Kerberos,在古希腊神话故事中,指的是一只三头犬守护在地狱之门外,禁止任何人类闯入地狱之中。
那么在现实中,Kerberos指的是什么呢?
一、Kerberos介绍
01 Kerberos是什么
根据百度词条释义,Kerberos是一种计算机网络授权协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。Kerberos旨在通过密钥加密技术为客户端/服务器应用程序提供身份验证,主要用在域环境下的身份验证。
在此之前,通常只有服务器的运维管理人员在配置Active Directory之类的东西时才会接触到Kerberos,但随着大数据的流行,整个Hadoop生态圈在安全方面对于Kerberos愈发依赖,同时由于Kerberos认证必须入侵式改造代码的特点,使得越来越多的大数据开发同学开始接触到Kerberos。
02 Kerberos 解决了什么问题
目前用于身份密码的验证主要面临两个问题:首先是人工记忆的密码混乱且易遗忘,一些比较简单的密码又容易被攻击;其次是技术错觉,在计算机上的输入密码时显示的是一串星号,大家误以为很安全,实际上计算机通过网络发送密码基本是发送“明文”密码,大部分密码都处于“裸奔”状态。
Kerberos的出现很好的解决了这个问题,它减少了每个用户使用整个网络时必须记住的密码数量——只需记住 Kerberos 密码,同时Kerberos结合了加密和消息完整性来确保敏感的身份验证数据不会在网络上透明地发送。通过提供安全的身份验证机制,Kerberos为最终用户和管理员提供了明显的好处。
03 Kerberos 基本概念
principal 是Kerberos 世界的用户名,用于标识身份,每个用户都会有一个 principal,如果 principal 失效或者不正确,那么这个用户将无法访问任何资源。principal 主要由三部分构成:primary,instance(可选) 和 realm。

