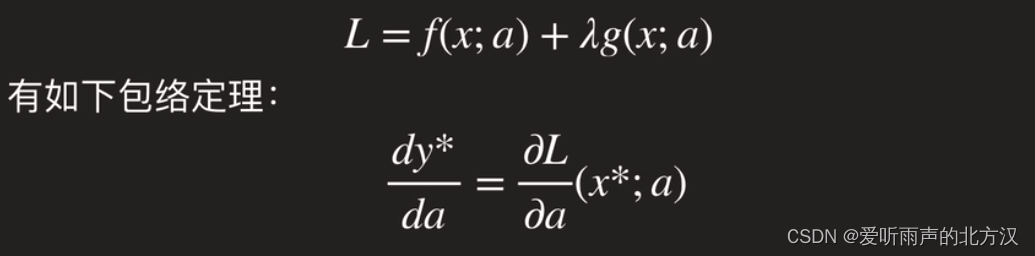Learning Transferable Visual Models From Natural Language Supervision
- 前言
- Abstract
- 1. Introduction and Motivating Work
- 2. Approach
- 2.1. Creating a Sufficiently Large Dataset
- 2.2. Selecting an Efficient Pre-Training Method
- 2.3. Choosing and Scaling a Model
- 2.4. Pre-training
- 2.5. Using CLIP
- 3. Analysis
- 3.1. Initial Comparison to Visual N-Grams
- 3.2. Zero-Shot Performance
- 3.3. Representation Learning
- 3.4. Robustness to Natural Distribution Shift
- 4. Data Overlap Analysis
- 5. Broader Impacts
- 6. Limitations
- 7. Related Work
- 8. Conclusion
- 阅读总结
前言
CLIP作为多模态对比学习里程碑式工作,在创新性,有效性和领域性三个方面都拉满了。它最伟大的地方在于,打破了固有的基于给定类别分类的壁垒,让即使是未见过的类也能给出很好的结果,这大大提升了模型的灵活性,也让其更适配多种下游任务。
| Paper | http://proceedings.mlr.press/v139/radford21a/radford21a.pdf |
