import os
import copy
import time
import torch
import torch.nn as nn
import torch.optim as optin
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torchvision.models as models
from utils.data.custom_finetune_dataset import customFinetuneDataset
from utils.data.custom_batch_sampler import CustomBatchSampler
from utils.util import check_dir
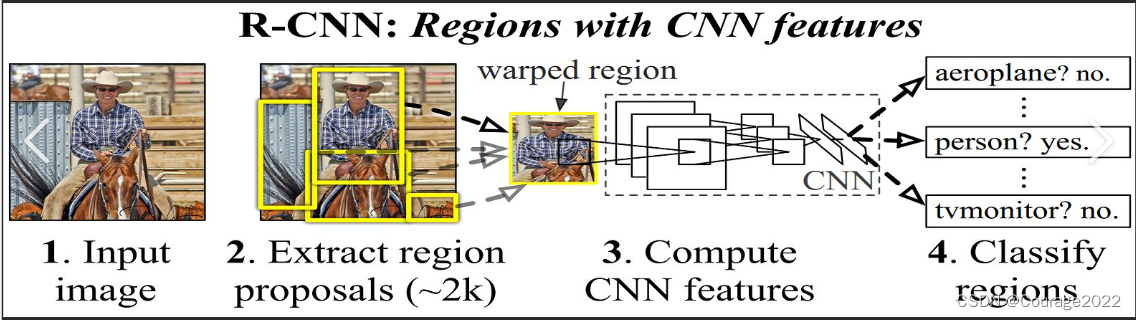
在torchvision.models里面存放了Alexnet的模型。
2.主函数
from image_handler import show_images
impont numpy as np
if __name__ == ' __main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
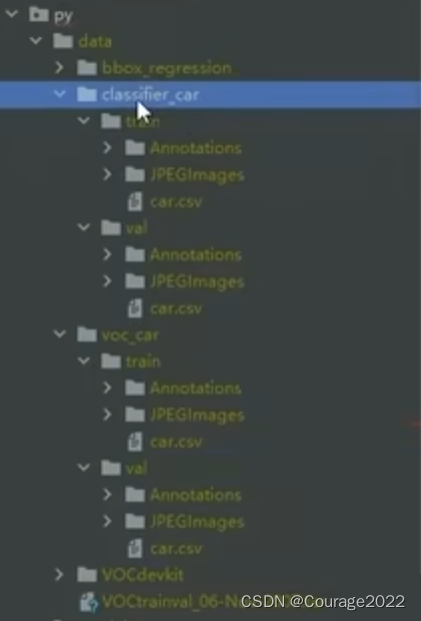
data_loaders,data_sizes = load_data('./data/classifier_car')
#加载alexnet神经网洛
model = models.alexnet(pretraine = True)
print(model)
data_loader = data_loaders["train"]
print("一次迭代取得所有的正负数据,如果是多个类则取得多类数据集合")
"""
index: 323 inage_id: 200 target: 1 image.shape: (254,342,3)[xmin,ymin,xnax,ymax]: [80,39,422,293]
"""
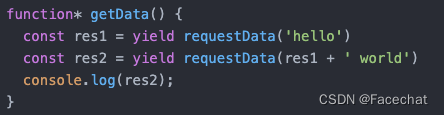
inputs,targets = next(data_loader.__iter__())
print(inputs[0].size(),type(inputs[0]))
trans = transforms.ToPILImage()
print(type(trans(inputs[0])))
print(targets)
print(inputs.shape)
titles = ["TRUE" if i.item() else "False" for i in targets[0:60]]
images = [np.array(trans(i))for i in inputs[0:60]]
show_images(images,titles=titles,num_cols=12)
#
#把alexnet变成二分类模型,在最后一行改为2分类。
