git开源地址:GitHub - joonspk-research/generative_agents: Generative Agents: Interactive Simulacra of Human Behavior
论文地址:https://arxiv.org/abs/2304.03442
前言
最近很火的方向,利用GhatGPT的规划、对话、总结能力,让AI在预设的环境中自由生活。自由生成各种各样的剧情和对话。

地图资源
基于tile构建的沙盒世界,构建了由粗到细三层地域结构:
第一层:大区域,如酒吧、咖啡馆、学校、lisa的房子等;
第二层:屋内区域,如房子内的厨房、学校的图书馆等;
第三层:物品,如酒吧客座、学校教室黑板、屋子厨房内的冰箱等;
agent如何在环境中生活?
由树的根节点出发,由粗到细盘问大模型当前行为应该在哪个大区域中发生、在选定大区域的哪个屋内区域发生、对选定屋内区域的那个物品作用。直到找到最佳子地点,用传统的路径生成方法规划到达目的地的路线。
环境中的物品状态是受agent影响的,如agent睡觉的时候床是占用的,agent做了一顿早餐时候冰箱会变空。
用户可以通过自然语言重塑agent生活的环境,如让agent厨房着火、浴室漏水等。
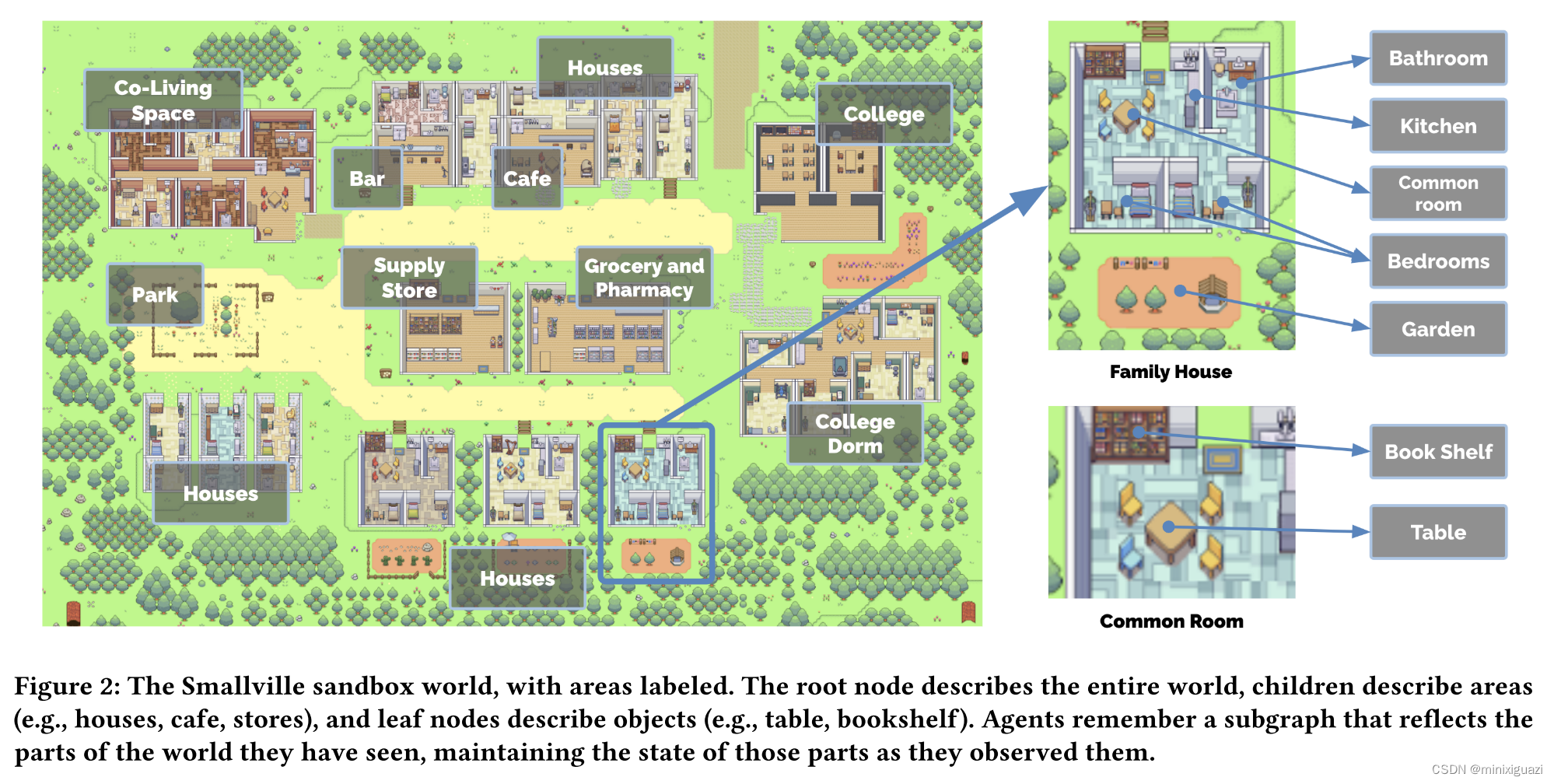
每个agent维护者自己的物品树,随着agent的探索树节点不断变化。此外agent不是无所不知的,他们离开一个区域之后,树节点的更新暂停,当他们重新进入这个空间时,更新又会开始。
主要方法
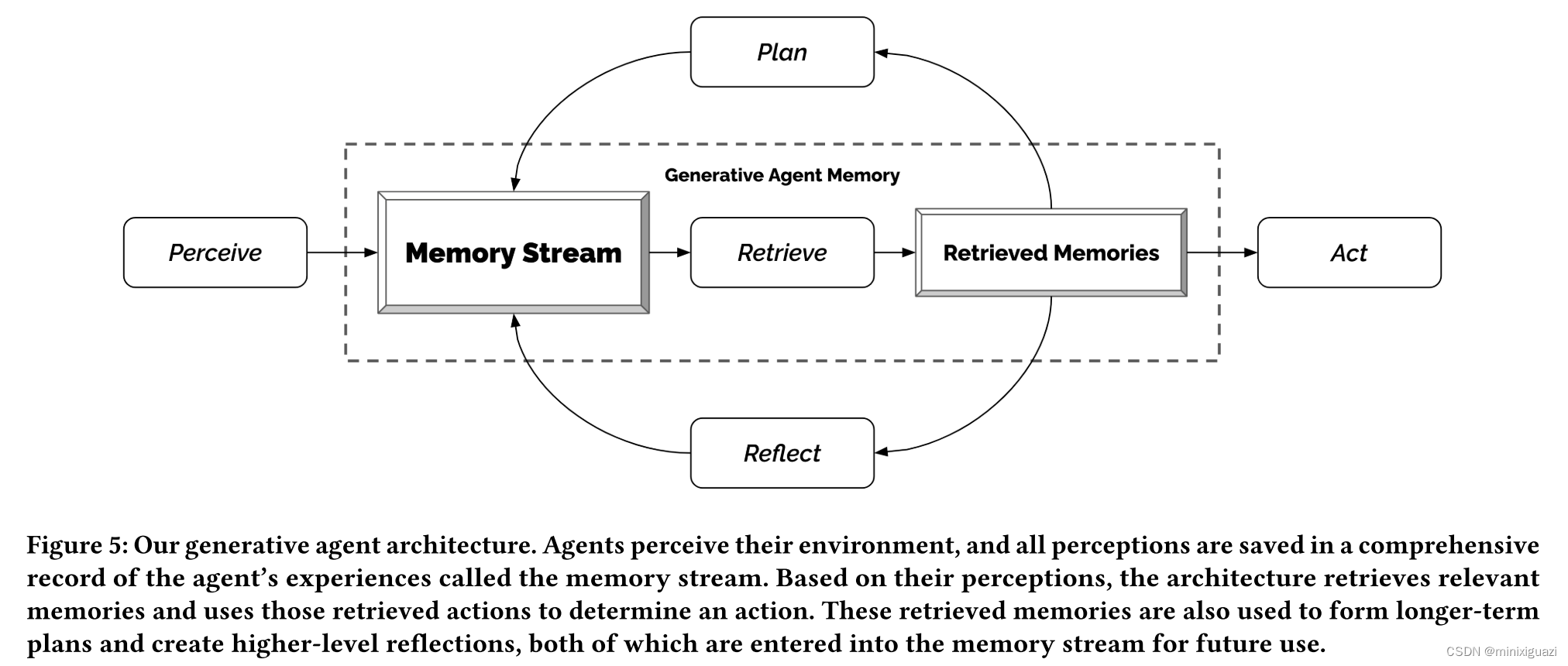
三大块核心组件:plan(规划能力),memory(记忆流),reflect(反思)
1. Plan
从粗到细规划:每日大致规划->每小时规划->每5分钟规划;
每日大致规划(给时间分块):have a lunch at 12:00 pm, watch TV from 7 to 8 pm
每小时规划(逐小时):根据每日大致规划,列出从0点到晚上睡觉11点之间每个时刻的计划;
每5分钟规划(分钟为单位):划分的最小单位为5分钟,最细粒度任务拆解。

这种规划方法有CoT(chain of through)的意思在里面。不给GPT一下子上难度(直接规划每5分钟行程),而是引导它一步一步思考规划,制作出长期合理短期协调的计划。
