0x0. 前言
我的 ChatRWKV 学习笔记和使用指南 这篇文章是学习RWKV的第一步,然后学习了一下之后决定自己应该做一些什么。所以就在RWKV社区看到了这个将RWKV World系列模型通过MLC-LLM部署在各种硬件平台的需求,然后我就开始了解MLC-LLM的编译部署流程和RWKV World模型相比于MLC-LLM已经支持的Raven系列模型的特殊之处。
MLC-LLM的编译部署流程在MLC-LLM的官方文档已经比较详细了,但这部分有一些隐藏的坑点需要你去发现,比如现在要支持的RWKV-World模型它的Tokenizer是自定义的,并不是Huggingface的格式,这就导致我们不能使用MLC-LLM去直接编译这个模型,也不能使用预编译好的MLC-LLM二进制库去运行这个模型了。另外,在编译MLC-LLM仓库之前我们需要先编译Relax仓库而不是原始的TVM仓库,Relax可以认为是TVM的一个fork,在此基础上支持了Relax这个新一代的IR,这部分背景建议读者看一下我这个仓库的相关链接:
https://github.com/BBuf/tvm_mlir_learn
这个仓库已经揽下1.4k star,谢谢读者们支持。
从RWKV社区了解到,RWKV-World系列模型相比于Raven系列,推理代码和模型都是完全一样,不一样的地方主要是tokenizer是自定义的,并且system prompt不同。
在编译Relax的时候需要按需选择自己的编译平台进行编译,编译完之后 MLC-LLM 会通过 TVM_HOME 这个环境变量来感知 Relax 的位置,并且Relax编译时开启的选项要和MLC-LLM编译的选项匹配上,这样才可以在指定平台上进行正确的编译和推理。
在适配 RWKV-World 1.5B时,由于模型比较小对逗号比较敏感,导致第一层就炸了精度,最终挂在sampler里面,这个地方我定位2个晚上,后来mlc-ai官方的冯思远告诉我在 MLC-LLM 里如何逐层打印精度之后,我最终定位到了问题。并且在 RWKV 社区里面了解到了这个现象之前就出现过,那就是1.5B的模型第一层需要用FP32来计算,不然会炸精度,我后续实验了RWKV-4-World 3B/7B,这个现象就没有了。
另外,模型的组织格式也是值得注意的一点,并不是在任意位置编译好模型都可以在运行时被 MLC-LLM 正确发现。我大概花了快一周工作外时间在 MLC-LLM 上来支持 RWKV-World 系列模型,工作内容主要为:
- 将大缺弦的 https://github.com/daquexian/faster-rwkv 仓库中的 RWKV World模型tokenizer实现挂到 mlc-ai 的 tokenizers.cpp 中,作为一个 3rd 库提供给MLC-LLM。合并的PR为:https://github.com/mlc-ai/tokenizers-cpp/pull/14。
- 在上面的基础上,在MLC-LLM中支持 RWKV World系列模型的部署,对齐 World 系列模型的 Prompt ,获得良好的对话效果。分别在 Apple M2和A800显卡上进行了部署和测试。PR为:https://github.com/mlc-ai/mlc-llm/pull/848 ,这个pr还wip,如果你现在要使用的话可以直接切到这个pr对应的分支就可以了。
- debug到1.5B RWKV World小模型会炸精度的bug,相当于踩了个大坑。
我要特别感谢 mlc-ai 官方的冯思远在我部署过程中提供的支持以及帮我Review让代码合并到 mlc-ai 社区,以及感谢大缺弦的 RWKV World Tokenizer c++实现以及在编译第三方库时帮我解决的一个bug。