|---|---|
| Code | https://github.com/OpenAI/CLIP |
| From | ICML2021 |
Abstract
目前CV系统最佳的模型都是基于固定对象类别进行训练的。这种监督训练方式限制了它们的通用性和可用性,直接从原始文本中学习图像是一种很有前途的替换方案,它可以利用更广泛的监督来源。作者证明,通过预测图像和其对应文本的简单预训练任务是一种高效可扩展的方案。作者从互联网上收集了4亿对图文数据,并在该数据集上重头开始训练。预训练后,通过自然语言来引导学习的视觉概念,实现在下游任务零样本迁移。作者研究了30多个下游任务上CLIP的性能,包括OCR、视频动作识别等,CLIP可以轻松迁移到各种任务上,甚至达到了完全监督训练的结果。
1. Introduction and Motivating Work
直接从原始文本中学习的预训练方法彻底改变了NLP领域,典型的模型如GPT-3,几乎不需要特定于数据集的训练就可以在很多下游任务上取得很好的结果。这一结果表明,大规模无标注数据集可实现的总体监督超过了高质量的人工标注数据集。但是在CV领域,主流的做法仍然是在监督数据集上预训练,亟待无监督的预训练方法在CV中带来突破。
此前就有科研人员在CV无监督学习上进行尝试。包括对图片和其caption建模,采用基于Transformer的机构建模,掩码语言建模以及对比学习等方法从文本中学习图像的表示潜力。
但是上述的方法仍然低于领域的SOTA。作者认为gap的产生主要来自于规模,因此作者研究大规模自然语言监督训练图像模型的行为。最后作者提出了CLIP模型用于对比语言图像预训练,这是一种从自然语言监督中学习的高效且可扩展的方法。
CLIP在预训练期间学习执行一系列任务,效果优于公开可用的ImageNet模型,并且计算高效。作者还发现CLIP模型在零样本下甚至能够达到监督训练的效果。
