文章目录
- 前言
- 1. Hash基础
- 1.1 Hash的概念和基本特征
- 1.2 碰撞处理方法
- 1.2.1 开放地址法
- 1.1.2 链地址法
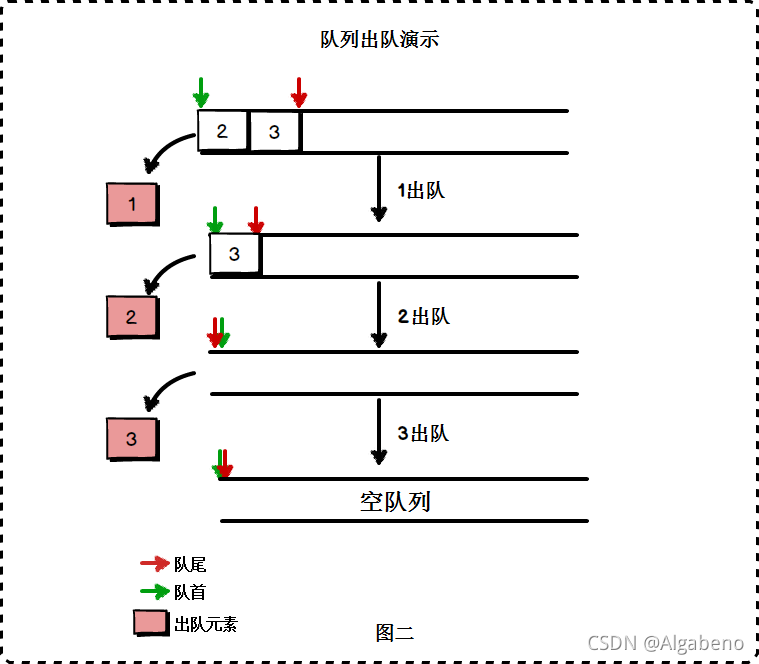
- 2. 队列的基础
- 2.1 队列的概念和基本特征
- 2.2 队列的实现
- 总结
前言
提示:幸福的秘密是尽量扩大自己的兴趣范围对感兴趣的人和物尽可能的友善 --波特兰·罗素
谈完栈,我们今天就来聊聊队列和Hash,这也是很常见的数据结构,尤其是Hash。
1. Hash基础
哈希(Hash)也称为是散列表,就是把任意长度的输入,通过散列算法,变成固定长度的输出,这个输出也称为散列值。
1.1 Hash的概念和基本特征
很多人对于映射这个东西,很难理解,为啥就说Hash的访问时间复杂度就是O(1)?我们今天就来谈谈这个东西是真么回事。🥰
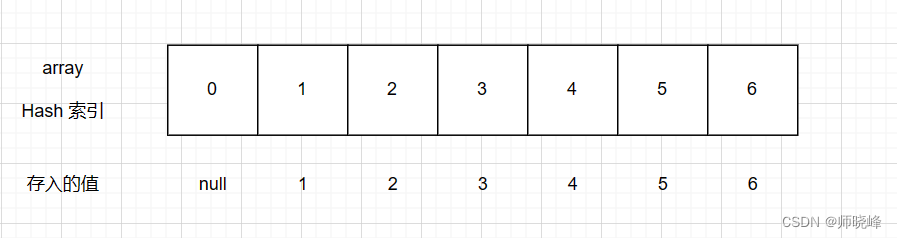
假设我们现在要将1-15存放如数组长度为7的array中,我们应该怎么存储呢?我给你一个公式:
index = number % 7
这个时候我们先将1-6出入的时候,看图:
这里没有问题吧,那我们接着存储7-17,如下图:
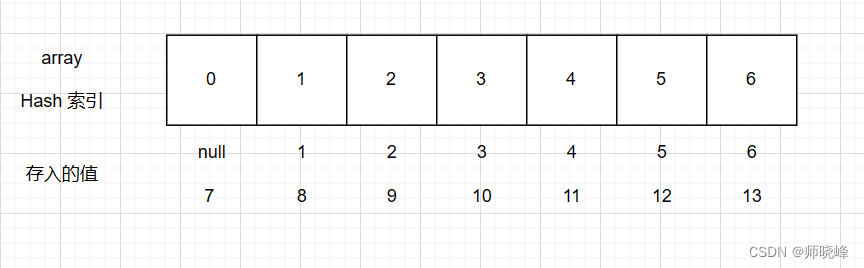
不是还有14、15呢,是这样的,看图:
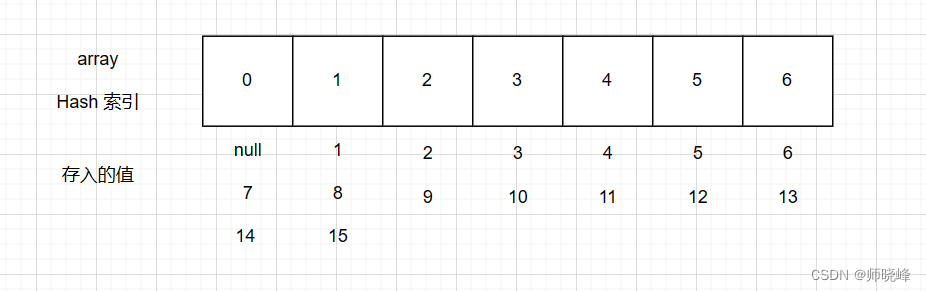
这个时候我们会发现有些数据被存放在同一个位置了,我们后面再讨论这个问题,接下来我们看看,我们将如何取值?
假如我要测试13在不在结构,我是不是还需要上面的公式,计算一下index = 13 % 7 6 ,我么你直接访问array[6]这个位置就可以拿到结果,然后返回true;
同样的我想知道20在不在呢?也是用上面的公式,即 index = 20 % 7 6 这是我们再访问array[6]这个位置,但是这里面只有6和13 没有20,我们就返回 false。
