目录
- 前言
- 1. cuda驱动API
- 2. cuda运行时API
- 3. tensorRT基础
- 4. tensorRT高级
- 5. tensorRT封装
- 6. 自动驾驶案例项目
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程主要是课程总结,对之前学习的知识的一个复习
课程大纲可看下面的思维导图

1. cuda驱动API
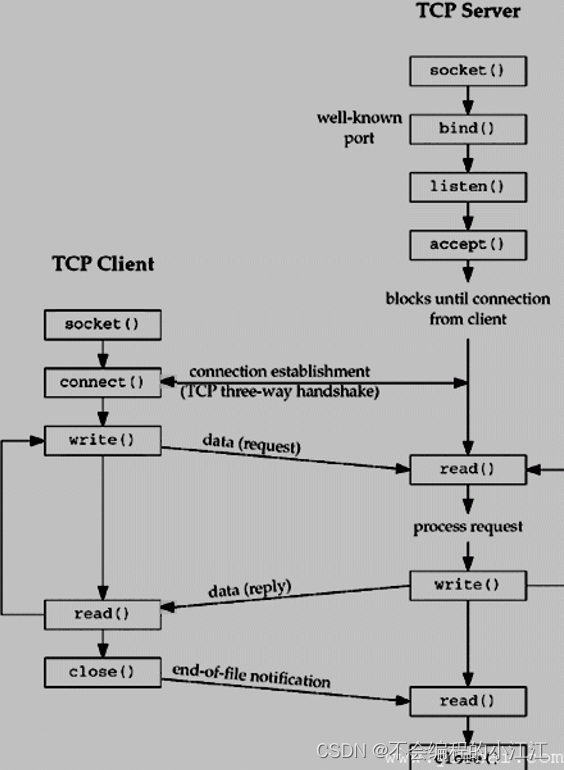
这个章节我们主要了解了 CUDA Driver API 这个与 GPU 沟通的驱动级底层 API,在 Driver API 中我们主要学习了 CUDA 系列接口的开发习惯、Context 的管理机制和内存模型
我们在调用 CUDA Driver API 时都会去对 API 返回值的结果进行一个检查,这样做的目的当然是便于我们发现错误,方便调试,具体实现我们是通过函数封装+宏的方式提供一个统一的接口,并根据返回值判断 API 执行是否成功,从而进行相应的处理。以后的诸如 Runtime API、Kernel 核函数都是这样做的,为各种 CUDA API 函数添加 check 功能,方便定位错误信息,有利于后续开发。
接着我们了解了 context,它是一种上下文,可以关联对 GPU 的所有操作。使用 context 的目的是可以将一系列相关的 CUDA 操作关联到一个 context 中,而不用每次在执行诸如 cuMalloc、cuMemcpy 时都需要显式的制定设备标识符 device。此外,关于上下文的创建更推荐使用 cuDevicePrimaryCtxRetain,它不需要显式地管理上下文栈,代码更简洁。
最后我们简单地学习了 device memory、page-locked memory 的内存分配,分别使用的是 cuMemAlloc 和 cuMemAllocHost
2. cuda运行时API
这个章节我们主要学习了 CUDA Runtime API,它是封装了 CUDA Driver 的高级别更友好的 API,在 Runtime API 中主要的知识点有内存模型、流的使用、线程束布局、核函数的使用
Runtime API 使用时,当调用需要 context 的 API 时,它会自动创建管理 context 无需我们手动操作管理,此外,在 Runtime API 中我们也需要添加 check 功能,方便我们调试和排查问题。
接着我们学习了内存模型,主要了解 pinned memory(Host Memory)、global memory(Device Memory)以及 shared memory(Device Memory)
Host Memory 物理上对应的是内存条内存,它分为 pageable memory 和 page lock memory/pinned memory(逻辑上区别,物理上指同一个东西),对应到代码中,由 new、malloc 分配的是 pageable memory,而由 cudaMallocHost 分配的是 pinned memory
Device Memory 物理上对应的是显存,它拥有片上内存(shared memory)和片外内存(global memory),对应到代码中,由 cudaMalloc 分配的是 global memory,而 shared memory 则常用于同一个线程块内的线程之间共享数据,我们在启动 Kernel 核函数时需要指定共享内存 shared memory 的大小
GPU 可以直接访问 pinned memory,其轨迹主要是通过 PCIE 接口到主板再到内存条,称之为 DMA(Direct Memory Access)技术,而 GPU 要访问 pageable memory 中的数据必须通过 pinned memeory。
对于 GPU 访问而言,距离计算单元越近,效率越高,即 pageable memory<pinned memory<global memory<shared memory,由此我们得出一个结论:尽量多用 pinned memory 储存 host 数据或者显式处理 Host 到 Device 时用 pinned memory 做缓存都是提高性能的关键
随后我们学习了流(stram),stream 是 CUDA 中用于异步控制的主要方式,例如在进行内存拷贝时我们经常使用 cudaMemcpyAsync 异步复制的方式,并把 stream 作为参数填入,最后使用 cudaStreamSynchronize 同步流,确保异步复制操作全部完成。通过使用 stream,可以将数据传输和内存操作与主线程的计算异步进行,从而提高并行性和性能。
