前言
这里主要是 由于之前的一个 datetime 存储的时间 导致的问题的衍生出来的探究
探究的主要内容为 int 类类型的存储, 浮点类类型的存储, char 类类型的存储, blob 类类型的存储, enum/json/set/bit 类类型的存储
本文主要 的相关内容是 char 类类型的相关数据的存储
这部分数据 客户端 和 服务器这边的交互 主要是以字符串的形式交互
服务器这边的存储 主要是 按照特定的编码进行存储
mysql 中 char 的服务器客户端的数据交互
测试表结构如下
CREATE TABLE `tz_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`field1` char(6) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
INSERT INTO `test`.`tz_test`(`id`, `field1`) VALUES (1, '123456');
测试脚本如下
package com.hx.test07;
/**
* Test06MysqlTimezone
*
* @author Jerry.X.He
* @version 1.0
* @date 2023/4/24 16:26
*/
public class Test06MysqlTimezone {
// Test06MysqlTimezone
public static void main(String[] args) {
String url = "jdbc:mysql://10.60.50.16:3306/test?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&autoReconnectForPools=true&useSSL=false";
String username = "root";
String password = "root";
JdbcTemplate jdbcTemplate = Test14GenExpertSql.getMysqlJdbcTemplate(url, username, password);
String sql = " select * from tz_test; ";
List<Map<String, Object>> list = jdbcTemplate.queryForList(sql);
int x = 0;
}
}
mysql 是将给定的 char 的数据以 字符串的形式 交互给客户端的
mysql 服务器中对应的类型为 STRING
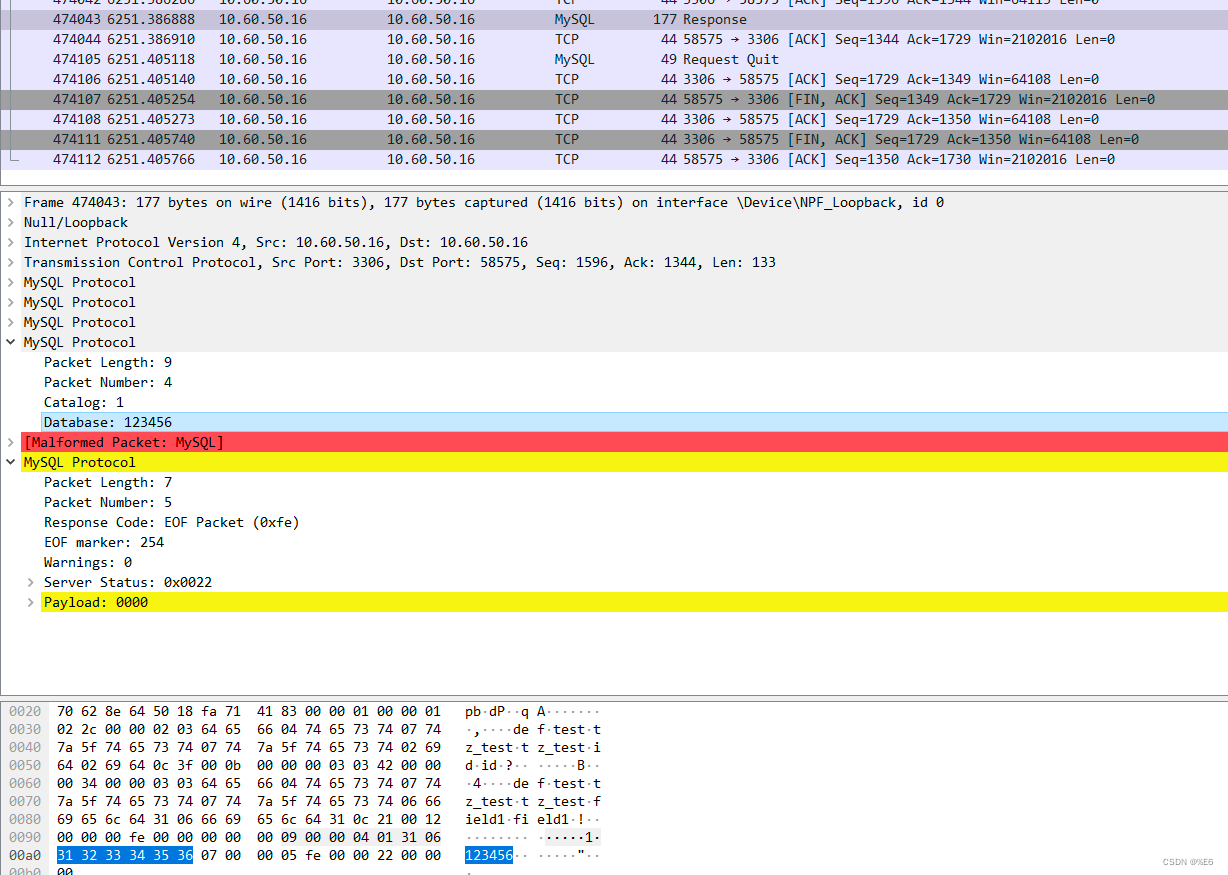
与客户端的交互, 本身存放的就是 目标字符串 按照指定的编码存放的 字节序列
这里 直接响应 原数据 即可
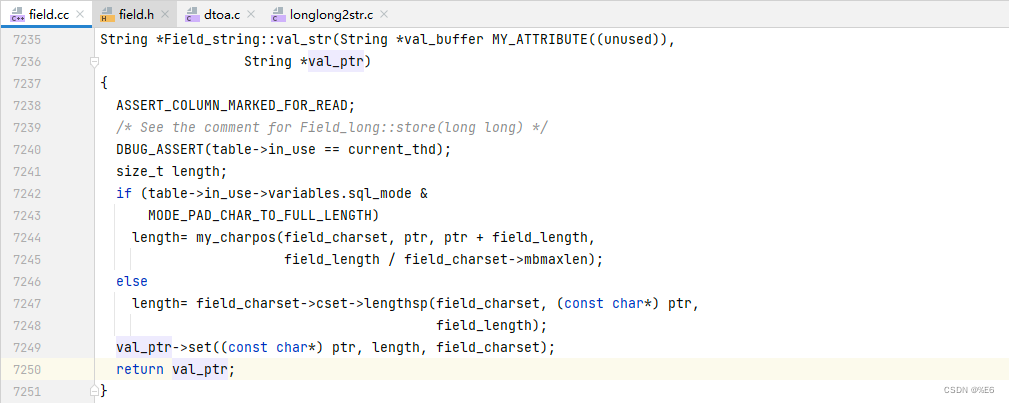
mysql 服务器 char 的存储
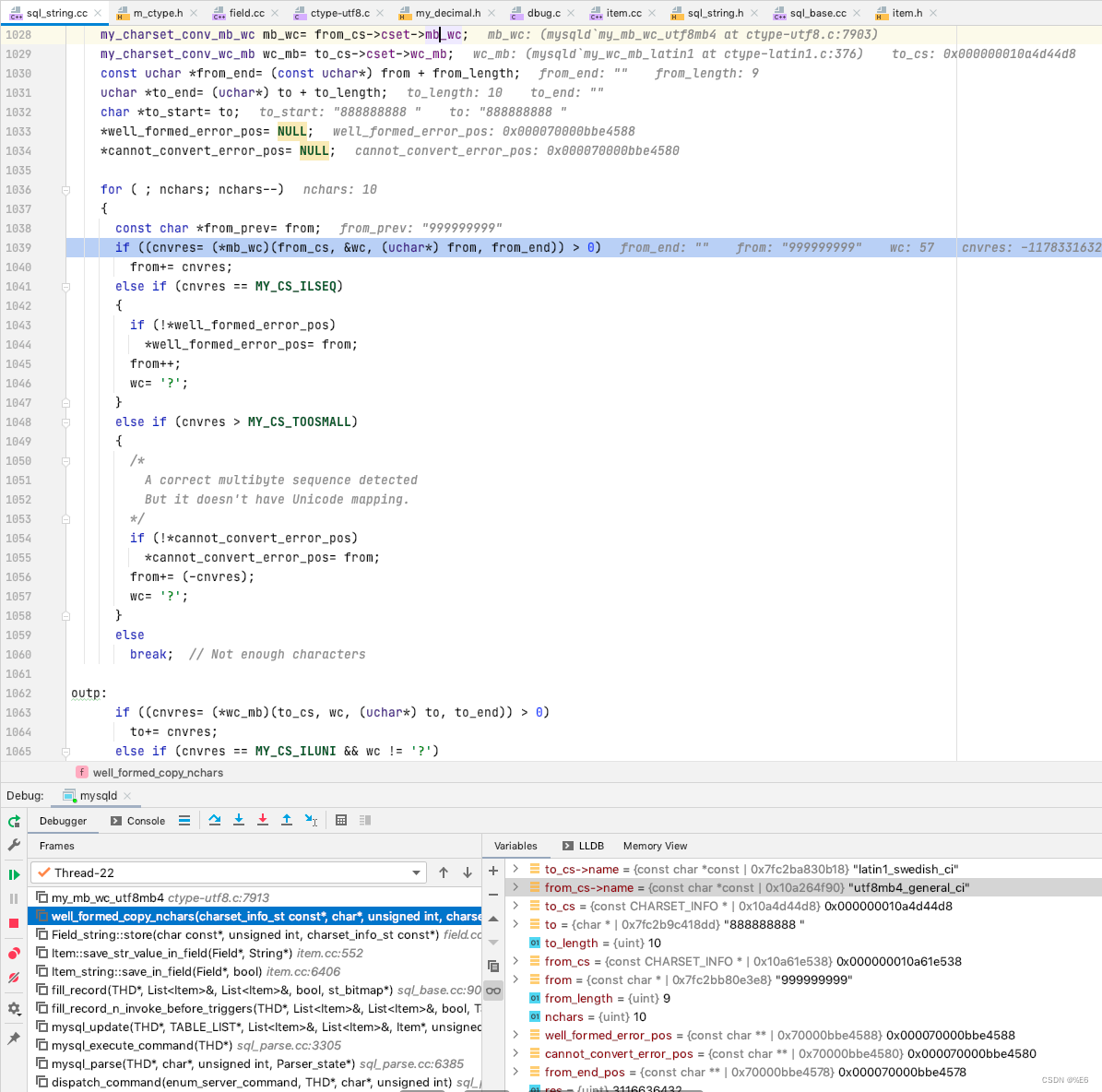
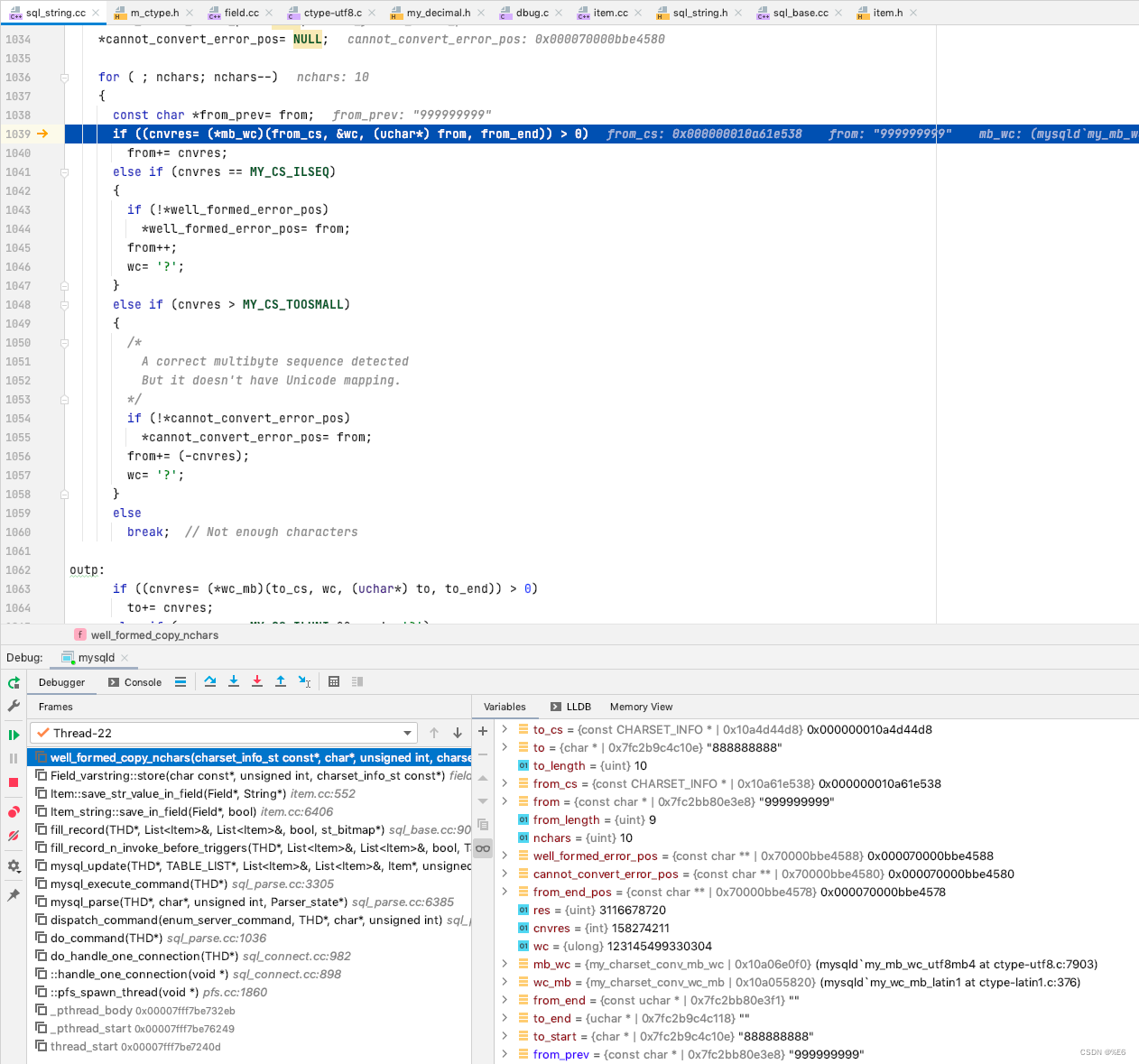
