文章目录
- 一、前言
- 二、Druid相关内容
- 1、Druid简介
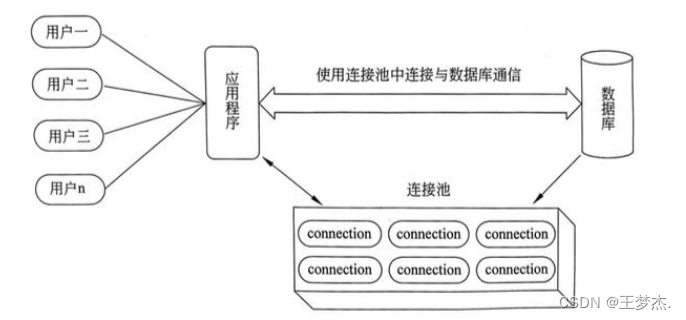
- 1.1数据库连接池
- 2、项目集成Druid
- 2.1、环境准备
- 2.2、依赖准备
- 2.3、编写配置文件
- 2.4、测试访问
- 3、功能介绍
- 3.1、查看数据源
- 3.2、SQL监控
- 3.3、URI监控
- 三、总结提升
一、前言
本文将介绍Druid的相关内容以及项目如何集成Druid,请多多指教。
二、Druid相关内容
1、Druid简介
Druid是阿里开源的一个数据库连接池的解决方案。它本身还自带一个监控平台,可以查看时时产生的sql、uri等监控数据,可以排查慢sql、慢请求,方便对sql和项目代码进行调优。
1.1数据库连接池
数据库连接池是一种用于管理和复用数据库连接的技术。在应用程序与数据库之间建立连接是一项开销较大的操作,而连接池的目标是通过预先建立一组数据库连接,然后在应用程序需要时分配和复用这些连接,以减少连接建立和断开的开销,提高数据库访问的效率和性能。
2、项目集成Druid
2.1、环境准备
父项目是一个springboot工程
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.12.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
- MySQL版本:5.7
- springboot版本:2.3.12.RELEASE
2.2、依赖准备
引入Druid的依赖:
<!--druid依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
