目录
一 算法简介
1)算法解释
2)概述
3)分类
4)前提
5)算法模板
6)常见问题
二 算法实践
1)反向扫描
1)反转字符串(一)
题目描述
思路
解法
2)反转字符串(二)
题目描述
思路
解法
3)有序数组的平方
题目描述
思路
解法
2)同向扫描
1)移除元素
题目描述
思路
解法
2)替换空格
题目描述
思路
解法
3)翻转字符串里的单词
题目描述
思路
解法
4)三数之和
题目描述
思路
解法
去重逻辑的思考
4)四数之和(了解)
题目描述
思路
解法
3)同向扫描经典应用一:滑动窗口
1)简介
2)题目实践
1)长度最小的子数组
题目描述
思路
解法
2)寻找区间和
题目描述
思路
解法
4)同向扫描经典应用二:数组去重
问题描述
解法
1)哈希
2)尺取法
5)同向扫描经典应用三:多指针
问题描述
解法
6)与链表相关的题目
1)翻转链表
题目描述
思路
解法
2)删除链表的倒数第N个节点
题目描述
思路
解法
3)链表相交
题目描述
思路
解法
4)环形链表
题目描述
思路
解法
总结:判断链表中是否含有环
一 算法简介
1)算法解释
双指针主要用于遍历数组,两个指针指向不同的元素,从而协同完成任务。也可以延伸到多 个数组的多个指针。
若两个指针指向同一数组,遍历方向相同且不会相交,则也称为滑动窗口(两个指针包围的 区域即为当前的窗口),经常用于区间搜索。
若两个指针指向同一数组,但是遍历方向相反,则可以用来进行搜索,待搜索的数组往往是 排好序的。
2)概述
定义快慢指针
- 快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
- 慢指针:指向更新 新数组下标的位置
双指针法(快慢指针法):通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
- 暴力解法时间复杂度:O(n^2)
- 双指针时间复杂度:O(n)
3)分类
i和j有以下两种扫描方向:
1.同向扫描:两个指针从头开始一起走,速度不同,如让j跑在i前面
2.反向扫描:一个指针从头开始,一个指针从尾开始,在中间相会
把同向扫描的i,j指针称为快慢指针,把反向扫描的i,j指针称为左右指针,更加形象。其中快慢指针在序列上产生了一个大小可变的滑动窗口,有灵活的应用,如寻找区间,数组去重,多指针问题
时间复杂度 : O(n)或者O(n logn)
4)前提
1)给定一个序列,有时需要他是有序的,先排序
2)问题和序列的区间有关,且需要操作两个变量,可以用两个下标(指针)i和j扫描区间
5)算法模板
//用while实现
int i=0,j=n-1;
while(i<j)//i和j再中间相遇,这样做还能防止i和j越界
{
...//满足题意的要求
i++;//i从头扫到尾
j--;//j从尾扫到头
}
//用for实现
for(int i=0,j=n-1;i<j;i++,j--)
{
...
}6)常见问题
(1) 对于一个序列,用两个指针维护一段区间
(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
二 算法实践
1)反向扫描
1)反转字符串(一)
题目描述
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:["h","e","l","l","o"]
输出:["o","l","l","e","h"]
示例 2:
输入:["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]
思路
对于字符串,我们定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。
以字符串hello为例,过程如下:
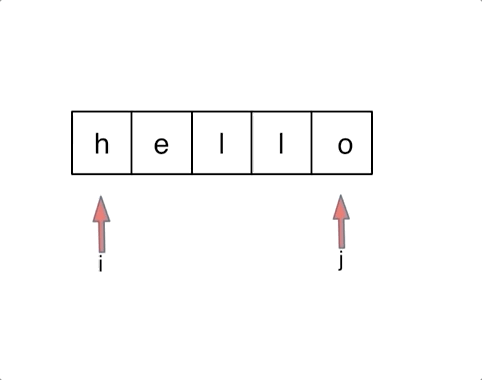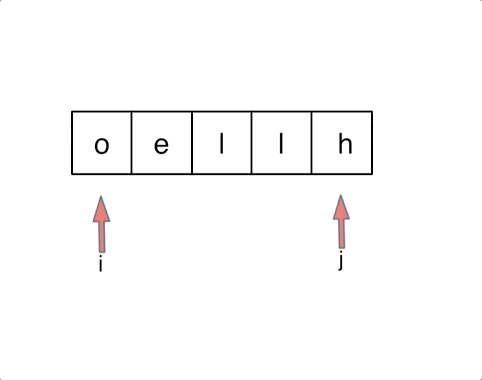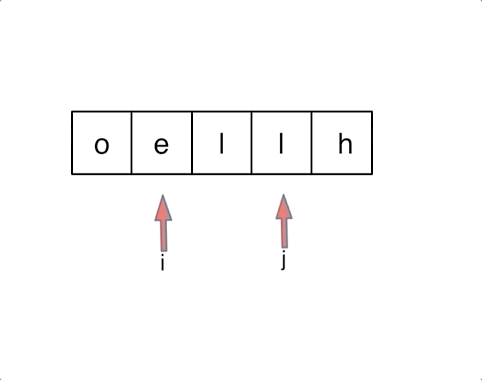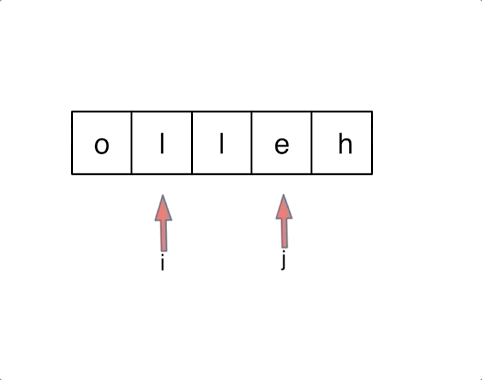
解法
双指针法
代码
void reverseString(char* s, int sSize){
int left = 0;
int right = sSize - 1;
while(left < right) {
char temp = s[left];
s[left++] = s[right];
s[right--] = temp;
}
}拓展
swap可以有两种实现。
一种就是常见的交换数值:
int tmp = s[i];
s[i] = s[j];
s[j] = tmp;
一种就是通过位运算:
s[i] ^= s[j];
s[j] ^= s[i];
s[i] ^= s[j];2)反转字符串(二)
题目描述
给定一个字符串 s 和一个整数 k,从字符串开头算起, 每计数至 2k 个字符,就反转这 2k 个字符中的前 k 个字符。
如果剩余字符少于 k 个,则将剩余字符全部反转。
如果剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符,其余字符保持原样。
示例:
输入: s = "abcdefg", k = 2
输出: "bacdfeg"
思路
模拟,实现题目中规定的反转规则就可以了
在遍历字符串的过程中,只要让 i += (2 * k),i 每次移动 2 * k 就可以了,然后判断是否需要有反转的区间。因为要找的也就是每2 * k 区间的起点
所以当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
解法
char * reverseStr(char * s, int k){
int len = strlen(s);
for (int i = 0; i < len; i += (2 * k)) {
//判断剩余字符是否少于 k
k = i + k > len ? len - i : k;
int left = i;
int right = i + k - 1;
while (left < right) {
char temp = s[left];
s[left++] = s[right];
s[right--] = temp;
}
}
return s;
}3)有序数组的平方
题目描述
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1: 输入:nums = [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后,数组变为 [16,1,0,9,100],排序后,数组变为 [0,1,9,16,100]