2. Approach
2.1. Creating a Sufficiently Large Dataset
作者发现,现有的图文数据集如MS-COCO、Visual Genome,虽然质量很高,但是规模太小,只有10万规模的数据。作为对比,其他CV系统在多达35亿张图像的Instagram数据集上训练。YFCC100M数据集虽然规模上亿,但是质量过低。因此作者构建了一个包含四亿对图文的数据集,这些数据从互联网各种公开来源收集。该数据集称作WIT。
2.2. Selecting an Efficient Pre-Training Method
作者最初的方法也是采用生成式方法来预测图像的标题,但是这种方法计算量大,效率低下。如下图所示:
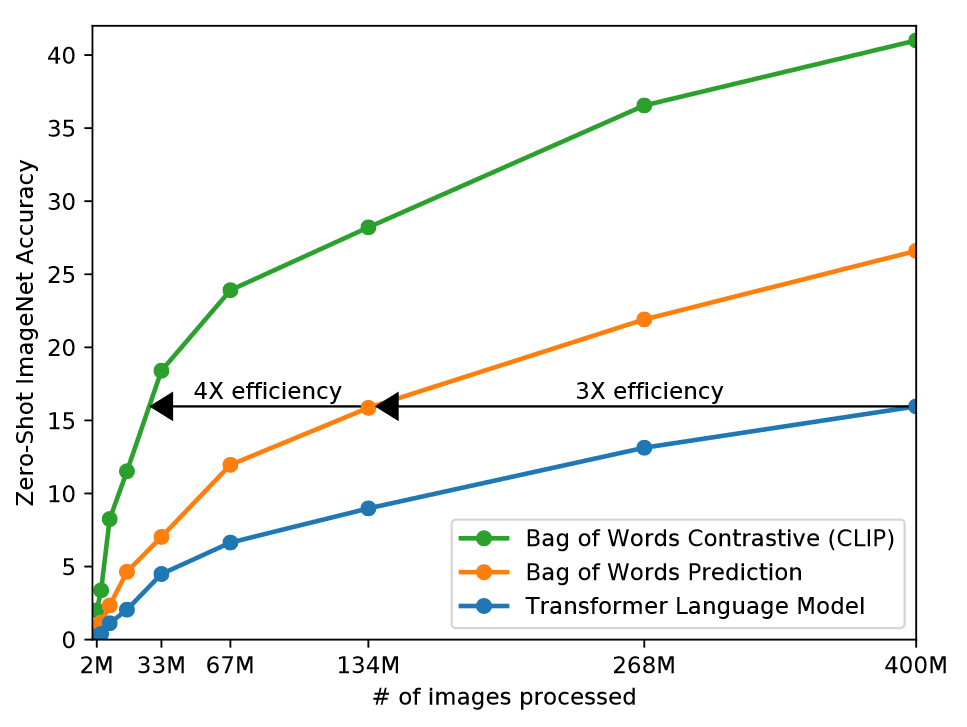
因此作者探索一个系统可以解决更容易的代理任务。作者发现,如果将预测任务更换为文本与哪个图像配对,即换成对比学习的方法,效率提升了四倍。
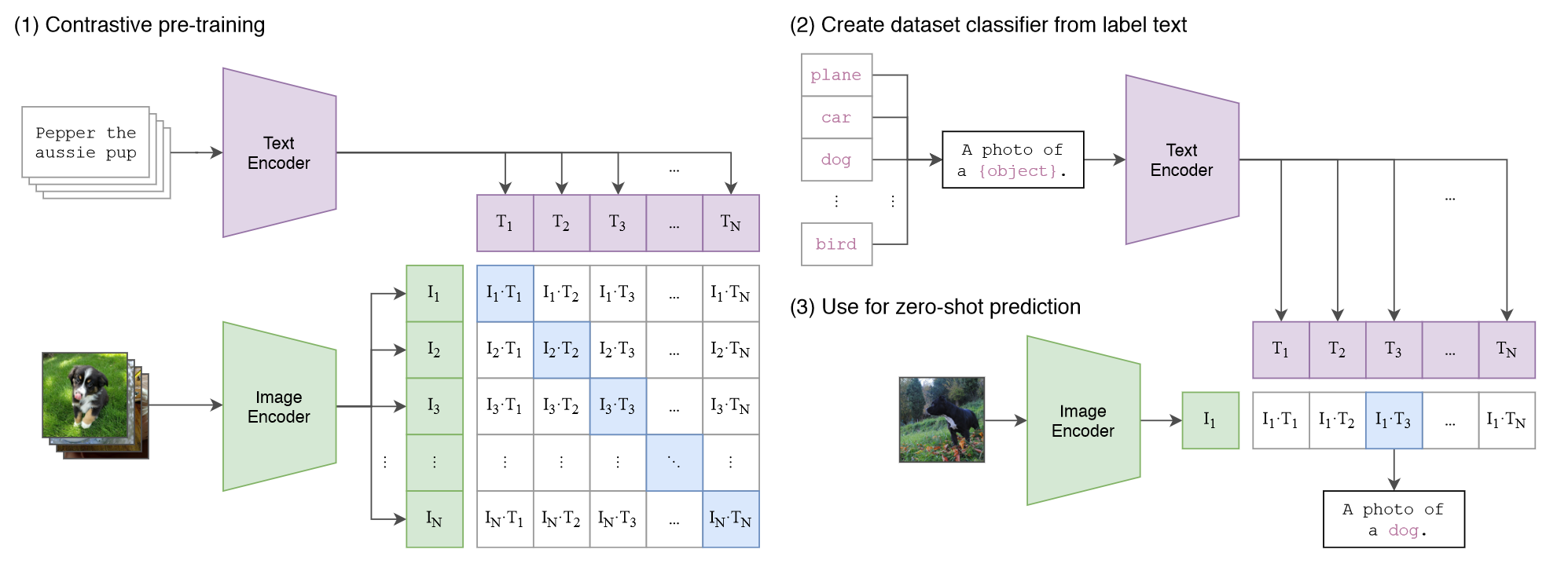
整体的过程第二节开头的流程图和下面的伪代码所示:

给定一批图文对,分别用两个编码器对图文进行编码,图片的编码器可以是ResNet,也可以是ViT;文本的编码器是Transformer。CLIP通过联合训练图像和文本编码来学习多模态嵌入空间,以最大化批次中N个图像和其对应文本的余弦相似度,并最小化与其它
N
2
−
N
N^2-N
N2−N个负样本的余弦相似度。
由于模型规模和数据集相匹配,CLIP不会出现过拟合的问题。作者重头开始训练CLIP,并且将表示对比嵌入空间之间的非线性投影替换为了线性投影。作者还删除了文本转换函数,简化了图像转换函数,只保留了随机裁剪的数据增强。最后作者将温度
