目录
C语言内存管理及栈攻击
内存管理
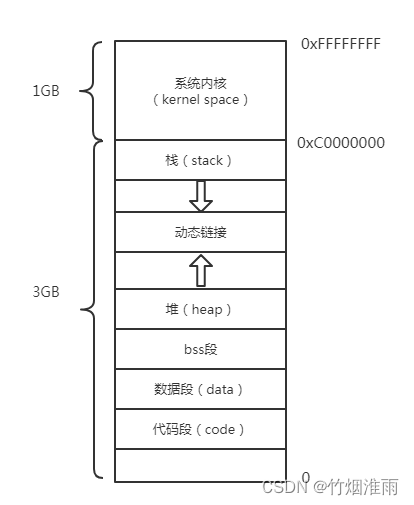
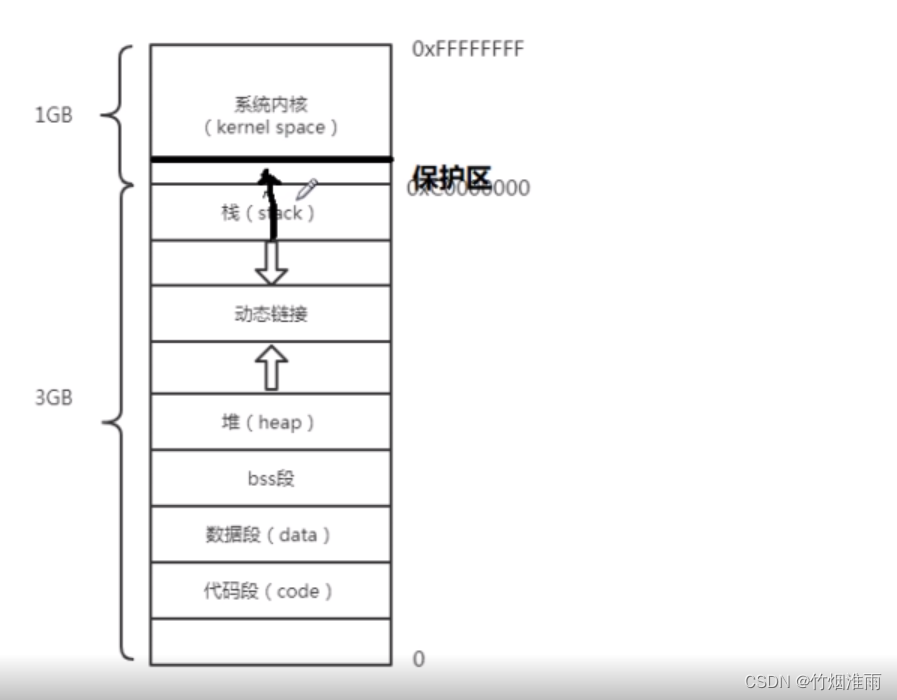
Linux虚拟内存空间分布(重要)
栈溢出(栈攻击)
堆栈的特点
栈攻击
栈攻击的实现
原理
编译器选项
实现案例
linux修改栈空间大小方式
内存泄漏
如何避免野指针?
