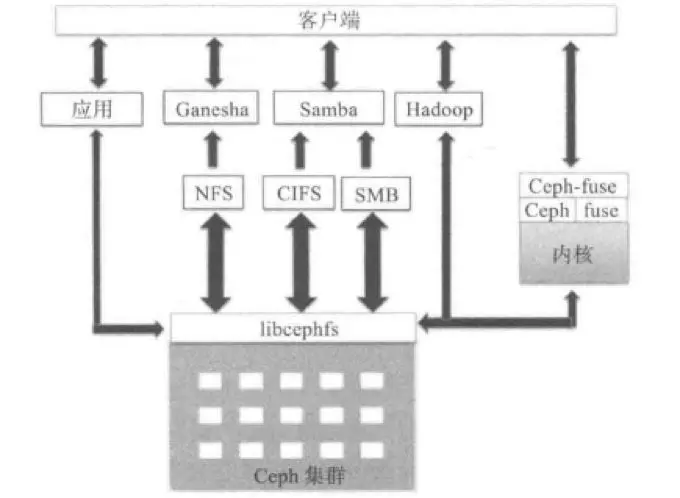
kafka-producer源码分析
kafka-1.0.1源码下载地址
一.kafka发送示例
/**
* Created by XiChuan on 2021/6/7.
*/
public class ProducerTest {
public static void main(String[] args) throws Exception {
KafkaProducer<String, String> producer = createProducer();
JSONObject order=createRecord();
ProducerRecord<String, String> record = new ProducerRecord<String, String>(
"test" ,order.toString());
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
System.out.println("消息发送成功");
} else {
exception.printStackTrace();
//进行处理
}
}
});
producer.close();
}
public static KafkaProducer<String, String> createProducer() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.90.13:9091,192.168.90.13:9092,192.168.90.13:9093");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("buffer.memory", 33554432);
//props.put("compression.type", "lz4");
props.put("batch.size", 32768);
props.put("linger.ms", 100);
props.put("retries", 10);//5 10
props.put("retry.backoff.ms", 300);