然后我们学习了 CUDA 编程中的关键部分 —— 核函数,我们通过 xxx.cu 创建一个 cudac 程序文件后,要把 .cu 文件交给 nvcc 编译才能识别 cuda 语法,而 nvcc 是 nvidia 的一个 c++ 编译器,专门用来编译 cudac 程序的。
cu 文件一般是用来写 CUDA 核函数的,可以把它当作正常 cpp 写即可,它是 cpp 的超级,兼容支持 cpp 的所有特性,只是在 cu 文件中引入了一些新的符号和语法。
在 CUDA 编程中有一些特殊标识符需要我们注意:
- __global__:表示核函数,由 host 调用
- __device__:表示设备函数,由 device 调用
- __host__:表示主机函数,由 host 调用
核函数的调用语法如下:
function<<<gridDim,blockDim,sharedMemorySize,stream>>>(args…)
- function:要执行的核函数的名称
- <<<…>>>:这是启动和函数执行的语法接口,有三个 < 和 > 组成
- gridDim:表示要启动的 grid 的维度,一个 grid 由多个 block 组成。gridDim 定义了每个维度上的 block 数目。例如,如果 grid 的维度是 dim3(4, 4, 1) 则表示启动了一个 4x4 的 2-dim grid
- blockDim:表示要启动的 block 的线程块维度。一个 block 由多个 thread 组成,blockDim 定义了每个维度上的 thread 数目。例如,如果 block 的维度是 dim3(32, 32, 1),则表示每个 block 中有 32x32 个线程
- sharedMemorySize:可选参数,表示 block 中共享内存 shared memory 的大小
- stream:可选参数,CUDA 流用于异步控制
- args…:核函数的实际参数
核函数在执行时实际上会启动很多线程,这些线程在逻辑上是并行的,但是在物理层不一定。GPU 硬件的一个核心组件就是流式多处理器(streaming Multi-processor,SM),当一个 Kernel 核函数被执行时,它的 grid 中的线程块就被分配到 SM 上。值得注意的是一个线程块只能在一个 SM 上被调度,而一个 SM 一般可以调度多个线程块,这要看 SM 本身的能力。一个 Kernel 的各个线程块被分配到多个 SM 中去执行,因此我们说 grid 只是逻辑层,而 SM 才是执行的物理层
SM 的基本执行单元是线程束(warps),线程束包含 32 个线程,一个 SM 同时并发的线程束数也是有限的。由于 SM 的基本执行单元是包含 32 个线程的线程束,因此 block 大小一般设置为 32 的倍数,如 256、512、1024
总之就是网格(grid)和线程块(block)只是逻辑划分,一个 Kernel 的所有线程其实在物理层不一定同时并发的。所以 Kernel 的 grid 和 block 的配置不同,性能会出现差异。
接着我们学习了共享内存的使用,shared memory 可以在同一个 block 中的线程之间共享数据,它通常与 __syncthreads 同时出现,为了同步 block 中的所有线程。
在 CUDA 编程中,共享内存可以通过两种方式进行定义:静态共享内存和动态共享内存。静态共享内存定义使用 __shared__ 关键字,动态共享内存定义使用 extern __shared__ 关键字,静态共享变量定义几个地址随之叠加,而动态共享变量无论定义多少个地址都一样。定义的共享变量并不能给初始值,必须由线程或者其它方式赋值。
接下来我们学习了 warpAffine 并实现了 CUDA 核函数来进行加速,warpAffine 是对图像做平移缩放旋转变换进行综合统一描述的方法,在深度学习领域通常需要对图像做预处理,比如缩放,颜色通道转换,减均值除以标准差,通过 CUDA 对 warpAffine 进行并行加速实现可以对整个预处理进行统一。因为我们在核函数中是对每个像素进行操作,因此可以非常轻易的实现诸如 BGR->RGB、减均值除标准差等操作,此外通过 warpAffine 和双线性插值可以实现图像的缩放,并通过仿射变换的逆矩阵可以用于后处理中的 decode 解码操作
然后我们也学习了 CUDA 核函数来加速后处理,我们以 YOLOv5 检测模型的后处理为例,我们先在 CPU 上实现 decode 和 nms,一些关键的性能优化点如下:
- 预测框过滤:在 decode 过程中先利用置信度阈值过滤,避免不必要的后续计算和处理