● primary
主体,每个 principal 都会有的组成部分,代表用户名(username)或服务名(service name)。
● instance
用于服务主体以及用来创建用于管理的特殊主体。instance 用于服务主体时的一般会用于区分同一服务在不同服务器上的服务实例,因此与 primary 组成的 principal 一般用于 server 端,如:NameNode,HiverServer2,Presto Coordinator等。
instance 用来创建用于管理的特殊主体时,一般来区分同一个用户的不同身份,如区分担任管理员角色的 a 用户与担任研发的 a 用户。
● realm
realm 是认证管理域名,用来创建认证的边界,只有在同属于一个认证服务的边界内,这个认证服务才有权利认证一个用户、主机或者服务。每个域都会有一个与之对应的 kdc 服务用于提供域内的所有服务的认证服务。
● keytab
"密码本",包含了多个 principal 与密码的文件,用户可以利用该文件进行身份认证。
● ticket cache
客户端与 KDC 交互完成后,包含身份认证信息的文件,短期有效,需要不断renew。

04 Kerberos 的认证简介
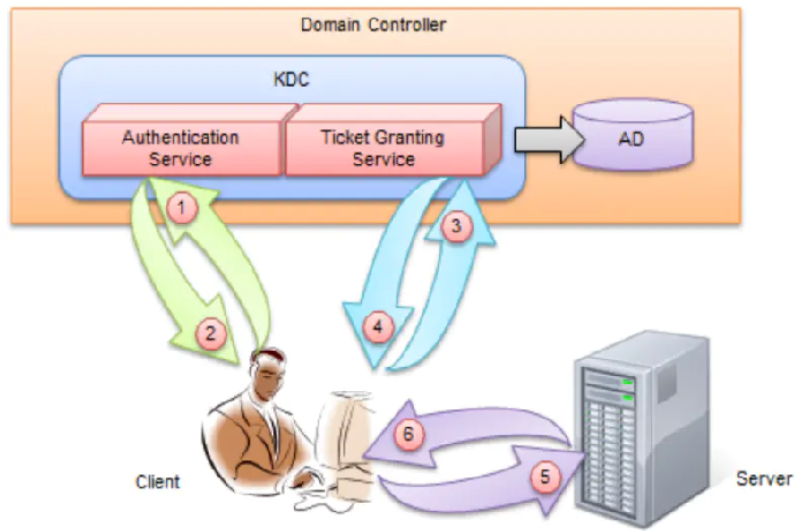
参与 Kerberos 认证过程中的角色:
- 访问服务的 Client;
- 提供服务的 Server;
- DC是Domain Controller的缩写,即域控制器;AD是Active Directory的缩写,即活动目录。DC中有一个特殊用户叫做krbtgt,它是一个无法登录的账户,是在创建域时系统自动创建的,在整个Kerberos认证中会多次用到它的Hash值去做验证。
