1、什么是索引下推?
索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。
需求: 查询users表中 "名字第一个字是张,年龄为10岁的所有记录"。
SELECT * FROM users WHERE user_name LIKE '张%' AND user_age = 10;根据最左前缀法则,该语句在搜索索引树的时候,只能匹配到名字第一个字是‘张’的记录,接下来是怎么处理的呢?当然就是从该记录开始,逐个回表,到主键索引上找出相应的记录,再比对 `age` 这个字段的值是否符合。
在 (name,age) 索引里面特意去掉了 age 的值,这个过程 InnoDB 并不会去看 age 的值,只是按顺序把“name 第一个字是’张’”的记录一条条取出来回表。因此,需要回表 4 次。

MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过,减少回表次数.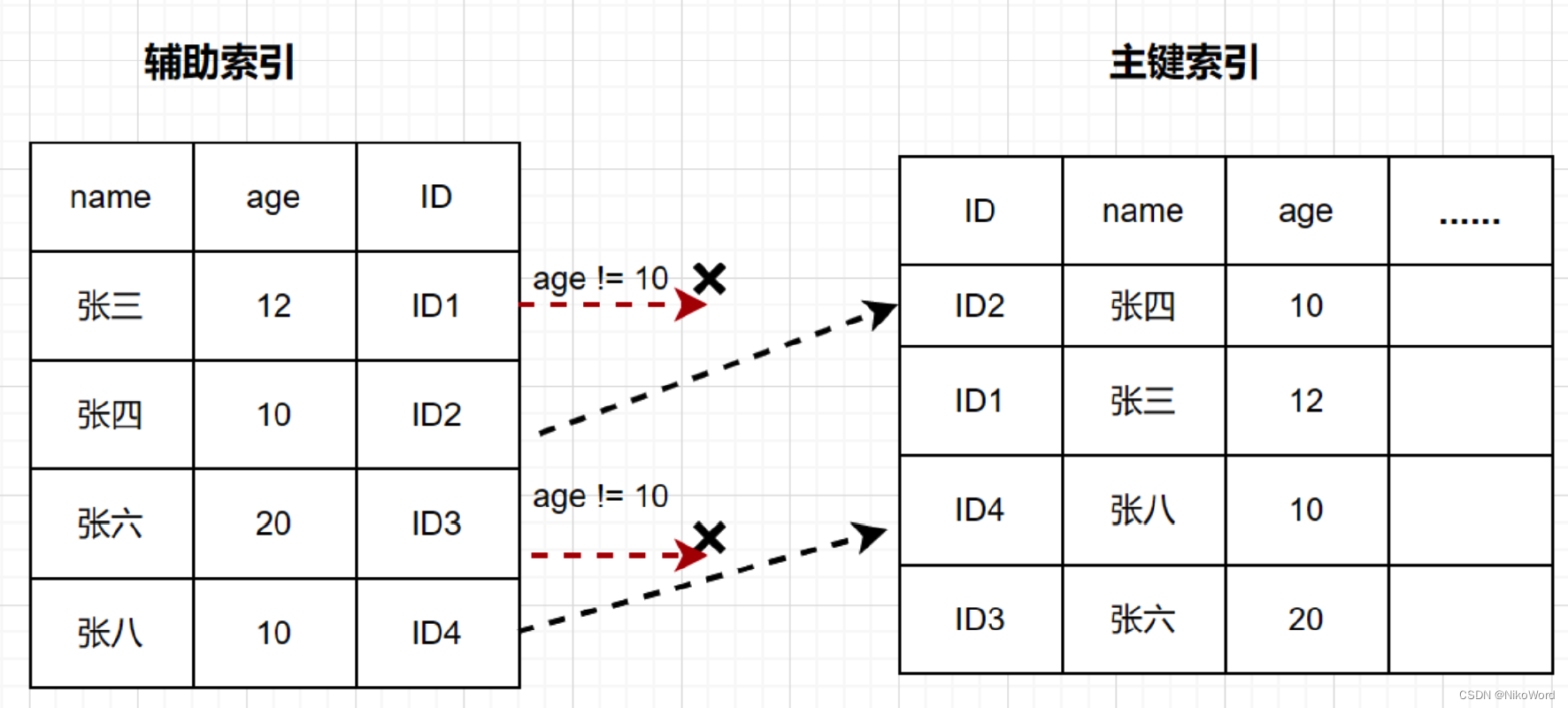
总结
如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;
在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
2、什么是自适应哈希索引?
