文章目录
- 框架介绍
- 模型类
- 视图
- 视图的功能
- 页面重定向
- 视图函数的使用
- url匹配过程
- 错误视图
- 补充
- 捕获url参数
- 类型介绍
- 普通登录案例(前情准备)
- HttpReqeust 对象
- HttpResponse 对象
- QueryDict 对象(即GET POST )
- 总结
- ajax
- ajax的登录样例
- 状态保持
- cookie
- Session
- 启用Session
- 对象以及使用方法
- 记住登录状态示例
- 模板
- 模板的功能
- 模板文件的使用
- 模板文件加载顺序
- 模板语言
- 变量
- 标签(模板中使用for和if函数)
- 过滤器(调用自己使用的函数)
- 注释
- 模板继承
- html转义
- csrf攻击
- 反向解析
- 补充 软件库下 url
- 前端反向解析(带参数)
- 后端的反向解析(带参数)
- 其他技术
框架介绍
模型类
见16 django框架(上)
视图
视图的功能
接收请求,进行处理,与 M 和 T 进行交互,返回应答。
返回 html 内容 HttpResponse,也可能重定向 redirect,还可以返回 json数据
页面重定向
服务器不返回页面,而是告诉浏览器再去请求其他的 url 地址:
将 return HttpResponse(‘ok’)改为 return HttpResponseRedirect(‘/index’),当然在头部需要增加HttpResponseRedirect 的引用包
def delete(request, bid):
'''删除点击的图书'''
# 1.通过 bid 获取图书对象
book = BookInfo.objects.get(id=bid)
# 2.删除
book.delete()
# 3.重定向,让浏览器访问/index
# return HttpResponseRedirect('/index')
return redirect('/index')
视图函数的使用
- 定义视图函数:request 参数必须有
- 配置 url:建立 url 和视图函数之间的对应关系。
url匹配过程
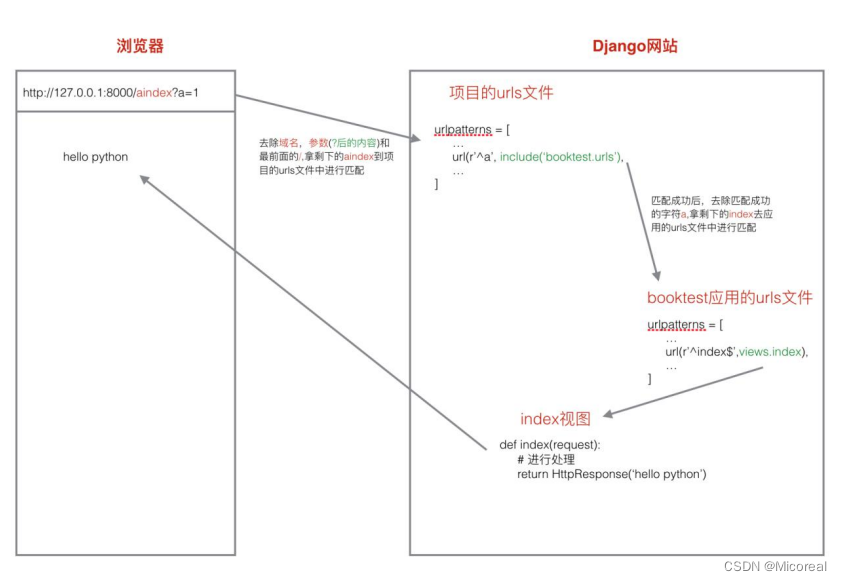
错误视图
404:找不到页面,关闭调试模式之后(在 setting.py 中修改 DEBUG 开关进行调试模式设置),默认会显示一个标准的错误页面,如果要显示自定义的页面,则需要的 templates 目录下面自定义一个 404.html 文件
404 错误
- url 没有配置
- url 配置错误
500: 服务器端的错误。
- 视图出错
补充
网站开发完成需要关闭调试模式,在 settings.py 文件中:
DEBUG=False
ALLOWED_HOST=[ '*'] #允许绑定的 IP 地址列表
比如在代码中增加 num =‘b’+1 这样的错误代码,就会出现 500 错误,当然我们也可以自己增加一个 500.html 页面,这样就会显示对应的内容,配置 400 和 505 页面需要重启 Django 服务器。
捕获url参数

关于path的理解,实际上这么一串数据,最后做到的就是将访问的url指向,匹配到对应的函数,并且将year ,month等等传递给相对应的视图函数。
类型介绍
- str - 匹配除了 ‘/’ 之外的非空字符串。如果表达式内不包含转换器,则会默认匹配字符串。
- int - 匹配 0 或任何正整数。返回一个 int 。
- slug - 匹配任意由 ASCII 字母或数字以及连字符和下划线组成的短标签。比如,building-your-1st-django-site 。
- uuid - 匹配一个格式化的 UUID 。为了防止多个 URL 映射到同一个页面 ,必 须包含破折号并且字符都为小写 。比如,075194d3-6885-417e-a8a86c931e272f00。返回一个 UUID 实例。
- path - 匹配非空字段,包括路径分隔符 ‘/’ 。它允许你匹配完整的 URL 路径而不是像 str 那样只匹配 URL 的一部分。
如果要用正则表达式,要用 re_path
普通登录案例(前情准备)
模板文件(login.html):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登录</title>
</head>
<body>
<form method="post" action="/login_check/">
用户名:<input type="text" name="username" value="{{ username }}"><br/>
密码:<input type="password" name="password"><br/>
<input type="checkbox" name="remember">记住用户名<br/>
<input type="submit" value="登录">
</form>
</body>
</html>
重点关注的对象是action:在模板文件中增加表单 form(注意 2.2 版本 action 必须是/login_check/,3.2版本可以采用/login_check),这边action的意思就是,当点击提交这个form表单的时候,跳转到url为/login_check的地方