示例 2: 输入:nums = [-7,-3,2,3,11] 输出:[4,9,9,49,121]
思路
最直观的想法,莫过于:每个数平方之后,排个序。
暴力排序:这个时间复杂度是 O(n + nlogn), 可以说是O(nlogn)的时间复杂度,但为了和下面双指针法算法时间复杂度有鲜明对比,我记为 O(n + nlog n)。
双指针:
数组其实是有序的, 只不过负数平方之后可能成为最大数了。
那么数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。
此时可以考虑双指针法了,i指向起始位置,j指向终止位置。
定义一个新数组result,和A数组一样的大小,让k指向result数组终止位置。
如果A[i] * A[i] < A[j] * A[j] 那么result[k--] = A[j] * A[j]; 。
如果A[i] * A[i] >= A[j] * A[j] 那么result[k--] = A[i] * A[i]; 。
时间复杂度为O(n)
解法
暴力:
for (int i = 0; i < A.size(); i++) {
A[i] *= A[i];
}
sort(A.begin(), A.end()); // 快速排序
return A;双指针:
int* sortedSquares(int* nums, int numsSize, int* returnSize){
//返回的数组大小就是原数组大小
*returnSize = numsSize;
//创建两个指针,right指向数组最后一位元素,left指向数组第一位元素
int right = numsSize - 1;
int left = 0;
//最后要返回的结果数组
int* ans = (int*)malloc(sizeof(int) * numsSize);
int index;
for(index = numsSize - 1; index >= 0; index--) {
//左指针指向元素的平方
int lSquare = nums[left] * nums[left];
//右指针指向元素的平方
int rSquare = nums[right] * nums[right];
//若左指针指向元素平方比右指针指向元素平方大,将左指针指向元素平方放入结果数组。左指针右移一位
if(lSquare > rSquare) {
ans[index] = lSquare;
left++;
}
//若右指针指向元素平方比左指针指向元素平方大,将右指针指向元素平方放入结果数组。右指针左移一位
else {
ans[index] = rSquare;
right--;
}
}
//返回结果数组
return ans;
}2)同向扫描
1)移除元素
题目描述
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1: 给定 nums = [3,2,2,3], val = 3, 函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 你不需要考虑数组中超出新长度后面的元素。
示例 2: 给定 nums = [0,1,2,2,3,0,4,2], val = 2, 函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
你不需要考虑数组中超出新长度后面的元素。
思路
要知道数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。
解法
1)暴力法
两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。
删除过程如下:
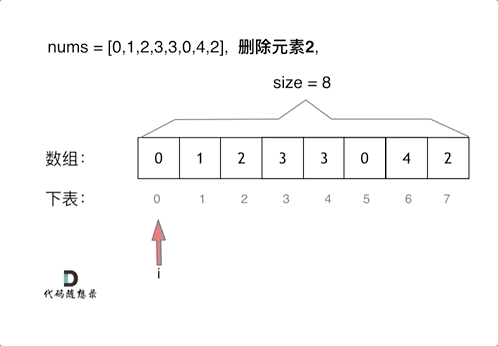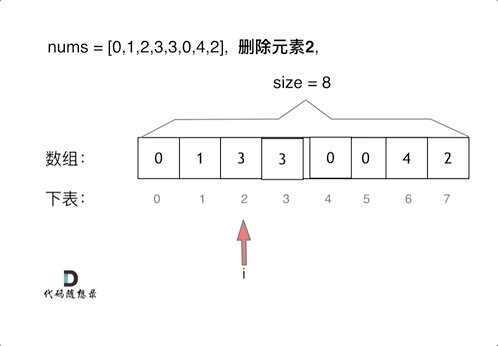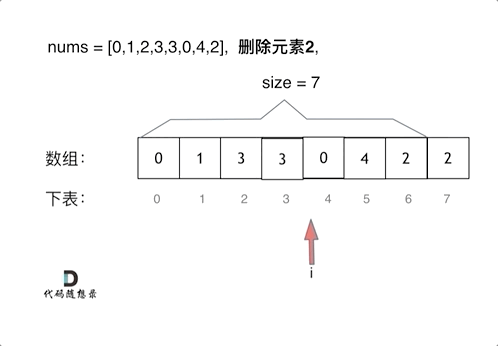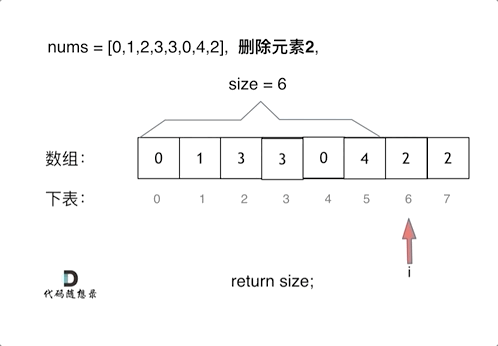
暴力解法的时间复杂度是O(n^2)
代码:
int size = nums.size();
for (int i = 0; i < size; i++) {
if (nums[i] == val) { // 发现需要移除的元素,就将数组集体向前移动一位
for (int j = i + 1; j < size; j++) {
nums[j - 1] = nums[j];
}
i--; // 因为下标i以后的数值都向前移动了一位,所以i也向前移动一位
size--; // 此时数组的大小-1
}
}
return size;2)双指针法
删除过程如下:

代码:
int removeElement(int* nums, int numsSize, int val){
int slow = 0;
for(int fast = 0; fast < numsSize; fast++) {
//若快指针位置的元素不等于要删除的元素
if(nums[fast] != val) {
//将其挪到慢指针指向的位置,慢指针+1
nums[slow++] = nums[fast];
}
}
//最后慢指针的大小就是新的数组的大小
return slow;
}- 时间复杂度:O(n)
- 空间复杂度:O(1)
注意:这些实现方法并没有改变元素的相对位置!
2)替换空格
题目描述
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1: 输入:s = "We are happy."
输出:"We%20are%20happy."
思路
如果想把这道题目做到极致,就不要只用额外的辅助空间了!
首先扩充数组到每个空格替换成"%20"之后的大小。
然后从后向前替换空格,也就是双指针法,过程如下:
i指向新长度的末尾,j指向旧长度的末尾。
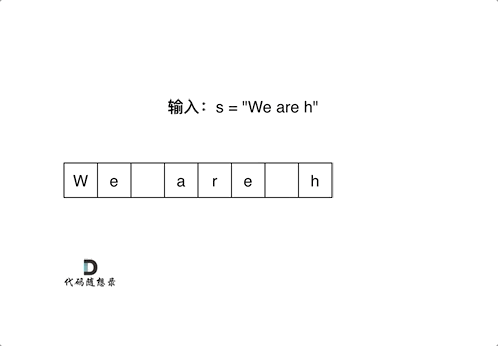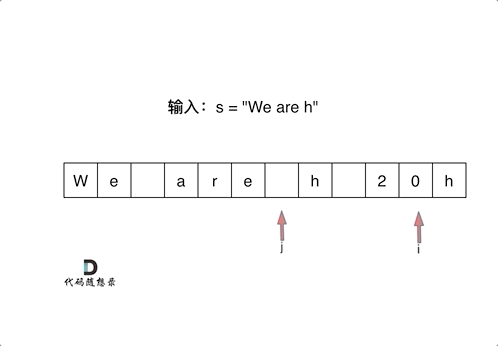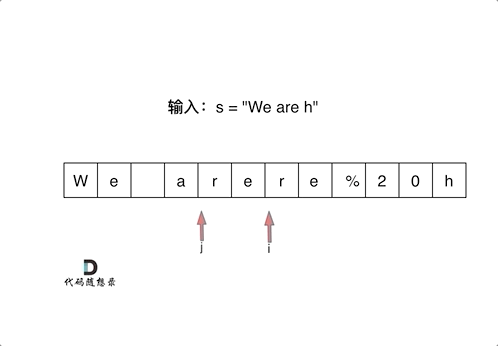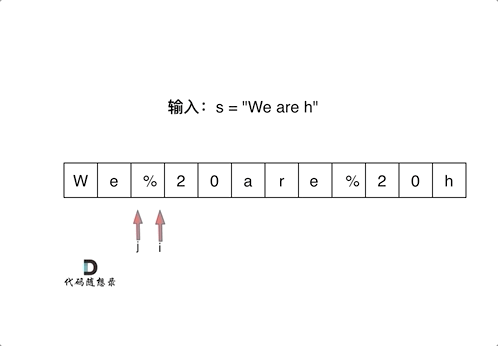
为什么要从后向前填充,从前向后填充不行么?