比如 这里我传入的是 “999999999”, 原始数据是 “888888888”
输入的字符集是 utf8_mb4_general_ci, 目标字段的字符集是 latin1_swedish_ci
然后这里的编码的转换处理是以 unicde 作为媒介进行的转换, utf8_mb4_general_ci 转换为 unicode, 然后再转换为 latin1_swedish_ci 的编码, 然后存储在 to 的位置
那么字符的存储就是以 这种编码来进行存储的
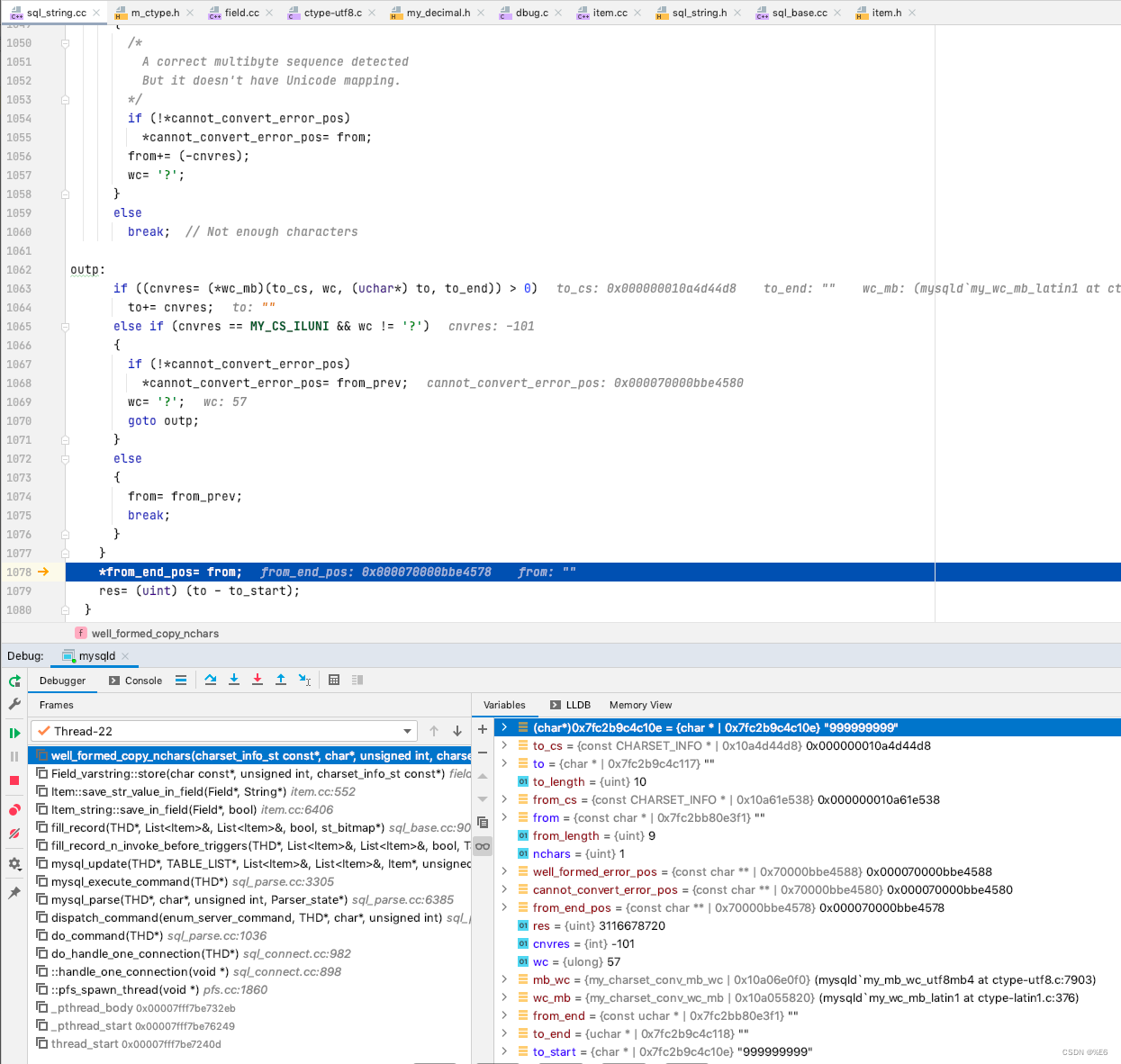
并且 如果长度不够 fieldLength, 则填充 空格至长度为 fieldLength, fieldLength 指的是字符的长度
处理之后, 给定的字段 更新成为了 “999999999 ”
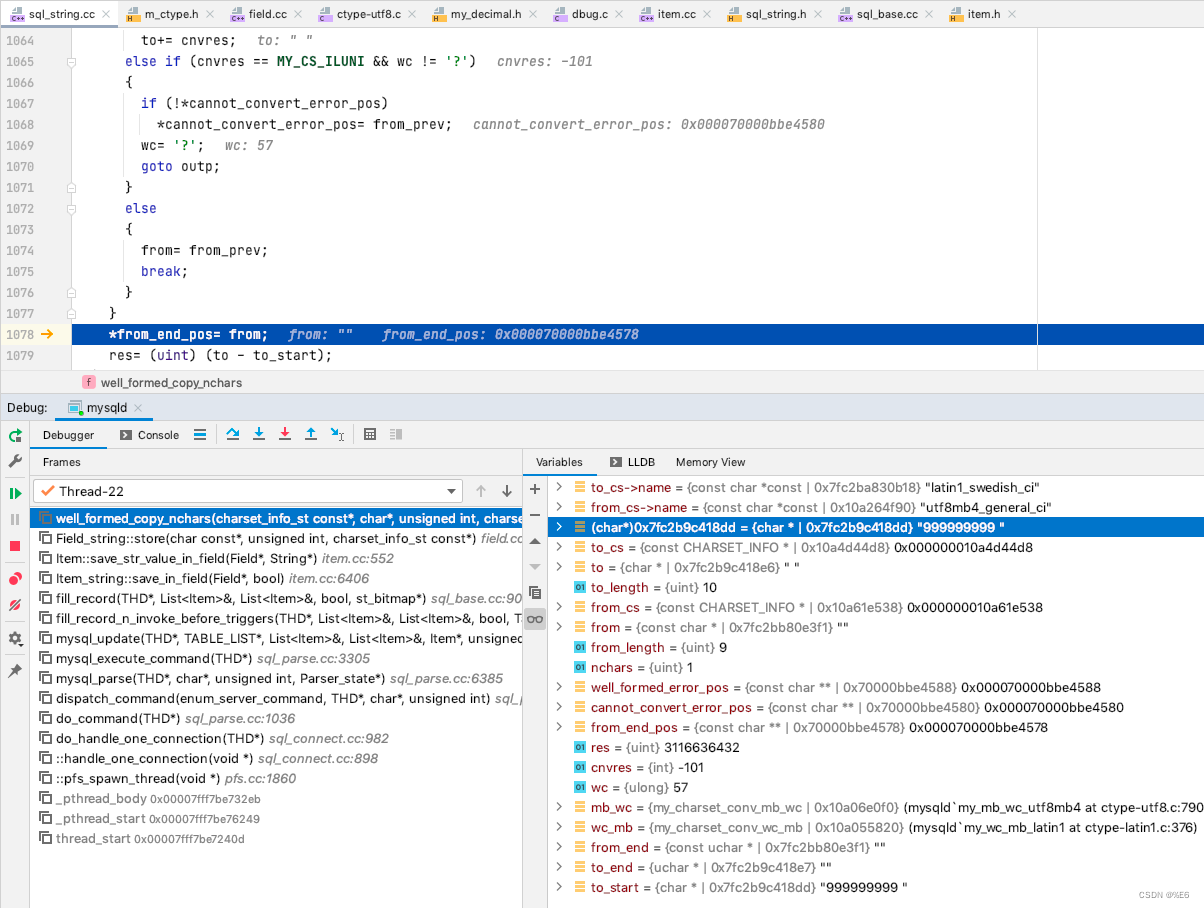
这里编码的转换多提一句
假设我这里设置的字段的编码集为 gbk 呢 ?