props.put("request.required.acks", "1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
return producer;
}
public static JSONObject createRecord() {
JSONObject order=new JSONObject();
order.put("userId", 12344);
order.put("amount", 100.0);
order.put("statement", "pay");
return order;
}
}
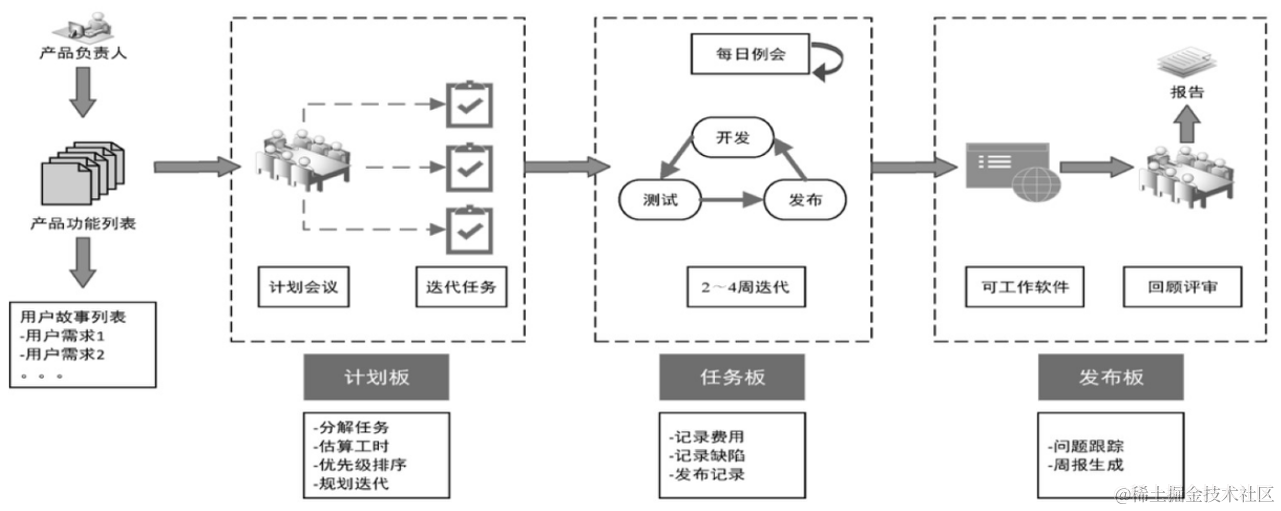
二.Producer初始化流程
2.1 此时我们先撇开源码不说,先来画个原理图。
2.1.1 丢进缓冲区前的操作
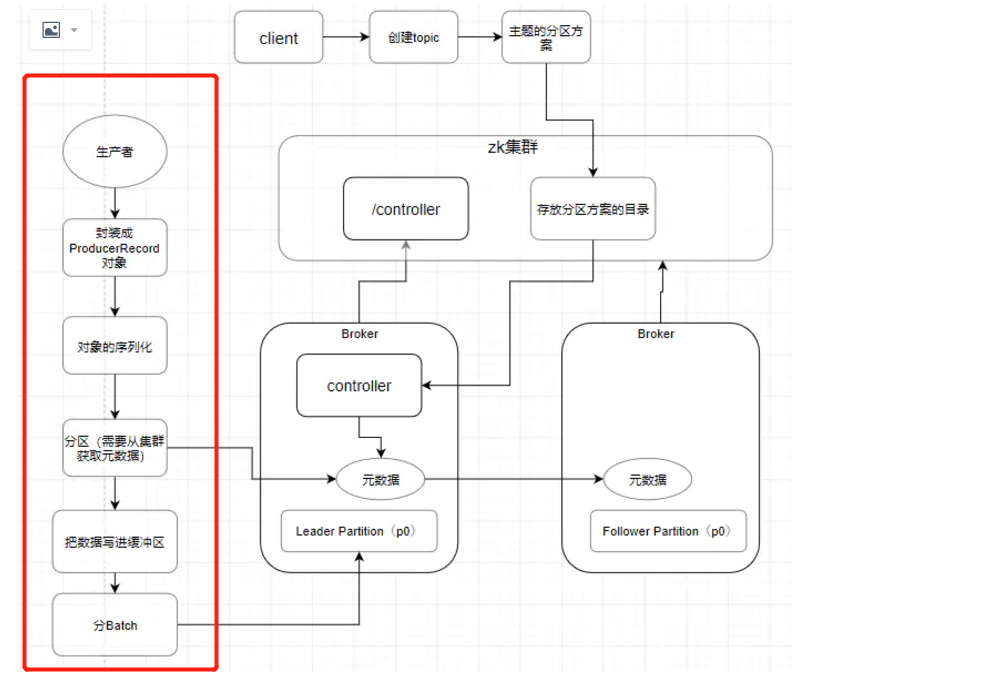
首先我们现在是初始化了一个 KafkaProducer 对吧。然后会有一个 ProducerInterceptors ,看这个英文像是拦截器,它会把我们的消息根据一定的规则去过滤掉。但是这个东西其实作用不大,因为我通过if-else都可以代替它的作用,所以就是比较鸡肋。所以发送消息前会用它进行一个消息的过滤,结束后会对消息进行 序列化 。序列化结束,就找到Partitioner分区器 (要知道该发送到哪一台服务器上的哪一个分区)进行分区。
所以我们现在得到的四个关键词是

2.1.2 缓冲区的结构
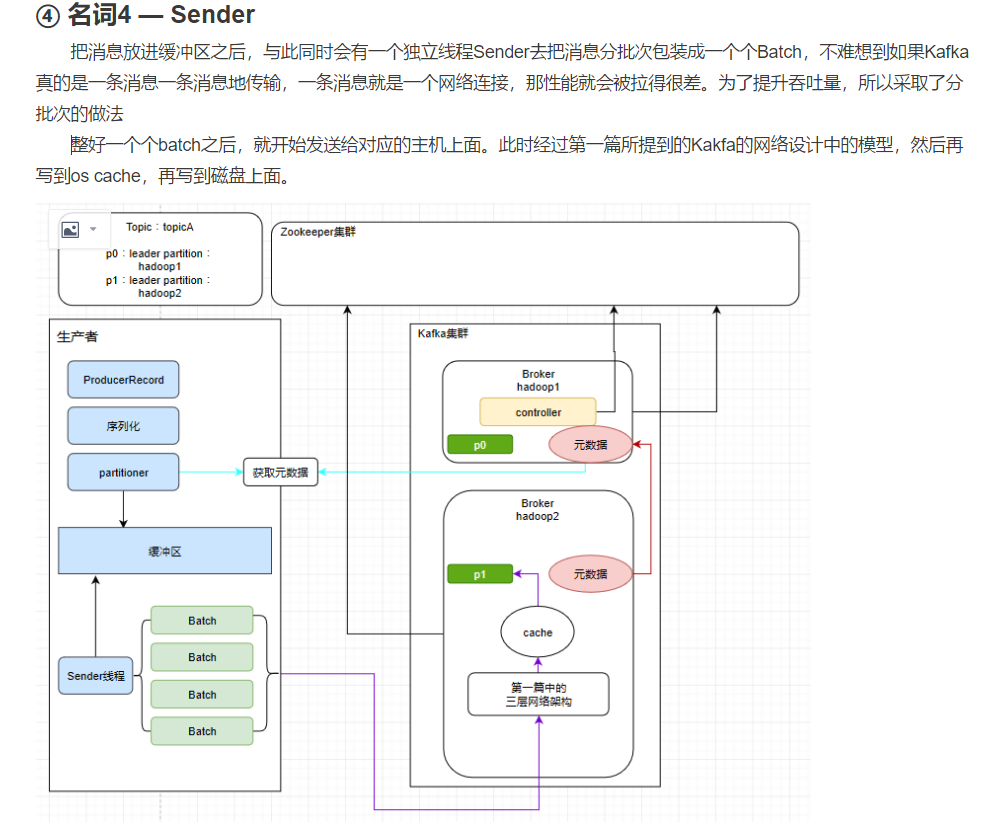
此时发送之前,我们要先把消息放入一个缓冲区里面,那么这个缓冲区其实是叫 RecordAccumulator ,缓冲区里面会存在多个deque队列。kafka的消息并不是逐条发送的,而是会打包成一个个批次(每个批次默认16K)发送。这些队列里面的封装好的消息批次会依次发送给不同的分区(图中仅列出1,2,3),比如下图

第一个deque就只负责发送给分区1,第二个deque就仅发送给分区2···依次类推
2.1.3 Sender线程的结构
真正发送数据的其实就是这个Sender线程,如下图