如何杜绝忘记释放内存?(分析诊断工具valgrind)
内存泄漏总结
C语言内存管理及栈攻击
内存管理
Linux虚拟内存空间分布(重要)
(1)bss段存放初始化的变量:
- 1.未初始化的全局变量和静态局部变量
- 初始值为0的全局变量和静态局部变量(依赖于编译器实现)
(2).data数据段存放初始化的变量:
数据段通常用于存放程序中已初始化且初值不为0的全局变量、静态全局变量和静态局部变量。数据段属于静态内存分配(静态存储区),可读可写。其中有一个.rodata段,一般用于存放常量字符串和只读变量。
(3).text(代码段)
可执行文件加载到内存中的只有数据和指令之分,而指令被存放在.text段中,一般是共享的,编译时确定,只读,不允许修改
(4).heap(堆)
用于存放进程运行时动态分配的内存,可动态扩张或缩减,这块内存由程序员自己管理,通过malloc/new可以申请内存,free/delete用来释放内存,heap的地址从低向高扩展,是不连续的空间
(5).stack(栈)
记录函数调用过程相关的维护性信息,栈的地址一般从高地址向低地址扩展,是连续的内存区域
(6)共享库(libc.so)
静态链接库和动态链接库的区别:
- 不同操作系统下后缀不一样
| windows | linux | |
| 静态库 | .lib | .a |
| 动态/共享库 | .dll | .so |
- 加载方法的时间点不同