“你好” 中, 将 “你” 转换为 unicode 为 20320, 然后再转换为 gbk 存储
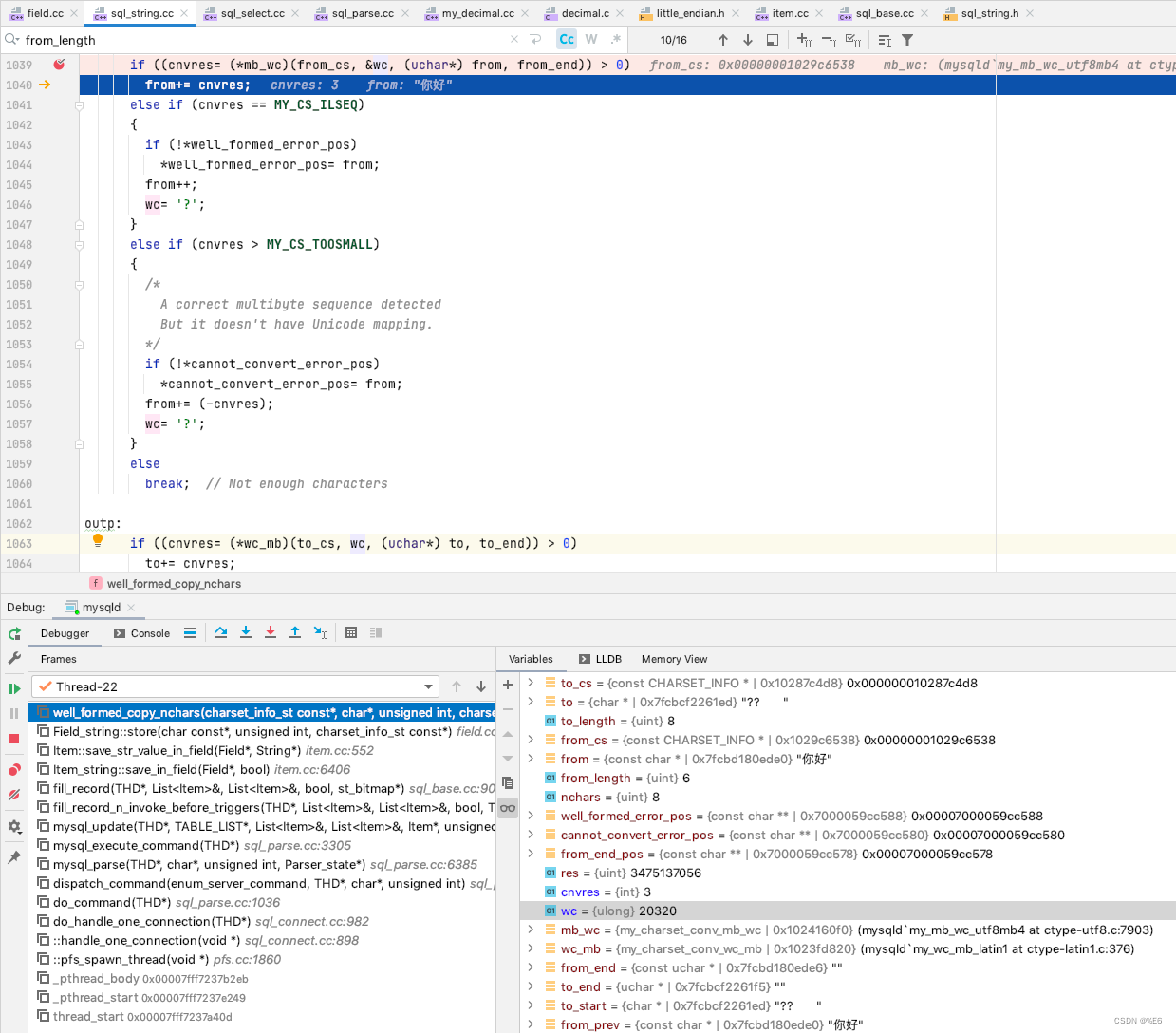
"你" 的 unicode, 以及 utf8 表示, 以及 gbk 表示
转换之后情况如下, 然后 我们来看一下 from 和 to 的相关信息
可以看到的是 "你" 按照了字段的编码集 gbk 转换为了字节存储