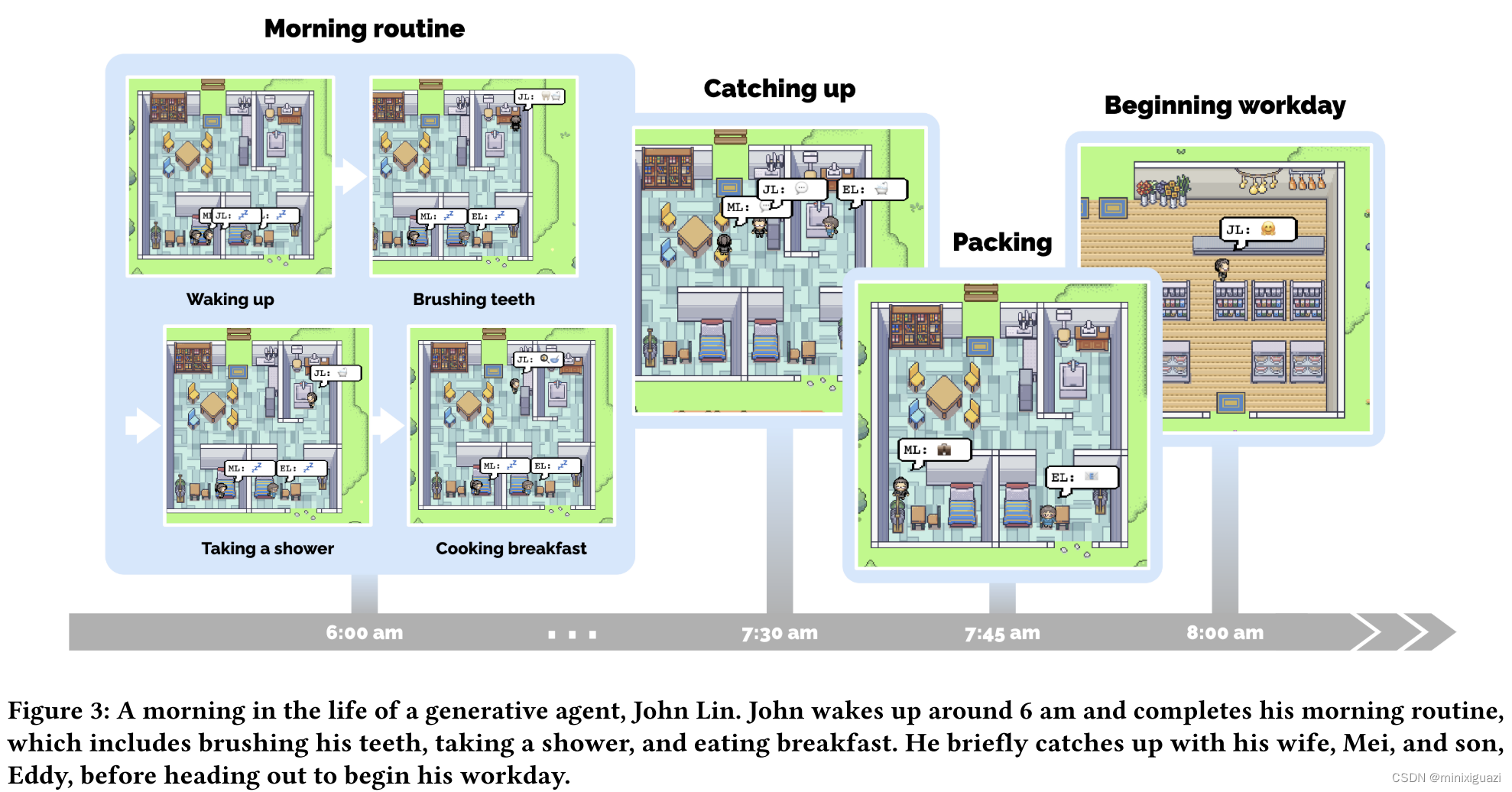
agent每个time step采集周围的环境状况,构造prompt询问大模型是否对该状况做出反应,并从当前时间开始重新生成所有计划。
2. Memory
记忆流模块是agent生成合理可信行为的关键。若没有记忆流模块,大语言模型会生成不依赖过往经历的行为,没法形成长期连贯的协作行为。
对大语言模型来说,如何处理大批量的时间和记忆一直是GPT系列的瓶颈。该论文的核心技术是保证模型综合和检索的是agent最相关的记忆片段,以减小数据流检索的压力。
具体方法
- 维护记忆流列表:每一项纪录了事件的创建时间和最新获取的时间。其中最基本最直接的记忆是agent观察到的现象,包括自己的行为、他人的行为、物品的状态。
- 筛选最相关的记忆:考虑时间、重要性、相关性
- 时间:按照沙盒时间按0.995的delay因子衰减;
- 重要性:每个事件在创建的同时,会让语言模型给出该事件的重要程度;
- 相关性:利用语言模型生成每个事件的文字描述的embedding向量,然后计算请求和embedding向量的余弦相似度;

3. Reflect
反思过程是总结升华的过程,避免陷入简单生成模型的僵局。
论文中给了一个例子。如果问klaus他最想和谁一起聊天,若按照简单的观察记忆,他会选择他天天见面的大学舍友,但他们其实没有共同爱好。从内心的渴望出发,因为他对研究工作抱有极高的热情,他更愿意与有共同兴趣爱好的Maria一起聊天。
具体方法
当较新的事件列表的重要分数达到了150以上,启动反思机制。反思得到的结果作为一种memory放到记忆流中,激发agent从更高的层面总结记忆的规律,而不是只关注表面观察到的状态。
- 反思第一步:给大模型输入100条最新纪录,要求大模型给出3个高深的问题(这种向大模型问问题的方式也是很常见的引导大模型思考的方式);用这些问题作为检索,获取每个问题最相关的memories;
- 反思第二步:要求大模型根据记忆流中的记录,给出5个高深见解,并用记忆中的记录举证这些见解;
- 反思第三步:将上面反思的结果,放进记忆流(加强重要的记忆);
验证效果
用5个问题测试生成的agent是否足够可信:
- 自我认知:如介绍一下自己,描述你一天的计划;
- 记忆检索能力:谁是xxx,谁是市长?