Sender启动起来之后会创建请求ClientRequest,这里的ClientRequest并不是完全一样的。因为发往不同的服务器应该是各种不同的请求。创建请求完成后,会发送给NetWorkClient,它是管理Kafka网络的非常重要的组件。它会在它的里面暂存请求,至于为何需要这样,我们之后说明。
后面的selector里的KafkaChannel其实就是类似于我们在 NIO 中所提到的SocketChannel,之后selector会发送消息给Kafka,这个过程是客户端向服务端发送消息,此时服务端,也就是Kafka会再返回响应,这个响应也仍旧是这个KafkaChannel接收,然后返回给NetworkClient,经过处理后返回给客户端。
2.1.4 原理分析总图
所以整个流程走下来应该就是这样的一张图。图中已经用数字1~12标好流程

这个图也是非常非常粗略的一个流程说明,Kafka的源码细节远比这个图来的细致,所以大家看到这里如果觉得似懂非懂也是正常,后面结合源码说明一定能更加清楚。
2.2 KafkaProducer进行初始化源码分析
我们再设置kafka参数后,需要对KafkaProducer进行初始化
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
进入这个构造函数内部
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
try {
//配置用户自定义的参数(非重点)
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = Time.SYSTEM;
String clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
if (clientId.length() <= 0)
clientId = "producer-" + PRODUCER_CLIENT_ID_SEQUENCE.getAndIncrement();
this.clientId = clientId;
String transactionalId = userProvidedConfigs.containsKey(ProducerConfig.TRANSACTIONAL_ID_CONFIG) ?