以下是MLC-LLM 部署RWKV World系列模型教程,尽量提供大家部署最不踩坑的实践。
效果:

0x1. 将RWKV-4-World-7B部署在A800上
准备工作
- RWKV-4-World模型地址:https://huggingface.co/StarRing2022/RWKV-4-World-7B
- 下载这里:https://github.com/BBuf/rwkv-world-tokenizer/releases/tag/v1.0.0 的 tokenizer_model.zip并解压为tokenizer_model文件,这是RWKV World系列模型的Tokenizer文件。
- 克隆好 https://github.com/mlc-ai/mlc-llm 和 https://github.com/mlc-ai/relax ,注意克隆的时候一定要加上 –recursive 参数,这样才会把它们依赖的第三方库也添加上。
编译Relax
git clone --recursive git@github.com:mlc-ai/relax.git
cd relax
mkdir build
cd build
cp ../cmake/config.cmake ./
然后修改build目录下的config.cmake文件,由于我这里是在A800上面编译,我改了以下设置:
set(USE_CUDA ON)
set(USE_CUTLASS ON)
set(USE_CUBLAS ON)
即启用了CUDA,并开启了2个加速库CUTLASS和CUBLAS。然后在build目录下执行cmake .. && make -j32 即可。
最后可以考虑把Relax添加到PYTHONPATH环境变量里面使得全局可见,在~/.bashrc上输入以下内容:
export TVM_HOME=/bbuf/relax
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
然后source ~/.bashrc即可。
编译和安装MLC-LLM
git clone --recursive git@github.com:mlc-ai/mlc-llm.git
cd mlc-llm/cmake
python3 gen_cmake_config.py
执行python3 gen_cmake_config.py 可以按需选择需要打开的编译选项,比如我这里就选择打开CUDA,CUBLAS,CUTLASS,另外需要注意的是这里的 TVM_HOME 路径需要设置为上面编译的Relax路径。
然后执行下面的操作编译:
cd ..
mkdir build
cp cmake/config.cmake build
cd build
cmake ..
make -j32
这里编译时还需要安装一下rust,按照建议的命令安装即可,编译完成之后即安装上了mlc-llm提供的聊天程序mlc_chat_cli。然后为了做模型转换和量化,我们还需要在mlc-llm目录下执行一下pip install .安装mlc_llm包。
模型转换
模型转换这里基本就是参考这个教程了:https://mlc.ai/mlc-llm/docs/compilation/compile_models.html 。
例如我们执行python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-7B --target cuda --quantization q4f16_1 就可以将RWKV-4-World-7B模型权重量化为4个bit,然后activation还是以FP16的方式存储。