- 计划:你明天早上10点要做什么事情?
- 反应能力:你的早餐烧起来了,这时你要做什么?
- 反思能力:如果你要与一个最近遇到的人在一起,你希望和谁在一起,为什么?
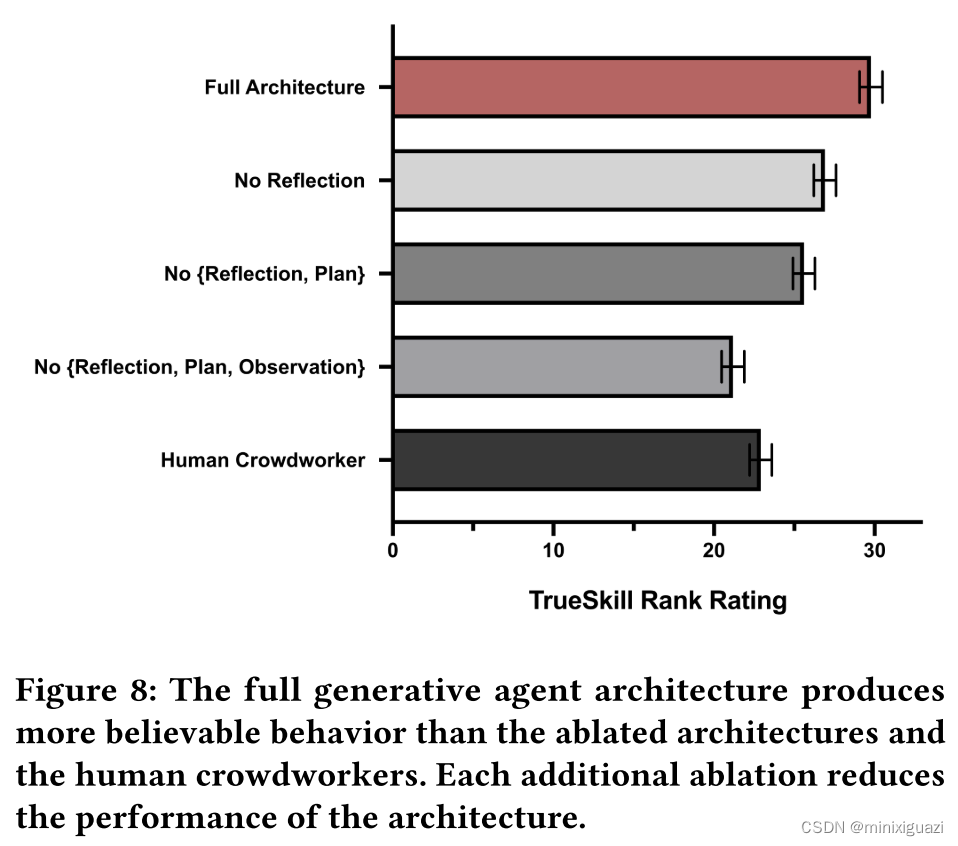
在不同约束条件下(没有观察信息、没有计划、没有反思),测试agent的回答效果。
有一批人类同步在回答和给agent的答案打分,结果在观察、计划和反思的同时加持下效果最好:
现存问题
论文中指出,程序长时间运行后可能可以发现以下问题:
- 地点选择错误:在知道附近有酒吧之后,会选择在酒吧吃午餐;
- 地点的使用规则很难用语言传达给agent:agent会进入已经有人的浴室(也许可以改名为one-person bathroom),商店关门后还有人尝试进入;
经过代码复现,我感觉还有以下问题论文没有提到:
- 多人任务之间协作性差:妈妈还在给孩子煮早餐,孩子已经出门上学了