还有这边定义的是采用post的方法进行上传信息:


HttpReqeust 对象
服务器接收到 http 协议的请求后,会根据报文创建 HttpRequest 对象,这个对
象不需要我们创建,直接使用服务器构造好的对象就可以。视图的第一个参数
必须是 HttpRequest 对象,在 django.http 模块中定义了 HttpRequest 对象的
API,实际上就是右键检查网络当中的-request header那一部分,而这一部分返回的值,会被返回到view视图的

关于request属性介绍:
- path:一个字符串,表示请求的页面的完整路径,不包含域名和参数部分。
- method:一个字符串,表示请求使用的 HTTP 方法,常用值包括 : ‘GET’,‘POST’,’PUT’,’DETELE’。
- encoding:一个字符串,表示提交的数据的编码方式。如果为 None 则表示使用浏览器的默认设置,一般为 utf-8。
- GET:QueryDict 类型对象,类似于字典,包含 get 请求方式的所有参数。
例:网址如下
http://www.cskaoyan.com/?a=10&b=20&c=python
其中的请求参数为:a=10&b=20&c=python
分析请求参数,键为’a’、‘b’、‘c’,值为’10’、‘20’、‘python’。
在 Django 中可以使用 HttpRequest 对象的 GET 属性获得 get 方方式请求的参数。GET 属性是一个 QueryDict 类型的对象,键和值都是字符串类型。 - POST:QueryDict 类型对象,类似于字典,包含 post 请求方式的所有参数。
使用 form 表单请求时,method 方式为 post 则会发起 post 方式的请求,需要使用 HttpRequest 对象的 POST 属性接收参数,提取数据和GET的方式一样。 - FILES:一个类似于字典的对象,包含所有的上传文件。
- COOKIES:一个标准的 Python 字典,包含所有的 cookie,键和值都为字符串。
- session:一个既可读又可写的类似于字典的对象,表示当前的会话,只有当 Django 启用会话的支持时才可用,详细内容见"状态保持"。
HttpResponse 对象
实际上就是右键查询网络的第二个 和 上面的进行区分。
视图在接收请求并处理后,必须返回 HttpResponse 对象或子对象。在django.http 模块中定义了 HttpResponse 对象的 API。HttpRequest对象由Django 创建,HttpResponse 对象由开发人员创建。
属性:
content:表示返回的内容。
charset:表示 response 采用的编码字符集,默认为 utf-8。
status_code:返回的 HTTP 响应状态码。
content-type:指定返回数据的的 MIME 类型,默认为’text/html
主要是两种方式使用 Response
- return HttpResponse(‘hello’)
- return render(request, ‘booktest/index.html’, {‘content’: 'hello})
QueryDict 对象(即GET POST )
与 python 字典不同,QueryDict 类型的对象用来处理同一个键带有多个值的情况。
使用方法:
- QueryDict.get(键) 得到的是一个值
- QueryDict.get(键,默认值) 当这个键不存在,就插入一个默认值键值对,并且返回自己
- QueryDict[键] 得到的也是一个值
- QueryDict.getlist(键) 由于QueryDict对象可能存在{‘a’:[1,2]},他的值是存储在一个列表当中的,即可以允许重复插入值。这个方法提取的就是全部的值
例子(补充login_check):
def login_check(request):
'''登录校验视图'''
# request.POST 保存的是 post 方式提交的参数 QueryDict
# request.GET 保存是 get 方式提交的参数 类型也是 QueryDict
username=request.POST.get('username')
password=request.POST.get('password')
print(username+':'+password)
return HttpResponse('ok')
总结
写的有点乱:整理一下流程
- 先写一个前端显示login.html,里面的表单中 关注method 代表以什么方式进行上传数据 和 action 代表当提交表单之后会传送到什么url
- 配置login的url,转向view.login函数
- 在login函数当中先不进行书写,这里是当我们访问登录页面的时候需要的操作,一般这里用来判断是否已经登陆过了,检查cookie内部是否存在登陆的账号,如果登录,转向别的别的页面,没的话,继续本页面
- 然后配置login_check 也就是action中的url
- 编写login_check 的函数,这里面访问数据库,检测是否存在用户名以及相对应的密码。
以及上文的三种对象,进行理解
ajax
异步的 javascript。在不全部加载某一个页面部的情况下,对页面进行局部的
