目录
1.开篇版权提示
2.时间序列介绍
3.项目数据处理
4.项目数据划分+可视化
5.时间预测序列经典算法1:朴素法
6.时间预测序列经典算法2: 简单平均法
7.时间预测序列经典算法3:移动平均法
8.时间预测序列经典算法4:简单指数法
9.时间预测序列经典算法5:Holt线性趋势法
10.时间预测序列经典算法6:Holt-Winters季节性预测算法
11.时间预测序列经典算法7:自回归移动平均(ARIMA)算法
12.参考文章和致谢
1.开篇版权提示
"""
开篇提示:
这篇文章的绝大部分代码都不是我自己书写的,而是来自:https://www.cnblogs.com/lfri/articles/12243268.html#gallery-5的文章中。
由于目前很多的时间序列预测模型的文章中都没有给出相关的数据集,所以我不能够很好的进行对应的学习和代码的运行
而这篇文章,给出了对应的数据集,所以我就通过这篇文章来对于时间序列预测模型有一个更好的理解,在这里对于这位作者表示不尽的感谢!
如果有涉及到版权问题,请及时联系我对文章做相应的修改或者删除!
再次申明:
代码文章出处:https://www.cnblogs.com/lfri/articles/12243268.html#gallery-5
本人仅作学习参考使用,本篇博客也仅作相关的理解研究的标注,需要更深的理解交流请跳转上述网址出处,本人不胜感激!
"""2.时间序列介绍
时间序列介绍
"""
时间预测序列模型是一个非常强大的预测模型算法,其体现在对于根据先前的数据经验的整理学习来完成对于未来的合理预测和计算,是数学建模中一种基础的预测算法。
文章将通过一个项目的处理解决来对于7种时间序列预测的模型算法的研究并且对比分析它们的优缺点和不足之处
"""
实践项目题目
"""
Question:
假设给出了过去两年不同时间段的乘客的数量,要求你根据这些数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量。