自适应Hash索引(Adatptive Hash Index,内部简称AHI)是InnoDB的三大特性之一,还有两个是 Buffer Pool简称BP、双写缓冲区(Doublewrite Buffer)。
1、自适应即我们不需要自己处理,当InnoDB引擎根据查询统计发现某一查询满足hash索引的数据结构特点,就会给其建立一个hash索引;
2、hash索引底层的数据结构是散列表(Hash表),其数据特点就是比较适合在内存中使用,自适应Hash索引存在于InnoDB架构中的缓存中(不存在于磁盘架构中),见下面的InnoDB架构图。
3、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
当我们在进行等值查询的时候,他会在下面维护一张Hash表。和B+树的叶子节点进行一个关联,这样我们在进行范围查找的时候就会比较快。
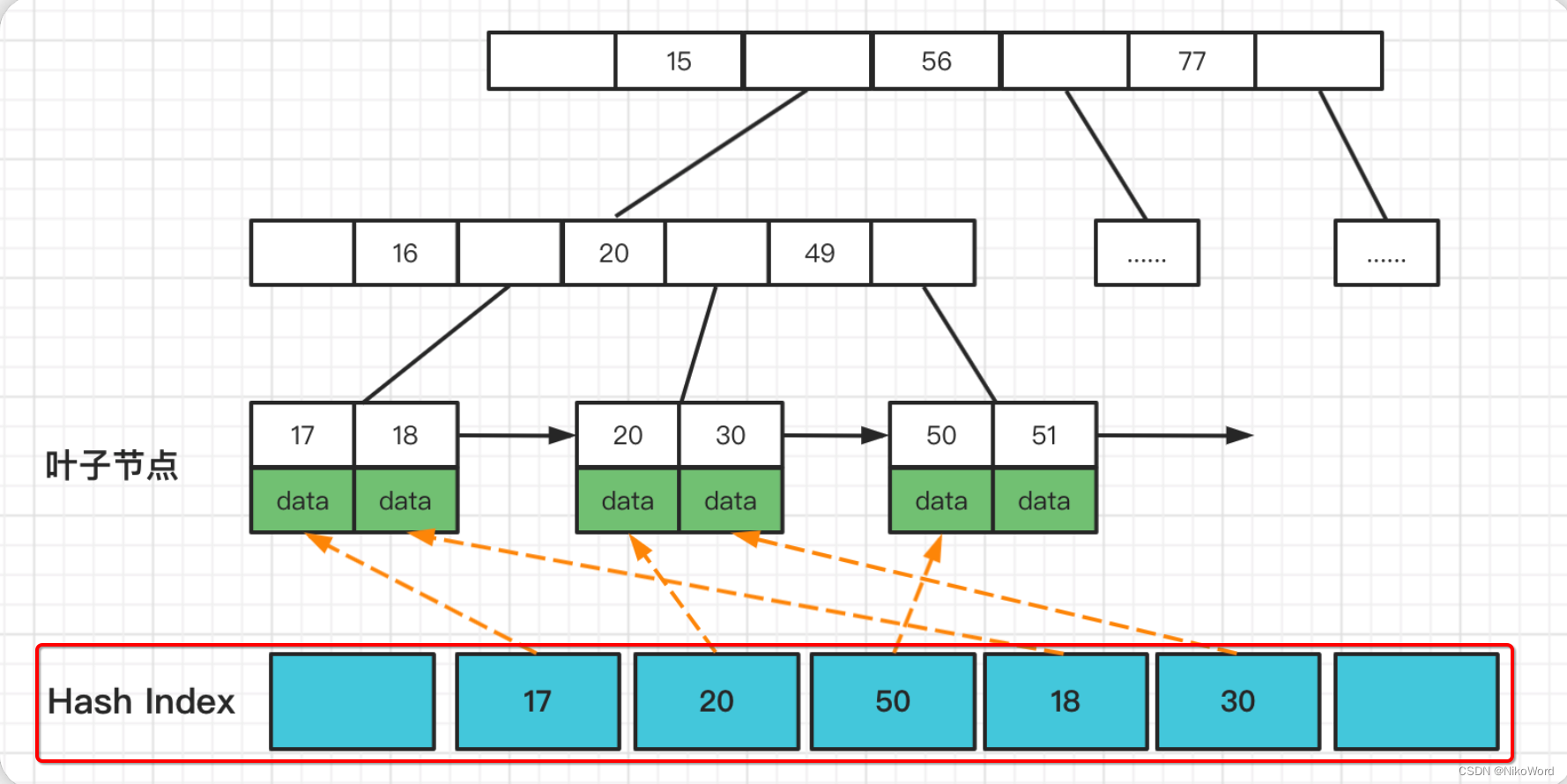
InnoDB的自适应Hash索引是默认开启的,可以通过配置下面的参数设置进行关闭。
innodb_adaptive_hash_index = off3、为什么LIKE以%开头索引会失效?
like查询为范围查询,%出现在左边,则索引失效。%出现在右边索引未失效.
场景1: 两边都有% 或者 字段左边有%,索引都会失效。
EXPLAIN SELECT * FROM users WHERE user_name LIKE '%tom%';
EXPLAIN SELECT * FROM users WHERE user_name LIKE '%tom';场景2: 字段右边有%,索引生效
EXPLAIN SELECT * FROM users WHERE user_name LIKE 'tom%';解决%出现在左边索引失效的方法,使用覆盖索引
EXPLAIN SELECT user_name FROM users WHERE user_name LIKE '%jack%';
EXPLAIN SELECT user_name,user_age,user_level FROM users WHERE user_name LIKE '%jack%';对比场景1可以知道, 通过使用覆盖索引 `type = index`,并且 `extra = Using index`,从全表扫描变成了全索引扫描.
