YOLOv5是一个非常流行的图像识别框架,这里介绍一下使用YOLOv5给自己的数据集进行训练和测试
官方介绍文档:YOLOv5官方文档
基本流程:
- 下载必要的库和包,以及yolov5框架
- 自制数据集:收集图像、视频数据,labelimg标注
- 修改train.py参数,进行训练
- 修改dectect.py参数,进行推理
下面逐步来演示一下
环境:Windows10,Python3.9,Anaconda
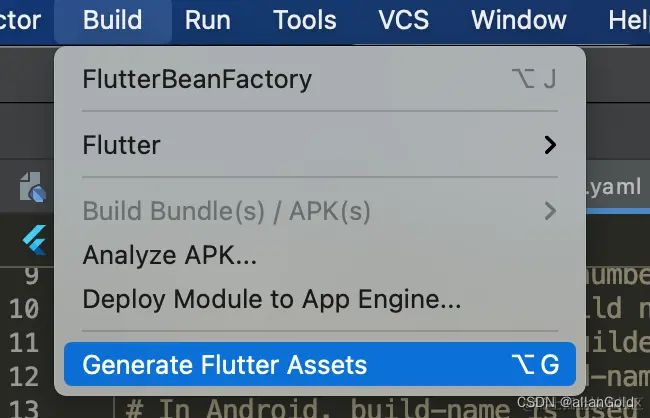
一、下载yolov5框架
建议使用Anaconda新开一个虚拟环境
- 在自己项目的目录下运行git clone,下载yolov5
git clone https://github.com/ultralytics/yolov5
如果网速不好的话可以直接在github下载:YOLOv5-master
- cd到yolov5的根目录后,pip install依赖项
cd [path]\yolov5
pip install -r requirements.txt
常见报错:
1.安装依赖项时可能会出现部分包无法安装,报错:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x98
原因:读取文件出现编码问题导致没法读取文件,解决方式详见我的另一篇文章:
【已解决】Windows10 pip安装报错:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x98
2. 如果虚拟环境里没有安装过gpu版本的torch,则此处使用requirements.txt安装的pytorch可能为cpu版本,后续训练无法使用gpu进行训练,因此需要将已安装的pytorch卸掉,然后重新安装gpu版本的pytorch,gpu版本的pytorch安装见官网:INSTALL PYTORCH
注:请事先下载对应的cuda和cudnn,以及确认好版本, 下载cuda和cudnn可见我另一篇文章的第一节内容:TensorFlow安装步骤