引入log4j
<!-- 引入log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2.3、编写配置文件
spring:
application:
name: user-demo
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mengjie
username: root
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
#druid数据源配置
druid:
# 初始化连接池大小
initialSize: 5
# 最小连接数
minIdle: 5
# 最大连接数
maxActive: 40
# 获取连接时的最大等待时间
maxWait: 60000
#间隔多长时间进行一次检测;
timeBetweenEvictionRunsMillis: 60000
#配置一个最小的生存对象的空闲时间
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1
testWhileIdle: true
#申请连接时执行validationQuery检测连接是否有效,默认true,开启后会降低性能
testOnBorrow: false
#归还连接时执行validationQuery检测连接是否有效,默认false,开启后会降低性能
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters。stat:监控统计、wall:防御sql注入、log4j:日志记录
filters: stat,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
#执行时间超过3000毫秒的sql会被标记为慢sql
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=3000
#配置过滤器,过滤掉静态文件
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: /druid/*,*.js,*.css,*.gif,*.jpg,*.bmp,*.png,*.ico
#配置可视化控制台页面
stat-view-servlet:
filter:
stat:
merge-sql: false
enabled: true
#访问德鲁伊监控页面的地址
url-pattern: /druid/*
#IP白名单 没有配置或者为空 则允许所有访问
#allow: xxx.xxx.xxx
#IP黑名单 若白名单也存在 则优先使用
#deny: ip地址
#禁用重置按钮
reset-enable: true
#登录所用的用户名与密码
login-username: admin
login-password: 123456
2.4、测试访问
访问:http://localhost:9010/druid
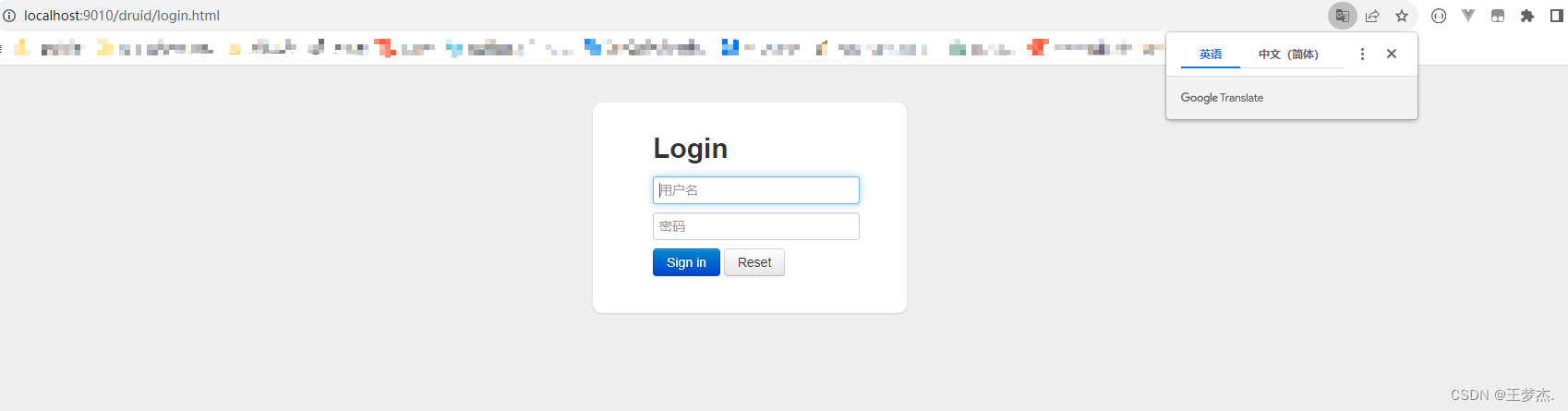
注意:博主这里的context-path为空,如果这里有值的话,那我们就需要在http://localhost:9010/druid端口的后面添加上context-path的值:http://localhost:9010/xxx/druid