从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
这么做有两个好处:
- 不用申请新数组。
- 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
解法
双指针
代码
char* replaceSpace(char* s){
//统计空格数量
int count = 0;
int len = strlen(s);
for (int i = 0; i < len; i++) {
if (s[i] == ' ') {
count++;
}
}
//为新数组分配空间
int newLen = len + count * 2;
char* result = malloc(sizeof(char) * newLen + 1);
//填充新数组并替换空格
for (int i = len - 1, j = newLen - 1; i >= 0; i--, j--) {
if (s[i] != ' ') {
result[j] = s[i];
} else {
result[j--] = '0';
result[j--] = '2';
result[j] = '%';
}
}
result[newLen] = '\0';
return result;
}- 时间复杂度:O(n)
- 空间复杂度:O(1)
3)翻转字符串里的单词
题目描述
给定一个字符串,逐个翻转字符串中的每个单词。
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
思路
提高难度:不使用辅助空间,空间复杂度要求为O(1)
不能使用辅助空间之后,那么只能在原字符串上下功夫了。
想一下,我们将整个字符串都反转过来,那么单词的顺序指定是倒序了,只不过单词本身也倒序了,那么再把单词反转一下,单词不就正过来了。
所以解题思路如下:
1)移除多余空格
2)将整个字符串反转
3)将每个单词反转
举个例子,源字符串为:"the sky is blue "
- 移除多余空格 : "the sky is blue"
- 字符串反转:"eulb si yks eht"
- 单词反转:"blue is sky the"
这样我们就完成了翻转字符串里的单词
解法
双指针
代码:
注意:不是C语言,理解思想即可
void reverse(string& s, int start, int end){ //翻转,区间写法:左闭又闭 []
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
int slow = 0; //
for (int i = 0; i < s.size(); ++i) { //
if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
s[slow++] = s[i++];
}
}
}
s.resize(slow); //slow的大小即为去除多余空格后的大小。
}
string reverseWords(string s) {
removeExtraSpaces(s); //去除多余空格,保证单词之间之只有一个空格,且字符串首尾没空格。
reverse(s, 0, s.size() - 1);
int start = 0; //removeExtraSpaces后保证第一个单词的开始下标一定是0。
for (int i = 0; i <= s.size(); ++i) {
if (i == s.size() || s[i] == ' ') { //到达空格或者串尾,说明一个单词结束。进行翻转。
reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
start = i + 1; //更新下一个单词的开始下标start
}
}
return s;
}4)三数之和
题目描述
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意: 答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ]
思路
注意[0, 0, 0, 0] 这组数据
动画效果图
拿这个nums数组来举例,首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上。
依然还是在数组中找到 abc 使得a + b +c =0,我们这里相当于 a = nums[i],b = nums[left],c = nums[right]。
接下来如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些。
如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
时间复杂度:O(n^2)。
解法
//qsort辅助cmp函数
int cmp(const void* ptr1, const void* ptr2) {
return *((int*)ptr1) > *((int*)ptr2);
}
int** threeSum(int* nums, int numsSize, int* returnSize, int** returnColumnSizes) {
//开辟ans数组空间
int **ans = (int**)malloc(sizeof(int*) * 18000);
int ansTop = 0;
//若传入nums数组大小小于3,则需要返回数组大小为0
if(numsSize < 3) {
*returnSize = 0;
return ans;
}
//对nums数组进行排序
qsort(nums, numsSize, sizeof(int), cmp);
int i;
//用for循环遍历数组,结束条件为i < numsSize - 2(因为要预留左右指针的位置)
for(i = 0; i < numsSize - 2; i++) {
//若当前i指向元素>0,则代表left和right以及i的和大于0。直接break
if(nums[i] > 0)
break;
//去重:i > 0 && nums[i] == nums[i-1]
if(i > 0 && nums[i] == nums[i-1])
continue;
//定义左指针和右指针
int left = i + 1;
int right = numsSize - 1;
//当右指针比左指针大时进行循环
while(right > left) {
//求出三数之和
int sum = nums[right] + nums[left] + nums[i];
//若和小于0,则左指针+1(因为左指针右边的数比当前所指元素大)
if(sum < 0)
left++;
//若和大于0,则将右指针-1
else if(sum > 0)
right--;
//若和等于0
else {
//开辟一个大小为3的数组空间,存入nums[i], nums[left]和nums[right]
int* arr = (int*)malloc(sizeof(int) * 3);
arr[0] = nums[i];
arr[1] = nums[left];
arr[2] = nums[right];
//将开辟数组存入ans中
ans[ansTop++] = arr;
//去重
while(right > left && nums[right] == nums[right - 1])
right--;
while(left < right && nums[left] == nums[left + 1])
left++;
//更新左右指针
left++;
right--;
}
}
}
//设定返回的数组大小
*returnSize = ansTop;
*returnColumnSizes = (int*)malloc(sizeof(int) * ansTop);
int z;
for(z = 0; z < ansTop; z++) {
(*returnColumnSizes)[z] = 3;
}
return ans;
}去重逻辑的思考
a的去重
说道去重,其实主要考虑三个数的去重。 a, b ,c, 对应的就是 nums[i],nums[left],nums[right]
a 如果重复了怎么办,a是nums里遍历的元素,那么应该直接跳过去。
但这里有一个问题,是判断 nums[i] 与 nums[i + 1]是否相同,还是判断 nums[i] 与 nums[i-1] 是否相同。
这不都一样吗。
其实不一样!
都是和 nums[i]进行比较,是比较它的前一个,还是比较他的后一个。
如果我们的写法是 这样:
if (nums[i] == nums[i + 1]) { // 去重操作
continue;
}
那就我们就把 三元组中出现重复元素的情况直接pass掉了。 例如{-1, -1 ,2} 这组数据,当遍历到第一个-1 的时候,判断 下一个也是-1,那这组数据就pass了。
我们要做的是 不能有重复的三元组,但三元组内的元素是可以重复的!
所以这里是有两个重复的维度。
那么应该这么写:
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
这么写就是当前使用 nums[i],我们判断前一位是不是一样的元素,在看 {-1, -1 ,2} 这组数据,当遍历到 第一个 -1 的时候,只要前一位没有-1,那么 {-1, -1 ,2} 这组数据一样可以收录到 结果集里。
这是一个非常细节的思考过程。
b与c的去重
写本题的时候,去重的逻辑多加了 对right 和left 的去重:(代码中注释部分)
while (right > left) {
if (nums[i] + nums[left] + nums[right] > 0) {
right--;
// 去重 right
while (left < right && nums[right] == nums[right + 1]) right--;
} else if (nums[i] + nums[left] + nums[right] < 0) {
left++;
// 去重 left
while (left < right && nums[left] == nums[left - 1]) left++;
} else {
}
}
但细想一下,这种去重其实对提升程序运行效率是没有帮助的。
拿right去重为例,即使不加这个去重逻辑,依然根据 while (right > left) 和 if (nums[i] + nums[left] + nums[right] > 0) 去完成right-- 的操作。
多加了 while (left < right && nums[right] == nums[right + 1]) right--; 这一行代码,其实就是把 需要执行的逻辑提前执行了,但并没有减少 判断的逻辑。
最直白的思考过程,就是right还是一个数一个数的减下去的,所以在哪里减的都是一样的。
所以这种去重 是可以不加的。 仅仅是 把去重的逻辑提前了而已。
4)四数之和(了解)
题目描述
题意:给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
答案中不可以包含重复的四元组。
示例: 给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。 满足要求的四元组集合为: [ [-1, 0, 0, 1], [-2, -1, 1, 2], [-2, 0, 0, 2] ]
思路
四数之和,和三数之和是一个思路,都是使用双指针法, 基本解法就是在三数之和的基础上再套一层for循环。
但是有一些细节需要注意,例如: 不要判断nums[k] > target 就返回了,三数之和 可以通过 nums[i] > 0 就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值。比如:数组是[-4, -3, -2, -1],target是-10,不能因为-4 > -10而跳过。但是我们依旧可以去做剪枝,逻辑变成nums[i] > target && (nums[i] >=0 || target >= 0)就可以了。
三数之和的双指针解法是一层for循环num[i]为确定值,然后循环内有left和right下标作为双指针,找到nums[i] + nums[left] + nums[right] == 0。
四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下标作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。
那么一样的道理,五数之和、六数之和等等都采用这种解法。
对于三数之和双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。
解法
c++代码
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for (int k = 0; k < nums.size(); k++) {
// 剪枝处理
if (nums[k] > target && nums[k] >= 0) {
break; // 这里使用break,统一通过最后的return返回
}
// 对nums[k]去重
if (k > 0 && nums[k] == nums[k - 1]) {
continue;
}
for (int i = k + 1; i < nums.size(); i++) {
// 2级剪枝处理
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
// 对nums[i]去重
if (i > k + 1 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// nums[k] + nums[i] + nums[left] + nums[right] > target 会溢出
if ((long) nums[k] + nums[i] + nums[left] + nums[right] > target) {
right--;
// nums[k] + nums[i] + nums[left] + nums[right] < target 会溢出
} else if ((long) nums[k] + nums[i] + nums[left] + nums[right] < target) {
left++;
} else {
result.push_back(vector<int>{nums[k], nums[i], nums[left], nums[right]});
// 对nums[left]和nums[right]去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
}
return result;
}
};3)同向扫描经典应用一:滑动窗口
1)简介
滑动窗口,就是不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果
滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)暴力解法降为O(n)。
2)题目实践
1)长度最小的子数组
题目描述
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。
示例:
输入:s = 7, nums = [2,3,1,2,4,3] 输出:2 解释:子数组 [4,3] 是该条件下的长度最小的子数组
思路
暴力法:
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
滑动窗口:
在暴力解法中,是一个for循环滑动窗口的起始位置,一个for循环为滑动窗口的终止位置,用两个for循环 完成了一个不断搜索区间的过程。
那么滑动窗口如何用一个for循环来完成这个操作呢。
首先要思考 如果用一个for循环,那么应该表示 滑动窗口的起始位置,还是终止位置。
如果只用一个for循环来表示 滑动窗口的起始位置,那么如何遍历剩下的终止位置?
此时难免再次陷入 暴力解法的怪圈。
所以 只用一个for循环,那么这个循环的索引,一定是表示 滑动窗口的终止位置。
那么问题来了, 滑动窗口的起始位置如何移动呢?
这里还是以题目中的示例来举例,s=7, 数组是 2,3,1,2,4,3,来看一下查找的过程:
动画效果图
最后找到 4,3 是最短距离。
其实从动画中可以发现滑动窗口也可以理解为双指针法的一种!只不过这种解法更像是一个窗口的移动,所以叫做滑动窗口更适合一些。
在本题中实现滑动窗口,主要确定如下三点:
- 窗口内是什么?