二、自制数据集
-
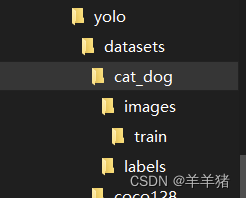
获取数据集(本次使用kaggle上面的一个猫狗数据集,里面大概有1000张猫狗图片,本次仅使用约170张猫和狗的图片做示例)
文件夹目录结构如下:
-
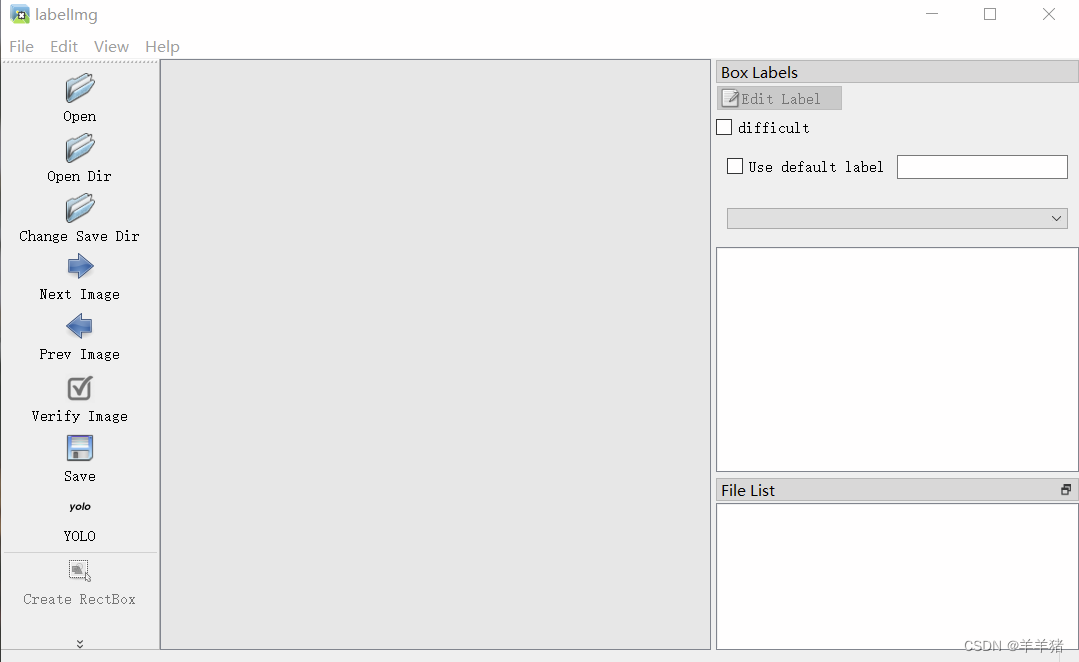
下载labelimg
pip install labelimg
然后他就会弹出一个软件:
- 点击
Open Dir,选择我们的数据集的路径,本例为\datasets\cat_dog\images\train - 点击
Change Save Dir,选择我们标签保存的位置,本例为\datasets\cat_dog\labels\train - 点击
save下面的模块,选择为YOLO,表示打标签的格式为YOLO的格式 - 点击
View,选择Auto save mode,设置为自动保存模式
然后就可以进行打标签了。
快捷键:w:画框;d:下一张图;a:上一张图;del:删除多余框
打完标签后可以看到labels文件夹里每张图片的标签,以及一个classes.txt的文件,内含标签类别,图片标签如下:

这表示为标签为0,物体位置坐标为【0.492188 0.177647 0.846875 0.345882
】
常见问题:
无法打开labelimg,报错:qt.qpa.plugin: Could not load the Qt platform plugin “windows“ in ““ even though it was found.
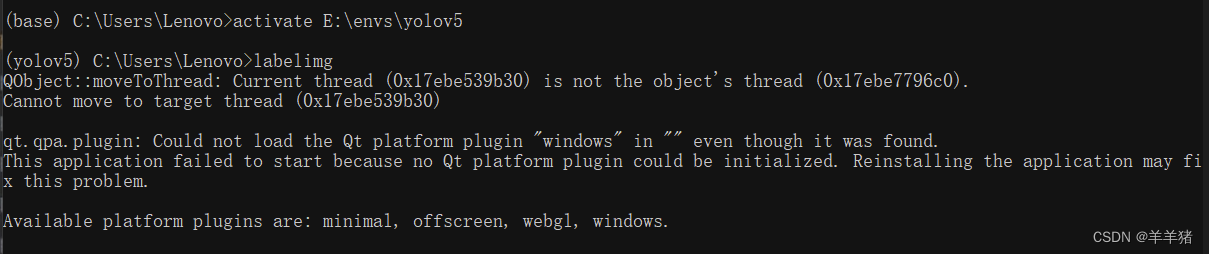
解决方法详见我的另一篇文章:【已解决】qt.qpa.plugin: Could not load the Qt platform plugin “windows“ in ““ even though it was found.