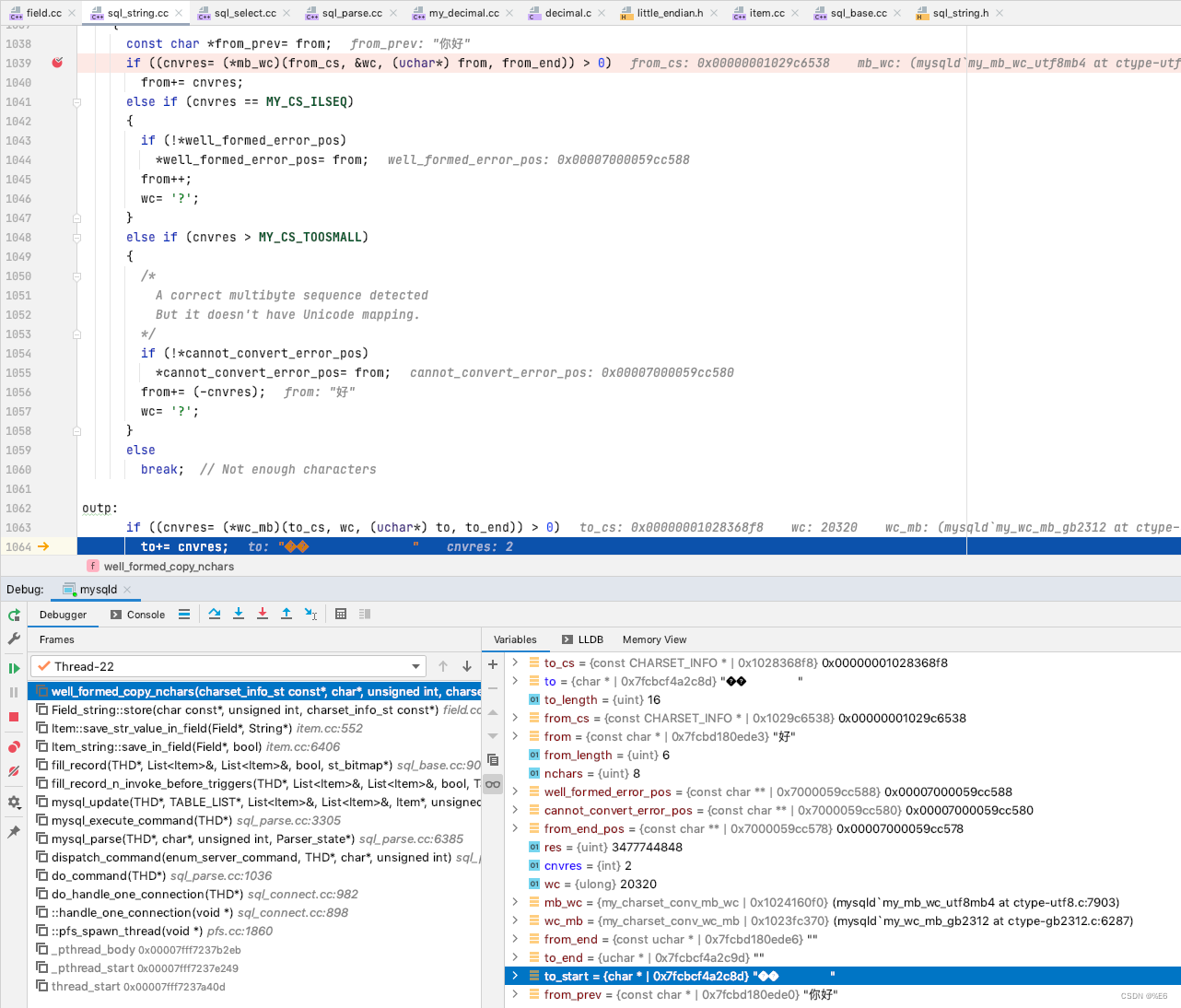
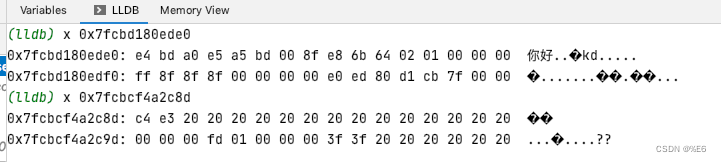
假设我这里设置的字段的编码集为 latin-1 呢 ?
目标编码集 latin-1 不兼容于 unicode 中的 "你" 的中文表述, 这里 mysql 将 "你" 更新为了 "?" 然后进行存储, 同样 "好" 也存储为了 "?"