- 如何移动窗口的起始位置?
- 如何移动窗口的结束位置?
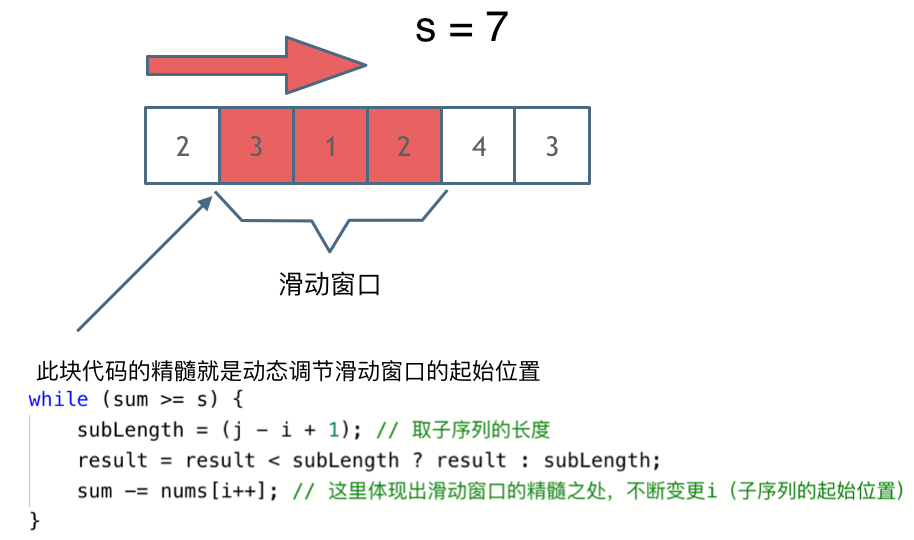
窗口就是 满足其和 ≥ s 的长度最小的 连续 子数组。
窗口的起始位置如何移动:如果当前窗口的值大于s了,窗口就要向前移动了(也就是该缩小了)。
窗口的结束位置如何移动:窗口的结束位置就是遍历数组的指针,也就是for循环里的索引。
解题的关键在于 窗口的起始位置如何移动,如图所示:
解法
暴力法:
这道题目暴力解法当然是 两个for循环,然后不断的寻找符合条件的子序列,时间复杂度很明显是O(n^2)。
int minSubArrayLen(int target, int* nums, int numsSize){
//初始化最小长度为INT_MAX
int minLength = INT_MAX;
int sum;
int left, right;
for(left = 0; left < numsSize; ++left) {
//每次遍历都清零sum,计算当前位置后和>=target的子数组的长度
sum = 0;
//从left开始,sum中添加元素
for(right = left; right < numsSize; ++right) {
sum += nums[right];
//若加入当前元素后,和大于target,则更新minLength
if(sum >= target) {
int subLength = right - left + 1;
minLength = minLength < subLength ? minLength : subLength;
}
}
}
//若minLength不为INT_MAX,则返回minLnegth
return minLength == INT_MAX ? 0 : minLength;
}滑动窗口:
int minSubArrayLen(int target, int* nums, int numsSize){
//初始化最小长度为INT_MAX
int minLength = INT_MAX;
int sum = 0;
int left = 0, right = 0;
//右边界向右扩展
for(; right < numsSize; ++right) {
sum += nums[right];
//当sum的值大于等于target时,保存长度,并且收缩左边界
while(sum >= target) {
int subLength = right - left + 1;
minLength = minLength < subLength ? minLength : subLength;
sum -= nums[left++];
}
}
//若minLength不为INT_MAX,则返回minLnegth
return minLength == INT_MAX ? 0 : minLength;
}2)寻找区间和
题目描述
给定一个长度为 n 的数组a]和一个数 s,在这个数组中找一个区间,使这个区间的数组元素之和等于 s。输出区间的起点和终点位置。说明:输入样例的第1行是n=15,第 2 行是数组a],第 3 行是区间和s=6。输出样例共有4种情况。
输人样例:
15
6 1 2 3 4 6 4 2 8 9 10 11 12 13 14
6
输出样例:
0 0
1 3
5 5
6 2
思路
指针i和j(i<j) 都从头向尾扫描,判断区间[i,j],数组元素的和是否等于 s。
如何寻找区间和等于 s 的区间? 如果简单地对 和做二重循环,复杂度为 O(n2)
用尺取法,复杂度为 O(n),操作步骤如下。
(1) 初始值 i=0,j=0,即开始都指向第 1 个元素a[o]。定义 sum 是区间[i,j]数组元
素的和,初始值 sum=a[0]。
(2) 如果 sum=s,输出一个解。继续,把 sum 减掉元素 a[i],并把向后移动一位。
(3)如果 sum>s,让 sum 减掉元素 a[],并把向后移动一位。
(4) 如果 sum<s,把,向后移动一位,并把 sum 的值加上这个新元素。在上面的步骤中,有两个关键技巧。
(1)滑动窗口的实现。窗口就是区间[i,门,随着和从头到尾移动,窗口就“滑动”扫描了整个序列,检索了所有数据。i 和,并不是同步增加的,窗口像一只蚯蚓伸缩前进,它的长度是变化的,这个变化正对应了对区间和的计算。
(2)sum 的使用。如何计算区间和? 暴力的方法是从 a[]到 a[j]累加,但是这个累加的复杂度为 O(n),超时。如果利用 sum,每次移动i或时,只需要把 sum 加或减一次,得到了区间和,复杂度为 O(1)。这是“前缀和”递推思想的应用。
解法
代码
void findsum(int *a,int s)
{
int i=0,j=0;
int sum=a[0];
while(j<n)//下面代码保证i<=j
{
if(sum>=s)
{
if(sum==s) printf("%d %d\n",i,j);
sum-=a[i];
i++;
if(i>j) {sum=a[i];j++}//防止i超过j
}
if(sum<s) {j++;sum+=a[j];}
}
}拓展
滑动窗口的例子还有:
1)给定一个序列以及一个整数M,在序列中找M个连续递增的元素,使他们的区间和最大
2)给定一个序列以及一个整数K,求一个最短的连续子序列,其中包含至少K个不同的元素
4)同向扫描经典应用二:数组去重
数组去重是很常见的操作,方法也很多,尺取法是比较优秀的算法;
问题描述
给定数组a[],长度为n,把数组中重复的数去掉
解法
1)哈希