注意:数据集保存在时间预测模型材料包中,详见:time_data.csv
"""3.项目数据处理
"""
首先我们通过pandas对于数据集有一个简单的了解,该数据集是由18288个数据组构成的,其中包括了其ID,Datetime和Count数据
通过df.head(10)我们查阅了前10列的元素,对于数据集有了相应的理解。
"""import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('C:\\Users\\Zeng Zhong Yan\\Desktop\\时间预测模型材料包\\time_data.csv')
df.head()
df.shape#(18288, 3)print(df.head(10))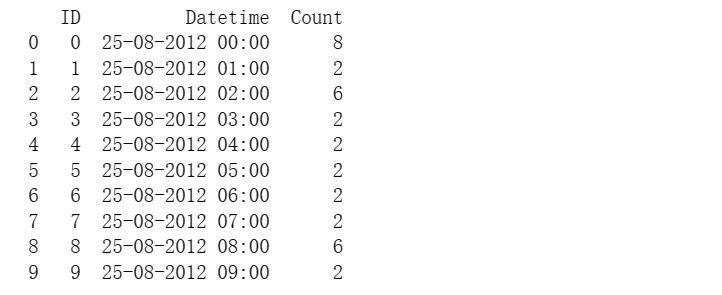
4.项目数据划分+可视化
"""
现在我们需要进行进一步的处理:
我们将前11856个元素,也就是从2012 年8月-2013年12月的数据单独拿出来制作一个数据集,以此作为训练集
我们再将剩余的元素拿出来作为作为测试集,用来检测模型的精确程度。
接下来我们将完成3个步骤:
#1.对于训练数据和测试数据进行步划分
#2.对于数据进行一个采样划分
#3.进行可视化绘图
"""import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('C:\\Users\\Zeng Zhong Yan\\Desktop\\时间预测模型材料包\\time_data.csv', nrows=11856)
#对于训练数据和测试数据进行步划分
train = df[0:10392]
test = df[10392:]
#对于数据进行一个采样划分
df['Timestamp'] = pd.to_datetime(df['Datetime'], format='%d-%m-%Y %H:%M') # 4位年用Y,2位年用y