这是一种不可逆的数据丢失
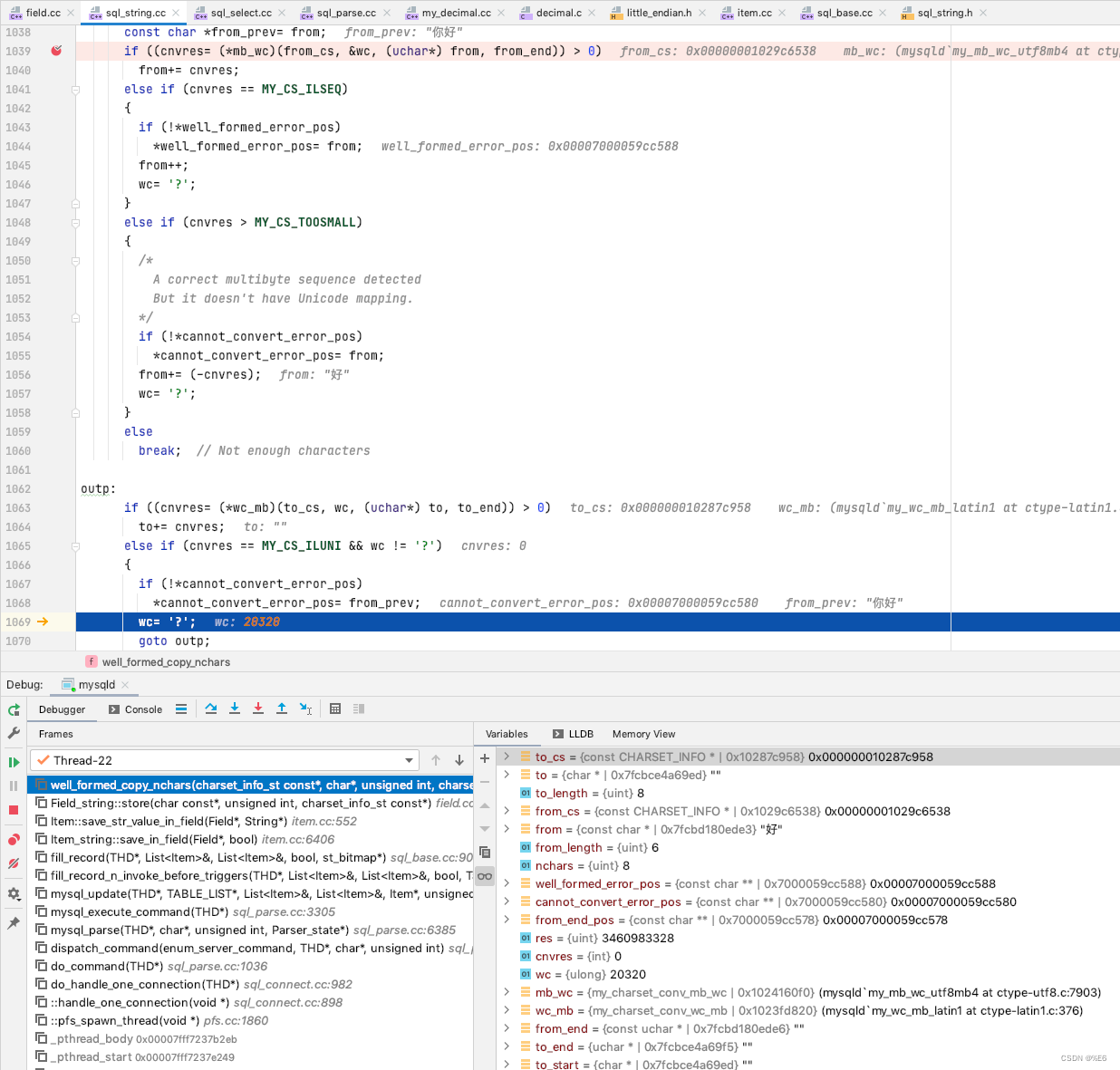
查看数据记录, 发现 field1 为 "??"
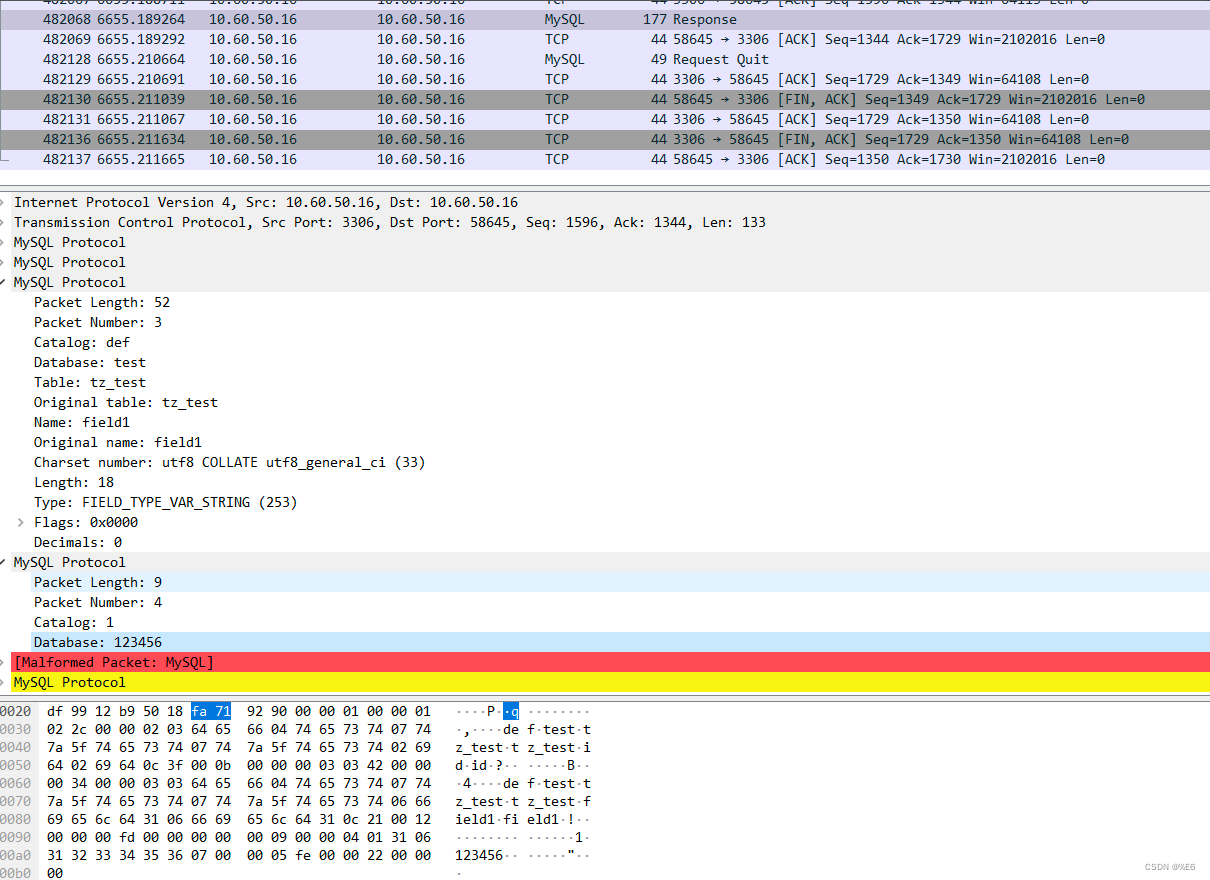
mysql 中 varchar的服务器客户端的数据交互
和上面 char 相同
mysql 服务器中对应的类型为 VAR_STRING
与客户端的交互, 本身存放的就是 目标字符串 按照指定的编码存放的 字节序列
这里 直接响应 原数据 即可
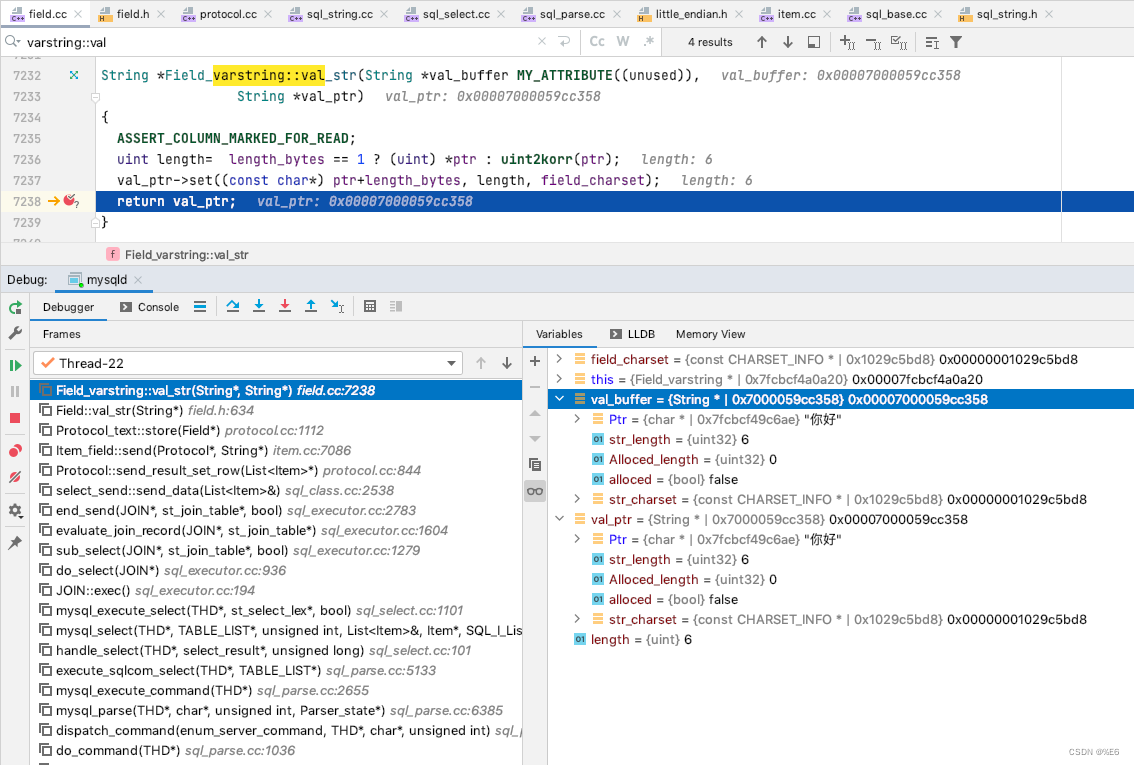
mysql 服务器 varchar 的存储
比如 这里我传入的是 “999999999”, 原始数据是 “888888888”
输入的字符集是 utf8_mb4_general_ci, 目标字段的字符集是 latin1_swedish_ci
然后这里的编码的转换处理是以 unicde 作为媒介进行的转换, utf8_mb4_general_ci 转换为 unicode, 然后再转换为 latin1_swedish_ci 的编码, 然后存储在 to 的位置
那么字符的存储就是以 这种编码来进行存储的
和上面 char 同理, char 如果长度不够 fieldLength 需要填充空格, varchar 存储是存储长度 和 具体的数据, fieldLength 指的是字符的长度
处理之后, 给定的字段 更新成为了 “999999999”
完