哈希函数的特点是有冲突,利用这个特点去重。把所有数插入哈希表,用冲突过滤重复的数,就能得到不同的数。缺点是哈希把数据的值本身看作地址,如果数据值过大,需要的空间也非常大;
2)尺取法
1)将数组排序,排序后重复的整数就会挤在一起
2)定义双指针i和j,初始值都指向a[0].i和j都从头到尾扫描数组a[],i指针走得快,逐个遍历整个数组;j指针走的慢,他始终指向当前不重复部分的最后一个数。也就是说,j用于获取不重复的数
3)扫描数组。快指针执行i++,如果此时a【i】不等于满指针j指向的a[j],就执行j++,并且把a【i]
复制到满指针j的当前位置a【j】。
4)i扫描结束后,a[0]-a[j]就是不重复数组
5)同向扫描经典应用三:多指针
问题描述
给出一串数以及一个数字 C,要求计算出所有A-B=C 的数对的个数(不同位置的数字一样的数对算不同的数对)。
输入:共两行。第1行输入两个整数和C;第2 行输入个整数,作为要求处理的那串数。
输出:该串数中包含的满足A-B=C 的数对的个数。数据范围:1 n≤2X10;所有输入数据绝对值小于 2的30次方
输入样例:6 3
8 4 5 7 7 4
输出样例:
5
解法
尺取法:
对输人样例排序后得(4 4 5 7 7 8),其中第1个4和后面两个7 是两对,第2个4和面两个 7也是两对,共 4 对。如果仅使用 i 和两个指针,无法实现。如何解决?可以把后面两个7看作一个整体,一起统计数对。用两个指针 j和指这种区间,[j,k]区间内每个数都相同,这个区间可以产生k一i个数对。细节见下面的代码。使用3 个指针,i 是主指针,从头到尾遍历 n个数;j和k 是辅助指针,用于查找数字相同的区间[j,k]。
第 10 行的尺取法代码只有一个 for 循环,且和k 随着递增,所以复杂度为 O(n)。
另外,第8行的排序复杂度为 O(nlog2n)
#include < stdio.h>
const int N= 2e5 + 5;
int a[N];
int main ()
{
int n,c;
scanf("%d %d",&n,&c);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
sort(a+1,a+1+n);
long long ans= 0;
for(int i=1,j=1,k=1; i<= n;i++)
{
while(j<= n&&a[j] - a[i]<c) j++; //用j和k查找数字相同的区间
while(k<= n && a[k] - a[i]<= c) k++; //区间[j,k]内所有数字相同
if(a[j]-a[i]==c&& a[k-1]-a[i]==c&& k-1>=1) ans += k - j;
}
printf("%d",ans);
return 0;
}
6)与链表相关的题目
1)翻转链表
题目描述
反转一个单链表。
示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
思路
如果再定义一个新的链表,实现链表元素的反转,其实这是对内存空间的浪费。
其实只需要改变链表的next指针的指向,直接将链表反转 ,而不用重新定义一个新的链表,如图所示:
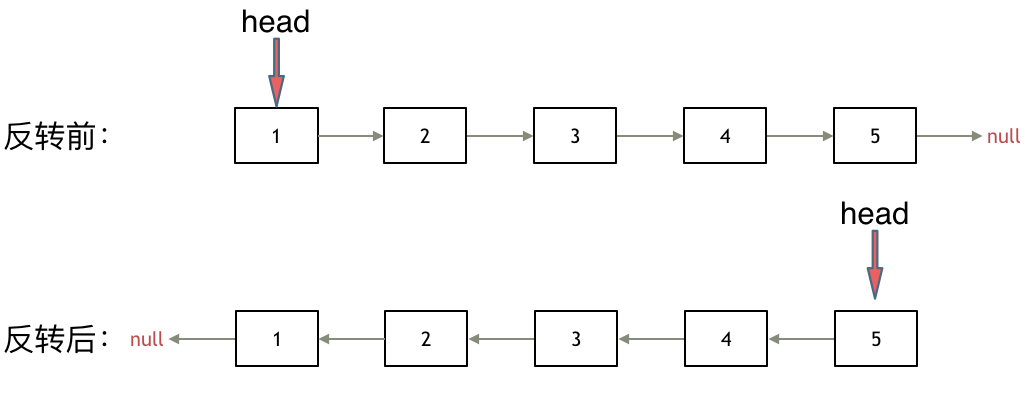
之前链表的头节点是元素1, 反转之后头结点就是元素5 ,这里并没有添加或者删除节点,仅仅是改变next指针的方向。
示例:
注意:下图应该是先移动pre,再移动cur;
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
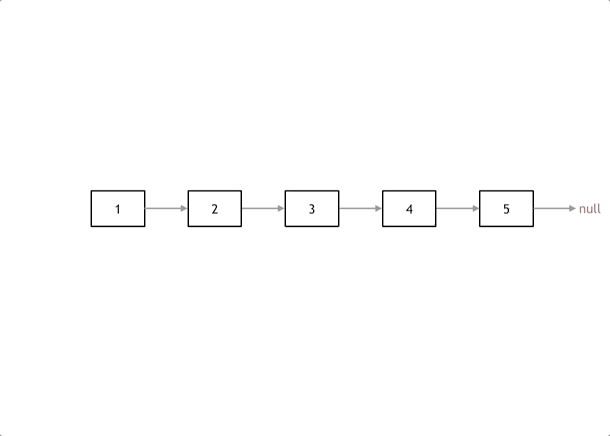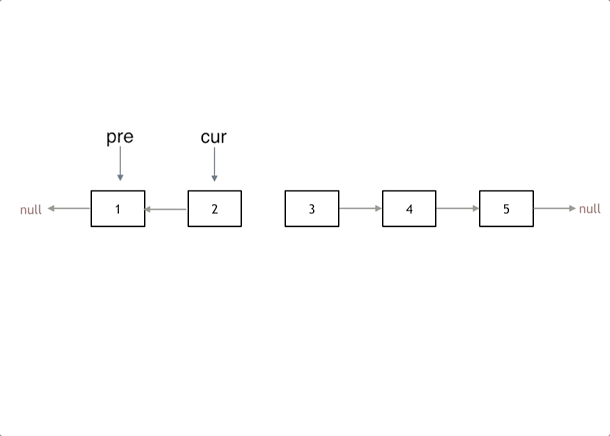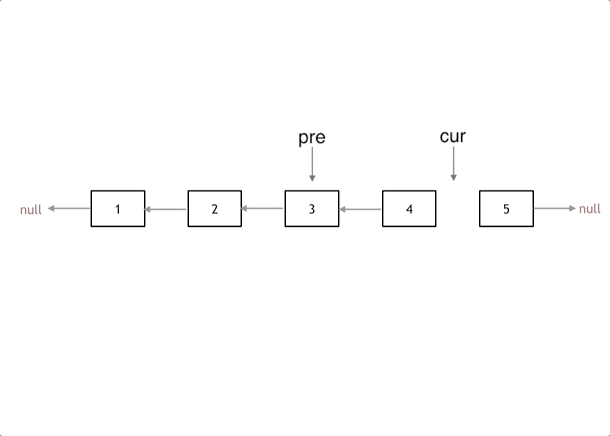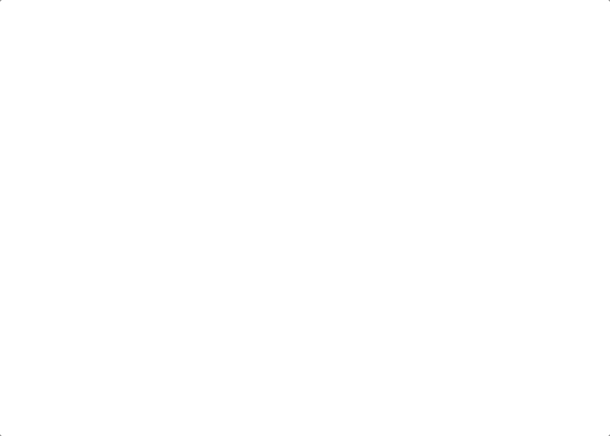
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
解法
双指针法
struct ListNode* reverseList(struct ListNode* head){
//保存cur的下一个结点
struct ListNode* temp;
//pre指针指向前一个当前结点的前一个结点
struct ListNode* pre = NULL;
//用head代替cur,也可以再定义一个cur结点指向head。
while(head) {
//保存下一个结点的位置
temp = head->next;
//翻转操作
head->next = pre;
//更新结点
pre = head;
head = temp;
}
return pre;
}递归法
struct ListNode* reverse(struct ListNode* pre, struct ListNode* cur) {
if(!cur)
return pre;
struct ListNode* temp = cur->next;
cur->next = pre;
//将cur作为pre传入下一层
//将temp作为cur传入下一层,改变其指针指向当前cur
return reverse(cur, temp);
}
struct ListNode* reverseList(struct ListNode* head){
return reverse(NULL, head);
}2)删除链表的倒数第N个节点
题目描述
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
进阶:你能尝试使用一趟扫描实现吗?