总结like 失效的原因:
1. %号在右: 由于B+树的索引顺序,是按照首字母的大小进行排序,%号在右的匹配首字母。所以可以在B+树上进行有序的查找,查找首字母符合要求的数据。
2. %号在左: 是匹配字符串尾部的数据,我们上面说了排序规则,尾部的字母是没有顺序的,所以不能按照索引顺序查询,就用不到索引.
3. 两个%%号: 这个是查询任意位置的字母满足条件即可,只有首字母是进行索引排序的,其他位置的字母都是相对无序的,所以查找任意位置的字母是用不上索引的.
4、自增还是UUID?数据库主键的类型该如何选择?
auto_increment的优点:
1. 字段长度较uuid小很多,可以是bigint甚至是int类型,这对检索的性能会有所影响。
2. 在写的方面,因为是自增的,所以主键是趋势自增的,也就是说新增的数据永远在后面,这点对于性能有很大的提升。
3. 数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利。
4. 数字型,占用空间小,易排序,在程序中传递也方便。
auto_increment的缺点:
1. 由于是自增,很容易通过网络爬虫知晓当前系统的业务量。
2. 高并发的情况下,竞争自增锁会降低数据库的吞吐能力。
3. 数据迁移或分库分表场景下,自增方式不再适用。
UUID的优点:
1. 不会冲突。进行数据拆分、合并存储的时候,能保证主键全局的唯一性
2. 可以在应用层生成,提高数据库吞吐能力
UUID的缺点:
1. 影响插入速度, 并且造成硬盘使用率低。与自增相比,最大的缺陷就是随机io,下面我们会去具体解释
2. 字符串类型相比整数类型肯定更消耗空间,而且会比整数类型操作慢。
使用自增 id 的内部结构:
自增的主键的值是顺序的,所以 InnoDB 把每一条记录都存储在一条记录的后面。
* 当达到页面的最大填充因子时候(InnoDB 默认的最大填充因子是页大小的 15/16,会留出 1/16 的空间留作以后的修改)。
* 下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费。
* 新插入的行一定会在原有的最大数据行下一行,MySQL 定位和寻址很快,不会为计算新行的位置而做出额外的消耗。减少了页分裂和碎片的产生。
使用 uuid 的索引内部结构
插入UUID: 新的记录可能会插入之前记录的中间,因此需要移动之前的记录
因为 uuid 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以 innodb 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
1. 写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb 在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机 IO。
2. 因为写入是乱序的,innodb 不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上。
3. 由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片。
4. 在把随机值(uuid 和雪花 id)载入到聚簇索引(InnoDB 默认的索引类型)以后,有时候会需要做一次 OPTIMEIZE TABLE 来重建表并优化页的填充,这将又需要一定的时间消耗。
结论:使用 InnoDB 应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行。如果是分库分表场景下,分布式主键ID的生成方案 优先选择雪花算法生成全局唯一主键(雪花算法生成的主键在一定程度上是有序的)。
5、InnoDB与MyISAM的区别?
InnoDB和MyISAM是使用MySQL时最常用的两种引擎类型,我们重点来看下两者区别。
* 事务和外键
InnoDB支持事务和外键,具有安全性和完整性,适合大量insert或update操作
MyISAM不支持事务和外键,它提供高速存储和检索,适合大量的select查询操作
* 锁机制
InnoDB支持行级锁,锁定指定记录。基于索引来加锁实现。
MyISAM支持表级锁,锁定整张表。
* 索引结构
InnoDB使用聚簇索引,索引和记录在一起存储,既缓存索引,也缓存记录。
MyISAM使用非聚簇索引,索引和记录分开。
* 并发处理能力
MyISAM使用表锁,会导致写操作并发率低,读之间并不阻塞,读写阻塞。
InnoDB读写阻塞可以与隔离级别有关,可以采用多版本并发控制(MVCC)来支持高并发
* 存储文件
InnoDB表对应两个文件,一个.frm表结构文件,一个.ibd数据文件。InnoDB表最大支持64TB;
MyISAM表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。从MySQL5.0开始默认限制是256TB。
MyISAM 适用场景:
* 不需要事务支持(不支持)
* 并发相对较低(锁定机制问题)
* 数据修改相对较少,以读为主
* 数据一致性要求不高
InnoDB 适用场景
* 需要事务支持(具有较好的事务特性)
* 行级锁定对高并发有很好的适应能力
* 数据更新较为频繁的场景
* 数据一致性要求较高
* 硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘IO
两种引擎该如何选择?
* 是否需要事务?有,InnoDB
* 是否存在并发修改?有,InnoDB
* 是否追求快速查询,且数据修改少?是,MyISAM
* 在绝大多数情况下,推荐使用InnoDB