理解了这个例子我们就理解了Hash是如何做最基本的映射的,还有就是说问什么它的访问时间复杂度为O(1)。
1.2 碰撞处理方法
上面的例子重构,我们发现有些Hash中很多位置要存储两个甚至多个元素,很明显单纯的数组是行不通的,这种两个不同的输入值,根据统一的散列函数计算出的散列值相同的现象就叫做碰撞啦
那我我们要怎么解决呢?常见的方法:
- 开放地址法(Java中的Threadlocal)
- 链地址法(Java里的ConcurrentHashMap)
- 再哈希法(布隆过滤器)
- 建立公共溢出区
后面两种方法目前不常见,我们重点看看前面的两个。
1.2.1 开放地址法
开放地址法就是一旦发生冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总是可以找到的,并记录存入的。
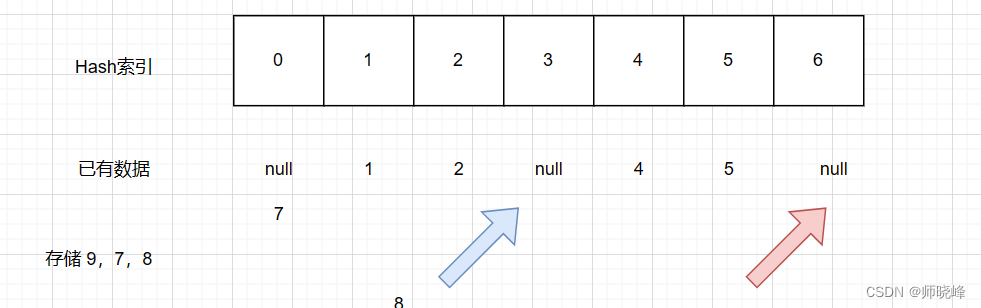
如上图:存储7,8,9的时候,对于7的话,可以直接存储在索引的位置0,8应该存储在1的位置,但是现在满了怎么办呢?就继续向后寻找,找到3的位置是空,所以8存储在3的位置上,同理9的位置也是这样。
这里你是否有一个疑问:这样的话鸠占鹊巢的方法会不会引起混乱?不如再存3和6的话,本来自己的位置好好的,但是现在却被占用了,我们该怎么处理呢?这个问题Java里的ThreadLocal会有答案,感兴趣的话可以学习一下。ThreadLocal有一个专门存储元素的ThreadLocalMap,每次在get和set元素的时候,会将目标位置前后的空间搜索一下,将标记为null的位置回收掉,这样大部分不用的位置就收回了。还有一点Hash处理该问题的过程也是非常复杂,设计弱引用等等,这些也都是Java技术面试的高频考点。
1.1.2 链地址法
将哈希表的每个单元作为链表的头节点,所有的哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键词链在该单元为头节点的链表的尾部。比如:
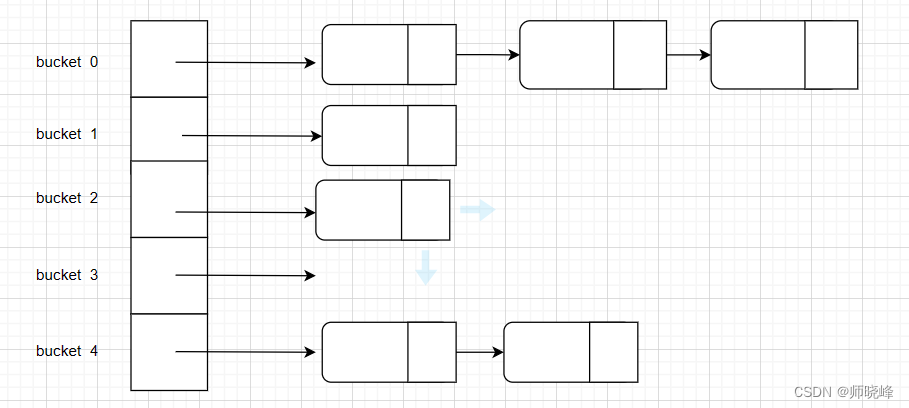