- KDC(Key Distribution Center)密钥分发中心。在KDC中又分为两个部分:Authentication Service(AS,身份验证服务)和Ticket Granting Service(TGS)
- AD会维护一个Account Database(账户数据库), 它存储了域中所有用户的密码Hash和白名单,只有账户密码都在白名单中的Client才能申请到TGT。
05 Kerberos详细认证流程
1. Client with AS
客户端(Client)向 AS(Authentication Service)发送请求获取 TGT(ticket grant ticket)
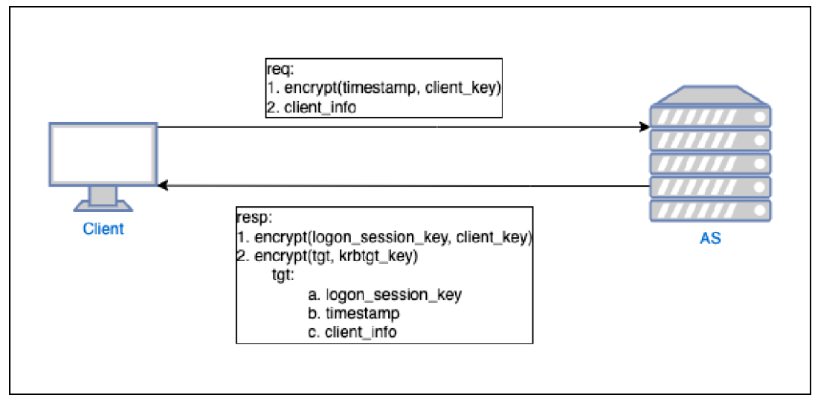
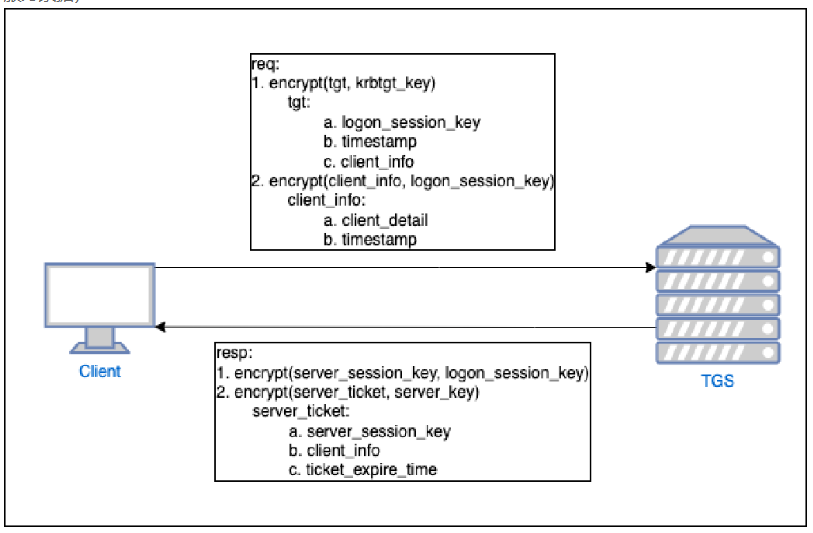
2. Client with TGS
客户端(Client)向 TGS(Ticket Granting Service,)发送请求获取ST(Service Ticke)
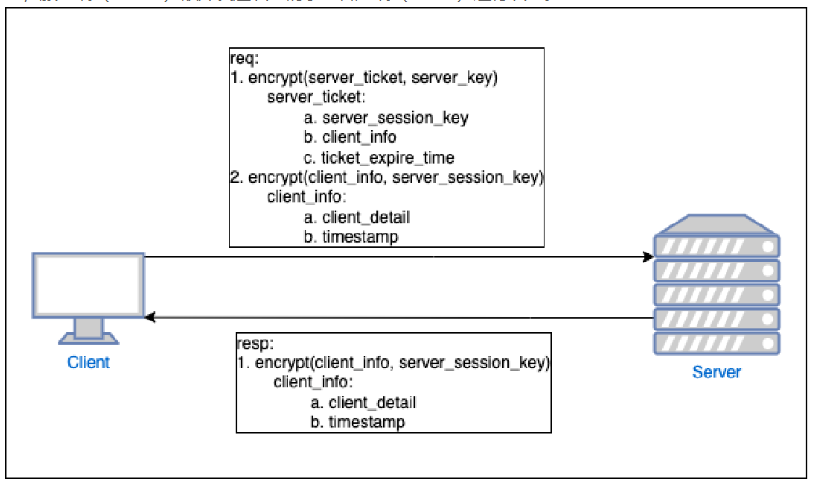
客户端(Client)向服务端(Server)发送认证请求进行认证,如果客户端(Client)要求进行双向认证,服务端(Server)额外发送认证请求至客户端(Client)进行认证。
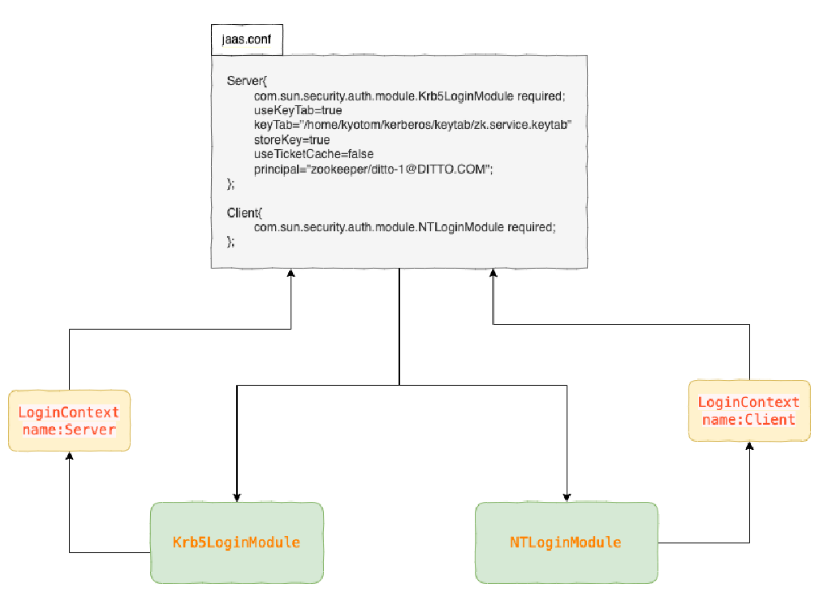
3.Kerberos 与 JAAS可插拔的认证模块
JAAS jdk 在1.4引入的一种可插拔的认证模块( Pluggable Authentication Module,PAM )的安全体系结构,这意味着可以通过改变模块,支持从一种安全协议组件无缝的切换到另一个协议组件。