*.a 在程序生成链接的时候已经包含(拷贝)进来了
*.so 程序在运行的时候才加载使用
- 静态库把包含调用函数的库是一次性全部加载进去的,动态库是在运行的时候,把用到的函数的定义加载进去,所以包含静态库的程序所以用静态库编译的文件比较大,如果静态库改变了,程序得重新编译,相反的,动态库编译的可执行文件较小,但.so改变了,不影响程序,动态库的开发很方便
- 程序对静态库没有依赖性,对动态库有依赖性。
栈溢出(栈攻击)
堆栈的特点
- 栈增长方向(现在的内核):高地址->低地址
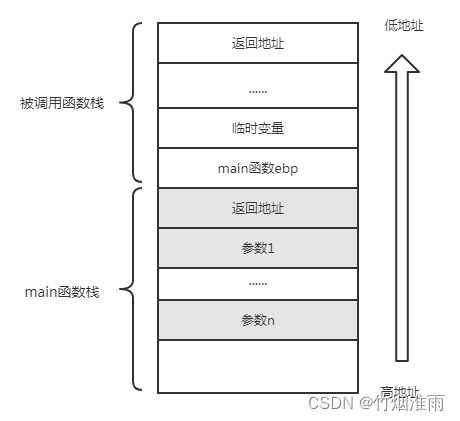
- 函数调用栈的示意图
栈攻击
在旧版本的内核,栈空间是向下增长的由于栈空间后面紧挨着内核空间,所有一旦栈溢出,就会对内核空间进行非法访问,这样就是所谓的栈攻击(黑客常用攻击手段)
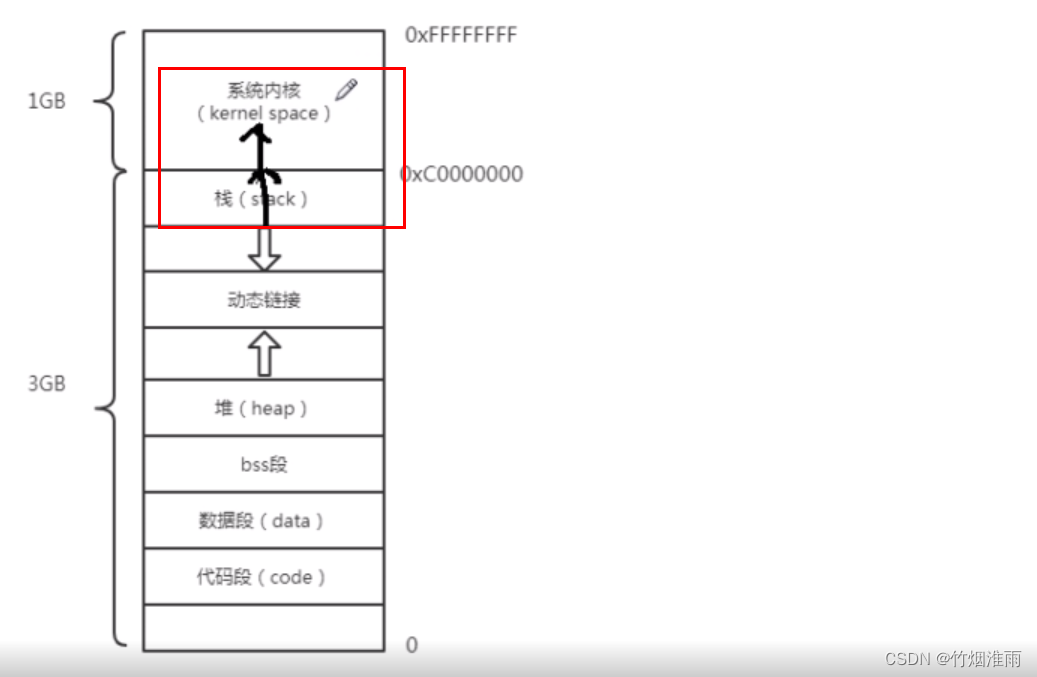
因此Linux内核在2.0升级维护的时候,在系统内核和栈之间增加了一个保护区,大概2M。作用是一旦栈溢出到了保护区,系统就自动报错(栈溢出错误)
还要一种做法,就是改变栈的增长方向,改为向下增长(Linux内核5.0的做法)。
栈攻击的实现
原理
如果忘了压栈的具体过程,可参考:
C/C++函数调用的压栈模型
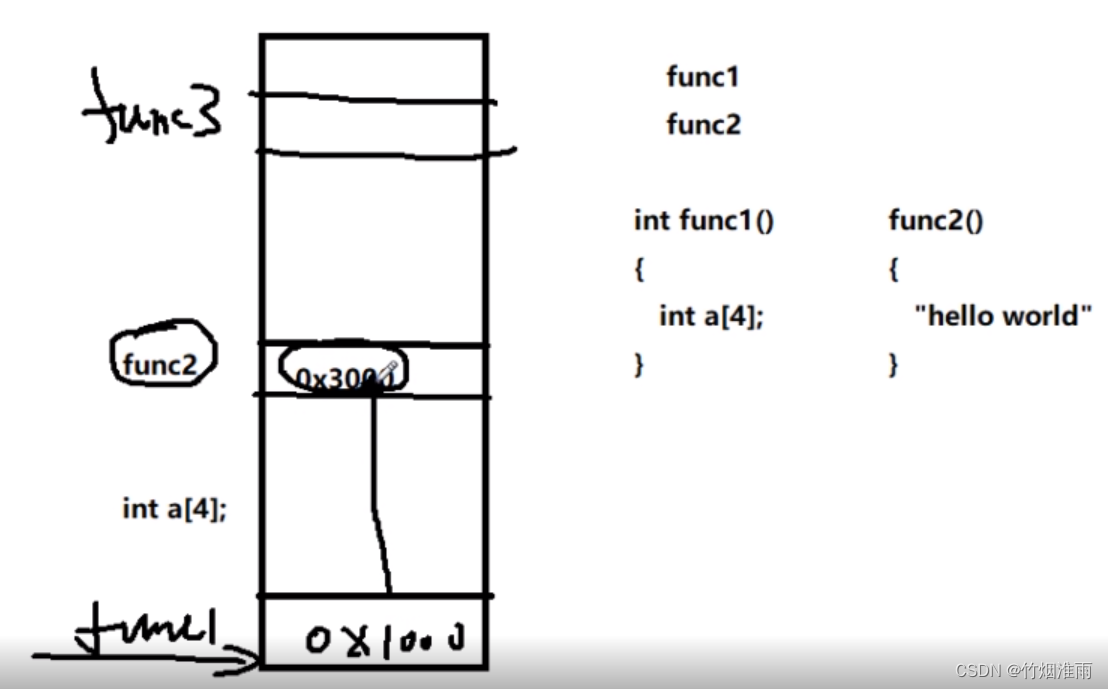