num_features = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_features,2)
print("记alexnet变成二分类模型,在最后一行改为2分类",model)
model = model.to(device)
criterion = nn.CrossEntroyLoss()
optimizer = optim.SGD(model.parameters(),lr=1e-3, momentum=0.9)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=7,gamma=0.1)
best_model = train_model(data_loaders,model,criterion,optimizer,lr_scheduler,device=device
num_epachs=10)
check_dir('./models')
torch.save(best_model.state_dict(),'models/alexnet_car.pth ')
更好的阅读体验
Project 2: CS 61A Autocorrected Typing Software cats.zip Programmers dream of Abstraction, recursion, and Typing really fast. Introduction Important submission note: For full credit: Submit with Phase 1 complete by Thursday, February 17, wo…
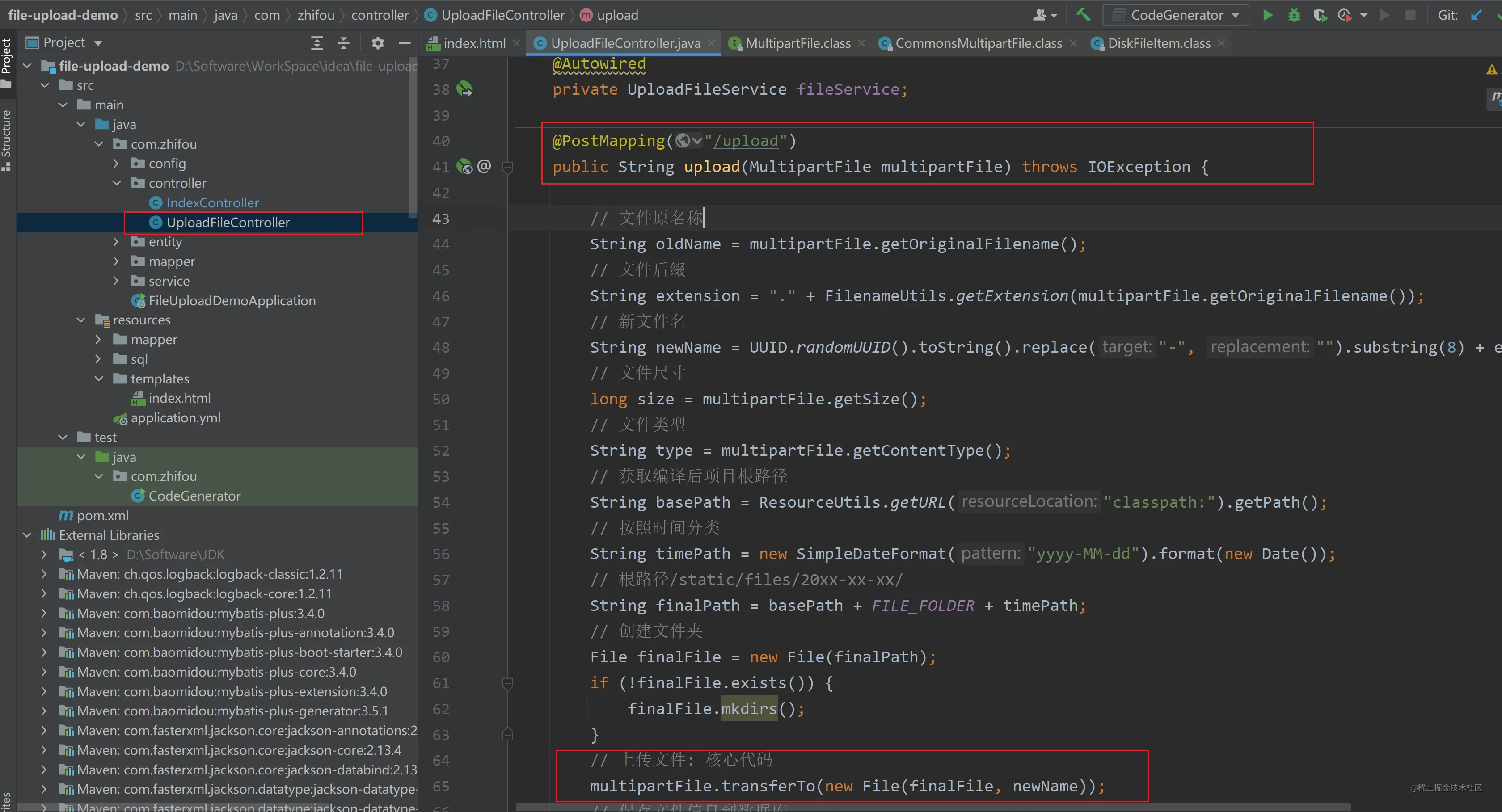
2.技术栈mavenspringbootmybatis-plusmysqlthymeleafbootstrap3.数据库表 CREATE TABLE t_upload_file (id bigint(11) NOT NULL AUTO_INCREMENT,old_name varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,new_Name varchar(100) CHARACTER SET utf8 CO…





![[内网渗透]—域外向域内信息收集、密码喷洒](https://img-blog.csdnimg.cn/dee6b448bb6e454ba2a11a87f157fe0c.png#pic_center)
![[附源码]Python计算机毕业设计红色景点自驾游网站管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/32de4af982d742559a8beebfd596b008.png)
![[附源码]Node.js计算机毕业设计古诗词知识学习系统Express](https://img-blog.csdnimg.cn/58977486e3f348c1bbcbe5aa21d19081.png)