同时这种体系架构定义的接口无需修改代码即可实现加入多种认证技术和授权机制,因为 JAAS API 定义了应用程序代码与实际验证逻辑之间的抽象,这个抽象不用重新编译现有的应用程序代码就可以作为登录模块的运行时替代。
这种实现方式是通过应用程序只调用 LoginContext 接口,而认证技术的实际提供程序则是基于 LoginModule 接口进行开发的,在运行时LoginContext 通过读取配置文件确定使用哪些认证模块来对应用程序进行认证。
二、ChunJun任务提交中的Kerberos认证
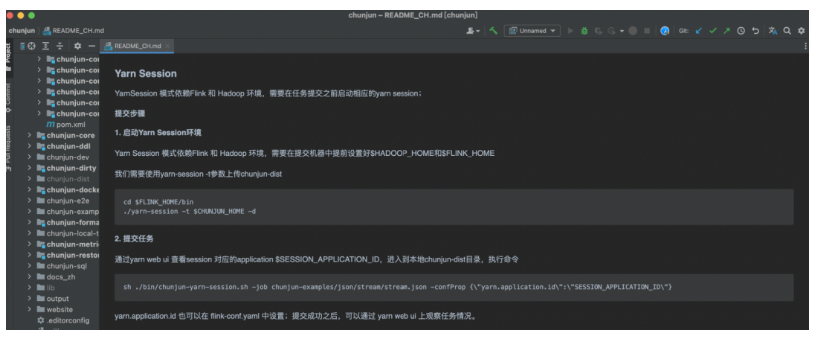
接下来我们来大家介绍下ChunJun任务提交中的 Kerberos 认证,我们可以参考ChunJun的 readme 文档中的 yarn session 部分:
https://github.com/DTStack/chunjun/blob/master/README_CH.md
01 Flink 提交流程中的 Kerberos
首先,我们需要启动一个 yarn session 环境,进入 Flink 的 bin 目录下执行 yarn-session 脚本启动 flink session 并使用 -t 参数上传 ChunJun 的依赖包。

当我们执行 yarn-session 时,脚本内部会调用 java 命令运行 FlinkYarnSessionCli 这个类的 main 方法。在 FlinkYarnSessionCli 的 main 方法中,首先需要安装一个全过程的安全配置,然后获得一个安装后的上下文,并且在上下文中运行 run 方法。
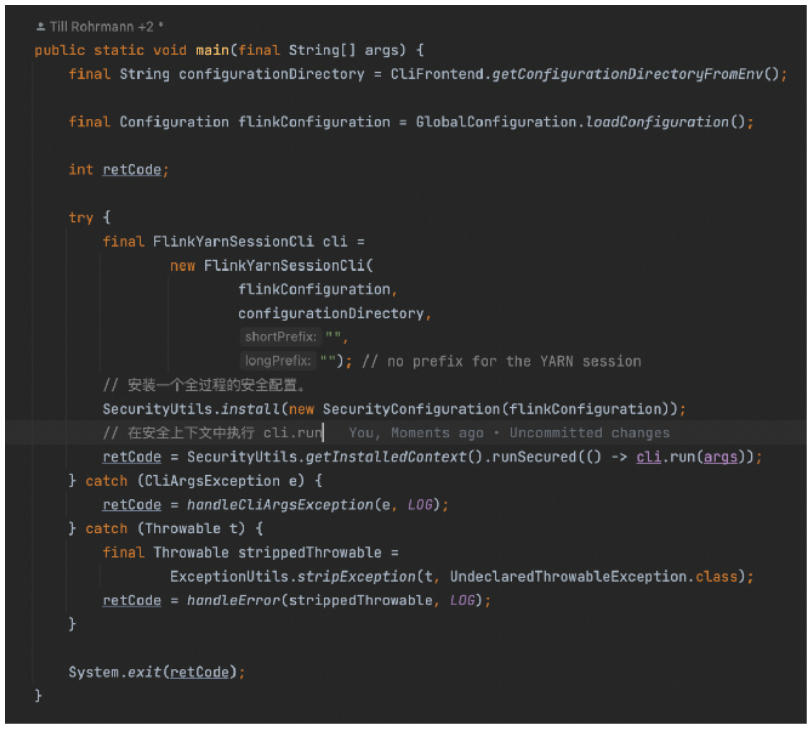
在 run 方法中我们构建了一个 YarnClusterDescripter 对象,这个对象中封装了 Flink 所依赖的配置文件和 jar 包等。而后再调用YarnClusterDescripter 对象的 DeploySessionClister 方法将任务提交到 yarn 集群。至此完成了 Flink session 到 Yarn 的一个提交。