这种处理的方法问题在于处理起来的代价有点高,要落地还需要很多优化,比如在Java里ConcurrentHashMap中就使用了这种方式,其中涉及元素尽量均匀,访问和操作速度要快,线程安全,扩容等等。
我们来看看这个Hash结构,限免的图有两处很严重的错误,麻烦找出来:
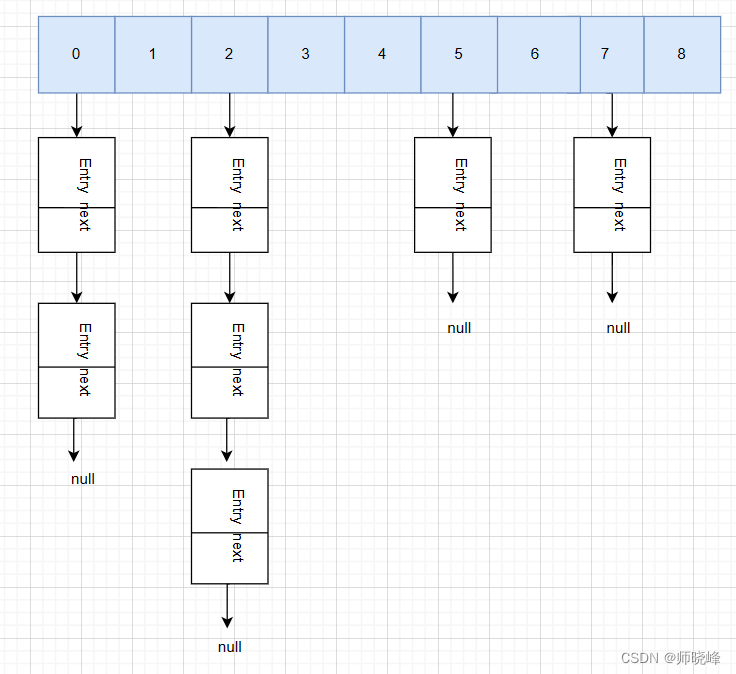
首先数组的长度必须时2的n次幂,长度9,明显有问题,然后Entry的个数不能大于数组长度的75%,如果大于就要触发扩容机制,这里明显发育75%,正确的呢?应该是下面这样:
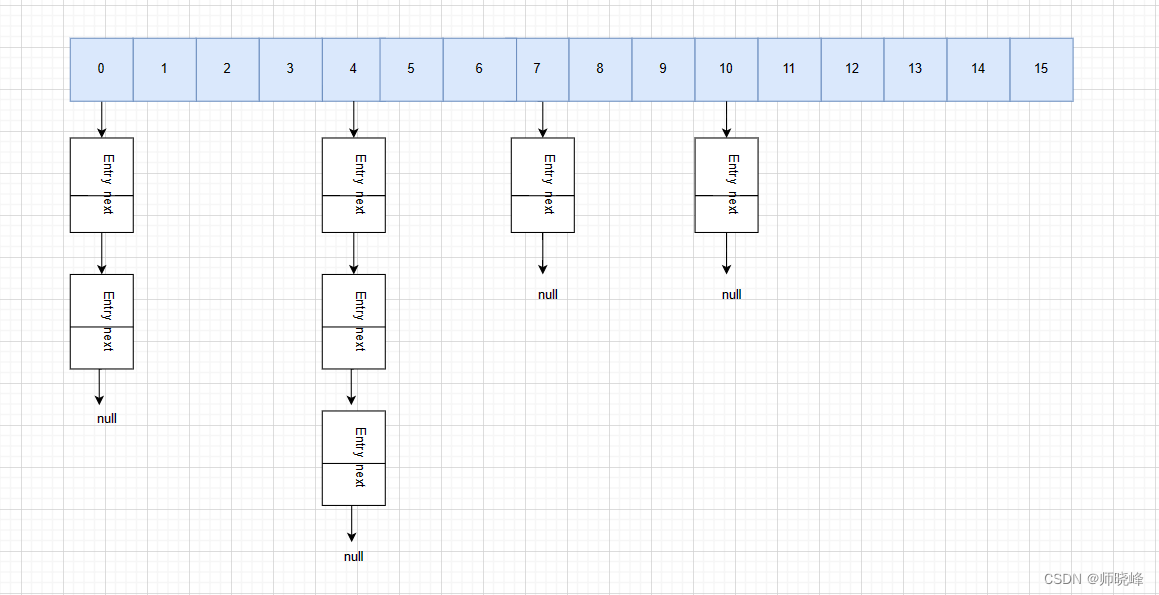
记住一下两点:
- 数组的长度即是2的n次幂
- Size不是超过数组长度的75%
顺便说一下,Hash的实现原理是先找到存放数组的下标,如果是空着就存进去,如果不是空的就判断key值是否一样,如果一样就替换掉,如果不一样就一链表的形式存储在后面(从JDK8开始,根据元素数量选择使用链表是红黑树存储)
2. 队列的基础
2.1 队列的概念和基本特征
队列的特点是节点的排序次序和出队次序按照入队时间先后确定,也就是常说的先进先出呗。【FIFO】。队列的实现有两种方法(形式),基于数组的实现和基于链表的实现,由于链表的长度可以随时改变,实现起来也比较简单。相反基于数组就比较麻烦,这里后面再来实现,我们先看一下基于链表的实现。
2.2 队列的实现
基于链表实现队列还是比较好处理的,只要在尾部插入元素,在front删除元素就可以了。
public class LinkQueue {
private Node front;
private Node rear;
private int size;
public LinkQueue() {
// 带头尾节点的遍历
front = new Node(0);
rear = new Node(0);
}
/**
* 入队
*/
public void push(int value) {
Node newNode = new Node(value);
Node temp = front;
while(temp.next != null){
temp = temp.next;
}
temp.next = newNode;
rear = newNode;
size++;
}
/**
* 出队
*/
public int pull() {
if (front.next == null){
throw new IllegalStateException("front.next is null");
}
Node firstNode = front.next;
front.next = firstNode.next;
size--;
return firstNode.data;
}
/**
* 遍历队列
*/
public void traverse() {
Node temp = front.next;
while (temp.next != null){
System.out.println(temp.data + "\t");
temp = temp.next;
}
}
static class Node {
public int data;
public Node next;
public Node(int data) {
this.data = data;
}
}
//测试main方法
public static void main(String[] args) {
LinkQueue linkQueue = new LinkQueue();
linkQueue.push(1);
linkQueue.push(2);
linkQueue.push(3);
System.out.println("第一个出队的元素为:" + linkQueue.pull());
System.out.print("队列中的元素为:");
linkQueue.traverse();
}
}
总结
提示:对Hash的理解和认识,掌握解决哈希冲突的两种方法,使用链表实现对列。