df.index = df['Timestamp']
df = df.resample('D').mean() #按天采样,计算均值
train['Timestamp'] = pd.to_datetime(train['Datetime'], format='%d-%m-%Y %H:%M')
train.index = train['Timestamp']
train = train.resample('D').mean() #
test['Timestamp'] = pd.to_datetime(test['Datetime'], format='%d-%m-%Y %H:%M')
test.index = test['Timestamp']
test = test.resample('D').mean()
#绘制测试集和训练集的点在图片上,进行可视化后知道数据是如何变化的
train.Count.plot( title= 'Daily Ridership', fontsize=14)
test.Count.plot(title= 'Daily Ridership', fontsize=14)
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列1.png', dpi=500, bbox_inches='tight')
plt.show()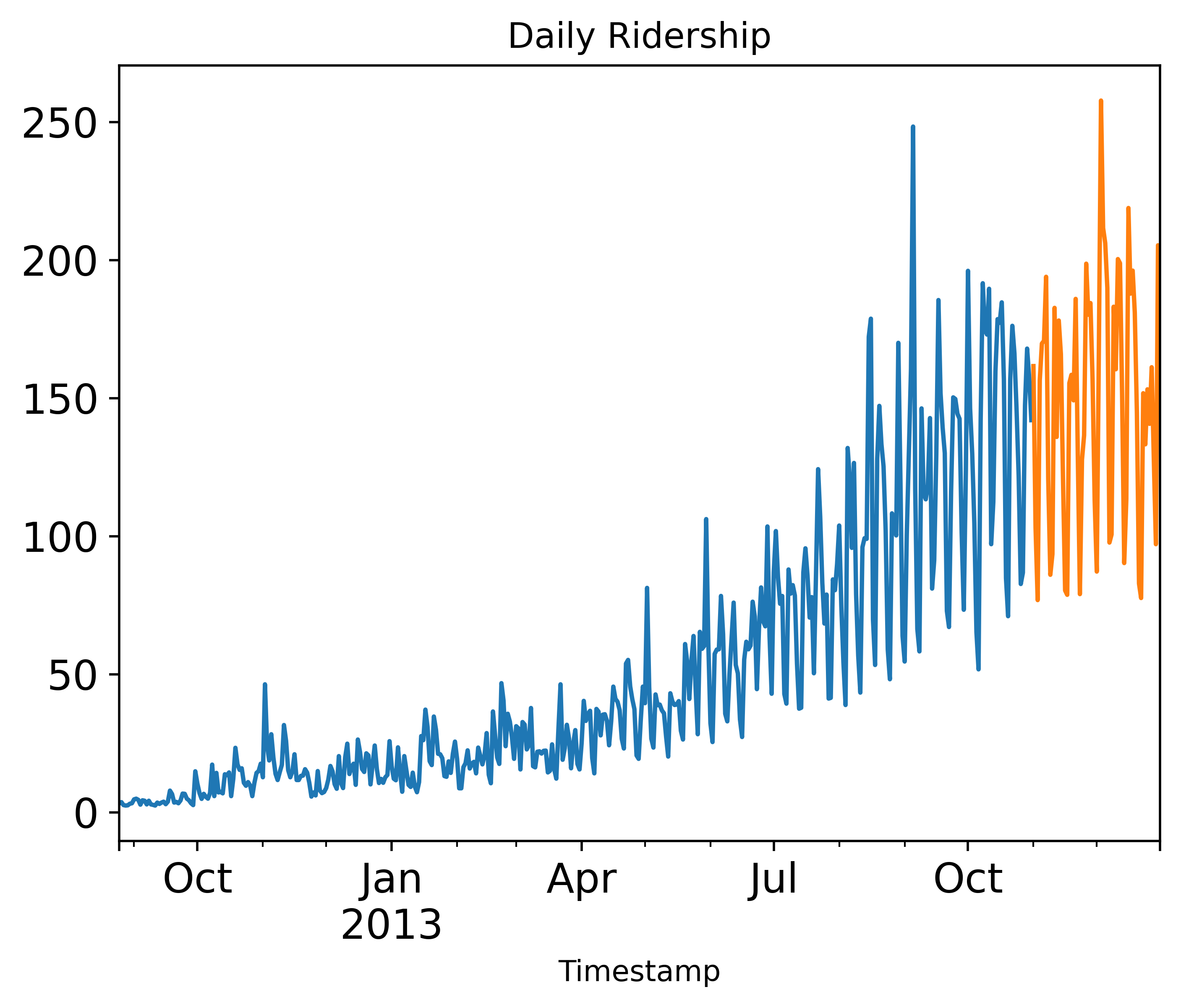
5.时间预测序列经典算法1:朴素法
"""
经典算法1:朴素法
朴素法的思想告诉我们,如果一个对象的变化很平稳,只会进行一般的波动,那么我们就可以预测t+1天的数值y(t+1)=y(t)
所以我们可以设想,朴素法预测之后的图像应该失调平稳的直线。
如下图所示,我们可以明显的发现朴素法的预测明显差距过大了,显然这很不合适。
朴素法并不适合变化很大的数据集,最适合稳定性很高的数据集。