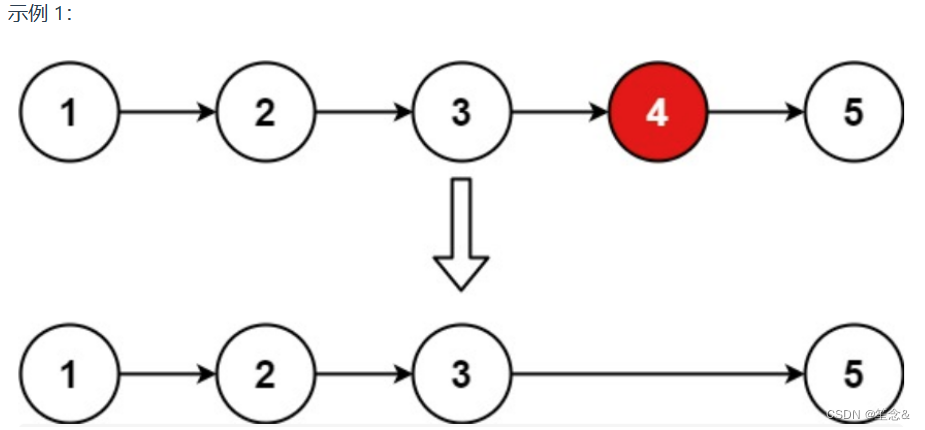
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1 输出:[]
示例 3:
输入:head = [1,2], n = 1 输出:[1]
思路
双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
思路是这样的,但要注意一些细节。
分为如下几步:
-
首先这里我推荐大家使用虚拟头结点,这样方便处理删除实际头结点的逻辑,
-
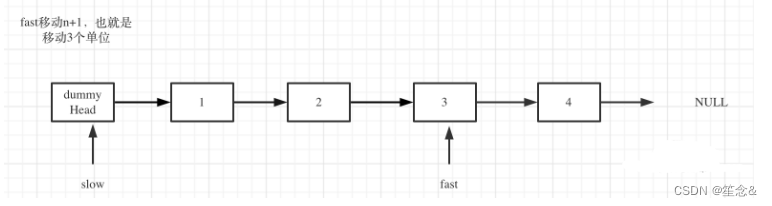
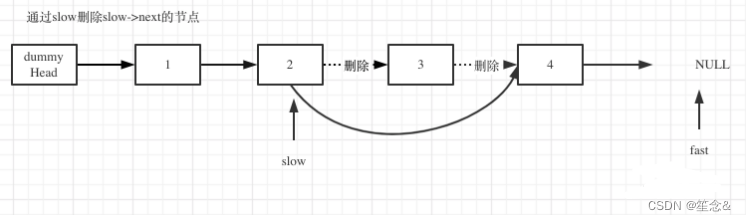
定义fast指针和slow指针,初始值为虚拟头结点,如图:
 fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
fast和slow同时移动,直到fast指向末尾,如图:
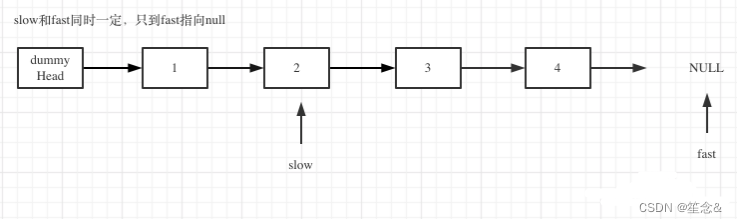
删除slow指向的下一个节点,如图:
解法
/**c语言单链表的定义
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {
//定义虚拟头节点dummy 并初始化使其指向head
struct ListNode* dummy = malloc(sizeof(struct ListNode));
dummy->val = 0;
dummy->next = head;
//定义 fast slow 双指针
struct ListNode* fast = head;
struct ListNode* slow = dummy;
for (int i = 0; i < n; ++i) {
fast = fast->next;
}
while (fast) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;//删除倒数第n个节点
head = dummy->next;
free(dummy);//删除虚拟节点dummy
return head;
}
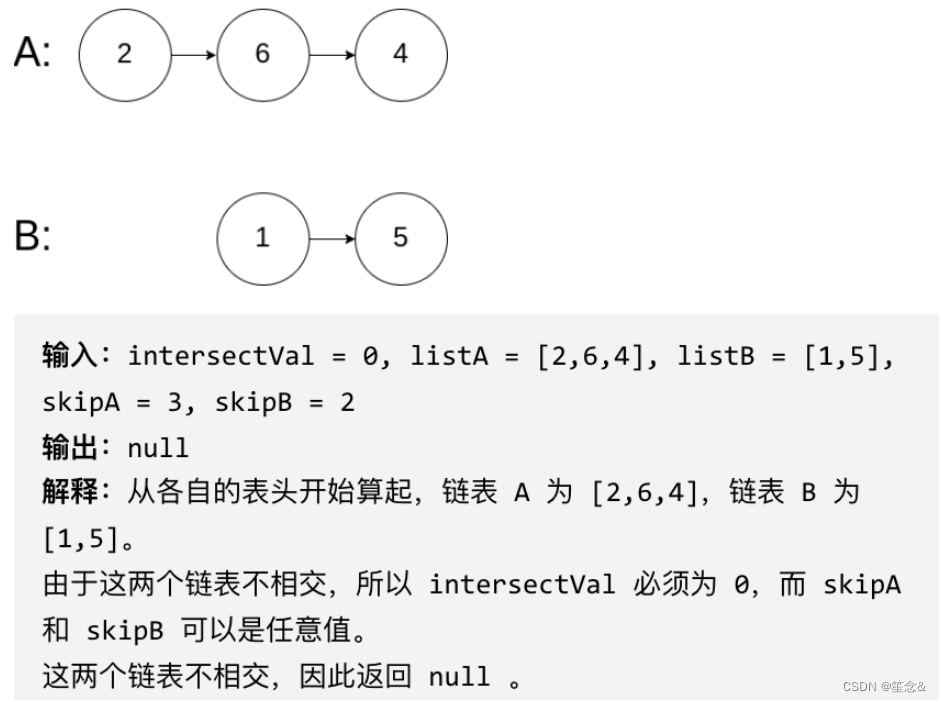
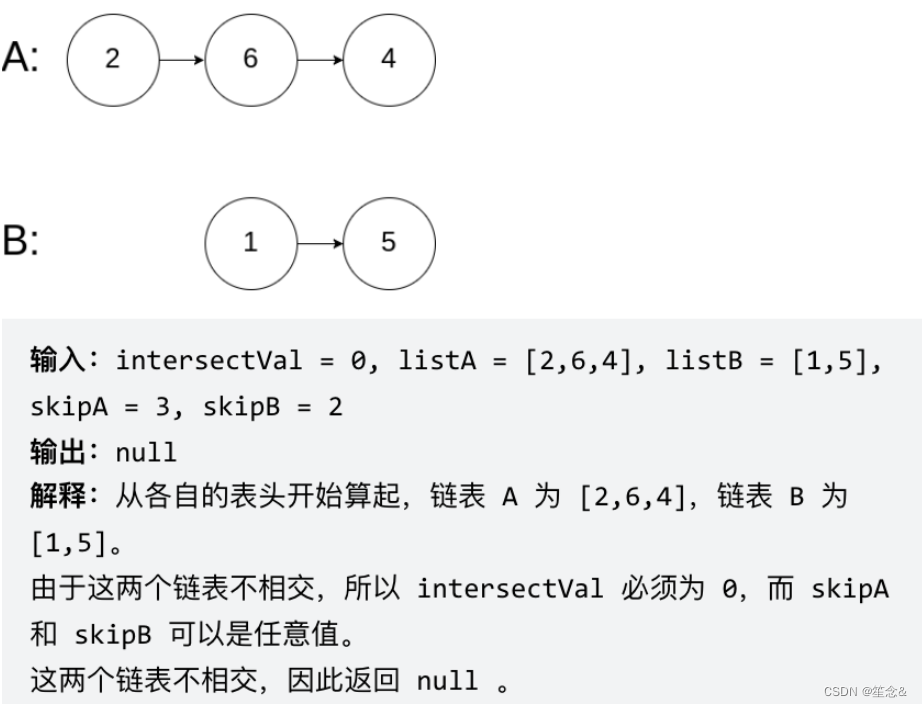
3)链表相交
题目描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
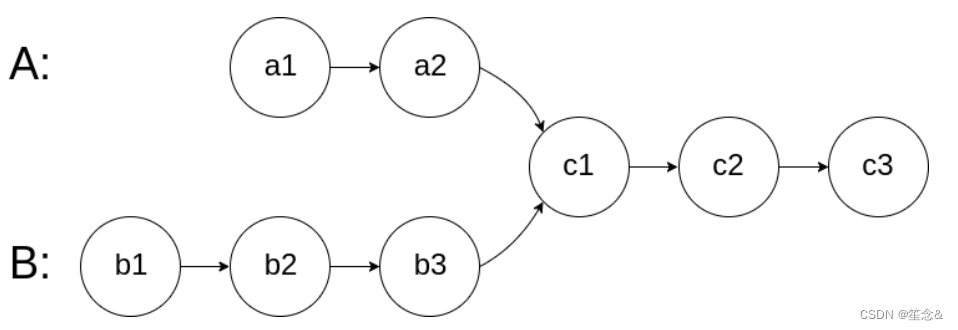
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:

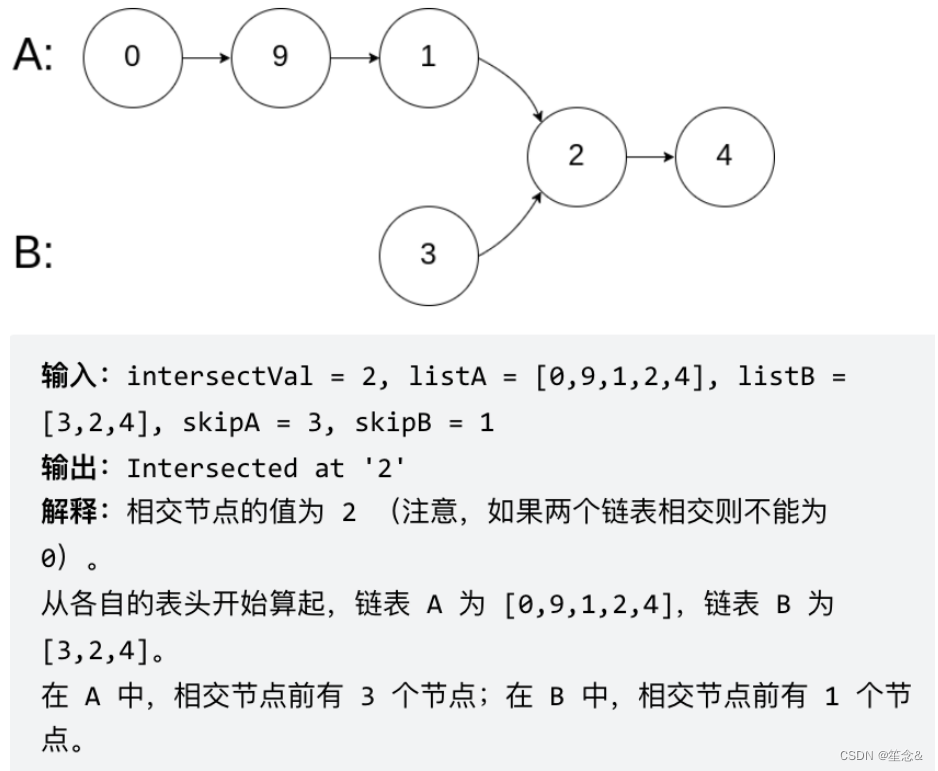
示例2:
示例 3:
思路