τ
\tau
τ优化为可学习参数(调参成本太高了)。
2.3. Choosing and Scaling a Model
作者考虑了两个不同的图像编码架构,即ResNet50和ViT。前者使用广泛,后者潜力无限。文本编码器采用Transformer。作者分别对这些模型进行了简单的变体,具体可见原文。
2.4. Pre-training
作者训练了5种ReNets和3种ViT,ResNet分别采用了RestNet50,ResNet101,以及另外三个变体,RN50×4,RN50×16,RN50×64,代表相对ResNet50的计算量。对于ViT,训练了ViT-B/32、ViT-B/16和ViT-L/14。最好的训练模型是ViT-L/14@336px,后面所提到的CLIP都是指该模型。
这里@336px代表的是以336像素的分辨率额外进行了预训练,从而提升模型的性能,该方法在FixRes上得到证实。
2.5. Using CLIP
CLIP经过预训练,可以预测图像和其对应的文本是否在WIT中配对。为了探索CLIP应用于下游任务的功能,作者对其进行了零样本性能测试。对于每个数据集,作者使用数据集中的类作为潜在的文本配对的集合。此外,作者还尝试为CLIP提供文本prompt以提升性能。
3. Analysis
3.1. Initial Comparison to Visual N-Grams
Visual N-Grams方法是已知和本文类似的工作,同样进行了zero-shot迁移。下表是CLIP和Visual N-Grams的zeroshot对比:

在ImageNet上,CLIP将性能从11.5%提升到76.2%。并且达到了与原始ResNet相近的性能。此外,CLIP的Top-5准确率明显更高,当然这样的比较并不公平,Visual N-Grams无论从模型大小还是训练数据的规模都远远落后于CLIP。