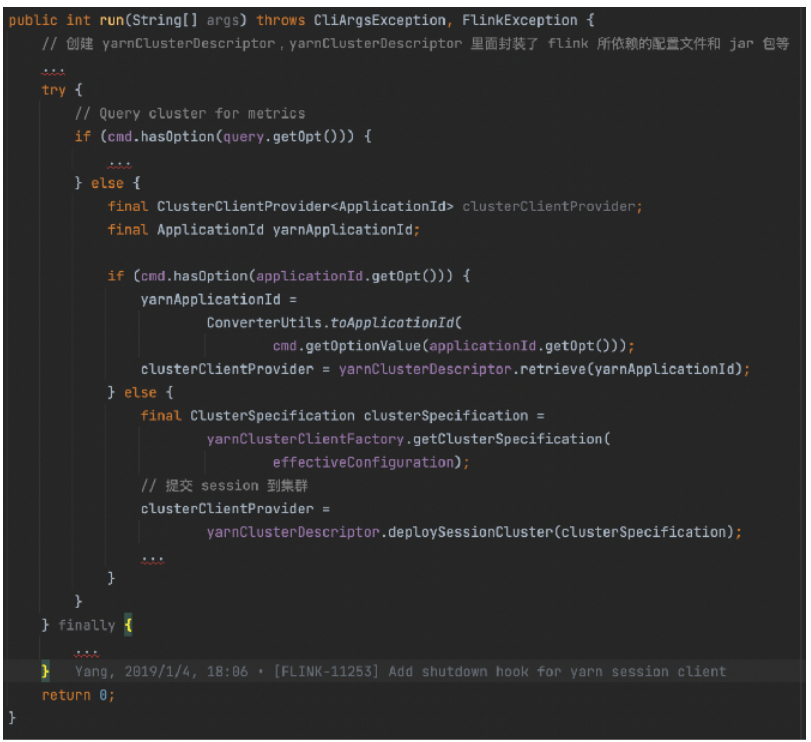
我们再回顾下整体的提交流程:
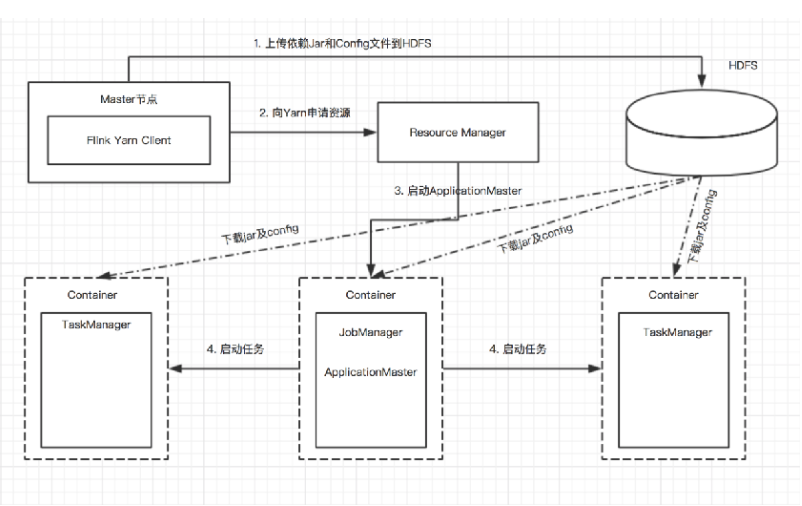
● Flink => HDFS
Flink 需要将配置文件以及 session 所依赖的 jar 上传至 HDFS,因此需要与 HDFS 进行通信
● Flink => Yarn
Flink 需要向 Yarn 申请资源,因此需要与 Yarn 进行通信
●Flink => Zookeeper
如果 Flink 配置了基于 zookeeper 的高可用,那么 JobManager 需要在 Zookeeper 注册 leader 节点,客户端还需要从 Zookeeper 上的 leader 节点获取 webMonitorUrl,因此需要与 Zookeeper 通信
02 Flink SecurityUtils作用于 Kerberos 认证
1.SecurityUtils.java
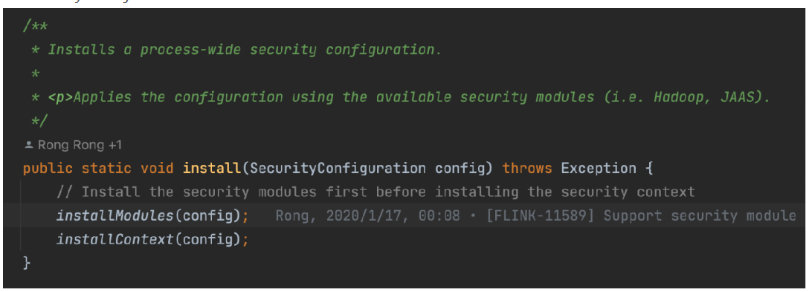
2.SecurityUtils#install 方法中首先通过 installModules 方法对 Flink 内部的安全模组进行了 install(其中包括Hadoop、Jaas、Zookeeper 模组)
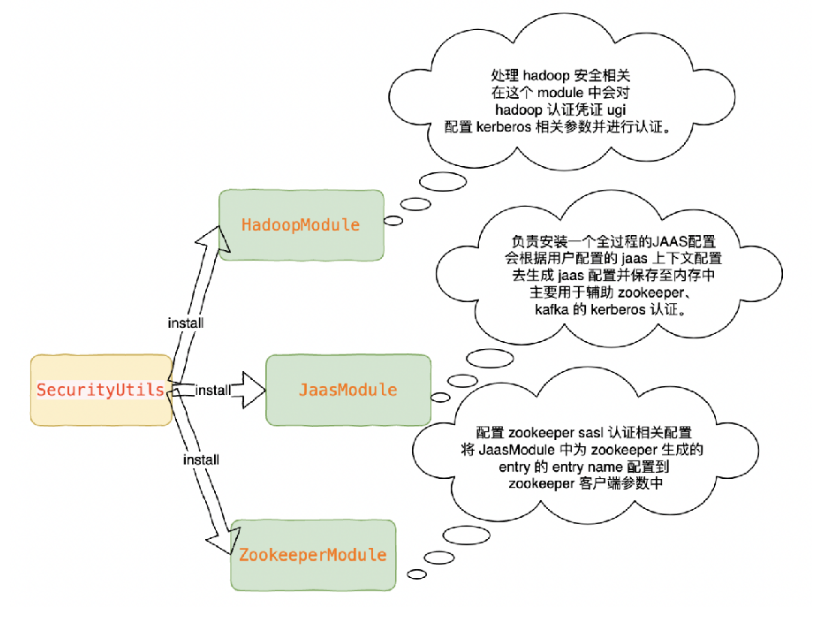
3.SecurityUtils#installContext 方法对安全上下文进行初始化(获得 HadoopSecurityContext,其中包含这 hadoop 的认证凭证 ugi)

03 Flink Hadoop Kerberos 认证