当函数从入口函数main函数开始执行时,编译器会将我们操作系统的运行状态,main函数的返回地址、main的参数、main函数中的变量、进行依次压栈;当main函数开始调用func1()函数时,编译器此时会将main函数的运行状态进行压栈,再将func1()函数的返回地址、func1函数的参数、func1定义变量依次压栈;当func1调用func2的时候,编译器此时会将func2函数的运行状态进行压栈,再将func2函数的返回地址、func2函数的参数、func2定义变量依次压栈。
以向上增长的栈为例:
我们可以很容易的想到一种攻击方式,比如我们想要获取func2的使用权,我们可以在func1中使用一个数组,通过增加数组的大小,让它能够触及的地址一直增加,最终就能够越界获取到func2的入口地址,这样就能够获取到func2的使用权限
编译器选项
gcc C文件名 -z execstack -fno-stack-protector
-z execstack开启堆栈可执行机制
-fno-stack-protector关闭堆栈保护机制
实现案例
(这个实例的实现过程其实还是不太明白:已解决!!!见后面)
如图所示,我们定义了两个函数,func1中定义了一个数组,通过赋值传入func2的函数名(即函数的入口地址)给数组成员(注意这里传入的不是func2(),不是调用func2函数);在func2中打印了一句话。最终我们在main函数中调用func1函数
