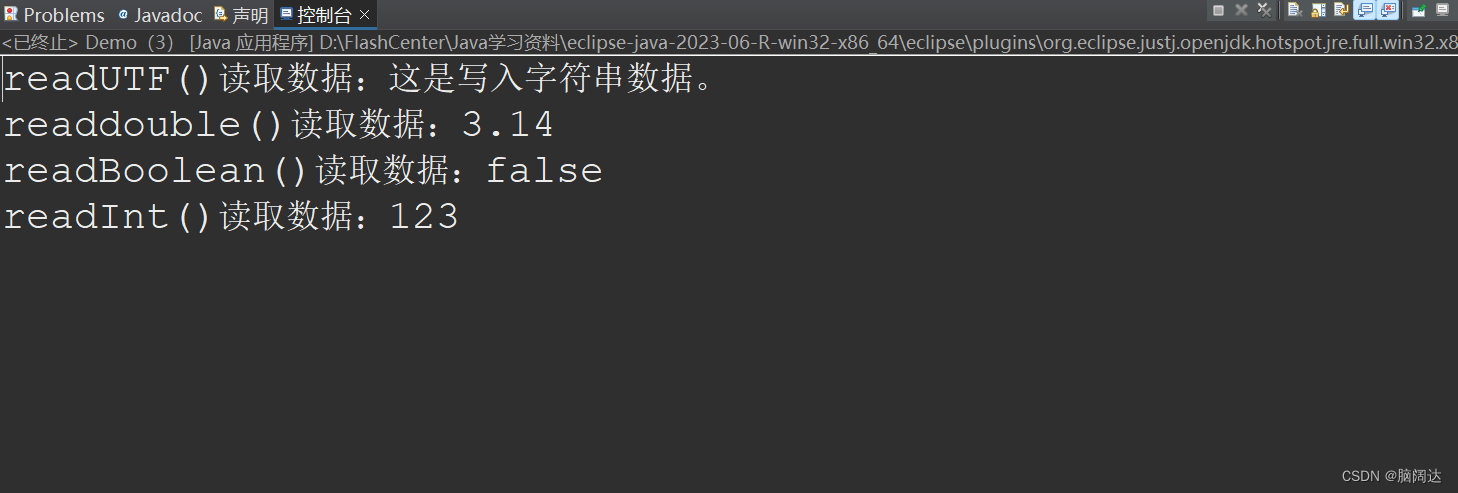
 Thank!
Thank!