$Flink_HOME/conf/Flink-conf.yaml
security.Kerberos.login.use-ticket-cache: 是否从你的Kerberos ticket缓存中读取
security.Kerberos.login.keytab: 包含用户凭证的Kerberos keytab文件的绝对路径。
security.Kerberos.login.principal: 与keytab相关的Kerberos principal名称。
security.Kerberos.krb5-conf.path:指定 krb5.conf 文件的本地位置。如果定义了,这个conf将被挂载到Kubernetes、Yarn和Mesos的JobManager和TaskManager容器/桶上。注意: 需要在容器内部可访问到定义的 KDC 的地址。
security.Kerberos.login.contexts: 用逗号分隔的登录上下文列表,以提供Kerberos凭证(例如,Client,KafkaClient用于ZooKeeper认证和Kafka认证的凭证)。
zookeeper.sasl.service-name: 默认为 "zookeeper"。如果ZooKeeper quorum配置了一个不同的服务名称,那么可以在这里提供。
zookeeper.sasl.login-context-name: 默认为 "Client"。该值需要与 "security.Kerberos.login.contexts"中配置的值之一相匹配。
04 ChunJun 提交流程中的 Kerberos
执行 ChunJun-Yarn-session.sh 提交任务,ChunJun-Yarn-session.sh 实际上只是对任务的脚本路径进行了检查校验,然后再执行 submit.sh 脚本启动任务提交进程。