简单来说,就是求两个链表交点节点的指针。 这里同学们要注意,交点不是数值相等,而是指针相等。
为了方便举例,假设节点元素数值相等,则节点指针相等。
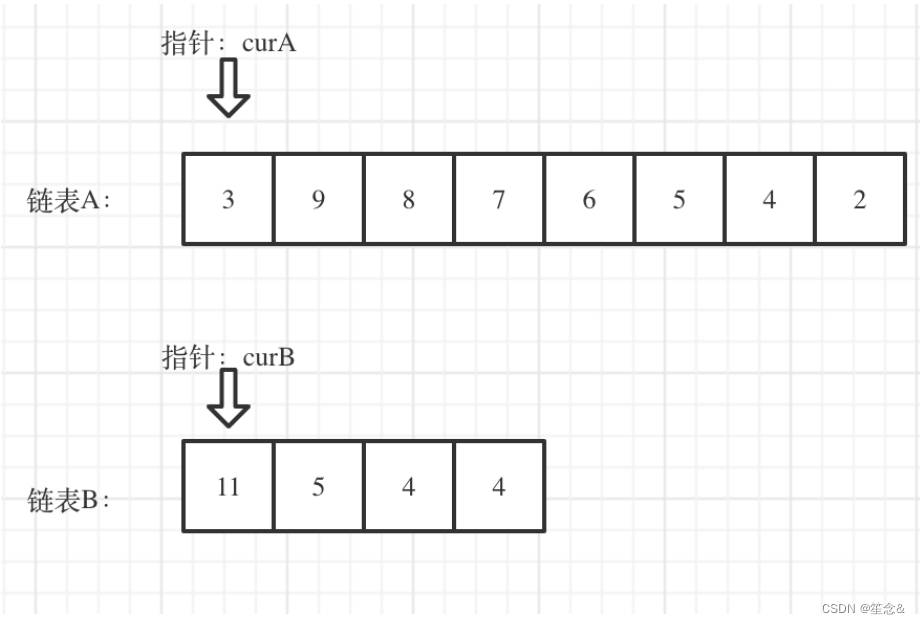
看如下两个链表,目前curA指向链表A的头结点,curB指向链表B的头结点:
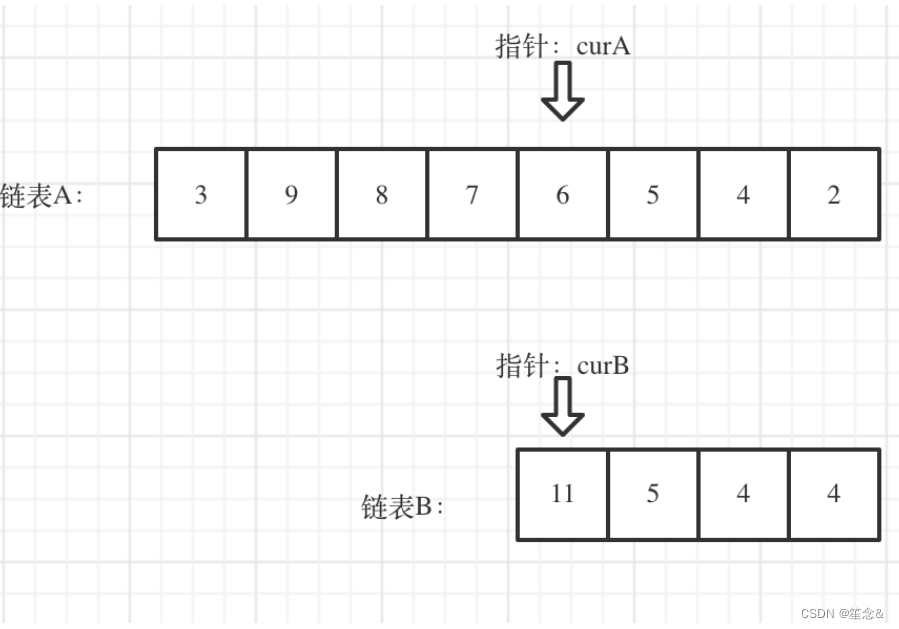
我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置,如图:
此时我们就可以比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到交点。
否则循环退出返回空指针。
解法
代码
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *l = NULL, *s = NULL;
int lenA = 0, lenB = 0, gap = 0;
// 求出两个链表的长度
s = headA;
while (s) {
lenA ++;
s = s->next;
}
s = headB;
while (s) {
lenB ++;
s = s->next;
}
// 求出两个链表长度差
if (lenA > lenB) {
l = headA, s = headB;
gap = lenA - lenB;
} else {
l = headB, s = headA;
gap = lenB - lenA;
}
// 尾部对齐
while (gap--) l = l->next;
// 移动,并检查是否有相同的元素
while (l) {
if (l == s) return l;
l = l->next, s = s->next;
}
return NULL;
}4)环形链表
题目描述
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
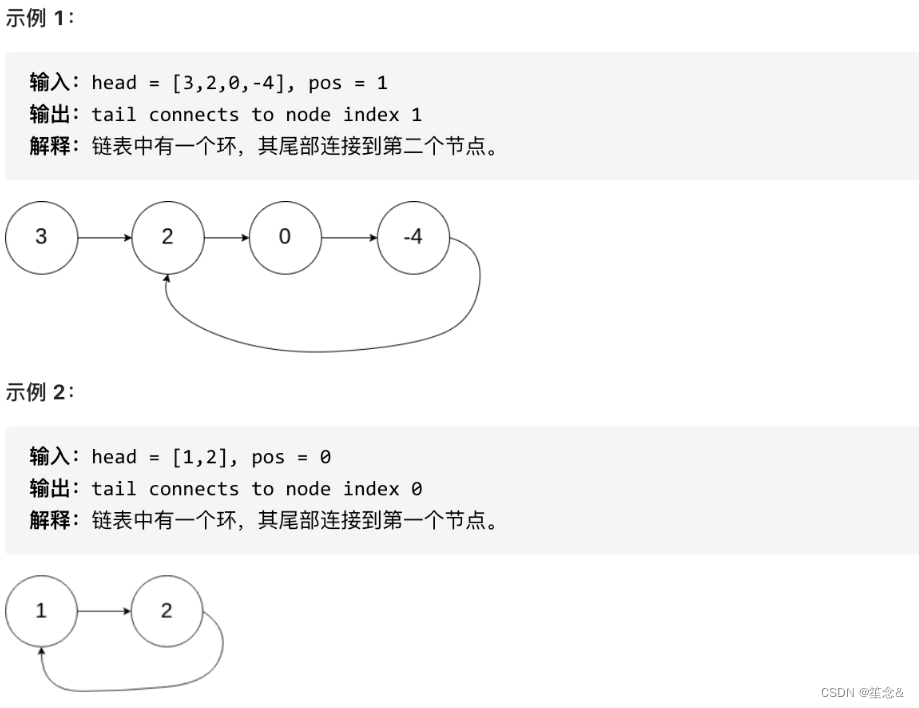
思路
主要考察两知识点:
- 判断链表是否环
- 如果有环,如何找到这个环的入口
1)判断链表是否有环
可以使用快慢指针法,分别定义 fast 和 slow 指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢
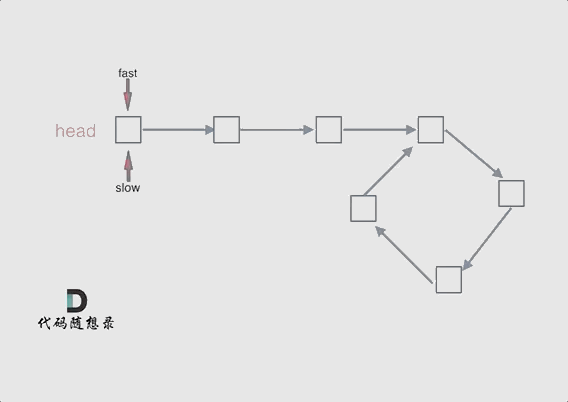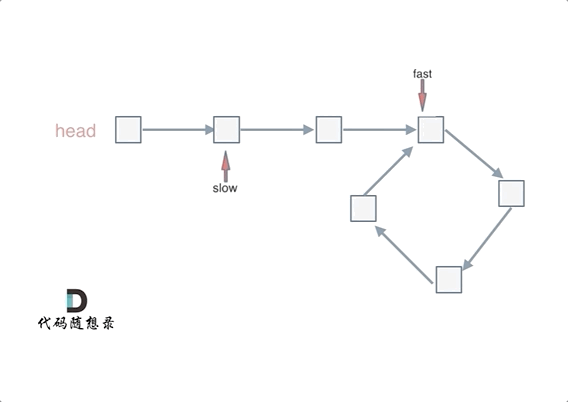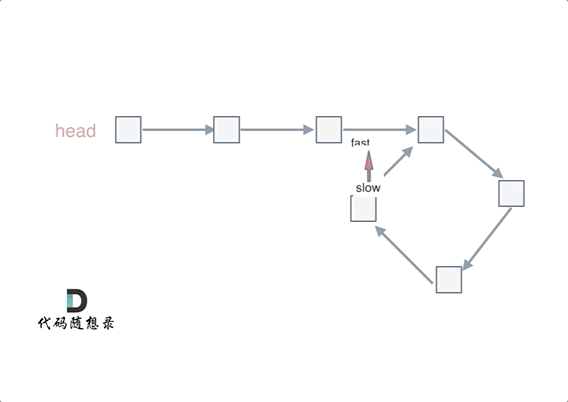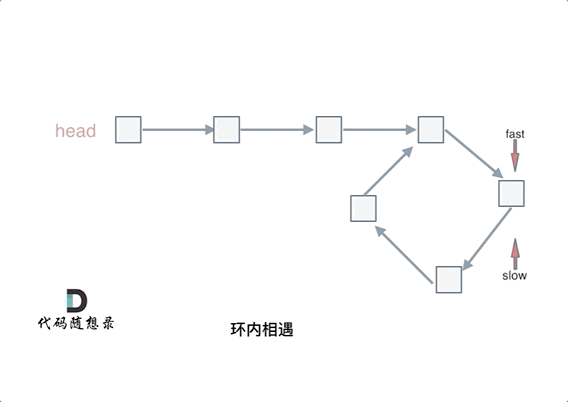
首先第一点:fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
那么来看一下,为什么fast指针和slow指针一定会相遇呢?