3.2. Zero-Shot Performance
CV中的zero-shot一般指的是对未见目标的泛化,本文在更广泛的意义上定义该任务,即对未见的数据集的泛化。虽然无监督学习的研究集中在学习表征上,但是本文希望其作为衡量机器学习特定任务的学习能力。从这个角度出发,一个数据集用于评估特定分布上任务的表现,但是许多热门CV数据集的构建是作为基线指导通用图像分类方法的开发,而不是衡量特定任务的性能。
作者在30多个数据集上进行评估,并与50多个现有的CV系统进行比较。首先是CLIP在分类任务上的表现与监督ResNet50的对比,如下所示:
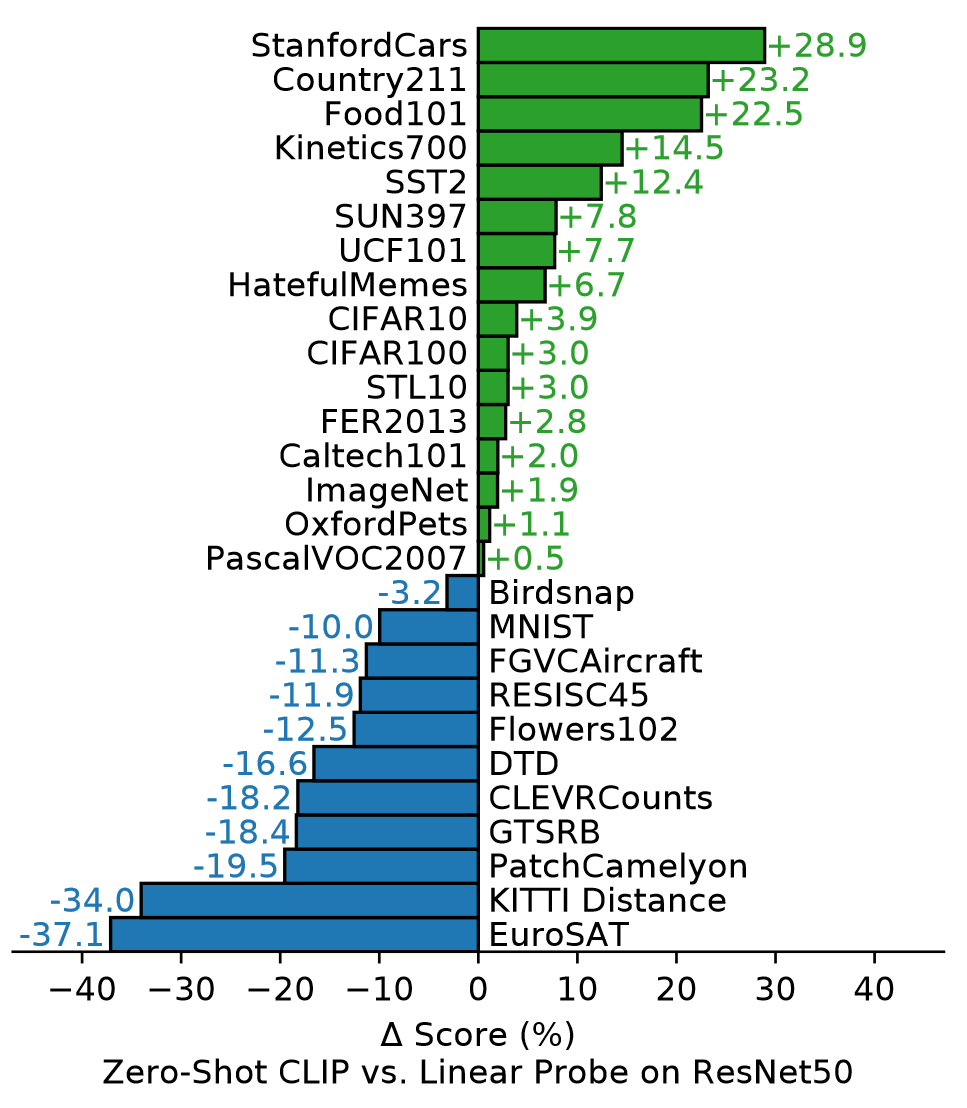
CLIP在27个数据集中的16个上取得更好的性能。对于细粒度的分类任务上,CLIP的优势明显,作者推测自然语言为涉及动词的视觉概念提供了更广泛的监督。在一些专门、复杂或抽象上的任务上,CLIP表现相当薄弱,这些结果表明了CLIP在更复杂的任务上能力较差,可能的原因是缺乏相应的领域知识。
虽然将CLIP的零样本能力和完全监督模型进行比较可以体现CLIP的任务学习能力,但是小样本可以是更直接的比较,零样本可以认为是极限的小样本任务。下图可视化了多个模型线性层微调的小样本性能,当然也包括了CLIP的零样本性能。
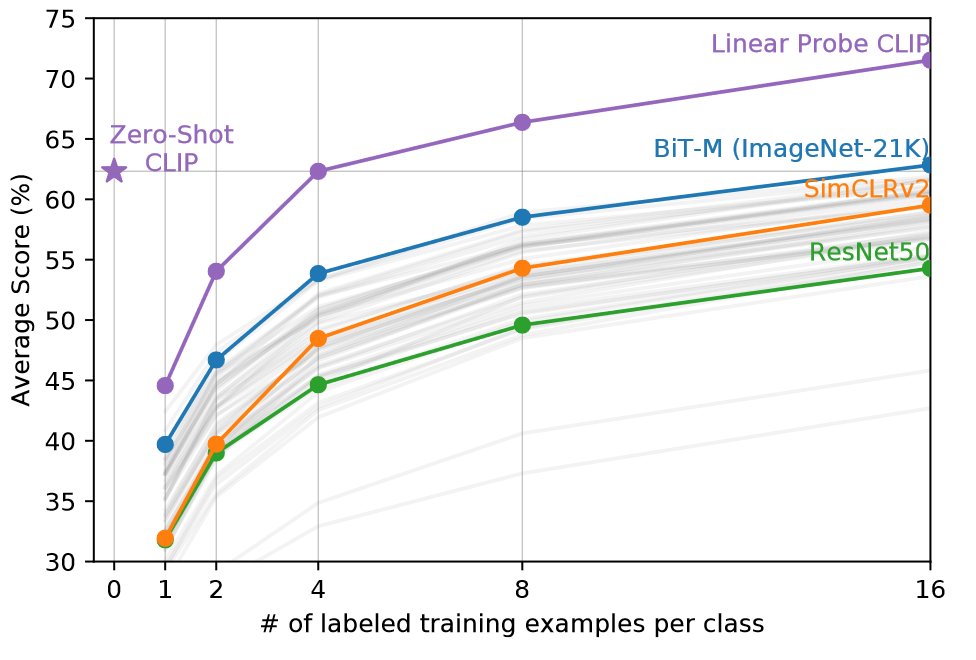
有趣的是,4-shot以下的CLIP性能不如零样本CLIP,这是二者方法之间差异导致的,零样本CLIP通过自然语言引导,可以直接具体化视觉概念,但是监督学习需要间接从训练样本中推断概念。但是基于自然语言引导的学习缺点是许多不同的假设和数据保持一致,即不能再提供更细致化的视觉信息,因此当样本数量增多,监督学习的性能还是超过了零样本性能。
