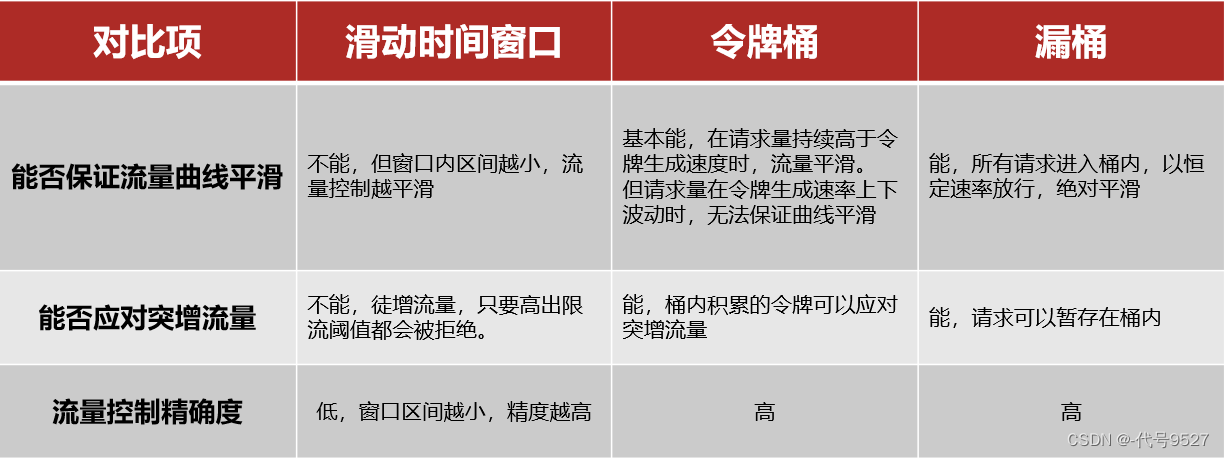
ModaHub魔搭社区:虽然您认为它是刚需,但也有人认为我可能不是需要一款企业级的向量数据库,而是需要一个向量引擎。我可以在传统的数据库上加一个向量引擎,然后它就变成了一款向量数据库,您觉得他们这样的想法是可行的吗?

李莅:这个想法我认为是完全可行的。大模型在这个方面的核心需求就是向量检索的能力,一般不需要特别复杂的数据库的功能。
我们可以通过大模型,或者是各种其他的简化版的模型去做 embedding,把各种文档、文字、图片、转化成向量。所以对于向量既要把它们存起来,又要可以被工具链调用,从里面能够查出来。比如像 LangChain 这种就可以支持很多向量数据库类型,如果我要做数据的增删改查,单纯的向量引擎是搞不定的,但在数据库上加入向量的能力就可以搞定这个事情了。

所以,单从场景和功能出发,我觉得在传统的数据库,或者是一些 NoSQL 的数据库上去加上向量能力是完全行得通的。
但是,当业务的规模发展得很大之后,那传统的数据库加上向量引擎就不一定能搞得定了。 这时可能就需要一个更加跟向量检索耦合的技术实现,来保证向量检索这一部分的性能需求。比如一款大模型应用,要支持上亿用户访问量,这个量级肯定就不是一个传统的数据库可以搞定的,它上面就肯定要做各种架构考量,比如存算分离之类的技术去保证它的规模能够扩展。