Launcher 的 main 方法中主要对不同的任务执行模式进行区分并交给各个模式具体的任务提交类去提交任务。
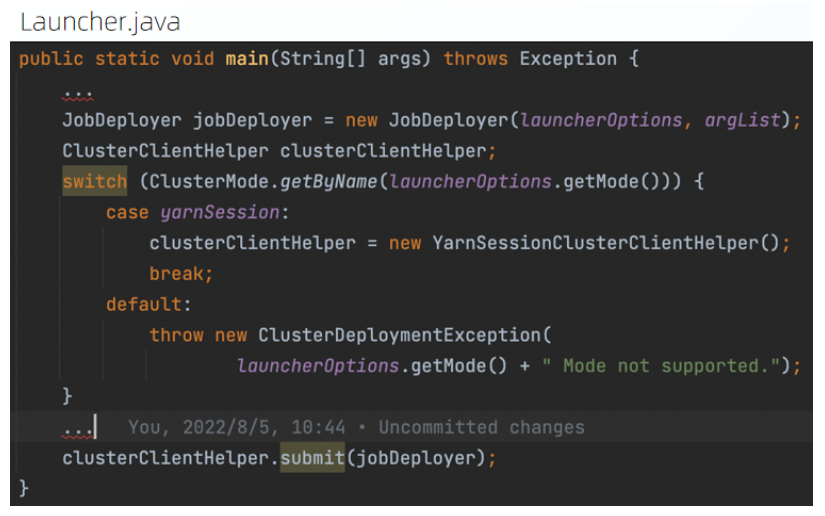
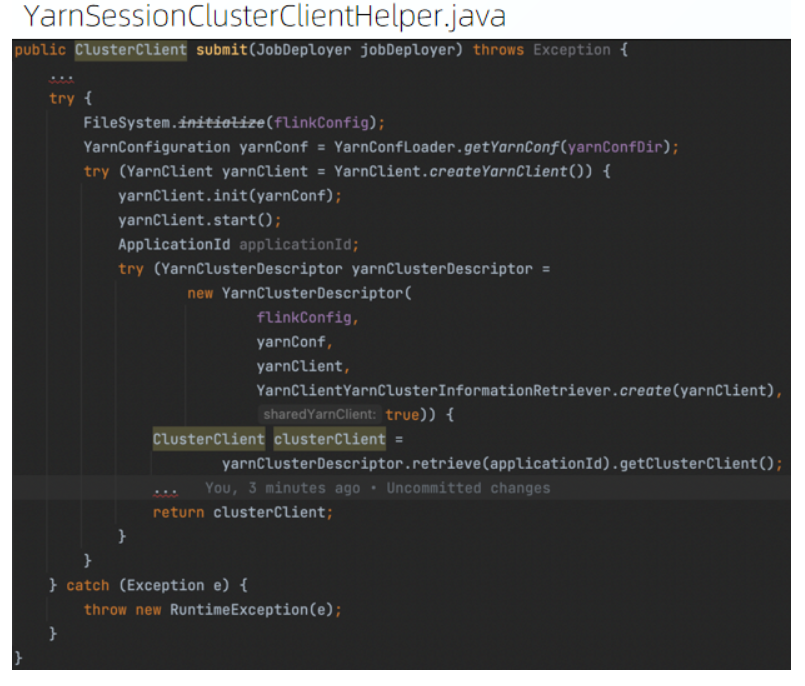
YarnSessionClusterClientHelper 将任务的配置以及依赖的 jar 进行组装获得 YarnClusterDescriptor 对象。再将任务提交到对应的 Flink session 上。
三、ChunJun Connector 中的Kerberos 认证
接下来为大家介绍 ChunJun Connector 中的 Kerberos 认证 。
01ChunJun 插件中的 Kerberos
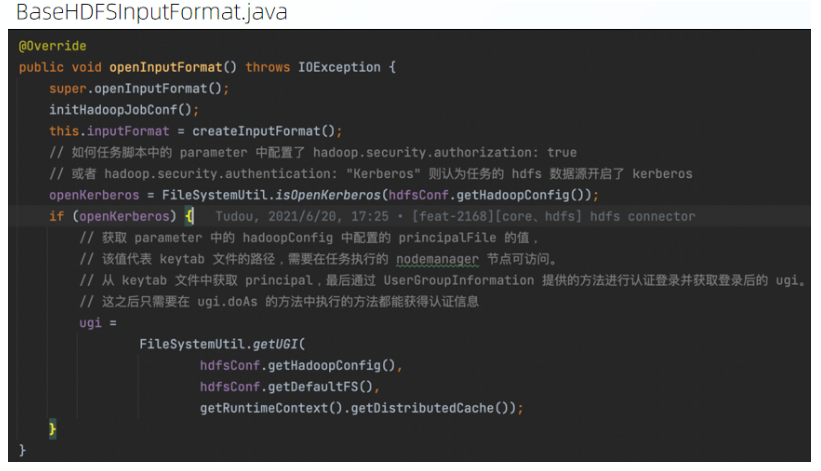
以 ChunJun HDFS Connector 为例:
插件在 openInputFormat 方法中会对任务的目标数据源 HDFS 是否开启了 Kerberos 进行判断,如果开启了 Kerberos,则会根据配置的认证文件进行认证并获取认证后的 ugi,ugi 可以认为是之后插件与 HDFS 通信的用户凭证,里面保存着用户的认证信息.
02 如何进行Kerberos 认证
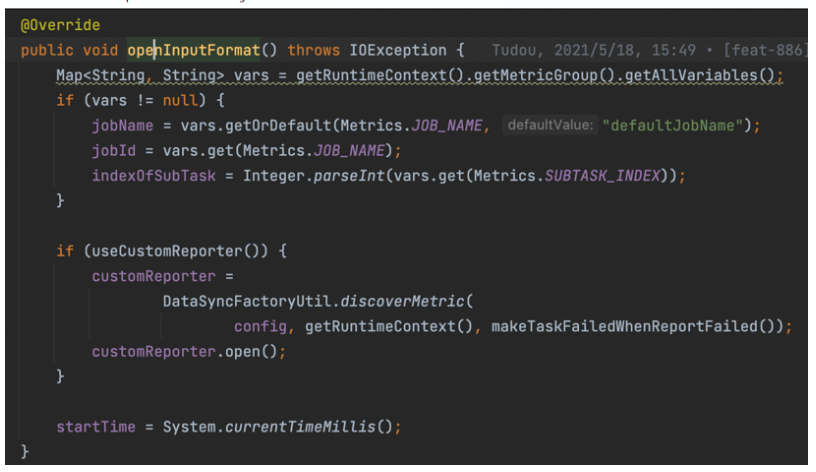
● OpenInputFormat 方法
OpenInputFormat 方法是 Flink 对算子的每个实例进行初始化是都会执行的方法,ChunJun 的BaseRichInputFormat 也实现了该方法,我们开发插件也都会去实现该方法。
对于每个算子实例来说,Kerberos 认证只会进行一次(不包括认证过期后的刷新),因此 Kerberos 认证的代码应该在该方法中实现.