和其他模型相比,CLIP的小样本性能都要更优。
3.3. Representation Learning
与其惊叹于CLIP的零样本能力,不如关注于CLIP的表征学习能力。作者对多个模型进行线性层全量数据集微调,得到如下图的结果:
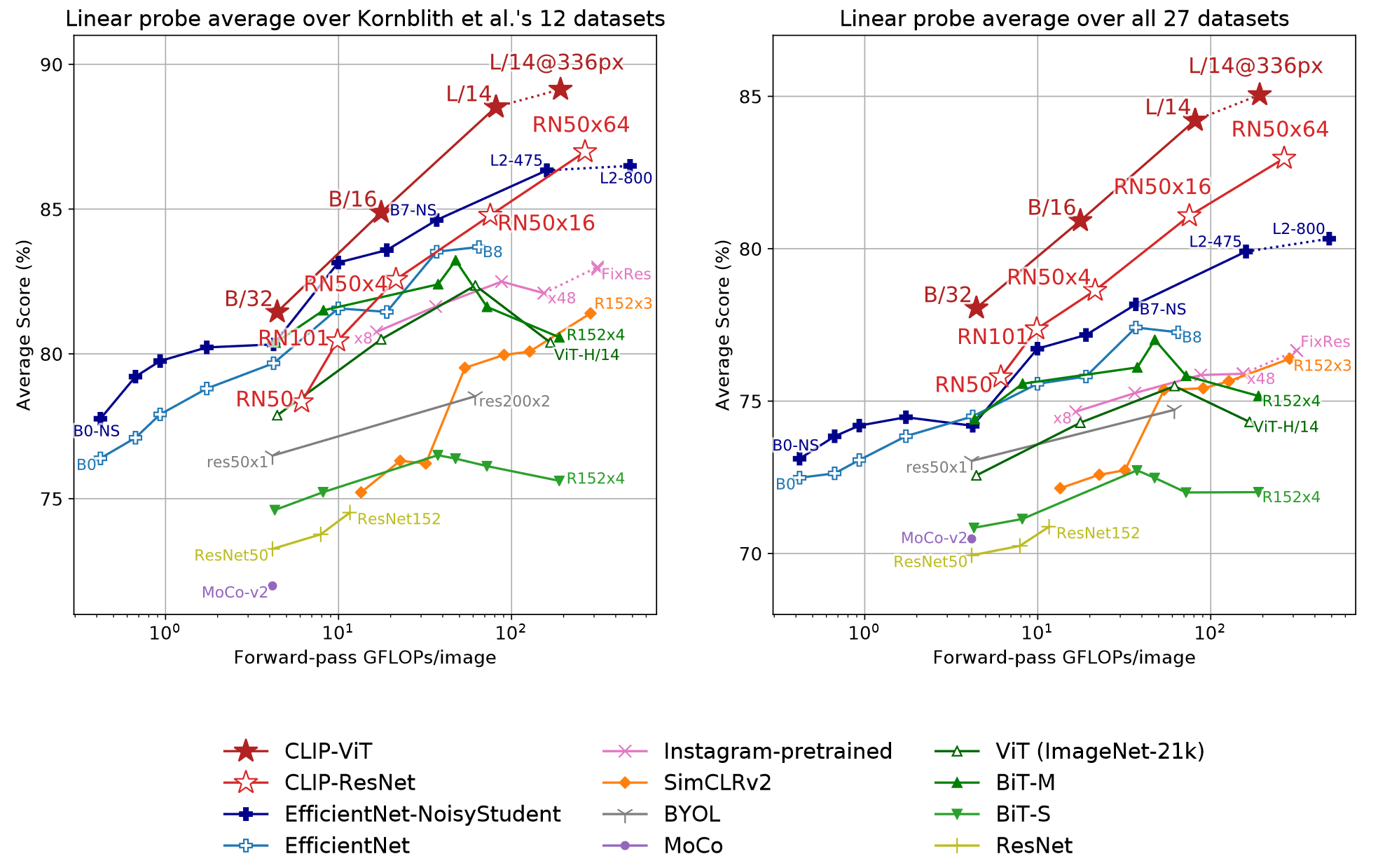
最好的CLIP模型比现有最好的模型平均高出2.6%,此外,与之前端到端训练的单个计算机视觉模型相比,CLIP模型可以学习到更广泛的任务,结果如右图所示,这是在27个更广泛的数据集上评估的性能。CLIP的优势更加明显,比之前系统提升了2.6%到5%。
3.4. Robustness to Natural Distribution Shift
虽然深度学习在ImageNet的性能超过了人类的判断,但是其仍会出现很多简单的错误。作者认为是否是因为训练和微调都是在ImageNet数据集上进行了,所以来带了观察上鲁棒性的gap。而CLIP并没有在ImageNet上训练,只是做零样本学习,直观上不会利用领域的特定模式或关系。所以CLIP理应表现更高的鲁棒性。下图是零样本CLIP与现有模型在自然分布变化上的性能。
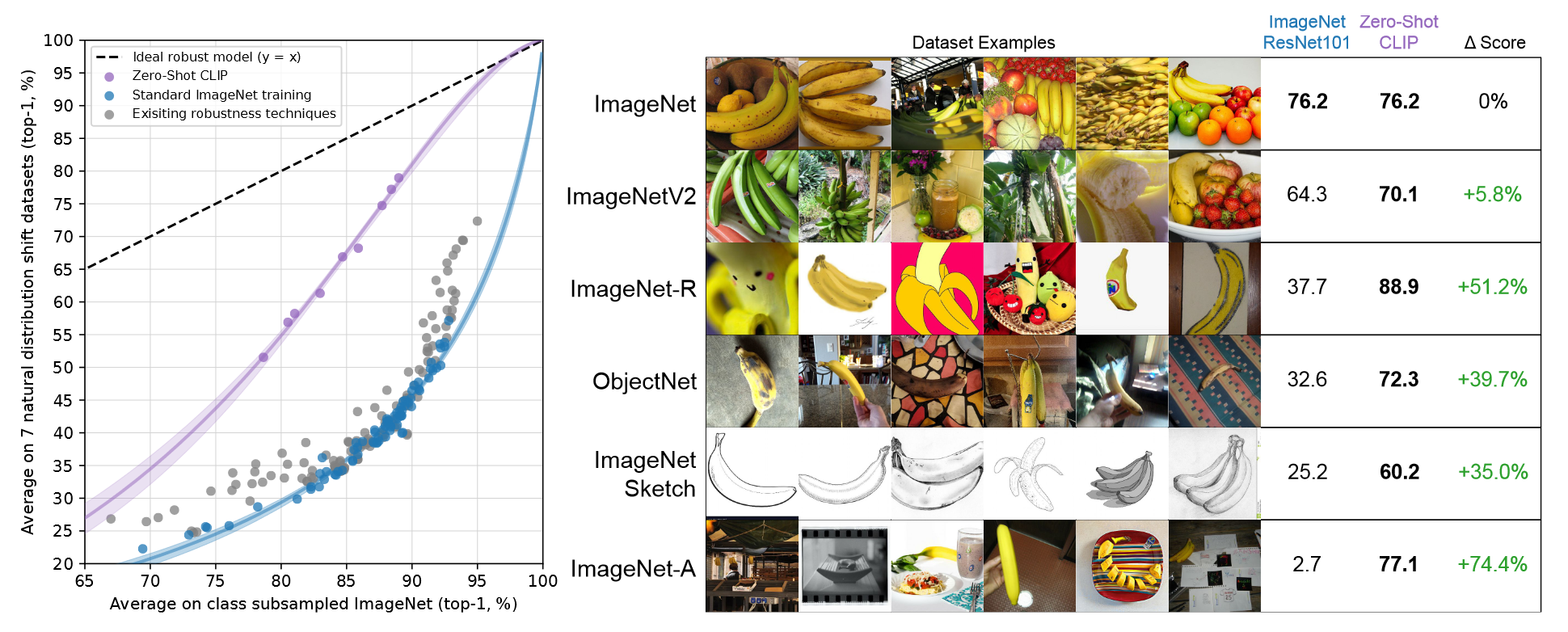
所有CLIP模型都大幅提高了鲁棒性。这些结果表明,最近面向大规模任务和数据集无关的预训练的转变,可以提供对真实模型性能更准确的评估。
4. Data Overlap Analysis
CLIP性能表现如此好,是否是因为收集得到的4亿样本有下游任务上的数据泄露?为此作者进行了重复数据删除分析。在研究的35个数据集中,有9个数据没有重叠,平均重叠为3.2%,重叠量很小,对结果的影响微乎其微。
5. Broader Impacts