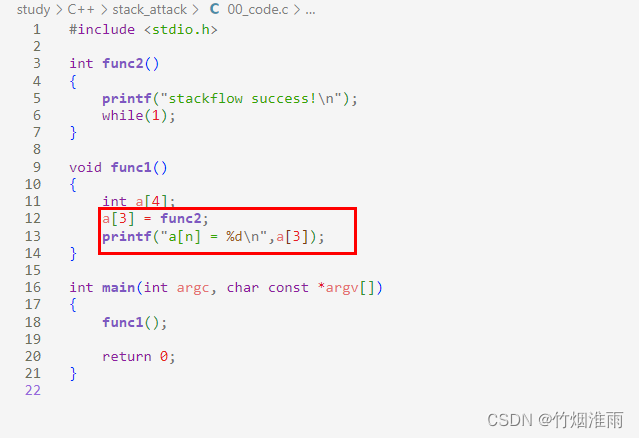
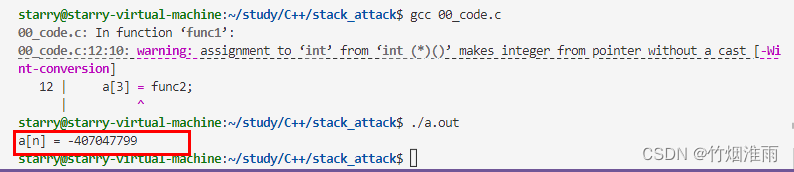
通过逐渐增加数组a[3]=func2中数组成员的下标,最终在a[6]的时候,成功获取使用权
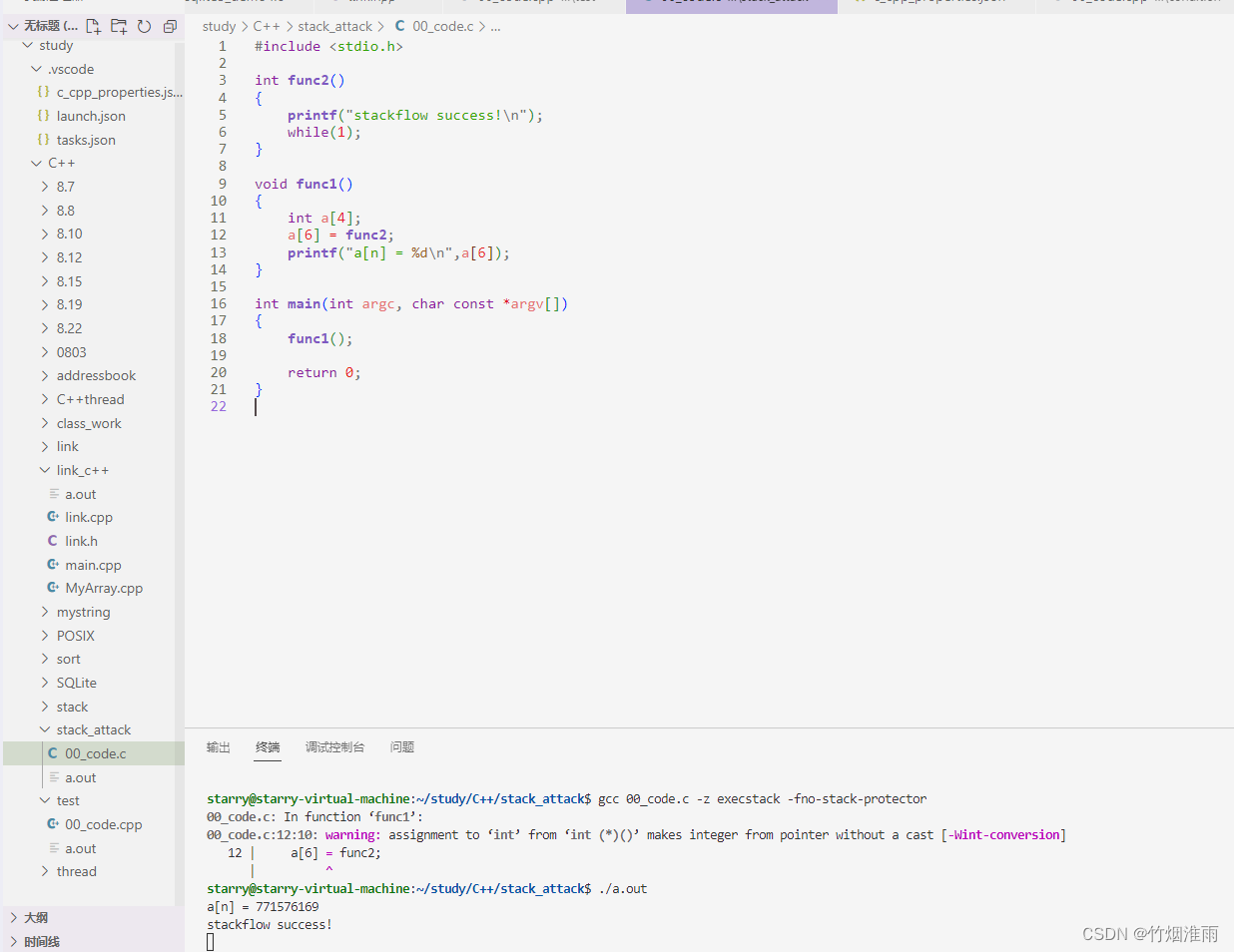
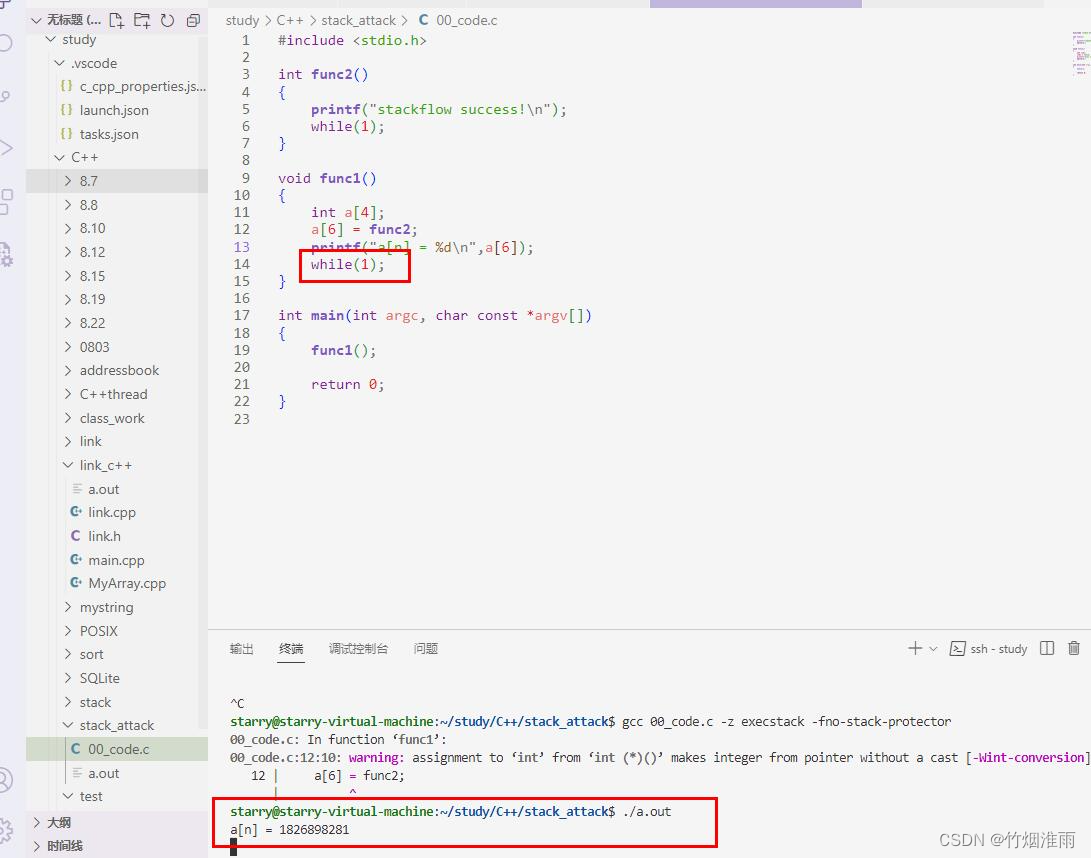
但通过在func1最后加了个while(1),发现func1退出不了,func2就不会被调用,所以最后得出结论:应该是func1的函数返回地址刚好是func2的入口地址
该问题已被我发布在CSDN,可以参考如下:没有被调用的函数其代码为什么会被执行?_xyz-x的博客-CSDN博客
(2023年9月3日)该问题已解决:

结合GPT的回答,可以总结出实现的原理是:
函数的定义通常存放在代码段中,而不是栈中。在程序运行时,代码段是用来存储程序的指令的内存区域,它通常是只读的。函数的定义在编译时就确定了,并且存放在代码段中,以便在程序执行过程中被调用和执行。栈则是用于存放局部变量、函数参数和临时数据等的内存区域,它在函数调用时动态分配和释放,具有先进后出的特性。
所以func1和func2的入口地址和返回地址在编译时已经确定好了,在代码段中。