"""dd = np.asarray(train['Count'])
y_hat = test.copy()
y_hat['naive'] = dd[len(dd) - 1]
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列2.png', dpi=500, bbox_inches='tight')
plt.show()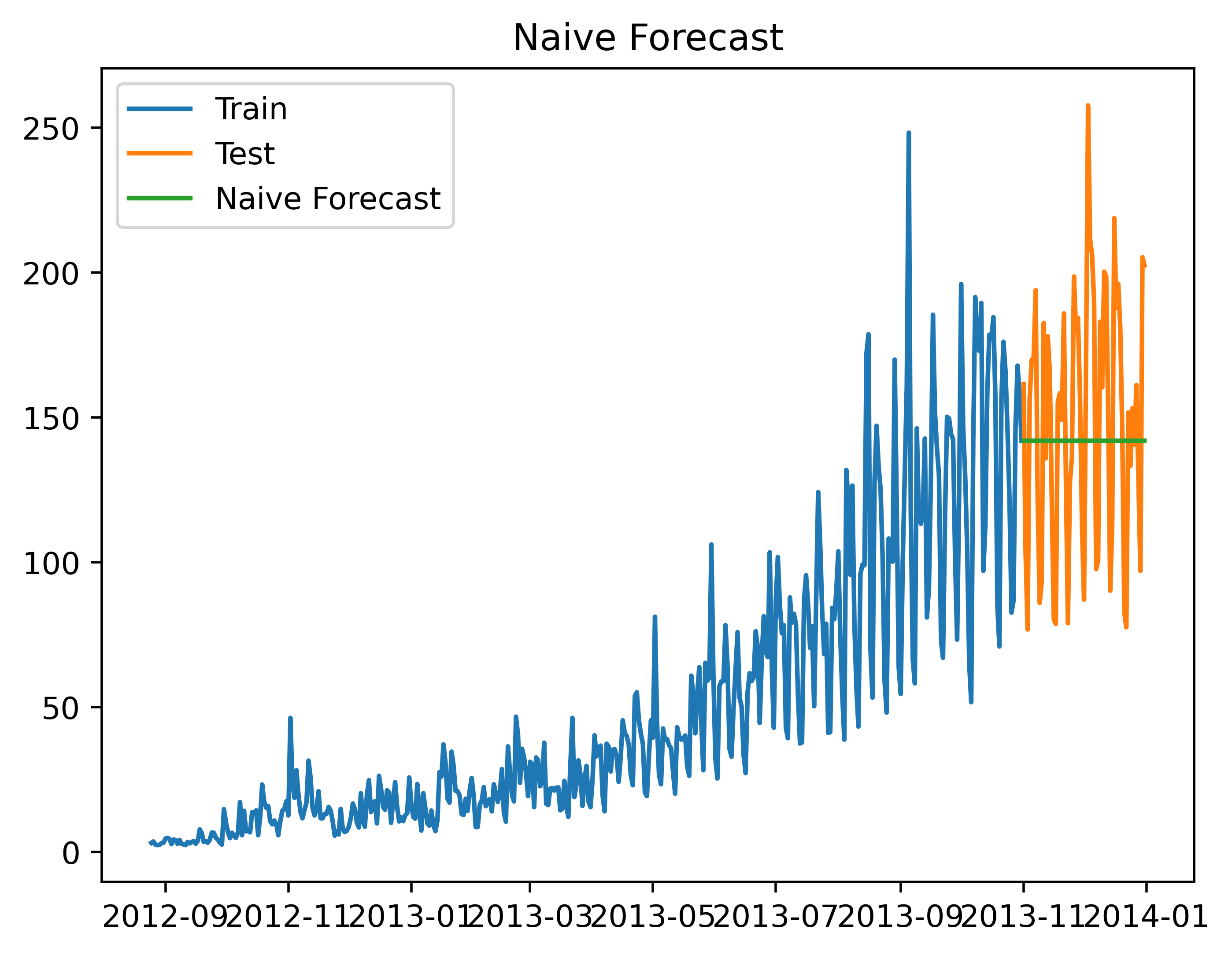
"""
朴素法到底有多大的误差呢?
我们计算下均方根误差,检查模型在测试数据集上的准确率,结果发现均方误差RMS=43.91640614391676
"""from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print("均方误差RMS=",rms)6.时间预测序列经典算法2: 简单平均法
"""
经典算法2:简答平均法
对象的数值会随机上涨和下跌,平均值一般会比较稳定,保持一致。
我们经常会遇到一些数据集,虽然在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。
这种情况下,我们可以预测出第二天的预测值大致和过去天数的价格平均值一致。
这种将预期值等同于之前所有观测点的平均值的预测方法就叫简单平均法。
公式y(t+1)=sum(y(i))/n(i=1,2,3,4.....n)
"""y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列3.png', dpi=500, bbox_inches='tight')
plt.show() 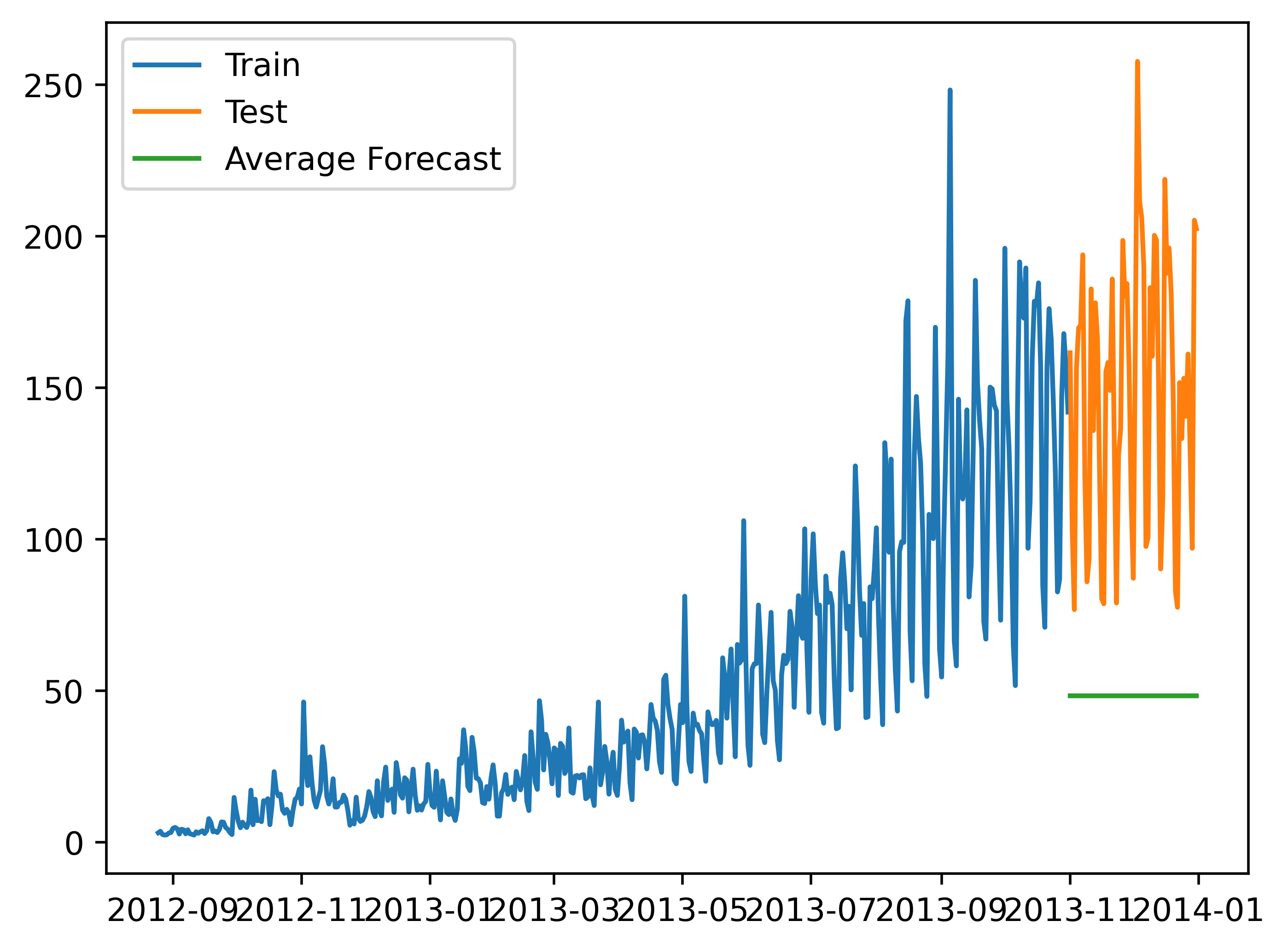
7.时间预测序列经典算法3:移动平均法
"""
经典算法3:移动平均法
研究的数据在一段时间内大幅上涨,但后来又趋于平稳。我们也经常会遇到这种数据集,比如价格或销售额某段时间大幅上升或下降。