target 则指定我们要在什么平台上去运行,这里会将整个模型构成的图编译成一个动态链接库(也就是TVM的IRModule)供后续的mlc_chat_cli程序(这个是在编译mlc-llm时产生的)调用。
这里默认会在当前目录下新建一个dist/models文件夹来存量化后模型和配置文件以及链接库,转换和量化好之后的模型会存储在当前命令所在目录的dist子目录下(会自动创建),你也可以手动克隆huggingface模型到dist/models文件夹下。量化完之后的模型结构如下:

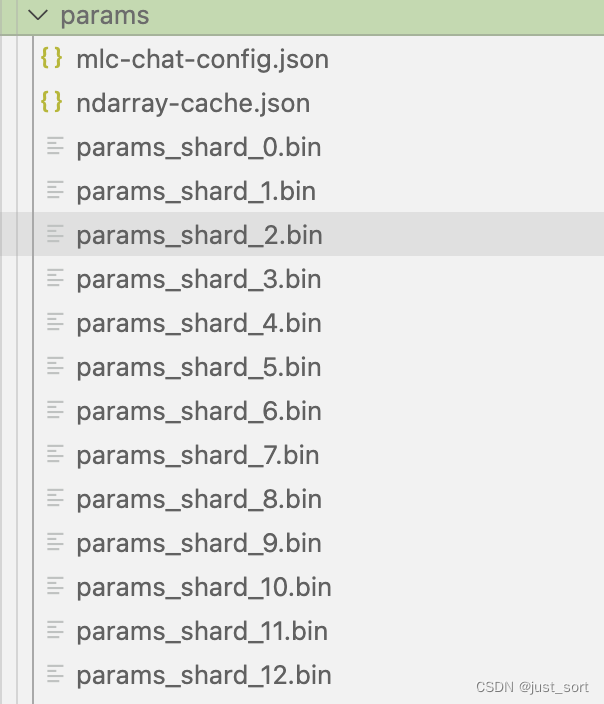
这里的mlc-chat-config.json指定来模型生成的一些超参数比如top_p,temperature等。
最后在推理之前,我们还需要把最开始准备的tokenizer_model文件拷贝到这个params文件夹中。
执行推理
我们在mlc-llm的上一层文件夹执行下面的命令:
./mlc-llm/build/mlc_chat_cli --model RWKV-4-World-7B-q0f16
RWKV-4-World-7B-q0f16可以换成你量化模型时的名字,加载完并运行system prompt之后你就可以愉快的和RWKV-4-World模型聊天了。

程序有一些特殊的指令来退出,查看速度等等:
性能测试
| 硬件 | 量化方法 | 速度 |
|---|---|---|
| A800 | q0f16 | prefill: 362.7 tok/s, decode: 72.4 tok/s |
| A800 | q4f16_1 | prefill: 1104.7 tok/s, decode: 122.6 tok/s |
这里给2组性能数据,大家感兴趣的话可以测测其它配置。
逐层debug方法
在适配1.5B模型时出现了推理结果nan的现象,可以用mlc-llm/tests/debug/dump_intermediate.py这个文件来对齐输入和tokenizer的结果之后进行debug,可以精准模拟模型推理并打印每一层的中间值,这样我们就可以方便的看到模型是在哪一层出现了nan。
0x2. 将RWKV-4-World-3B部署在Apple M2上
在mac上部署和cuda上部署并没有太大区别,主要是编译relax和mlc-llm的时候编译选项现在要选Metal而不是cuda了。我建议最好是在一个anconda环境里面处理编译的问题,不要用系统自带的python环境。
在编译relax的时候需要同时打开使用Metal和LLVM选项,如果系统没有LLVM可以先用Homebrew装一下。
在mlc-llm中生成config.cmake时使用下面的选项:
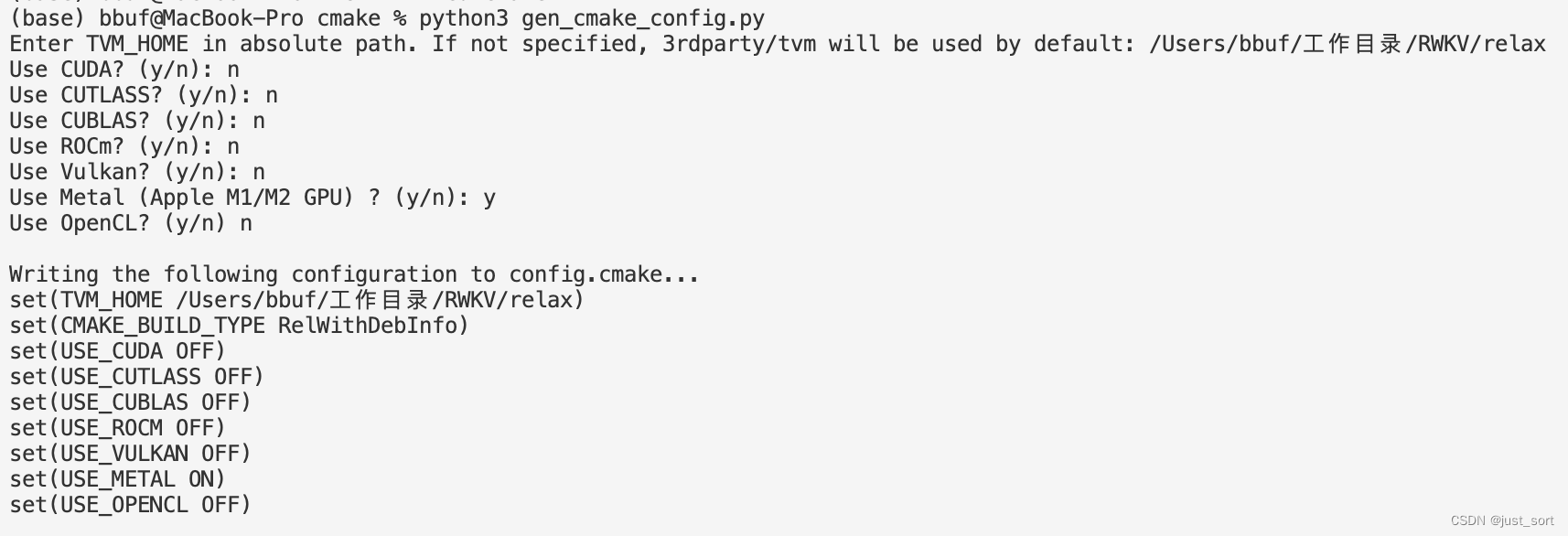 编译完并
编译完并pip install .之后使用下面的命令量化模型:
python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-3B --target metal --quantization q4f16_1
量化过程中日志如下:
(base) bbuf@MacBook-Pro RWKV % python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-3B --target metal --quantization q4f16_1
Weights exist at dist/models/RWKV-4-World-3B, skipping download.
Using path "dist/models/RWKV-4-World-3B" for model "RWKV-4-World-3B"