CLIP由于数据集分布的问题,可能会带来一定的偏见。包括种族,性别,年龄的歧视问题。作者希望这项工作能够激发未来对此类模型的能力、缺点和偏差的表征的研究。
6. Limitations
零样本的CLIP只能和传统的ResNet-50基线模型进行比较,远低于现有的SOTA。当前的硬件不足以支撑其达到SOTA的能力。因此有必要进一步研究提高CLIP计算和数据效率。
尽管作者强调零样本的迁移,但是还是反复通过测试性能来指导开发(即调参)。因此作者希望能够有个专门的评估数据集,只用于评估,而不作为调参的工作。
7. Related Work
略。
8. Conclusion
本文提出CLIP,用于研究其迁移学习的能力。为了优化其目标,作者采用自然语言引导的方式来利用模型学习到的特征,实现零样本迁移。在足够的规模下,这种方法的性能可以与特定任务的监督模型相媲美,尽管仍有很大的改进空间。
阅读总结
CLIP作为一种多模态对比学习方法,在创新性,有效性和领域性三个领域上都拉满了,可谓是十分硬核的里程碑式的工作。创新性上,作者采用了文本和图像两个模态信息进行对比学习,让模型同时学到文本和视觉语义信息;零样本实验采用自然语言引导,帮助模型理解任务。有效性上,零样本的CLIP可以达到监督训练ResNet-50的性能,线性层微调也超过了当前多个SOTA方法。领域性上,CLIP是无监督学习方法,本质上是对图像表征的学习,通过文本和图像两个模态信息的结合,CLIP可以学习到强大的表征,在多个CV下游任务上经过简单的微调甚至是零样本,就能得到部分领域的SOTA性能。
由于最近对无监督学习有比较多的理解,在我看来,CLIP这篇工作还有很多可以改进的地方,首先对比学习可以采用生成式的代理任务,更难的代理任务往往能学习到更复杂的表征。其次预训练的数据集可以是清理过的数据,并且进一步扩大规模,图像的编码器可以换成swin Transformer,能够学习到更复杂的图像表征。