这样的话对于整体平均数的计算的值显然是不合理的,因为极大极小的数已经影响到平均数合理的大小了。
如果我们这时用之前的简单平均法,就得使用所有先前数据的平均值,但在这里使用之前的所有数据是说不通的,因为用开始阶段的价格值会大幅影响接下来日期的预测值。
因此我们对于时间进行分段截取,分别计算切断时间的平均值,这样会显得更加合理一些。
很明显这里的逻辑是划分窗口区,这种用某些窗口期计算平均值的预测方法就叫移动平均法。
"""8.时间预测序列经典算法4:简单指数法
"""
经典算法四:简单指数法
我们注意到简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异。
我们就需要在这两种方法之间取一个折中的方法,在将所有数据考虑在内的同时也能给数据赋予不同非权重。
例如,相比更早时期内的观测值,它会给近期的观测值赋予更大的权重。按照这种原则工作的方法就叫做简单指数平滑法。
它通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关:
这样可能早期的指数所占的权重就更大,越晚期的指数所占的权重就越小
这样的话我们就得出了如下的计算公式:y(t+1)=a*y(t)+(1-a)*y(t-1)
"""from statsmodels.tsa.api import SimpleExpSmoothing
y_hat_avg = test.copy()
fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False)
y_hat_avg['SES'] = fit.forecast(len(test))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列4.png', dpi=500, bbox_inches='tight')
plt.show()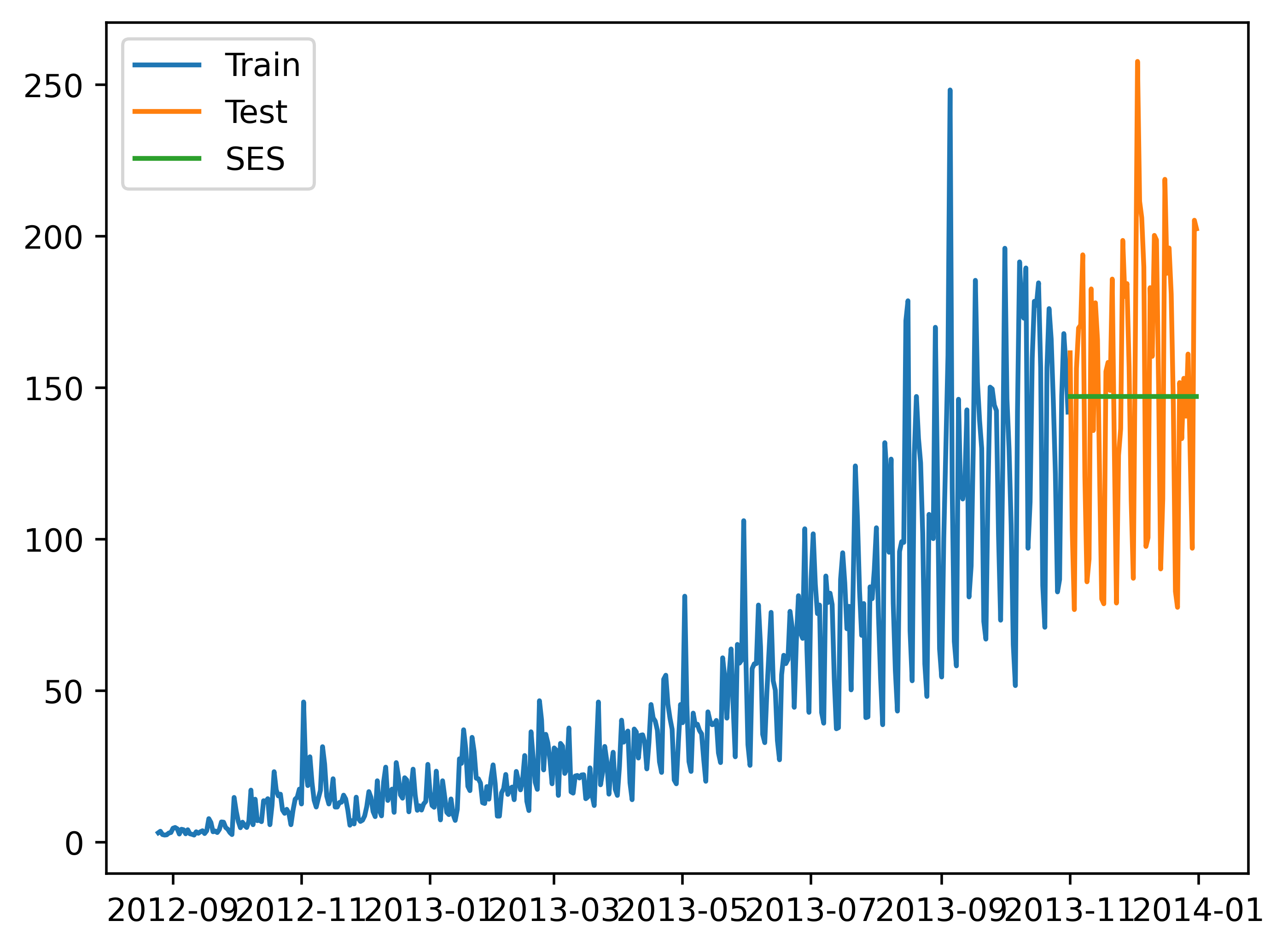