func1函数中的数组越界操作a[6] = func2。因为在func1函数的栈帧上,局部变量a的下标为 6 的位置处超过了a的实际长度(大小为 4),所以会覆盖到func1函数的返回地址。
因此,func2函数的入口地址被写入到了func1函数的返回地址位置上。当func1函数执行完毕并返回时,CPU会根据返回地址跳转到该地址对应的代码,从而执行了func2函数。
linux修改栈空间大小方式

由于线程使用的线程函数,因此栈空间越大,就能支持越多的线程,常用于网络编程中一个服务类连接更多的客户端
对于堆空间的大小,一般是在创建系统时候决定,堆空间一旦被分配完,如通过malloc或者new的方式再次申请空间就会一直失败。
内存泄漏
内存泄漏有三种情况:越界访问、野指针和内存忘记释放
如何避免野指针?
明确指针的指向
如何杜绝忘记释放内存?(分析诊断工具valgrind)
人无完人,我们人是不可能完全记得释放自己开辟的内存的,尤其在进行大型项目开发时,往往会产生疏忽,因此可以通过内存检测分析工具在写完程序之后进行诊断分析
推荐使用内存分析诊断工具valgrind
安装和使用可参考:linux代码检测工具valgrind之内存检测memcheck_linux代码检查工具_夜雨听萧瑟的博客-CSDN博客
使用时,在编译完程序,使用命令valgrind --tool=memcheck --leak-check=full ./test即可
内存泄漏总结
C语言没有更好的方法杜绝malloc的导致的内存泄漏