三、训练
打开train.py文件,找到def parse_opt(),进行配置
-
配置
--cfg:
1.1 在models文件夹里找到yolo5s.yaml,复制到models里,任意起一个名字(本例为cat_dog.yaml)
1.2 修改nc参数为标签的数量(本例的标签为猫和狗,所以这里nc修改为2)
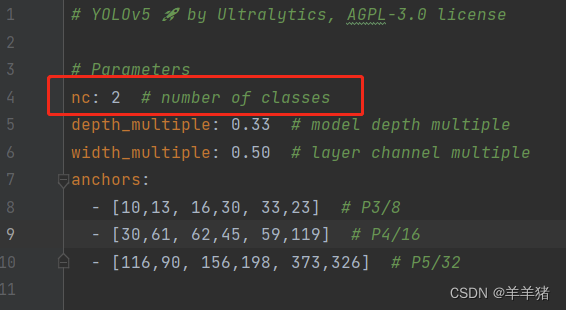
1.3 然后在train.py文件里修改cfg的配置参数,填上我们新建的cat_dog.yaml文件路径

-
配置
--data
2.1 在data文件夹里找到coco128.yaml,复制到data里,任意起一个名字(本例为cat_dog.yaml)
2.2 在cat_dog.yaml里修改数据集的路径,本例如下:

2.3 删除多余的分类,修改成自己的分类,本例如下:

-
设置训练参数,如
--epochs:设置训练轮数
--device:设置训练的device,改为0则为使用GPU计算框架 -
运行
train.py开始进行训练
训练完后可以在runs/train/exp里找到自己的训练结果
常见问题:
from torchvision.transform报错,找不到tranform模块
解决:卸载torchvision后再重新安装
# 本例
pip3 install torchvision --index-url https://download.pytorch.org/whl/cu117
-
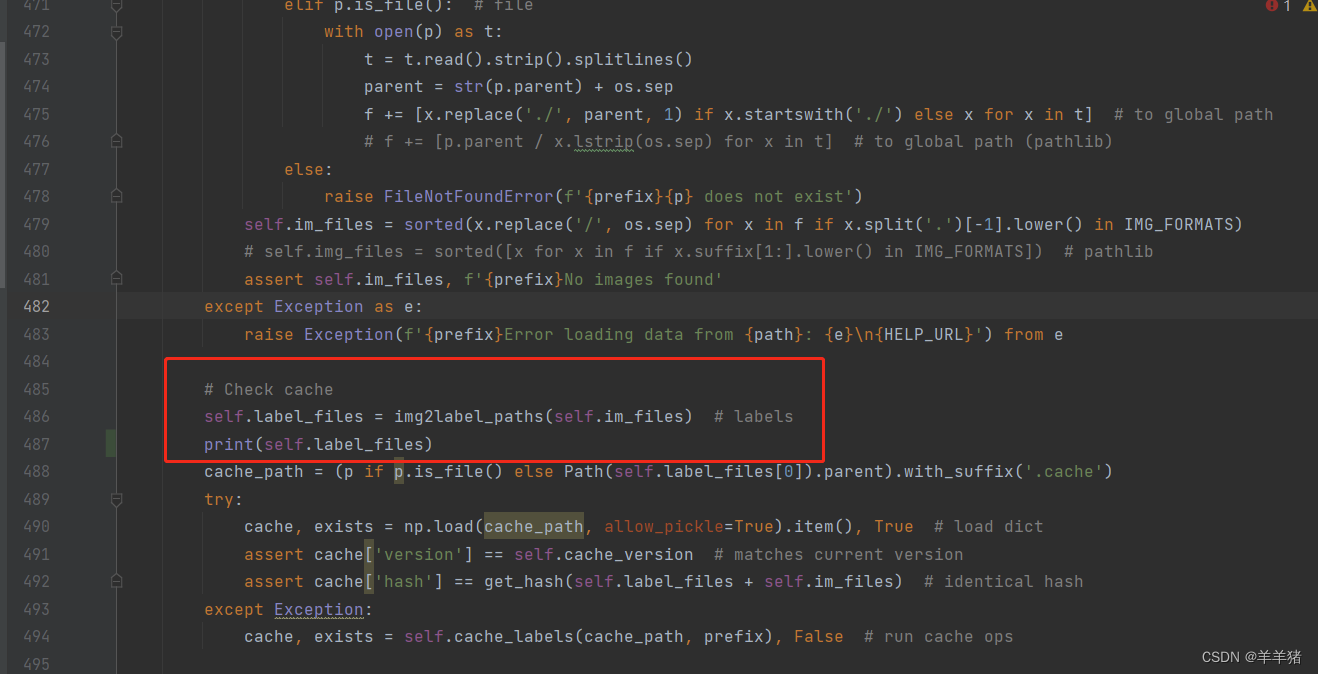
YOLOV5训练时找不到lables标签
解决方式:检查用于训练的图片及标签的路径,可以在dataloaders.py文件下打印标签的路径进行检查
-
报错:Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
原因:libiomp5md.dll在初始化的时候发现已经被初始化了
解决(本例):删掉E:\envs\yolov5\Lib\site-packages\torch\lib路径下的libiomp5md.dll文件(建议先备份文件及其路径)