(String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG) : null;
LogContext logContext;
if (transactionalId == null)
logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));
else
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
//metric是监控方面的,不是我们关心的逻辑部分
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
List<MetricsReporter> reporters = config.getConfiguredInstances(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG,
MetricsReporter.class);
reporters.add(new JmxReporter(JMX_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
//设置分区器
//可以给每一个消息设置一个key,也可以不指定,这个key跟我们要把这个消息发送到哪个主题的哪个分区是有关系的
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
//重试时间,默认100ms(非重点)
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
//序列化器
//props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
if (keySerializer == null) {
this.keySerializer = ensureExtended(config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class));
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = ensureExtended(keySerializer);
}
if (valueSerializer == null) {
this.valueSerializer = ensureExtended(config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class));
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = ensureExtended(valueSerializer);
}
// load interceptors and make sure they get clientId
//拦截器 (非重点)
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
List<ProducerInterceptor<K, V>> interceptorList = (List) (new ProducerConfig(userProvidedConfigs, false)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class);
this.interceptors = interceptorList.isEmpty() ? null : new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer, valueSerializer, interceptorList, reporters);
//元数据单元
//参数 METADATA_MAX_AGE_CONFIG ,默认值是5分钟,作用是默认每隔5分钟,生产者会从集群中去获取一次元数据信息。因为要发送消息的话我们必须保证元数据信息是准确的。
this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
true, true, clusterResourceListeners);
//参数 MAX_REQUEST_SIZE_CONFIG 这里代表的是生产者往服务端发送消息时规定一条消息最大为多少。
//而如果你超过了这个规定的大小,你的消息就无法发送出去。默认是1M,
//这个值有点偏小了,生产环境中需要去修改这个值。比如10M,当然这个因地制宜,大家需要结合公司的实际情况决定。
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
//参数 BUFFER_MEMORY_CONFIG 指的是缓冲区,也就是 RecordAccumulator 大小。
//这个值一般是够用的,默认是32M
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
//参数 COMPRESSION_TYPE_CONFIG 默认情况下是不支持压缩,不过也可以设置,可供选择的除了none,还有gzip,snappy,lz4,我们一般会使用lz4
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
this.requestTimeoutMs = config.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.transactionManager = configureTransactionState(config, logContext, log);
int retries = configureRetries(config, transactionManager != null, log);
int maxInflightRequests = configureInflightRequests(config, transactionManager != null);
short acks = configureAcks(config, transactionManager != null, log);
this.apiVersions = new ApiVersions();
//初始化一个RecordAccumulator
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.totalMemorySize,
this.compressionType,
config.getLong(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
metrics,
time,
apiVersions,
transactionManager);
//获取集群中的元数据信息的地址
//BOOTSTRAP_SERVERS_CONFIG 就是这个"hadoop1:9092,hadoop2:9092,hadoop3:9092",它的作用就是给生产者指明方向去获取集群中的元数据而已。
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
this.metadata.update(Cluster.bootstrap(addresses), Collections.<String>emptySet(), time.milliseconds());
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
// 初始化组件 NetworkClient
/**