[09:53:08] /Users/bbuf/工作目录/RWKV/relax/src/runtime/metal/metal_device_api.mm:167: Intializing Metal device 0, name=Apple M2
Host CPU dection:
Target triple: arm64-apple-darwin22.3.0
Process triple: arm64-apple-darwin22.3.0
Host CPU: apple-m1
Target configured: metal -keys=metal,gpu -max_function_args=31 -max_num_threads=256 -max_shared_memory_per_block=32768 -max_threads_per_block=1024 -thread_warp_size=32
Host CPU dection:
Target triple: arm64-apple-darwin22.3.0
Process triple: arm64-apple-darwin22.3.0
Host CPU: apple-m1
Automatically using target for weight quantization: metal -keys=metal,gpu -max_function_args=31 -max_num_threads=256 -max_shared_memory_per_block=32768 -max_threads_per_block=1024 -thread_warp_size=32
Start computing and quantizing weights... This may take a while.
Finish computing and quantizing weights.
Total param size: 1.6060066223144531 GB
Start storing to cache dist/RWKV-4-World-3B-q4f16_1/params
[0808/0808] saving param_807
All finished, 51 total shards committed, record saved to dist/RWKV-4-World-3B-q4f16_1/params/ndarray-cache.json
Finish exporting chat config to dist/RWKV-4-World-3B-q4f16_1/params/mlc-chat-config.json
[09:53:40] /Users/bbuf/工作目录/RWKV/relax/include/tvm/topi/transform.h:1076: Warning: Fast mode segfaults when there are out-of-bounds indices. Make sure input indices are in bound
[09:53:41] /Users/bbuf/工作目录/RWKV/relax/include/tvm/topi/transform.h:1076: Warning: Fast mode segfaults when there are out-of-bounds indices. Make sure input indices are in bound
Save a cached module to dist/RWKV-4-World-3B-q4f16_1/mod_cache_before_build.pkl.
Finish exporting to dist/RWKV-4-World-3B-q4f16_1/RWKV-4-World-3B-q4f16_1-metal.so
同样也需要把tokenizer_model文件拷贝到量化后模型文件夹的params目录下,然后执行下面的命令启动聊天程序:
./mlc-llm/build/mlc_chat_cli --model RWKV-4-World-3B-q0f16
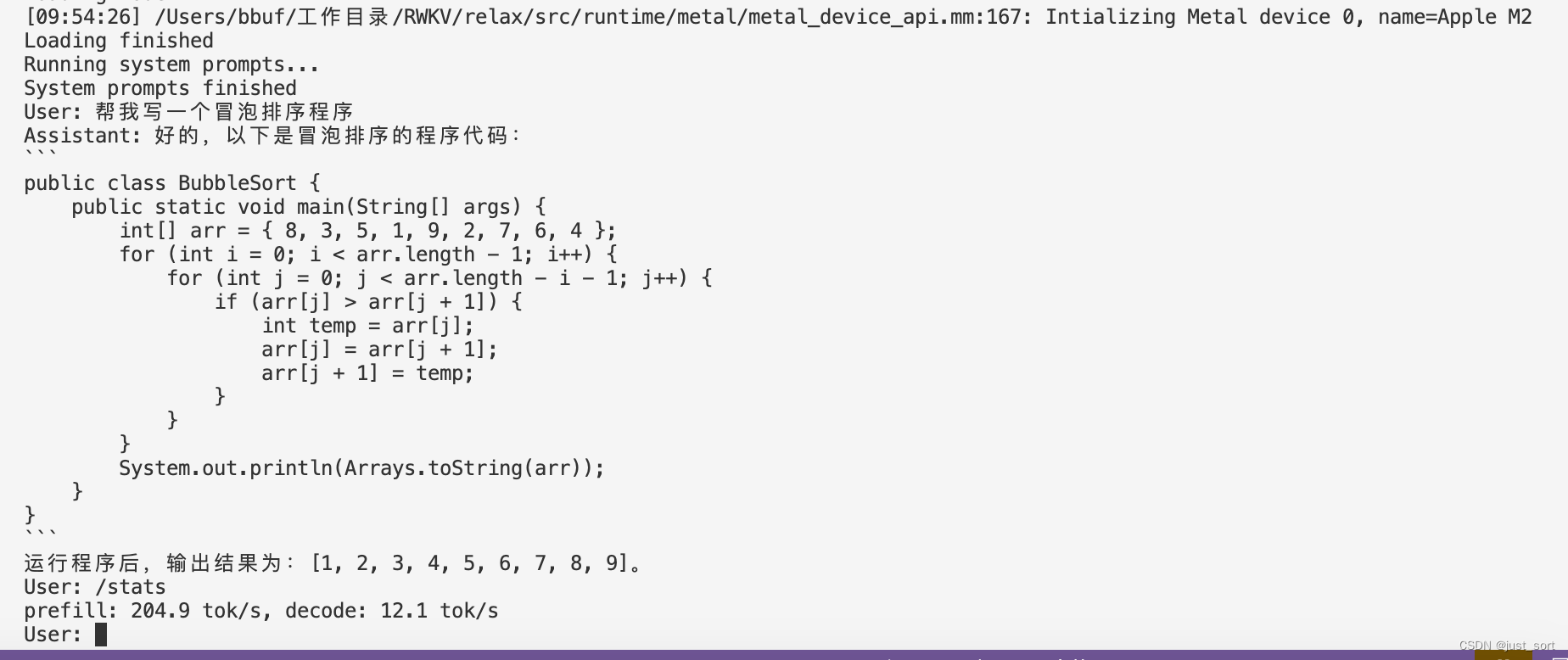
最后也来一个Mac M2的速度测试:
| 硬件 | 量化方法 | 速度 |
|---|---|---|
| Apple M2 | q0f16 | 204.9 tok/s, decode: 12.1 tok/s |
| Apple M2 | q4f16_1 | prefill: 201.6 tok/s, decode: 26.3 tok/s |
建议使用q4f16的配置,这样回复会快一些。
0x3. 总结
这篇文章介绍了一下笔者最近给mlc-llm做适配的工作,欢迎大家体验MLC-LLM和RWKV-World模型。