- 预测框排序:在 lambda 函数中传引用,同时对 box_result 利用 reserve 进行预分配提升性能
- 使用标志位:在 nms 过程中,使用 remove_flags 标志位来标记需要移除的预测框,相比于两两预测框比较提高了效率
杜老师提供的 CPU 版本的后处理性能已经非常好了,我们根据 cpu_decode 以及 cpu_nms 在 GPU 上也完成了同样的操作
最后我们简单了解了下 CUDA 编程中的错误处理以及错误的传播特性
3. tensorRT基础
这个章节我们主要学习了 tensorRT 的一些基础知识,在 tensorRT 基础篇中主要的知识点有模型结构定义方式、编译过程配置、推理过程实现、插件实现、onnx 理解
我们首先学习了利用 tensorRT 的 C++ API 构建了一个简单的神经网络模型,大致流程可以分为以下四个部分:
- 1. 定义 builder、config 和 network
- 2. 构建网络所需输入、模型结构和输出的基本信息
- 3. 生成 engine 模型文件
- 4. 序列化模型文件并存储
接下来我们使用了 C++ API 进行了推理,大致流程如下:
- 1. 准备模型并加载
- 2. 创建 runtime 反序列化模型创建 engine
- 3. 创建 context 和 CUDA stream
- 4. 准备数据执行推理
- 5. 释放内存
在完成了利用 tensorRT 的 C++ API 进行模型构建和推理后,我们学习了动态 shape 模型的构建和推理。在构建网络时,对于输入维度需要给定 -1,否则该维度不会动态,此外还需要设置 profile 对象,确定 kMin、kOPT 以及 kMAX 等。在推理阶段,动态 shape 模型只需要在每次推理前设置输入数据的 shape 即可,而大多时候我们只关心 batch 维度的动态,而对宽、高动态并不关心
接着我们学习了 onnx 文件的导出、读取、创建和编辑。onnx 是 Microsoft 开发的一种中间格式的模型,它的本质是一种 protobuf 格式的文件。我们需要理解 onnx 模型结构的储存、权重的储存、常量的储存、netron 的解读对应到代码,学习 onnx 的各种操作有利于我们后续 tensorRT 的部署工作
随后我们学习了导出 onnx 时的一些注意事项,确保导出的 onnx 在生成 engine 的时候问题尽可能的少。我们还学习了 libonnxparser.so 和源代码两种不同的方式来解析 onnx 模型,使用源代码的目的是为了更好的进行自定义封装,简化插件开发或者模型编译的过程,更加具有定制化,遇到问题也可以调试。
在学习完利用 onnxparser 构建网络模型后,我们还学习了 tensorRT 中插件的实现并对其进行了封装。最后我们学习了模型的 INT8 量化,我们以分类模型 resnet18 为例演示了 PTQ 隐式量化,
4. tensorRT高级
这个章节我们以实际项目为例,演示了 tensorRT 的综合运用,在 tensorRT 高级篇中主要的案例有分类器案例、Yolov5检测案例、Unet场景分割案例、Alphapose关键点检测案例、mmdetection案例、onnxruntime案例
首先我们学习了 resnet18 分类器案例,在这个案例中我们学习使用了 shared_ptr 对 tensorrt 对象的返回值进行了封装,防止内存的泄露。同时我们在 CPU 上也实现了一个高性能的预处理方法,直接对像素进行操作,将颜色通道转换、减均值除标准差一并做了。
接着我们学习了 yolov5 检测器案例,在这里我们重点学习了 yolov5 中 onnx 模型的导出,并详细分析了 yolov5 CPU 版本的预处理和后处理。我们还学习了场景分割网络 Unet 的导出、编译到推理,分割网络和检测网络略有不同,模型的预测可以看作对每个像素点进行分类
随后我们学习了 alphapose 姿态点估计案例,在这里我们体会了要将复杂的后处理放到 onnx,同时学习了如何从拉取一个官方代码到导出我们想要的 onnx,我们在理解完别人的代码后一定要自己实现一个版本,这样才能更好的去消化吸收变成我们自己的知识。
然后我们学习了调试分析 mmdet 代码,把 yolox 模型导出并在 tensorrt 上推理得到了结果。由于 mmdetection 封装得太死,导出 onnx 非常费劲,但是习惯后问题总是可以解决得,不至于束手无策。无论遇到多么复杂的框架、代码,我们首先需要对模型有一定了解,同时具备一定的代码功底,能完成解读、按照自己的理解重写,这样将大大锻炼动手能力。