1.CONNECTIONS_MAX_IDLE_MS_CONFIG
一个网络连接最大空闲时间,超过之后会自动关闭此连接,默认值为9min
一般情况下我们会设置成-1,-1时是什么情况下都不回收
2.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION (流控)
每个发送数据的网络连接对并未接收到响应的消息的最大数。默认值是5
3.SEND_BUFFER_CONFIG 和 RECEIVE_BUFFER_CONFIG
NIO的一些参数
**/
NetworkClient client = new NetworkClient(
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
this.metadata,
clientId,
maxInflightRequests,
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs,
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
//Sender线程的初始化
this.sender = new Sender(logContext,
client,
this.metadata,
this.accumulator,
maxInflightRequests == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
Time.SYSTEM,
this.requestTimeoutMs,
config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
//启动Sender线程
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
this.errors = this.metrics.sensor("errors");
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics);
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121
close(0, TimeUnit.MILLISECONDS, true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
可以看到初始化的时候,初始化了重要的RecordAccumulator、NetworkClient 以及启动了Sender线程
三.Producer的send流程
下面通过对 send 源码分析来一步步剖析 Producer 数据的发送流程。
3.1 Producer 的 send 实现
// 异步向一个 topic 发送数据
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
// 向 topic 异步地发送数据,当发送确认后唤起回调函数
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
数据发送的最终实现还是调用了Producer的doSend()接口。
blocking vs non-blocking:
KafkaProducer.send方法返回的是一个Future,那么它如何同时实现blocking方式和non-blocking方式。
blocking:在调用send返回Future时,立即调用get,因为Future.get在没有返回结果时会一直阻塞- 内部调用的是
FutureRecordMetadata的CountDownLatch.wait(),当完成或失败后会在回调函数执行完后进行countdown
- 内部调用的是
non-block:提供一个callback,调用send后,可以继续发送消息而不用等待。当有结果返回时,callback会被自动通知执行

3.2 Producer 的 doSend 实现
下面是 doSend()的具体实现
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 1.确认数据要发送到的 topic 的 metadata 是可用的
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 2.序列化 record 的 key 和 value
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer");
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer");
}
// 3. 获取该 record 的 partition 的值(可以指定,也可以根据算法计算)
int partition = partition(record, serializedKey, serializedValue, cluster);
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize); // record 的字节超出限制或大于内存限制时,就会抛出 RecordTooLargeException 异常
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp(); // 时间戳
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
// 4. 向 accumulator 中追加数据
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
// 5.在每次追加一条消息到收集器batch之后,都要判断是否满了.如果满了,就执行一次Sender操作,通知Sender将这批数据发送到Kafka
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (BufferExhaustedException e) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (KafkaException e) {
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
在 dosend() 方法的实现上,一条 Record 数据的发送,可以分为以下五步:
- 确认数据要发送到的 topic 的 metadata 是可用的(如果该 partition 的 leader 存在则是可用的,如果开启权限时,client 有相应的权限),如果没有 topic 的 metadata 信息,就需要获取相应的 metadata;
- 序列化 record 的 key 和 value;
- 获取该 record 要发送到的 partition(可以指定,也可以根据算法计算);
- 向 accumulator 中追加 record 数据,数据会先进行缓存;
- 如果追加完数据后,对应的 RecordBatch 已经达到了 batch.size 的大小(或者batch 的剩余空间不足以添加下一条 Record),则唤醒
sender线程发送数据。
数据的发送过程,可以简单总结为以上五点,下面会这几部分的具体实现进行详细分析。
3.3 发送过程详解
3.3.1 获取 topic 的 metadata 信息
Producer 通过 waitOnMetadata() 方法来获取对应 topic 的 metadata 信息,这部分后面会单独抽出一篇文章来介绍,这里就不再详述,总结起来就是:在数据发送前,需要先该 topic 是可用的。
3.3.2 key 和 value 的序列化
Producer 端对 record 的 key 和 value 值进行序列化操作,在 Consumer 端再进行相应的反序列化,Kafka 内部提供的序列化和反序列化算法如下图所示:
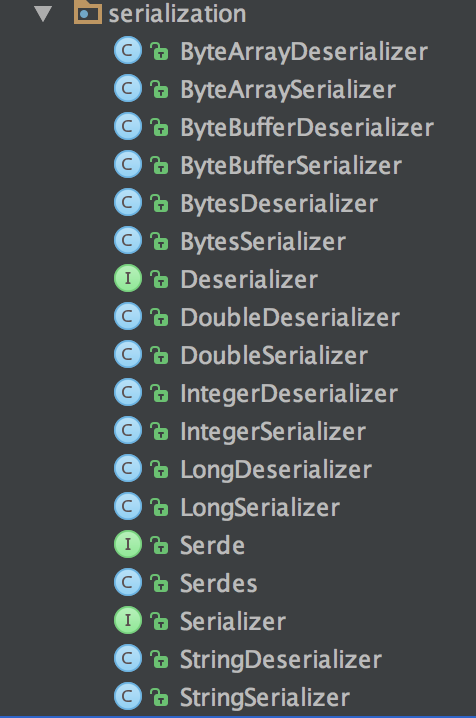
当然我们也是可以自定义序列化的具体实现,不过一般情况下,Kafka 内部提供的这些方法已经足够使用。
3.3.3 获取 partition 值
关于 partition 值的计算,分为三种情况:
- 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
- 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的
round-robin算法。
具体实现如下:
// 当 record 中有 partition 值时,直接返回,没有的情况下调用 partitioner 的类的 partition 方法去计算(KafkaProducer.class)
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
Producer 默认使用的 partitioner 是 org.apache.kafka.clients.producer.internals.DefaultPartitioner,用户也可以自定义 partition 的策略,下面是这个类两个方法的具体实现:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {// 没有指定 key 的情况下
int nextValue = nextValue(topic); // 第一次的时候产生一个随机整数,后面每次调用在之前的基础上自增;
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
// leader 不为 null,即为可用的 partition
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {// 有 key 的情况下,使用 key 的 hash 值进行计算
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; // 选择 key 的 hash 值
}
}
// 根据 topic 获取对应的整数变量
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) { // 第一次调用时,随机产生
counter = new AtomicInteger(new Random().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement(); // 后面再调用时,根据之前的结果自增
}
这就是 Producer 中默认的 partitioner 实现。
3.3.4 向 accumulator 写数据
由于生产者发送消息是异步地,所以可以将多条消息缓存起来,等到一定时机批量地写入到Kafka集群中,RecordAccumulator就扮演了缓冲者的角色。生产者每生产一条消息,就向accumulator中追加一条消息,并且要返回本次追加是否导致batch满了,如果batch满了,则开始发送这一批数据。最开始以为Deque<RecordBatch>就是一个消息队列,实际上一批消息会首先放在RecordBatch中,然后Batch又放在双端队列中。

Producer 会先将 record 写入到 buffer 中,当达到一个 batch.size 的大小时,再唤起 sender 线程去发送 RecordBatch(第五步),这里先详细分析一下 Producer 是如何向 buffer 中写入数据的。
Producer 是通过 RecordAccumulator 实例追加数据,RecordAccumulator 模型如下图所示,一个重要的变量就是 ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches,每个 TopicPartition 都会对应一个 Deque<RecordBatch>,当添加数据时,会向其 topic-partition 对应的这个 queue 最新创建的一个 RecordBatch 中添加 record,而发送数据时,则会先从 queue 中最老的那个 RecordBatch 开始发送。
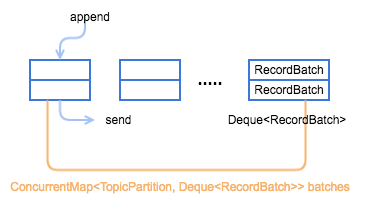
Producer RecordAccumulator 模型
// org.apache.kafka.clients.producer.internals.RecordAccumulator
// 向 accumulator 添加一条 record,并返回添加后的结果(结果主要包含: future metadata、batch 是否满的标志以及新 batch 是否创建)其中, maxTimeToBlock 是 buffer.memory 的 block 的最大时间
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
//如果一个topicPartition不存在Deque<RecordBatch>就会创建,如果存在,就会从batchs中获取
Deque<RecordBatch> dq = getOrCreateDeque(tp);// 每个 topicPartition 对应一个 queue
synchronized (dq) {// 在对一个 queue 进行操作时,会保证线程安全
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
//先获取 queue 中最新加入的那个 RecordBatch,如果不存在或者存在但剩余空余不足以添加本条 record 则返回 null,
//成功写入的话直接返回结果,写入成功;
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq); // 追加数据
if (appendResult != null)// 这个 topic-partition 已经有记录了
return appendResult;
}
// 为 topic-partition 创建一个新的 RecordBatch, 需要初始化相应的 RecordBatch,要为其分配的大小是: max(batch.size, 加上头文件的本条消息的大小)
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);// 给这个 RecordBatch 初始化一个 buffer
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {// 如果突然发现这个 queue 已经存在,那么就释放这个已经分配的空间
free.deallocate(buffer);
return appendResult;
}
// 给 topic-partition 创建一个 RecordBatch
MemoryRecordsBuilder recordsBuilder = MemoryRecords.builder(buffer, compression, TimestampType.CREATE_TIME, this.batchSize);
//前面没有append成功,说明最后一个RecordBatch不存在或者没有容量,需要重新创建一个RecordBatch再进行append
RecordBatch batch = new RecordBatch(tp, recordsBuilder, time.milliseconds());
// 向新的 RecordBatch 中追加数据
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);// 将 RecordBatch 添加到对应的 queue 中
incomplete.add(batch);// 向未 ack 的 batch 集合添加这个 batch
// 如果 dp.size()>1 就证明这个 queue 有一个 batch 是可以发送了
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
总结一下其 record 写入的具体流程如下图所示:

Producer RecordAccumulator record 写入流程:
- 获取该 topic-partition 对应的 queue,没有的话会创建一个空的 queue;
- 向 queue 中追加数据,先获取 queue 中最新加入的那个 RecordBatch,如果不存在或者存在但剩余空余不足以添加本条 record 则返回 null,成功写入的话直接返回结果,写入成功;
- 创建一个新的
RecordBatch,初始化内存大小根据max(batch.size, Records.LOG_OVERHEAD + Record.recordSize(key, value))来确定(防止单条 record 过大的情况); - 向新建的
RecordBatch写入 record,并将RecordBatch添加到 queue 中,返回结果,写入成功。
–下面过程可以忽略–
Kafka 定义了 BufferPool 类以实现对 ByteBuffer 的复用,避免频繁创建和释放所带来的性能开销。不过需要注意的一点是,并不是所有的 ByteBuffer 对象都会被复用,BufferPool 对所管理的 ByteBuffer 对象的大小是有限制的(默认大小为 16KB,可以依据具体的应用场景适当调整batch.size 配置进行修改),只有大小等于该值的 ByteBuffer 对象才会被 BufferPool 管理。
上述过程多次调用到 RecordAccumulator#tryAppend 方法,下面来看一下该方法的实现:
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque<RecordBatch> deque) {
// 获取 deque 的最后一个 RecordBatch
RecordBatch last = deque.peekLast();
if (last != null) {
// 尝试往该 RecordBatch 末尾追加消息
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future == null) {
// 追加失败
last.close();
} else {
// 追加成功,将结果封装成 RecordAppendResult 对象返回
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
}
}
return null;
}
// org.apache.kafka.clients.producer.internals.RecordBatch#tryAppend
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, long now) {
// 检测是否还有多余的空间容纳该消息
if (!recordsBuilder.hasRoomFor(key, value)) {
// 没有多余的空间则直接返回,后面会尝试申请新的空间
return null;
}
// 添加当前消息到 MemoryRecords,并返回消息对应的 CRC32 校验码
long checksum = this.recordsBuilder.append(timestamp, key, value);
// 更新最大 record 字节数
this.maxRecordSize = Math.max(this.maxRecordSize, Record.recordSize(key, value));
// 更新最后一次追加记录时间戳
this.lastAppendTime = now;
FutureRecordMetadata future = new FutureRecordMetadata(
produceFuture, recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
if (callback != null) {
// 如果指定了 Callback,将 Callback 和 FutureRecordMetadata 封装到 Trunk 中
thunks.add(new Thunk(callback, future));
}
this.recordCount++;
return future;
}
由代码可知,tryAppend()该函数最后调用的时this.recordsBuilder.append方法添加,那么这个recordBuilder是什么了?append是把消息追加到哪了?
同过查看RecoredBatch类定义可知这个recordsBuilder为MemoryRecordsBuilder,那我们接下来就可以来看下MemoryRecordsBuilder.append方法将消息添加到哪了
public long append(long timestamp, byte[] key, byte[] value) {
return appendWithOffset(lastOffset < 0 ? baseOffset : lastOffset + 1, timestamp, key, value);
}
/*----------------------------------------------------------------------------------------------*/
//appendStream为封装ByteBuffer的数据流
bufferStream = new ByteBufferOutputStream(buffer);
appendStream = wrapForOutput(bufferStream, compressionType, magic, COMPRESSION_DEFAULT_BUFFER_SIZE);
/*--------------------------------------------------------------------------------------------------*/
public long appendWithOffset(long offset, long timestamp, byte[] key, byte[] value) {
try {
if (lastOffset >= 0 && offset <= lastOffset)
throw new IllegalArgumentException(String.format("Illegal offset %s following previous offset %s (Offsets must increase monotonically).", offset, lastOffset));
int size = Record.recordSize(magic, key, value);
LogEntry.writeHeader(appendStream, toInnerOffset(offset), size);
if (timestampType == TimestampType.LOG_APPEND_TIME)
timestamp = logAppendTime;
long crc = Record.write(appendStream, magic, timestamp, key, value, CompressionType.NONE, timestampType);