可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
会发现最终都是这种情况, 如下图:
fast和slow各自再走一步, fast和slow就相遇了
这是因为fast是走两步,slow是走一步,其实相对于slow来说,fast是一个节点一个节点的靠近slow的,所以fast一定可以和slow重合。
2)如果有环,如何找到这个环的入口
此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。
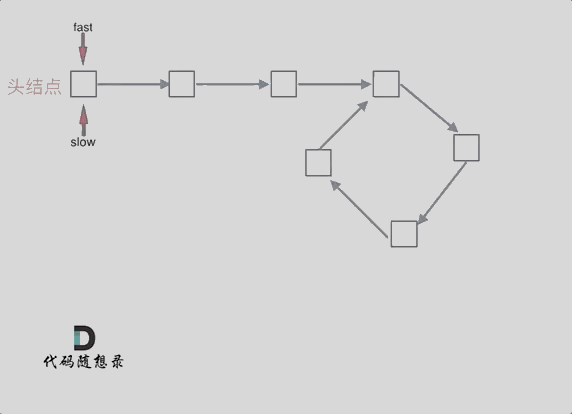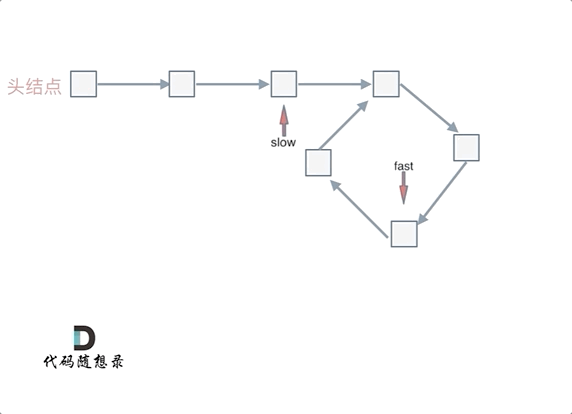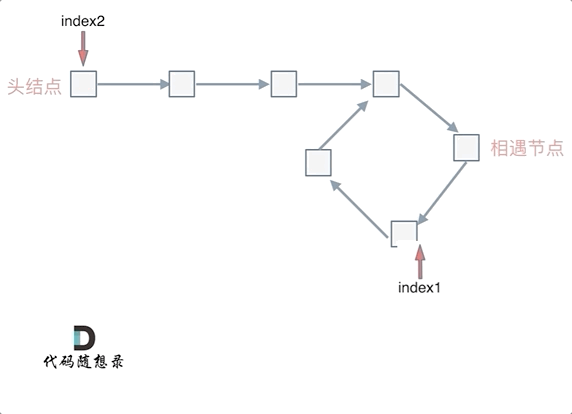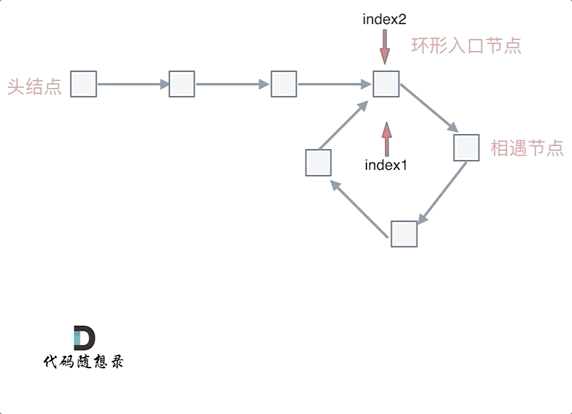
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。 如图所示:
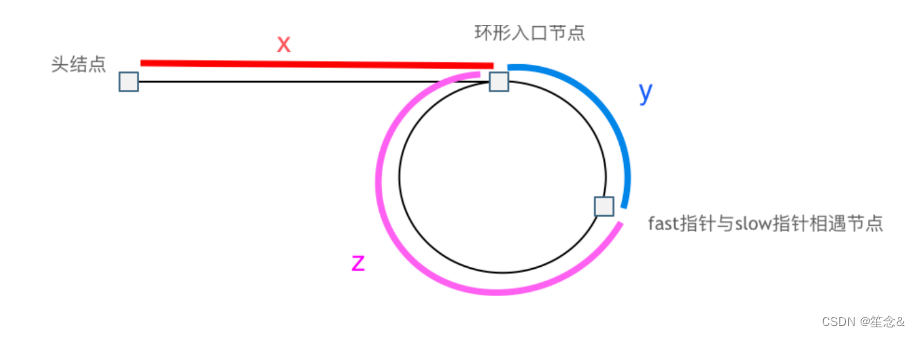
那么相遇时: slow指针走过的节点数为: x + y, fast指针走过的节点数:x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
(x + y) * 2 = x + y + n (y + z)
两边消掉一个(x+y): x + y = n (y + z)
因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:x = n (y + z) - y ,
再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:x = (n - 1) (y + z) + z 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 x = z,
这就意味着,从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
让index1和index2同时移动,每次移动一个节点, 那么他们相遇的地方就是 环形入口的节点。
动画如下:
那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
解法
代码如下:
ListNode *detectCycle(ListNode *head) {
ListNode *fast = head, *slow = head;
while (fast && fast->next) {
// 这里判断两个指针是否相等,所以移位操作放在前面
slow = slow->next;
fast = fast->next->next;
if (slow == fast) { // 相交,开始找环形入口:分别从头部和从交点出发,找到相遇的点就是环形入口
ListNode *f = fast, *h = head;
while (f != h) f = f->next, h = h->next;
return h;
}
}
return NULL;
}总结:判断链表中是否含有环
在单链表中,每个节点只知道下一个节点,用一个指针能否判断链表中是否含有环?
如果链表中不含环,那么这个指针最终会遇到空指针 null,表示链表到头,可以判断该链表不含环。
但是如果链表中含有环,那么这个指针就会陷入死循环,因为环形数组中没有 null指针作为尾部节点。
经典解法是用两个指针,一个跑得快,一个跑得慢。
如果不含有环,跑得快的指针最终会遇到 null 指针,说明链表不含环;如果含有环,快指针最终会超慢指针一圈,和慢指针相遇,说明链表含有环。






![[内网渗透]—域外向域内信息收集、密码喷洒](https://img-blog.csdnimg.cn/dee6b448bb6e454ba2a11a87f157fe0c.png#pic_center)
![[附源码]Python计算机毕业设计红色景点自驾游网站管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/32de4af982d742559a8beebfd596b008.png)
![[附源码]Node.js计算机毕业设计古诗词知识学习系统Express](https://img-blog.csdnimg.cn/58977486e3f348c1bbcbe5aa21d19081.png)