● 开发 hadoop 生态中的数据源组件
一般而言,Hadoop 生态中的数据源组件如:HDFS、HBase、Hive 等都是用 ugi(UserGroupInformation) 进行 Kerberos 认证。
ChunJun 内部也提供了相关的工具类用于获取登录后的 ugi:com.dtstack.ChunJun.util.FileSystemUtil#getUGI
● 开发 Zookeeper、Kafka 等组件
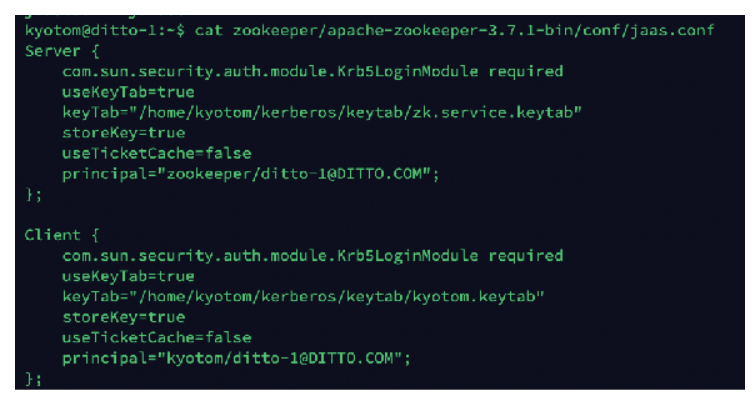
这类组件开启 Kerberos 认证后,用户需要在插件端配置 jaas.conf 文件,再通过各个组件提供的参数配置项配置组件所选用的 jaas.conf 的 entry,即可完成 Kerberos 配置。
03 如何排查 Kerberos 认证问题
$Flink_HOME/conf/Flink-conf.yaml
#jvm 启动参数中增加 “-Dsun.security.krb5.debug=true”
env.java.opts:用于配置启动所有Flink进程的JVM 参数
env.java.opts.jobmanager:用来配置启动 JobManager 的 JVM 参数
env.java.opts.taskmanager:用来配置启动 TaskManager 的 JVM 参数
env.java.opts.historyserver:用来配置启动 HistoryServer 的 JVM 参数
env.java.opts.client:用来配置启动 Flink Client 的 JVM 参数
04 Kerberos 认证常见问题
1.javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
此消息表明一个操作尝试要求以Kerberos的user/host@realm身份认证的操作,但票据cache中没有用于user/host@realm的票据。
用户环境引用的策略/票证缓存文件丢失、不可读(权限)、损坏或无效票证续签寿命设置为零
票证授予票证(TGT)不存在,因为服务A需要将命令作为服务B运行,但尚未正确配置为允许模拟服务B
票证更新尚未执行/未成功。这可能是由于CDH 5.3之前的HBASE或CDH5.2之前的Hive / Sentry缺陷引起的
该用户的凭据尚未在KDC中生成
执行了手动步骤,例如hadoop fs -ls,但是用户从未通过Kerberos身份验证
Oracle JDK 6 Update 26或更早版本无法读取由MIT Kerberos 1.8.1或更高版本创建的Kerberos凭证高速缓存。
某些版本的Oracle JDK 8可能会遇到此问题
2.javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Fail to create credential. (63) - No service creds)]
由JDK缺陷引起
票证消息对于UDP协议而言太大
主机未正确映射到Kerberos领域
3.Found unsupported keytype(18)
确保正确安装了与JDK相匹配的无限强度策略文件的正确版本
确保对策略文件(位于jdk目录中,例如/usr/java/jdk1.7.0_67-cloudera/jre/lib/security/)的许可权能够被所有用户读取。
确保文件已部署到集群软件正在使用的jdk中
有关详细信息,使用以下的(链接以匹配关键字类型号18在该实例中)将其加密类型http://www.iana.org/assignments/Kerberos-parameters/Kerberos-parameters.xml(AES256-CTS-HMAC-此示例为sha1-96)
4.GSSException: No valid credentials provided (Mechanism level: Server not found in Kerberos database (7) - UNKNOWN_SERVER)
hostname或要访问的URL与keytab中列出的主机之间发生主机名不匹配。造成这种情况的原因多种多样,包括但不限于:
多网卡(NIC)服务器,以使来自主机的数据包的IP地址与通过主机解析返回的IP不匹配
负载平衡器和后续的主机名解析问题
DNS和主机名解析问题/不一致
反向DNS(必需)主机名解析问题/不一致
在krb5.conf中主机正在映射到参数[domain_realm]的错误域,这或者是通过其他的krb5.conf配置,或者是通过KDC配置。默认参数情况下,除非使用[domain_realm]等进行显式配置,否则主机名(例如:“ crash.EXAMPLE.com ”)将映射到域“ EXAMPLE.com ” 。请参见MIT Kerberos文档:[domain_realm]
如果尝试在Cloudera Manager中执行“ Generate Credentials ”步骤(在更高版本中重命名为“ Generate Missing Credentials ”)时发生此错误,则可能是由于导入到Cloudera Manager数据库中的管理员帐户详细信息不再与主机匹配,例如Cloudera Manager服务器的主机名在上一次导入后随后更改了。
视频回放&PPT获取
- 视频回看:
https://www.bilibili.com/video/BV1mD4y1h7ce/?spm_id_from=333.999.0.0
- 课件获取:
关注公众号“ChunJun”,后台私信“课件”获得直播课件
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack