如果你曾经使用过nnUNet V1,那你一定明白数据集的命名是有严格要求的,必须按照特定的格式来进行命名才能正常使用。
这一节的学习需要有数据,如果你有自己的数据,可以拿自己的数据来实验,如果没有,可以用十项全能数据集,在之前分享过
nnUNet实战一使用预训练nnUNet模型进行推理,这篇文章里有数据集的下载地址和方法。如果网络问题下载不下来,可以微我。
nnUNet v2 支持的数据格式
在V2版本中支持的数据格式类型更多,默认情况下,支持以下文件格式:
- NaturalImage2DIO:.png、.bmp、.tif
- NibabelIO:.nii.gz、.nrrd、.mha
- NibabelIOWithReorient:.nii.gz、.nrrd、.mha。该阅读器会将图像重新定向为 RAS!
- SimpleITKIO:.nii.gz、.nrrd、.mha
- Tiff3DIO:.tif、.tiff。3D tif 图像!由于 TIF 没有存储间距信息的标准化方法,因此 nnU-Net 期望每个 TIF 文件都附带一个同名的 .json 文件,其中包含三个数字(没有单位,没有逗号。只是用空格分隔),每个数字一个方面。
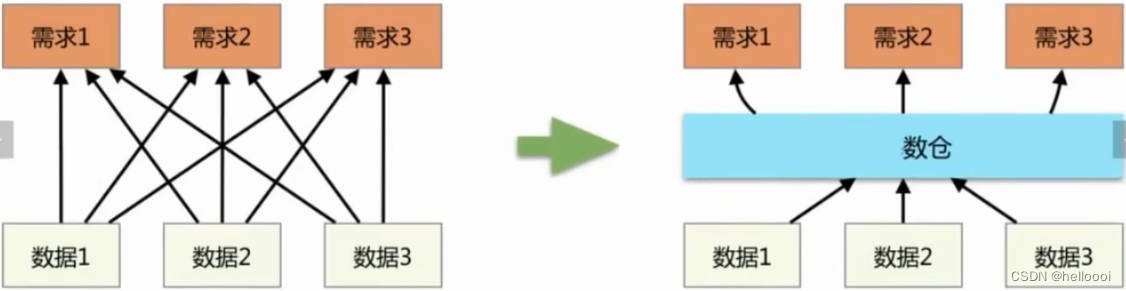
nnU-Net V2 的一大变化是支持多种输入文件类型。将所有内容转换为 .nii.gz 的日子已经一去不复返了!nnU-Net 附带了广泛的读取器+写入器集合,您甚至可以添加自己的读取器+写入器来支持您的数据格式!请参阅此处。
数据集文件夹结构
数据集必须位于该nnUNet_raw文件夹中,
nnUNet_raw/
├── Dataset001_BrainTumour
├── Dataset002_Heart
├── Dataset003_Liver
├── Dataset004_Hippocampus
├── Dataset005_Prostate
├── ...
在每个数据集文件夹中,具有以下结构:
Dataset001_BrainTumour/
├── dataset.json
├── imagesTr
├── imagesTs # optional
└── labelsTr
nnUNet_raw/Dataset001_BrainTumour/
├── dataset.json
├── imagesTr
│ ├── BRATS_001_0000.nii.gz
│ ├── BRATS_001_0001.nii.gz
│ ├── BRATS_001_0002.nii.gz
│ ├── BRATS_001_0003.nii.gz
│ ├── BRATS_002_0000.nii.gz
│ ├── BRATS_002_0001.nii.gz
│ ├── BRATS_002_0002.nii.gz
│ ├── BRATS_002_0003.nii.gz
│ ├── ...
├── imagesTs
│ ├── BRATS_485_0000.nii.gz
│ ├── BRATS_485_0001.nii.gz
│ ├── BRATS_485_0002.nii.gz
│ ├── BRATS_485_0003.nii.gz
│ ├── BRATS_486_0000.nii.gz
│ ├── BRATS_486_0001.nii.gz
│ ├── BRATS_486_0002.nii.gz
│ ├── BRATS_486_0003.nii.gz
│ ├── ...
└── labelsTr
├── BRATS_001.nii.gz
├── BRATS_002.nii.gz
├── ...
需要注意的是,与第一版本中的文件夹及数据集命名有些许差别

比如,第一版数据集用 TaskXXXX, V2版本用 DatasetXXX
dataset.json 文件构建
第二版本的 dataset.json 文件也发生了变化
dataset.json 包含 nnU-Net 训练所需的元数据。自版本 1 以来,我们大大减少了必填字段的数量! (第一版见 nnUNet实战一使用预训练nnUNet模型进行推理)
以下是 MSD 的 Dataset005_Prostate 示例中的 dataset.json 的样子:
{
"channel_names": { # formerly modalities
"0": "T2",
"1": "ADC"
},
"labels": { # THIS IS DIFFERENT NOW!
"background": 0,
"PZ": 1,
"TZ": 2
},
"numTraining": 32,
"file_ending": ".nii.gz"
"overwrite_image_reader_writer": "SimpleITKIO" # optional! If not provided nnU-Net will automatically determine the ReaderWriter
}
Channel_names 确定 nnU-Net 使用的归一化。如果通道被标记为“CT”,则将使用基于前景像素强度的全局归一化。如果是其他情况,将使用 per-channel z-scoring
相对于 nnU-Net v1 的重要变化:
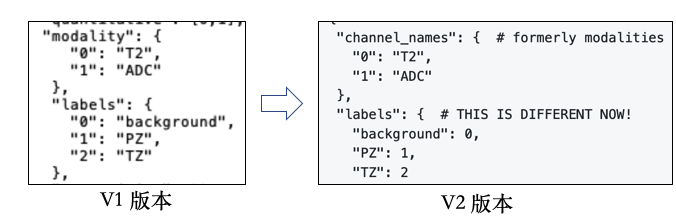
modality现在称为channel_names,以消除对医学图像的强烈偏见- Lable 的结构不同(name -> int 而不是 int -> name)。这样做的好处有助于层次标签的使用,具体见 【nnUNet v2版本与V1版有什么不同?】 这一部分
- 添加
file_ending字段:以支持不同的输入文件类型 overwrite_image_reader_writer可选!可用于指定ReaderWriter 类。如果不提供,nnU-Net会自动判断ReaderWriterregions_class_order仅用于基于regions的训练,具体见 region based trianing
由于V2版中,不需要指定训练和测试集的图像名字,减少了很多字段,构建起来就很简单了。可以把上述 dataset.json 复制下来,按照自己的数据集手动修改一下。
nnUNet v1 的数据格式如何转换为 V2 的格式
假设有一个数据集已经在 V1 上跑过了,如果您要从 v1 上迁移过来,请使用nnUNetv2_convert_old_nnUNet_dataset转换现有数据集。
迁移 nnU-Net v1 任务的示例:
nnUNetv2_convert_old_nnUNet_dataset INPUT_FOLDER OUTPUT_FOLDER
eg: nnUNetv2_convert_old_nnUNet_dataset /nnUNet_raw_data_base/nnUNet_raw_data/Task131_WORD/ Dataset131_WORD
- input_folder:指的是 V1 版本里要转换的数据(需要给出具体地址)
- output_folder: 只需要给出名字,不需要具体地址
此处迁移,主要是自动帮你修改 dataset.json.并帮你把数据放入 V2 的 nnUNet_raw 文件夹里面去
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连