9.时间预测序列经典算法5:Holt线性趋势法
"""
经典算法5:Holt线性趋势法
如果物对象的观测值是呈不断上涨的总体趋势的,我们在一段时间内观察到的数值的总体的模式。
每个时序数据集可以被划分为为相应的几个部分:趋势(Trend),季节性(Seasonal)和残差(Residual)。
通Holt线性趋势法,我们可以预测任何时期呈现变化趋势的曲线的预测值
"""import statsmodels.api as sm
sm.tsa.seasonal_decompose(train['Count']).plot()
result = sm.tsa.stattools.adfuller(train['Count'])
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列100.png', dpi=500, bbox_inches='tight')
plt.show()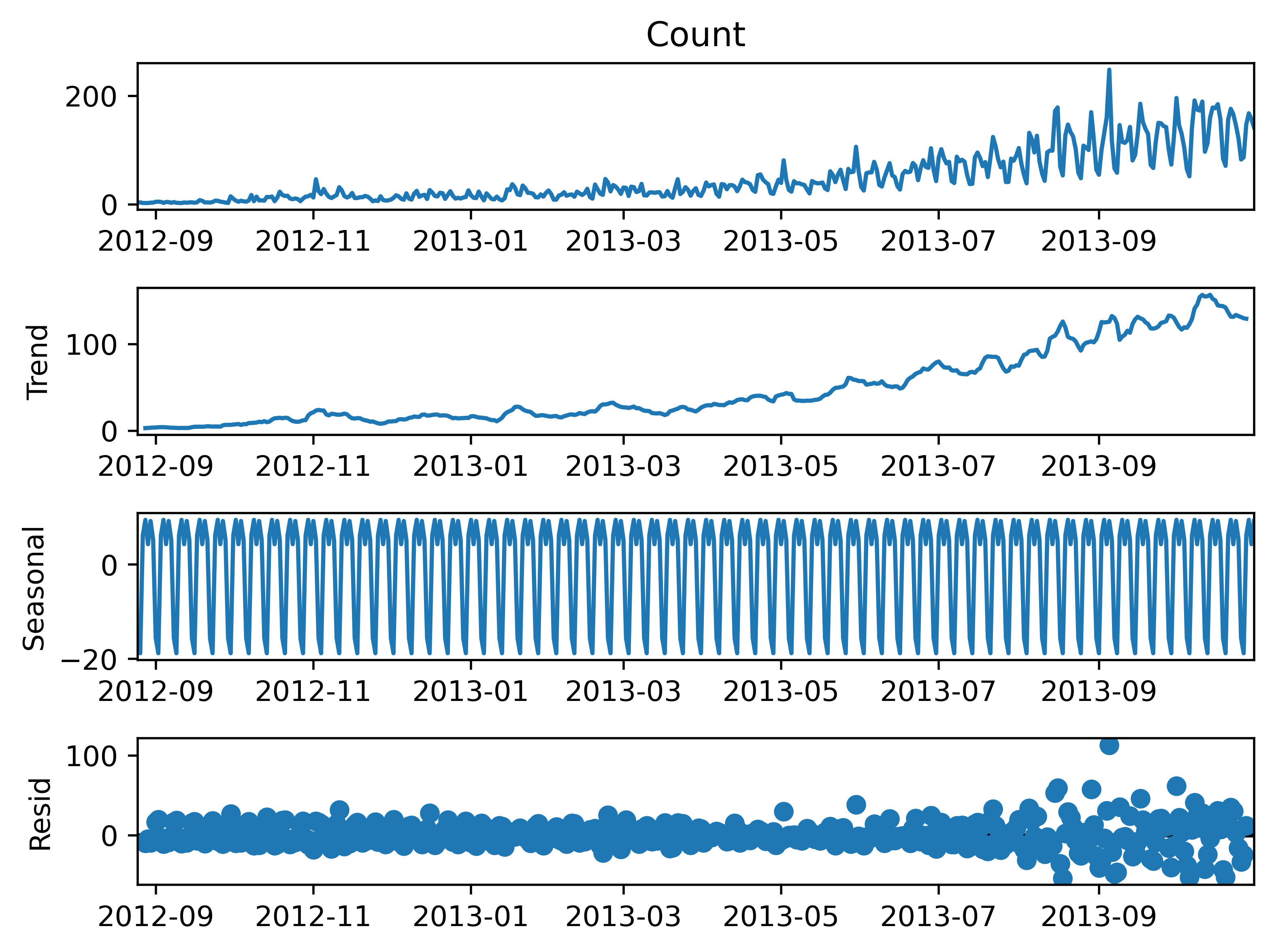
from statsmodels.tsa.api import Holt
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear')
plt.legend(loc='best')
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列6.png', dpi=500, bbox_inches='tight')
plt.show() 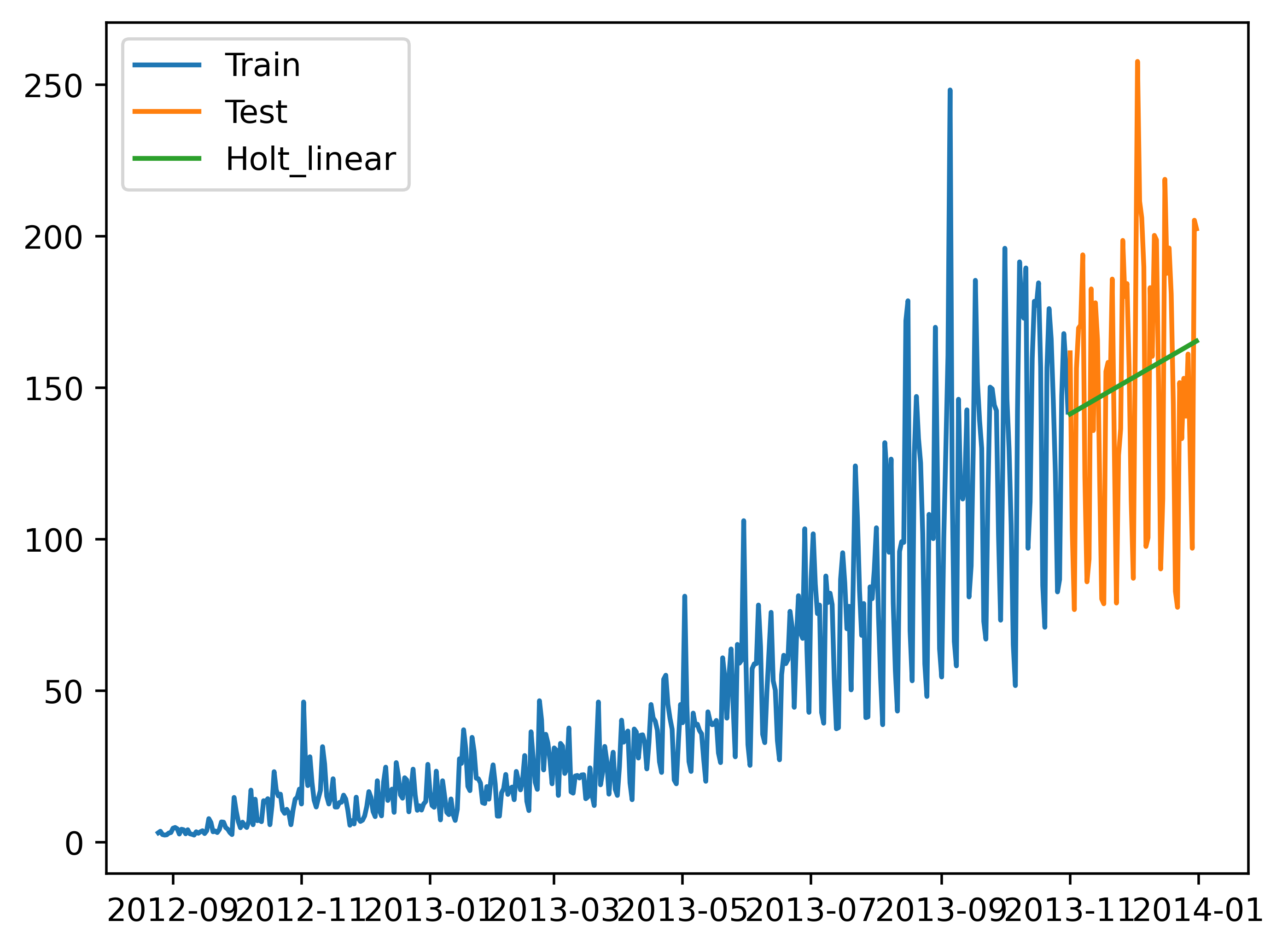
10.时间预测序列经典算法6:Holt-Winters季节性预测算法
"""
经典算法6:Holt-Winters季节性预测算法
我们之前在面临波动较大的数据的时候显得就是束手无策了,很显然前5种算法对于波动值的处理都不尽如人意!
所以造成了我们的预测有的时候就往往误差过大,预测不够精准!
我们之前讨论的5种模型在预测时并没有考虑到数据集的季节性,因此我们需要一种能考虑这种因素的方法。
应用到这种情况下的算法就叫做Holt-Winters季节性预测模型。
它是一种三次指数平滑预测,其背后的理念就是除了水平和趋势外,还将指数平滑应用到季节分量上。
Holt-Winters季节性预测模型由预测函数和三次平滑函数——一个是水平函数ℓt,一个是趋势函数bt,一个是季节分量 st,以及平滑参数α,β和γ。
在Holt-Winters算法中,我们采用的是相加和相乘的方法:
当季节性变化大致相同时,优先选择相加方法,
当季节变化的幅度与各时间段的水平成正比时,优先选择相乘的方法。
这样进行的预测值可能会更加合理一些!
"""from statsmodels.tsa.api import ExponentialSmoothing
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_Winter'], label='Holt_Winter')
plt.legend(loc='best')
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列7.png', dpi=500, bbox_inches='tight')
plt.show()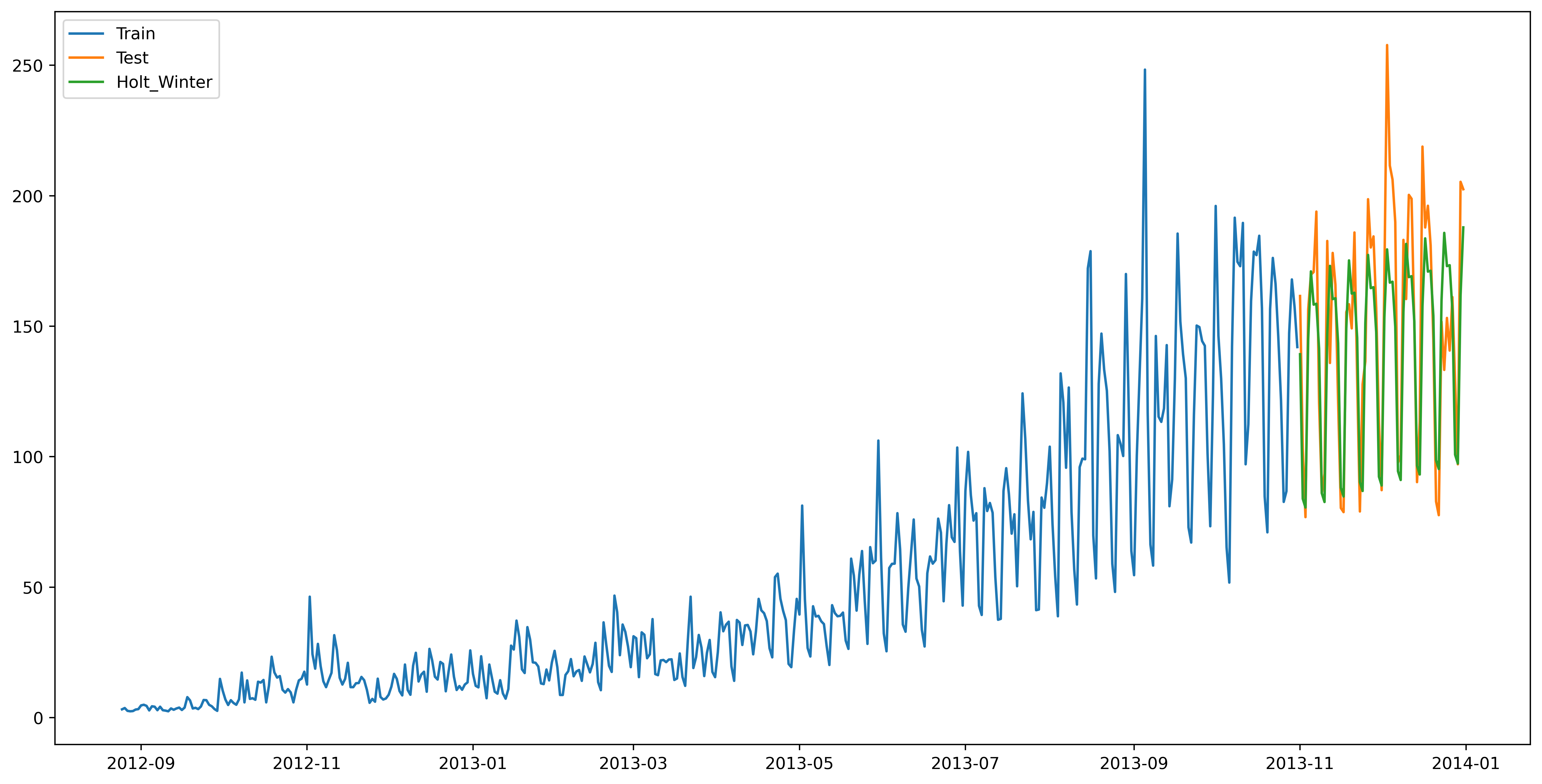
11.时间预测序列经典算法7:自回归移动平均(ARIMA)算法
"""
经典算法7:自回归移动平均(ARIMA)算法
ARIMA算法是前面提到的经典算法的集大成者,