刷新,ajax 请求都在后台。

也就是说,回想一下我们前面的登录试验,我们所作的是先在login页面进行登录,然后点击登陆后,先转到login_check页面,然后在login_check函数的作用下再返回别的页面,但我们不想要这种做法,我们希望没有页面跳转,也就是我们仅仅向在login页面登录,然后页面还是在本页面,或者显示登录成功的页面的异步加载,这就需要用到ajax方法,步骤:
- 发起 ajax 请求:jquery 发起
- 执行相应的视图函数,返回 json 内容
- 执行相应的回调函数。通过判断 json 内容,进行相应处理。
ajax的登录样例
首先就是需要放置对应的文件,比如我们这边需要放置jquery文件(ajax就在里面),放置文件的位置:
- 我们需要先在项目目录下放置一个文件夹(一般名为static的文件夹)
- 然后到配置下加上:
# 这个是静态文件的位置,这边的static代表的就是根目录下的static
STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]
- 然后往内部加上文件,比如这里要在static文件夹下创建js文件夹,内部再放入jquery的文件,如此完成配置。
然后就是先编写html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>ajax登录</title>
<script src="/static/js/jquery-1.12.4.min.js"></script>
<script>
$(function () {
$('#btnLogin').click(function () {
// 1.获取用户名和密码
username = $('#username').val()
password = $('#password').val()
// 2.发起post ajax请求,/login_ajax_check, 携带用户名和密码
$.ajax({
'url':'/login_ajax_check/', //当是post请求时默认多写一个/让urls匹配保持一致
'type': 'post',
'data': {'username':username, 'password':password},
'dataType': 'json'
}).success(function (data) {
// 登录成功 {'res':1}
// 登录失败 {'res':0}
if (data.res == 0){
$('#errmsg').show().html('用户名或密码错误')
}
else{
// 跳转到首页
location.href = '/index'
}
})
})
})
</script>
<style>
#errmsg{
display: none;
color: red;
}
</style>
</head>
<body>
<div>
用户名:<input type="text" id="username"><br/>
密码:<input type="password" id="password"><br/>
<input type="button" id="btnLogin" value="登录">
<div id="errmsg"></div>
</div>
</body>
</html>
如此之后,当点击登录按钮,将会向url为 /login_ajax_check/的地方发送post的请求,然后数据是json格式的data
'url':'/login_ajax_check/',
'type': 'post',
'data': {'username':username, 'password':password},
'dataType': 'json'
此时我们就需要编写对应的后端函数,并且匹配上路由为login_ajax_check。
- 匹配路由略
- 后端函数(要求需要返回一个json格式的数据,就用于类似上文的判断,当传回的数据的res是0,代表登录失败,我们就在id名为errmsg的组件上加上用户名或密码错误)
.success(function (data) {
// 登录成功 {'res':1}
// 登录失败 {'res':0}
if (data.res == 0){
$('#errmsg').show().html('用户名或密码错误')
}
else{
// 跳转到首页
location.href = '/index'
}
后端代码:(值得关注的是,这边使用的就不是和以前一样,返回一个redirect(‘/login’),或者render(),这边一定需要返回一个JsonResponse({‘res’:1})对象用于判断)
def login_ajax_check(request):
'''ajax登录校验'''
# 1.获取用户名和密码
username = request.POST.get('username')
password = request.POST.get('password')
# 2.进行校验,返回json数据
if username == 'admin' and password == '123':
# 用户名密码正确
return JsonResponse({'res':1})
# return redirect('/index') ajax请求在后台,不要返回页面或者重定向,这样是不行的,一定要返回Json!
else:
# 用户名或密码错误
return JsonResponse({'res':0})
状态保持
http 协议是无状态的。下一次去访问一个页面时并不知道上一次对这个页面做了什么。具体意思就是类似短连接,我们访问某一个路由,他就把对应的资源传给你,然后断开连接,那么什么是有状态呢?就是游戏,我么需要时刻连接的这种长连接模式。
cookie
cookie 是由服务器生成,存储在浏览器端的一小段文本信息。
cookie 的特点:
- 以键值对方式进行存储。
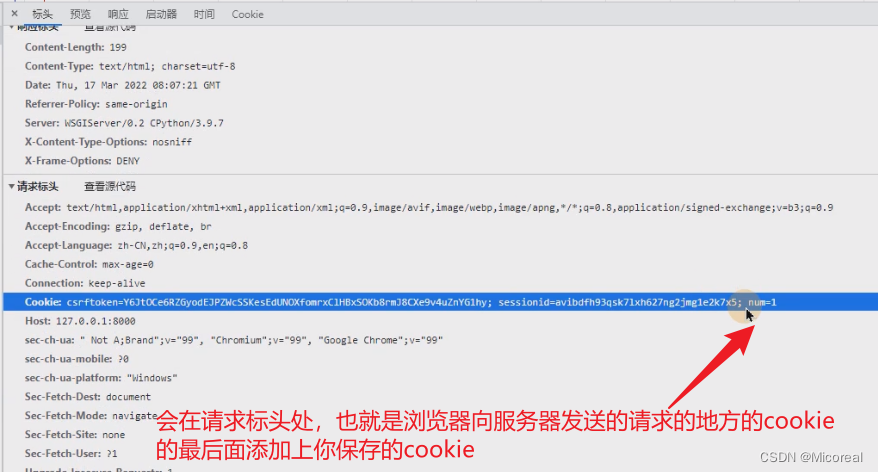
- 通过浏览器访问一个网站时,会将浏览器存储的跟网站相关的所有 cookie信息发送给该网站的服务器。request.COOKIES
- cookie 是基于域名安全的。www.baidu.com www.iqiyi.com
- cookie 是有过期时间的,如果不指定,默认关闭浏览器之后 cookie 就会过期。
样例1:基本使用,使用之后就会在浏览器的
from datetime import datetime,timedelta
# /set_cookie
def set_cookie(request):
'''设置 cookie 信息'''
response = HttpResponse('设置 cookie')
# 设置一个 cookie 信息,名字为 num, 值为 2
# response.set_cookie('num', 2)
# 下面是设置 cookie 在两周之后过期
# response.set_cookie('num', 2, max_age=14*24*3600)
response.set_cookie('num',1,expires=datetime.now()+timedelta(days=14))
# 返回 response
return respons
样例2:
cookie的基本使用:还是以登录为例子,实际上就是为了让用户本次输入账号之后,之后再一次进入此页面,达到账号已经填入的效果,只需要输入密码就可以完成登录的效果。
def login(request):
# 判断用户是否登录
if request.session.has_key('islogin'):
# 用户已登录, 跳转到首页
return redirect('/index')
if 'username' in request.COOKIES:
# 获取记住的用户名
username = request.COOKIES['username']
else:
username = ''
return render(request, 'booktest/login.html', {'username': username})
def login_check(request):
'''登录校验视图'''
# request.POST 保存的是post方式提交的参数 QueryDict
# request.GET 保存是get方式提交的参数 类型也是 QueryDict
username=request.POST.get('username')
password=request.POST.get('password')
remember=request.POST.get('remember')
if username=='admin' and password=='123':
reponse=redirect('/index')
# 值得关注的是,在前端中的打勾返回的json格式数据,一般都是on
if remember=='on':
reponse.set_cookie('username', username, max_age=7*24*3600)
return reponse
else:
return redirect('/login')
Session
现在我们又面临一个问题,就是我们想要记录我们的登录状态,那cookie只能完成服务器上存储我们发送的信息,这没办法完成,甚至还有点不安全,于是我们需要引入Session,这个能在数据库当中存储我们的登录状态,但是也需要搭配cookie进行使用。
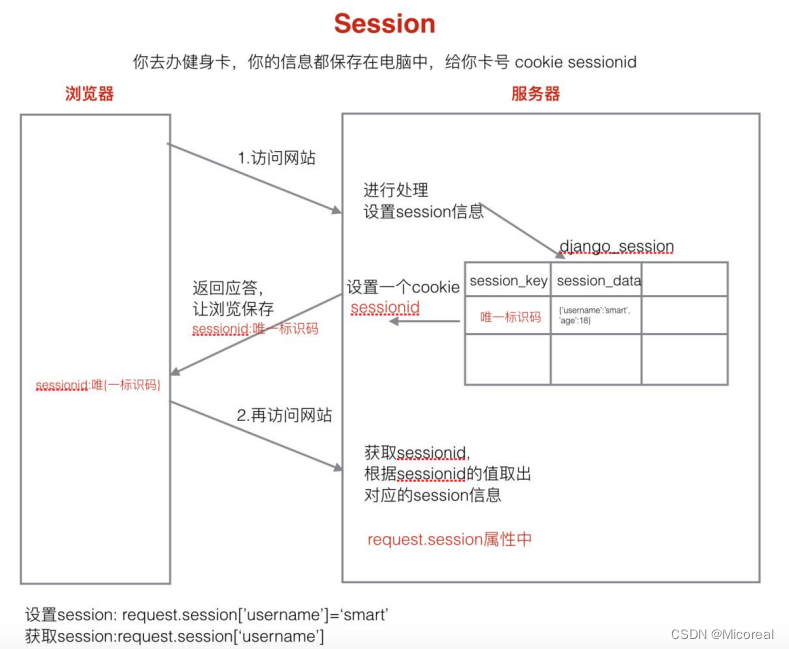
session 存储在服务器端。
在服务器端进行状态保持的方案就是 Session。
session 的特点:
- session 是以键值对进行存储的。
- session 依赖于 cookie。唯一的标识码 sessionid 保存在 cookie 中,实际上就变成了服务器向浏览器以cookie的方式 传递sessionid码,然后每次浏览器读取这个网页,就通过这个cookie码去服务器的数据库当中查询登录状态。
- session 也是有过期时间,如果不指定,默认两周就会过期。
- session 与 cookie 的差异,cookie 无论保存什么值进去,取出来都是字符串,session 保存进去什么类型,取出来就是什么类型。
启用Session
Django 项目默认启用 Session,在setting.py文件当中:

值得关注的是我们这边注释了csrf,这个是跨域问题的中间件,注释掉解决跨域问题,但是当上线的时候,需要打开。
存储 Session 时,键与 Cookie 中的 sessionid 相同,值是开发人员设置的键
值对信息,进行了 base64 编码,过期时间由开发人员设置。Base64 是网络上最常见的用于传输 8Bit 字节码的编码方式之一,Base64 就是一种基于 64个可打印字符来表示二进制数据的方法
对象以及使用方法
通过 HttpRequest 对象的 session 属性进行会话的读写操作。
1) 以键值对的格式写 session。
request.session['键']=值
2)根据键读取值。
request.session.get('键',默认值)
或者 request.session['键']
3)清除所有 session,clear()方法只清除会话中的数据,但会话本身仍然存在。
request.session.clear()
4)清除 session 数据,在存储中删除 session 的整条数据。flush()方法不仅清除会话中的数据,还会删除会话本身,使用户获得一个新的会话。
request.session.flush()
5)删除 session 中的指定键及值,在存储中只删除某个键及对应的值。
del request.session['键']
6)设置会话的超时时间,如果没有指定过期时间则两个星期后过期。
request.session.set_expiry(value)
如果 value 是一个整数,会话将在 value 秒没有活动后过期。
如果 value为 0,那么用户会话的 Cookie 将在用户的浏览器关闭时过期。
如果 value 为 None,那么会话永不过期。
记住登录状态示例
def login(request):
# 判断用户是否登录
if request.session.has_key('islogin'):
# 用户已登录, 跳转到首页
return redirect('/index')
if 'username' in request.COOKIES:
# 获取记住的用户名
username = request.COOKIES['username']
else:
username = ''
return render(request, 'booktest/login.html', {'username': username})
def login_check(request):
'''登录校验视图'''
# request.POST 保存的是post方式提交的参数 QueryDict
# request.GET 保存是get方式提交的参数 类型也是 QueryDict
username=request.POST.get('username')
password=request.POST.get('password')
remember=request.POST.get('remember')
if username=='admin' and password=='123':
reponse=redirect('/index')
request.session['islogin']=True
if remember=='on':
reponse.set_cookie('username', username, max_age=7*24*3600)
return reponse
else:
return redirect('/login')
模板
模板的功能
产生 html,控制页面上展示的内容。模板文件不仅仅是一个 html 文件。模板文件包含两部分内容:
- 静态内容:css,js,html。
- 动态内容:用于动态去产生一些网页内容。通过模板语言来产生。
模板文件的使用
通常是在视图函数中使用模板产生 html 内容返回给客户端。
- 加载模板文件 loader.get_template 获取模板文件的内容,产生一个模板对象。
- 定义模板上下文 Context 给模板文件传递数据。
- 模板渲染产生 html 页面内容 render(之前已经用过多次)
用传递的数据替换相应的变量,产生一个替换后的标准的 html 内容。
下面是关于我们经常使用的render的一个解析(示例):
from django.template import loader,RequestContext
from django.http import HttpResponse
def my_render(template_path, context={}):
# 1.加载模板文件,获取一个模板对象
temp = loader.get_template(template_path)
# 2.给模板传参,模板渲染,产生一个替换后的 html 内容
res_html = temp.render(context)
# 3.返回应答
return HttpResponse(res_html)
def index(request):
return my_render('booktest/index.html')
#return render(request,'booktest/index.html')
上面是为了让大家理解 render 主要做了哪些事情,但是实际上的 使用直接使用render即可,内部填的参数也直接类似这种:render(request, ‘转达的html文件’,{‘area’:area,‘parent’:parent, ‘children’:children}需要传递的参数)
模板文件加载顺序
- 首先去配置的模板目录下面去找模板文件。
- 去 INSTALLED_APPS 下面的每个应用的 templates 去找模板文件,前提是应用中必须有 templates 文件夹,加载顺序是 INSTALLED_APPS 中的顺序
模板语言
模板语言简称为 DTL。(Django Template Language)
模板语言包括 4 种类型,分别是:变量 标签 过滤器 注释.
变量
模板变量名是由数字,字母,下划线和点组成的,不能以下划线开头,然后在html上进行使用,在后端render()的第三个参数上传输,以键值对来传输。
使用模板变量:{{模板变量名}}
模板变量的解析顺序:
例如:{{ book.btitle }}
- 首先把 book 当成一个字典 ,把 btitle 当成键名,进行取值book[‘btitle’]
- 把 book 当作一个列表,但是bititle明显不是一个数字,所以跳过。
- 把 book 当成一个对象,把 btitle 当成属性,进行取值 book.btitle。
- 把 book 当成一个对象,把 btitle 当成对象的方法,进行取值 book.btitle
标签(模板中使用for和if函数)
for循环使用方法:
{% 代码段 %}
# for循环
{% for x in 列表 %}
# 列表不为空时执行
{% empty %}
# 列表为空时执行
{% endfor %}
# 可以通过{{ forloop.counter }}得到 for 循环遍历到了第几次
if判断使用方法:
{% if 条件 %}
{% elif 条件 %}
{% else %}
{% endif %}
关系比较操作符:> < >= <= == != 注意:进行比较操作时,比较操作符两边必须包含空格
逻辑运算:not and or
示例:
{% for book in books %}
{% if book.id <= 2 %}
<li class="red">{{ forloop.counter }}--{{ book.btitle }}</li>
{% elif book.id <= 5 %}
<li class="yellow">{{ forloop.counter }}--{{ book.btitle }}</li>
{% else %}
<li class="green">{{ forloop.counter }}--{{ book.btitle }}</li>
{% endif %}
{% endfor %}
过滤器(调用自己使用的函数)
参考链接
这边只点几个个人认为重要的:
格式:模板变量|过滤器:参数
自定义过滤器。(比如不能使用除号)
自定义的过滤器函数,至少有一个参数,最多两个。
自定义过滤标签的时候,需要在 应用文件夹 下新建 templatetags文件夹,注意必须在对应路径,而且必须叫这个名字,在下面新建 filters.py文件。
内部写上相对应的代码:这边以我写的为例子:
from django.template import Library
# 创建一个 Library 类的对象
register = Library()
# 自定义的过滤器函数,至少有一个参数,最多两个
# 自定义过滤器函数一,实际上完成的就是判断是不是偶数
@register.filter
def mod(num):
'''判断 num 是否为偶数'''
return num%2 == 0
# 自定义过滤器函数二
@register.filter
def mod_val(num, val):
'''判断 num 是否能被 val 整除'''
return num%val == 0
相对应使用模板函数地方,一些比较不重要的去掉了,只保留使用了的地方
{% for book in books %}
{# {% if book.id|mod %}#} # 使用一个参数的地方,实际上默认将第一个book.id当作第一个参数进行传入
{% if book.id|mod_val:3 %} # 使用俩个参数的地方,第一个是book.id第二个是3,需要用:隔开
<li class="red">{{ book.id }}--{{ book.btitle|length }}--{{ book.bpub_date|date:'Y/m/d' }}</li>
{% else %}
<li class="green">{{ book.btitle }}--{{ book.bpub_date }}</li>
{% endif %}
{% endfor %}
上文还使用了date这一个内置的模板函数的地方,我们这边简要介绍一下date这种模板函数,实际上就是我们没使用模板函数的时候,显示的是2023年8月28日,但使用了上文类型的模板函数,就会变成我们想要的格式:2023/08/28
具体的内置过滤器函数,见上面的链接即可。
注释
单行注释:
{# 注释内容 #}
多行注释:
{% comment %}
······
注释内容
······
{% endcomment %}
浏览器源代码看不到模板注释的,但是可以看到 html 的注释。
模板继承
模板继承也是为了重用 html 页面内容。比如很多网站的头部导航条和底部版权版权信息不变的,但是如果想要不断重写这一块内容,就很浪费时间,所以对于我们来说就需要一个父亲模板,内部已经编写好了导航条和底部的版权等内容,然后子模板去继承,节省时间。
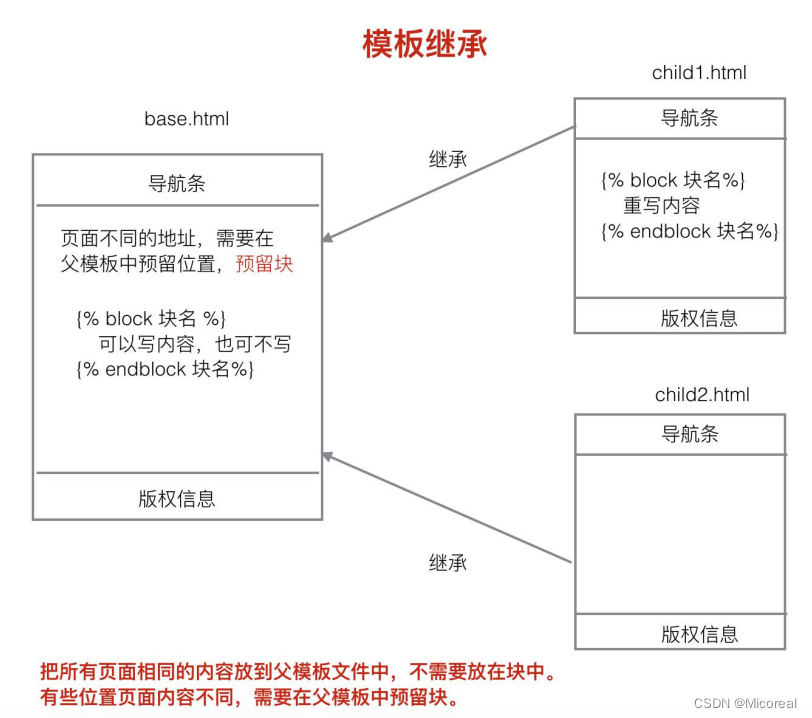
例子:父亲模板 base.html 父亲写block的地方实际上就是放着需要替换的位置
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}父模板文件{% endblock title %}</title>
</head>
<body>
<h1>导航条</h1>
{% block b1 %}
<h1>这是父模板 b1 块中的内容</h1>
{% endblock b1 %}
{% block b2 %}
<h1>这是父模板 b2 块中的内容</h1>
{% endblock b2 %}
<h1>版权信息</h1>
</body>
</html>
子模板 (首先先extends指向要继承的父亲模板 然后下文一个个去替换,{{ block.super }}是使用父亲模板内的内容,如果没有这句,就直接完全替换)
{% extends 'booktest/base.html' %}
{% block title %}子模板文件{% endblock title %}
{% block b1 %}
{{ block.super }}
<h1>这是子模板 b1 块中的内容</h1>
{% endblock b1 %}
{% block b2 %}
{{ block.super }}
<h1>这是子模板 b2 块中的内容</h1>
{% endblock b2 %}
html转义
在模板上下文中的 html 标记默认是会被转义的。
- 小于号< 转换为<
- 大于号> 转换为>
- 单引号’ 转换为'
- 双引号" 转换为 "
- 与符号& 转换为 &
什么意思呢?就是说,当我们view函数中render(request, 地址,{‘content’:‘<h1>hello world</h1>’})的时候网页上会直接打印出<h1>\hello world,而不是我们想要的h1标题状的hello world,那我们想要他能直接打印出标题装的,就需要我们让他关闭转义功能
打印出<h1>hello world</h1>
html 转义:<br/>
{{ content }}<br/>
打印出hello world
使用 safe 过滤器关闭转义:<br/>
{{ content|safe }}<br/>
和上面的safe一样,不过是多行safe
使用 autoescape 关闭转义:<br/>
{% autoescape off %}
{{ content }}
{{ content }}
{% endautoescape %}<br/>
使用别的模板过滤器
模板硬编码中的字符串默认不会经过转义:<br/>
{{ test|default:'<h1>hello</h1>' }}<br/>
手动进行转义:<br/>
{{ test|default:'<h1>hello</h1>' }
csrf攻击
CSRF 全拼为 Cross Site Request Forgery,译为跨站请求伪造。CSRF 指攻击者盗用了你的身份,以你的名义发送恶意请求。CSRF 能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账… 造成的问题包括:个人隐私泄露以及财产安全。
举个小例子:我们前面提到了cookie以及session,那么就比如说我们浏览器正常访问一个银行页面,输入了账户密码登录之后,服务器就会使用cookie给我们发送一个sessionid,储存在我们的浏览器中,然后这种攻击就有可能会发生在,当我们访问一个不健康的网站,比如说黄色网站,我们点击其中的美女还是什么的图案,他实际上内置了超链接,超链接的对象是我们上面登录过的银行的网站的修改密码的url(好好理解一下,在引入ajax/axios的异步后,url分为实际上显示网页的 和 只执行相对应函数的),并且模拟发送修改密码的密码,那由于是我们浏览器点击的超链接,就直接进行了修改密码这项操作,这是很不安全的
那我们csrf的解决策略就是使用token,当我们打开一个页面的时候,他会给我们发送一个csrftoken

这边再重复一遍我们正常修改密码的流程和csrf修改的流程:
- 正常:我们先在/xiugai 上填写新密码,点击表单提交后,post提交到/xiugai_mima 进行数据库修改
- csrf: 直接利用cookie的性质向/xiugai_mima直接模拟发包,直接发送新的密码。
二者在我们用户的视角上都是不可见的(ajax/axios)
对比一下二者的区别,所以解决策略就是我们会在访问xiugai页面的时候发送一个token,当你修改的时候一样需要检测这个token,如果没有或者不一样,那么就无法进行修改,所以说token的生存周期就是关闭即没有。
使用方式:如下文{% csrf_token %},实际上就是,当我们提交表单到/change_pwd_action/的时候需要验证这个token
<form method="post" action="/change_pwd_action/">
{% csrf_token %}
新密码:<input type="password" name="pwd">
<input type="submit" value="确认修改">
</form>
效果就是:

防御原理:
- 渲染模板文件时在页面生成一个名字叫做 csrfmiddlewaretoken 的隐藏域。
- 服务器交给浏览器保存一个名字为 csrftoken 的 cookie 信息。
- 提交表单时,两个值都会发给服务器,服务器进行比对,如果一样,则 csrf验证通过,否则失败
反向解析
实际上就是我们在写好项目的时候,产品经理要求我们将一个页面的url进行修改,那我们直接去url视图下直接进行修改,然后把所有用到这一部分的地方都进行修改吗?很明显工程量太大了。
所以这边可以使用反向解析操作进行实现
整个方法的流程
先去url.py处进行起一个别名(假设原本这边是index)
path('index1',view.index,name='ooo')
反向解析
# 后端反向解析
from django.urls import reverse
reverse('ooo') 这一个就是我们相对应的url
# 前端进行反向解析
<a href="{% url 'ooo' %}">111</a>
补充 软件库下 url
实际上我们也可以在我们对应的软件库下写一个url.py 然后把url配置写在里面,最后再将这一部分导入到项目url当中,导入的函数:
path('',include(('booktest.urls','booktest'),namespace = 'booktest')
然后之后使用反向解析,就需要我们使用namespace:ooo,如例如{% url ‘booktest:ooo’ %}
所以见下面的例子,希望好好理解一下,这是带参数的反向解析例子:
前端反向解析(带参数)
html的使用
动态产生/show_args/1/2:<br/>
<a href="{% url 'booktest:show_args' 1 2 %}">/show_args/1/2</a><br/>
<a href="{% url 'booktest:show_kwargs' d=4 c=3 %}">/show_kwargs/3/4</a>
同时在 urls.py 中增加
path('show_args/<int:a>/<int:b>',views.show_args,name='show_args'),
path('show_kwargs/<int:c>/<int:d>',views.show_kwargs,name='show_kwargs'),
软件的view下:
def show_args(request, a, b):
return HttpResponse(str(a) + ':' + str(b))
def show_kwargs(request, c, d):
return HttpResponse(str(c) + ":" + str(d))
后端的反向解析(带参数)
from django.urls import reverse
# /test_redirect
def test_redirect(request):
# 重定向到/index
# return redirect('/index')
# url = reverse('booktest:index')
# 重定向到/show_args/1/2
url = reverse('booktest:show_args', args=(1,2))
# 重定向到/show_kwargs/3/4
# url = reverse('booktest:show_kwargs', kwargs = {'c': 3, 'd': 4})
return redirect(url)
其他技术
见18 django框架(下)