接下来我们学习了使用不同的推理框架完成部署工作,包括 onnxruntime、openvino 等,这些框架其实大差不差,无非是准备数据塞到框架中,拿到推理后的解决进行后处理,我们能把握的其实就是数据的预处理和后处理部分,至于中间的推理部分我们其实是没办法控制的,因此为了实现高性能,我们就要想办法把数据的预处理和后处理部分尽可能的高效处理,这才是我们需要学习的核心。
在学习完了一系列的案例之后,我们了解了深度学习中涉及的线程知识,目的是方便后面我们的封装工作。
深度学习中的线程知识主要包括 thread、mutex、condition_varaiable、lock、promise、future 等
mutex 互斥锁的存在主要是为了解决共享资源访问问题,当线程不是安全的时候,需要对其资源访问加上锁
condition_variabel 条件变量的存在主要是解决在生产者消费者模式中消费者如何通知生产者以及生产者如何去等待消费者,分别使用的是 cv_.wait 和 cv_notify_one 方法,它们被用来同步生产者和消费者,以确保队列的大小不超过给定的限制。当生产者试图添加到队列时,如果队列已满,它会等待直到消费者从队列中取出一张图片。
promise、future 用于在线程间传递数据,消费者通过 promise.set 方法设置值,而生产者则可以通过 future.get 方法可以拿到消费者的反馈。这种方式在线程间传递数据非常有效,因为它允许生产者线程异步地等待消费者线程处理的结果,而不必使用复杂的同步机制。而且,由于 promise 和 future 之间的紧密关系,这种方法也是线程安全的。
在学习线程知识的过程中我们还了解了一种设计模式,即生产者-消费者设计模式,它在深度学习模型推理中非常常见,生产者线程负责不断生成新的图片任务,将其放入队列中,而消费者线程则负责从队列中获取图片任务并进行处理。通过这种方式,使得图片采集和模型推理过程可以并行进行,提高了系统的吞吐量和效率。
5. tensorRT封装
这个章节我们主要是学习对 tensorRT 的逐步封装,在 tensorRT 封装篇主要的封装有代码的封装、内存分配的封装、tensor 的封装、build 的封装,infer 的封装
首先我们学习了使用 RAII + 接口模式对代码进行了有效的封装,RAII 将资源在构造函数中就进行初始化,避免了外部获取资源后还要调用相关函数去做初始化,接口模式则将接口纯虚类与具体实现类分离开,让使用者只考虑具体的接口,而不必关心具体的实现。这种封装方式为代码提供了更大的灵活性和可维护性,十分推荐使用
然后我们学习了 tensorRT 中的 build 的封装,重点是 compile 函数的实现;我们还学习了 memory 的封装,使得内存分配复制自动管理,避免手动管理的繁琐,主要是通过 MixMemory 实现的内存的分配和释放以及内存的复用,其中复用思想在于申请分配的内存大于之前已经分配的内存才去释放并重新分配,否则直接返回之前已经分配好的内存,这样可以避免频繁的内存分配和释放操作,从而提高性能。
接着我们学习了 tensor 的封装,对 tensor 的封装重点考虑了四个方面:内存的管理、内存的复用、内存的拷贝以及索引的计算,其中前面两个可以用 MixMemory 来解决,内存的拷贝通过定义内存的状态,懒分配原则实现的,而索引的计算则是通过左乘右加原则完成的。tensor 的封装使得输入和输出的操作更加的便捷,索引的计算也更加的方便。随后我们还学习了 infer 的封装,通过一个 commit 函数即可完成整个推理过程。
在完成上述各个部件的封装后,我们使用这些封装好的组件,配合生产者和消费者模式实现了一个完整的 yolov5 推理,并对其进行了优化完善。最后我们探讨了模型的调试技巧,要学会善于使用 python 工作流,联合 python/cpp 一起进行问题调试。
6. 自动驾驶案例项目
这个章节我们主要是学习自动驾驶案例的各个项目,包括道路分割、深度估计、车道线检测
我们学习了自动驾驶场景中的模型案例,对不同的任务进行了了解。
道路分割案例是将道路分割成可行驶区域、车道线、不可行驶区域等,深度估计是从图像中获取车辆与目标的深度信息,而车道线检测是利用位置概率来对点进行回归
最后我们学习了使用 pybind11 为 python 写 c++ 的扩展模块,利用 c++ 的计算性能和 python 的便利性有利于我们平时的开发。
总结
这次重撸视频前前后后花了将近两个月的时间,不容易吖😂,从最开始的 Driver API、Runtime API 到 tensorRT 的模型构建推理,再到各个实际场景应用案例,再到各个模块的封装,最后到自动驾驶项目,一路走来,收获颇丰。感谢杜老师,也感谢一路坚持的自己😄