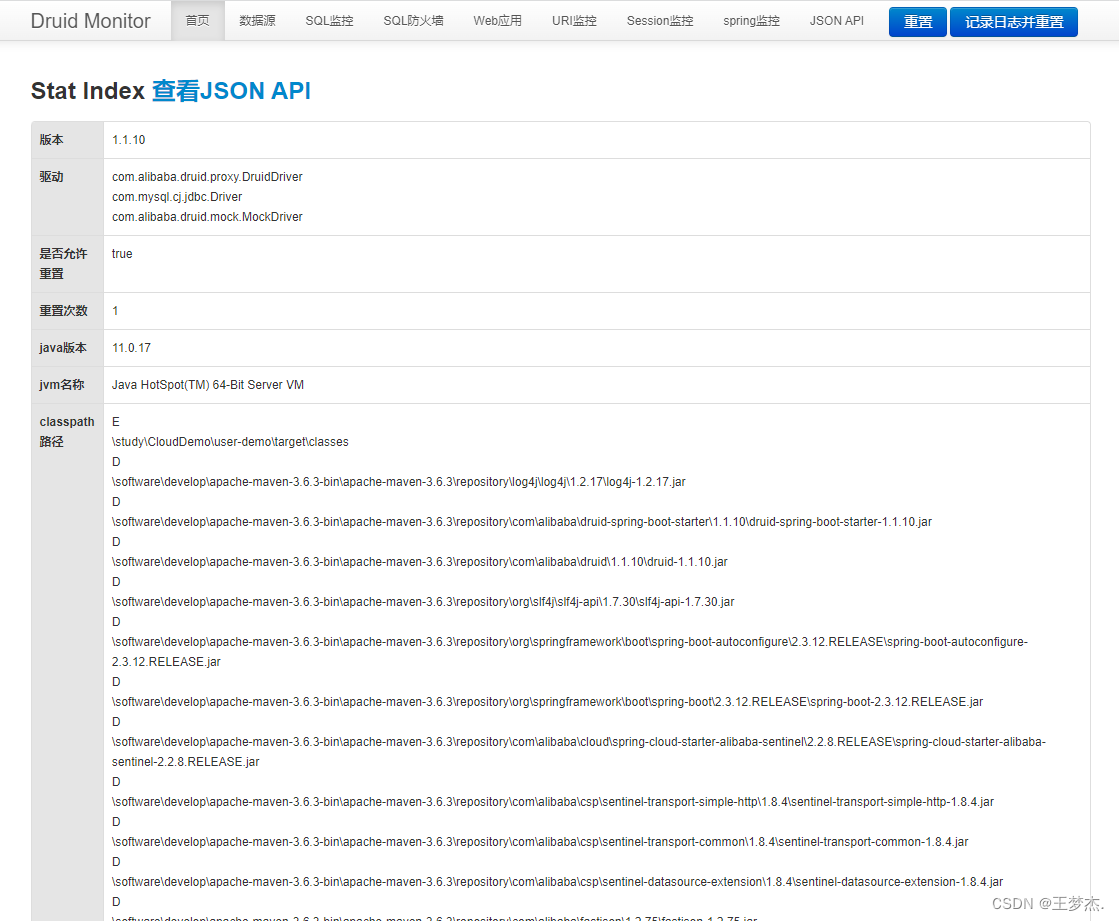
账号和密码都在配置文件中可以进行配置,输入账号密码进行登录,登录成功;
3、功能介绍
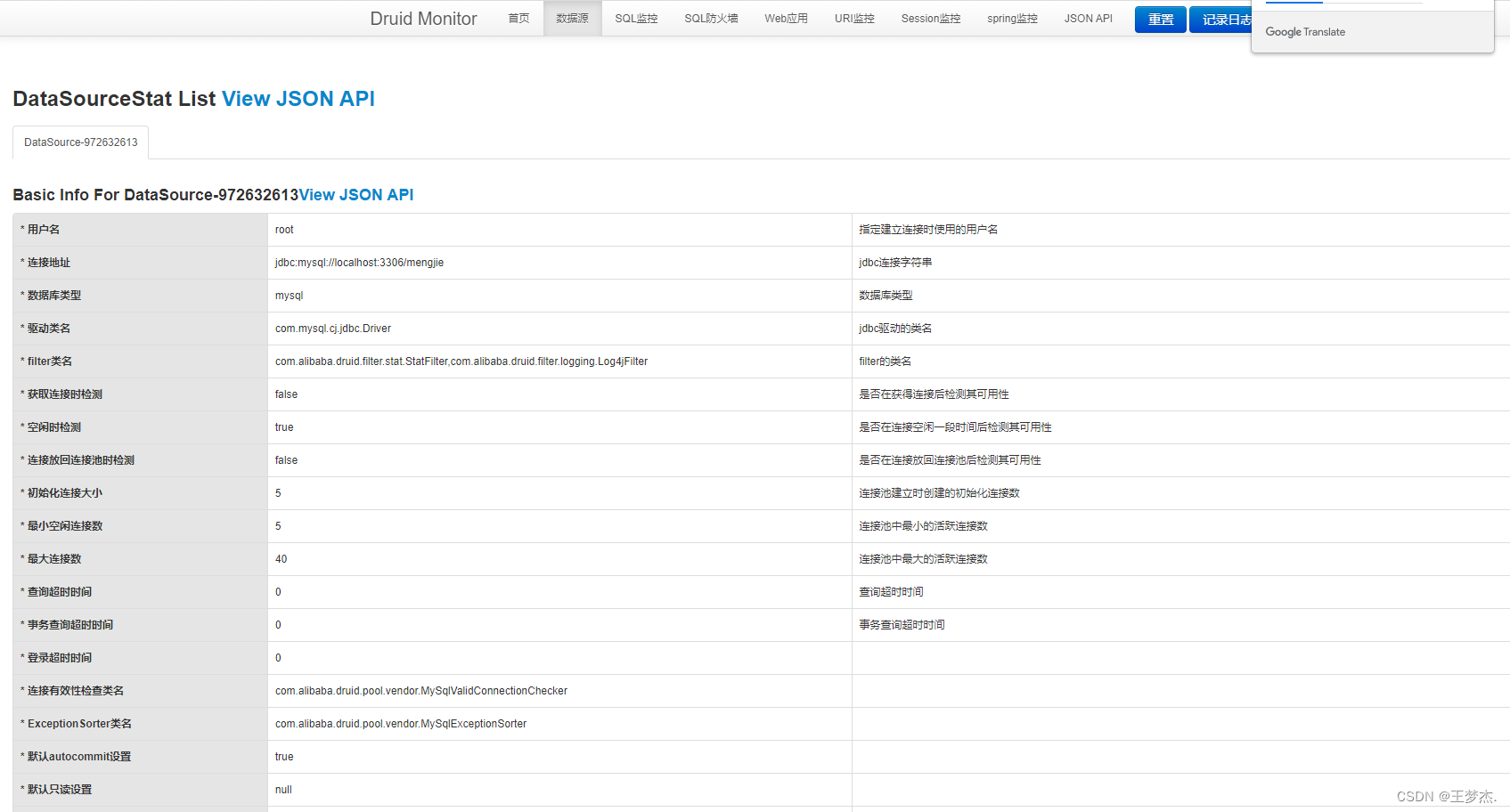
3.1、查看数据源
这里展示了当前项目数据源的全部详细信息;
3.2、SQL监控

以下是Druid的SQL监控功能的一些详细信息:
-
SQL查询支持:Druid的SQL监控功能提供了对标准SQL查询的支持,包括SELECT、FROM、WHERE、GROUP BY、ORDER BY等语句。这意味着用户可以使用通用的SQL查询来访问和分析Druid中的数据。
-
SQL解析器:Druid集成了一个SQL解析器,负责将接收到的SQL查询解析成Druid的查询语言,这使得Druid能够理解并执行SQL查询。
-
优化和执行:Druid的SQL监控功能不仅仅是一个简单的SQL解析器,它还包括了查询优化和执行的步骤,以确保查询在Druid集群上以高效的方式运行。这包括了查询计划的生成、数据片段的选择和并行执行等操作。
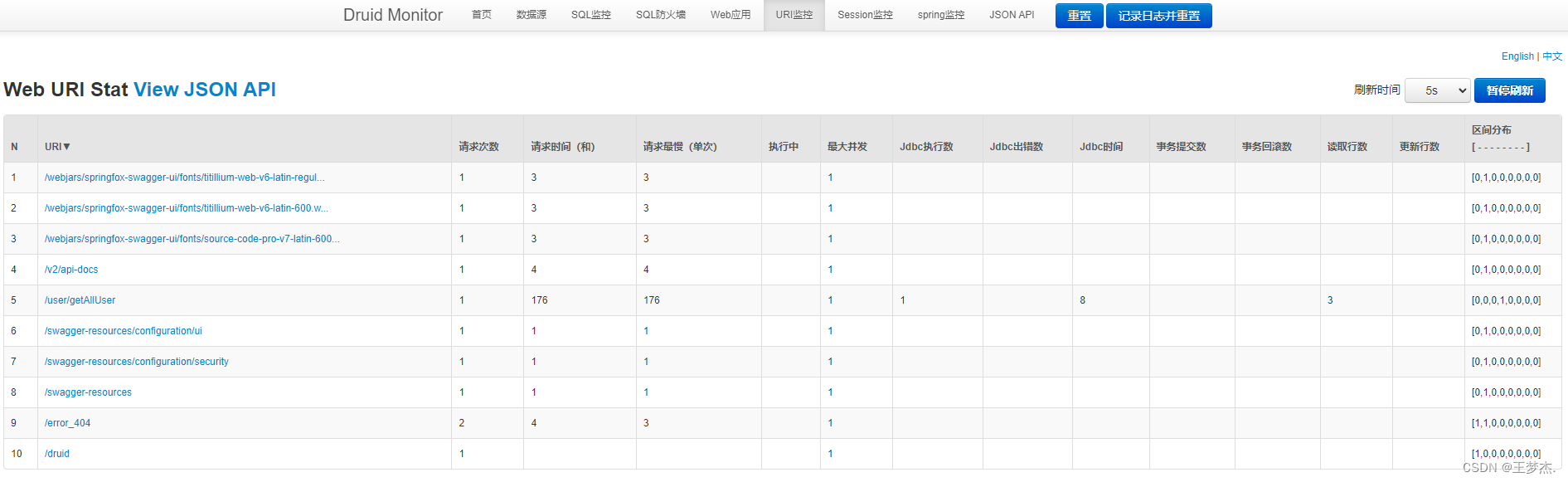
3.3、URI监控
druid也提供了自己的URI监控功能,有没有很熟悉,是不是好像在哪见到过,没错,之前介绍Sentinel的时候,sentinel就有URI监控的页面;
三、总结提升
Druid的SQL监控功能使得用户能够使用标准SQL语法来访问和分析存储在Druid集群中的实时数据,为数据分析提供了更大的灵活性和便利性。这个功能使得Druid成为了一个强大的实时数据存储和分析引擎,适用于各种大数据应用场景。
如果本篇博客对您有一定的帮助,大家记得留言+点赞+收藏哦。