参考:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. -
报错:OSError: [WinError 1455] 页面文件太小
原因:虚拟内存不够了,可以关掉一些进程,也可以修改虚拟内存
解决:OSError: [WinError 1455] 页面文件太小,或电脑崩溃出现 the window teminated unexpectedly (reason:‘oom‘code:‘-536870 -
报错:RuntimeError: [enforce fail at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory
解决:修改train.py中 batchsize、worker,减少数值(本例将--workers修改为2)
四、推理
打开detect.py文件,找到def parse_opt()进行配置
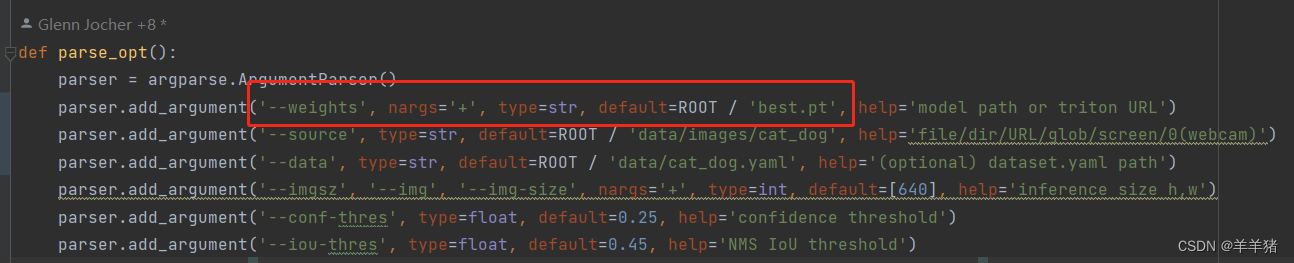
- 配置训练的权重文件
1.1 在runs/train/exp/weights文件夹里找到best.pt文件,复制到项目目录下
1.2 在detect.py文件里将--weights参数改成best.pt
- 配置
--data
将--data参数改成之前cat_dog.yaml文件路径

- 配置测试图片路径
3.1 将测试图片文件cat_dog放在data/images/路径下
3.2 设置--source路径参数
(测试文件也可以放在其他路径,定义好路径参数就行)
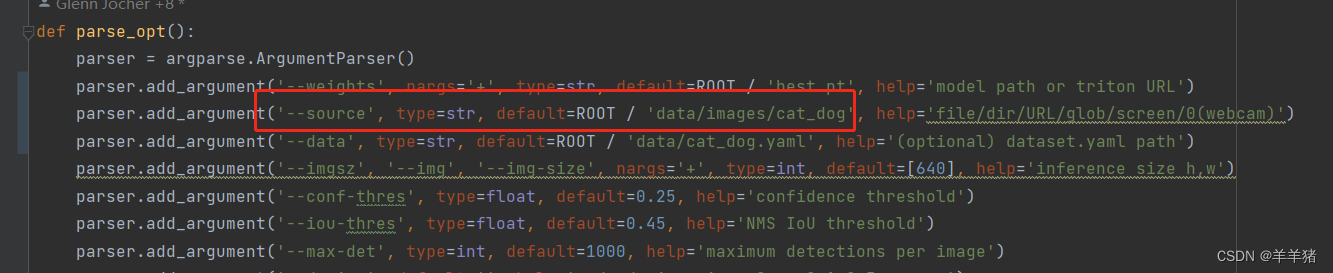
- 设置
--conf-thres置信率,表示相似度在xx以上就会被标记出来 - 运行
detect.py文件开始运行
更多参数设置可见:手把手带你调参YOLOv5 (v5.0-v7.0)(推理)
步骤参考来源:【一看就懂,一学就会】yolov5保姆级打标签、训练+识别教程