首先我们考虑到可指数平滑模型都是基于数据中的趋势和季节性的描述,
同时我们考虑回归移动平均模型的目标是描述数据中彼此之间的关系。
综合的结果使得我们预测出来的值会更加的合理,预测值和对应的测试值拟合的越来越成功
"""import statsmodels.api as sm
y_hat_avg = test.copy()
fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4), seasonal_order=(0, 1, 1, 7)).fit()
y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
plt.legend(loc='best')
plt.savefig('C:/Users/Zeng Zhong Yan/Desktop/时间序列8.png', dpi=500, bbox_inches='tight')
plt.show() 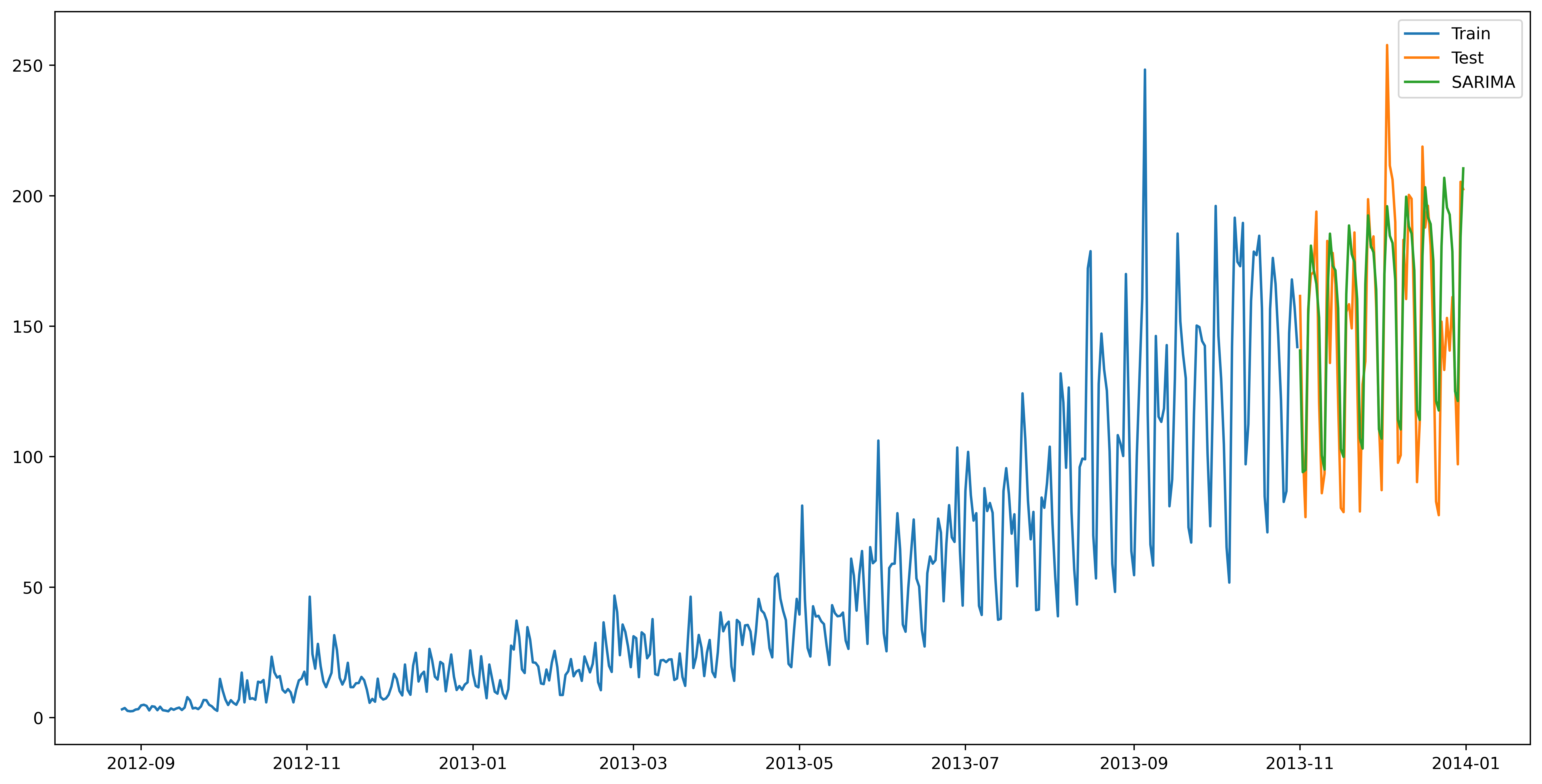
12.参考文章和致谢
"""
#参考文章和致谢:
首先代码主要来源于:https://www.cnblogs.com/lfri/articles/12243268.html#gallery-5
如果我在每一个算法中都有解释,如果还不能够明白,请跳转至原文章来进行学习,作者深入浅出的教学以及比较细致的类比和公式一定能过使你明白时间序列预测模型!
在这里我感谢这篇文章对我的帮助,首先是有完全的数据集可使用,其次是带我完整地进行了一次python的项目分析,使我受益匪浅!
再次感谢文章和作者对于我的启发和帮助!
"""