recordWritten(offset, timestamp, size + Records.LOG_OVERHEAD);
return crc;
} catch (IOException e) {
throw new KafkaException("I/O exception when writing to the append stream, closing", e);
}
}
首先我们需要知道每个RecordBatch都对应一个ByteBuffer和MemoryRecordsBuilder,而MemoryRecordsBuilder的作用就是将每条消息追加到ByteBuffer中。上述代码可知,ByteBuffer被封装成DataOutputStream,LogEntry.writeHeader和Record.write方法即执行把消息头和消息体追加到ByteBuffer当中。
这里先做个小结,每个KafkaProducer都有一个消息缓存类accumulator,这个缓存类有一个map存储TopicPartiton-->List<RecordBatch>键值对。用户每次发送消息都是先添加到该消息对应TopicPartition的RecordBatch中。而RecordBatch中有一个大小限制的ByteBuffer,存储用户发送的消息。
3.4 Sender线程发送 RecordBatch(此处先简单说下)
当 record 写入成功后,如果发现 RecordBatch 已满足发送的条件(通常是 queue 中有多个 batch,那么最先添加的那些 batch 肯定是可以发送了),那么就会唤醒 sender 线程,发送 RecordBatch。
sender 线程对 RecordBatch 的处理是在 run() 方法中进行的,该方法具体实现如下:
void run(long now) {
Cluster cluster = metadata.fetch();
// 获取那些已经可以发送的 RecordBatch 对应的 nodes
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果有 topic-partition 的 leader 是未知的,就强制 metadata 更新
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 如果与node 没有连接(如果可以连接,同时初始化该连接),就证明该 node 暂时不能发送数据,暂时移除该 node
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// 返回该 node 对应的所有可以发送的 RecordBatch 组成的 batches(key 是 node.id),并将 RecordBatch 从对应的 queue 中移除
Map<Integer, List<RecordBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
if (guaranteeMessageOrder) {
//记录将要发送的 RecordBatch
for (List<RecordBatch> batchList : batches.values()) {
for (RecordBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
// 将由于元数据不可用而导致发送超时的 RecordBatch 移除
List<RecordBatch> expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
pollTimeout = 0;
}
// 发送 RecordBatch
sendProduceRequests(batches, now);
this.client.poll(pollTimeout, now); // 关于 socket 的一些实际的读写操作(其中包括 meta 信息的更新)
}
这段代码前面有很多是其他的逻辑处理,如:移除暂时不可用的 node、处理由于元数据不可用导致的超时 RecordBatch,真正进行发送发送 RecordBatch 的是 sendProduceRequests(batches, now) 这个方法,具体是:
/**
* Transfer the record batches into a list of produce requests on a per-node basis
*/
private void sendProduceRequests(Map<Integer, List<RecordBatch>> collated, long now) {
for (Map.Entry<Integer, List<RecordBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
/**
* Create a produce request from the given record batches
*/
// 发送 produce 请求
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<RecordBatch> batches) {
Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());
final Map<TopicPartition, RecordBatch> recordsByPartition = new HashMap<>(batches.size());
for (RecordBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
produceRecordsByPartition.put(tp, batch.records());
recordsByPartition.put(tp, batch);
}
ProduceRequest.Builder requestBuilder =
new ProduceRequest.Builder(acks, timeout, produceRecordsByPartition);
//这个回调后面会提到...
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
这段代码就简单很多,总来起来就是,将 batches 中 leader 为同一个 node 的所有 RecordBatch 放在一个请求中进行发送。
四.Producer Metadata 更新机制
本文主要来讲述以下三个问题:
- metadata 内容是什么;
- Producer 更新 metadata 的流程;
- Producer 在什么情况下会去更新 metadata;
4.1 Metadata 内容
Metadata 信息的内容可以通过源码看明白:
// 这个类被 client 线程和后台 sender 所共享,它只保存了所有 topic 的部分数据,当我们请求一个它上面没有的 topic meta 时,它会通过发送 metadata update 来更新 meta 信息,
// 如果 topic meta 过期策略是允许的,那么任何 topic 过期的话都会被从集合中移除,
// 但是 consumer 是不允许 topic 过期的因为它明确地知道它需要管理哪些 topic
public final class Metadata {
private static final Logger log = LoggerFactory.getLogger(Metadata.class);
public static final long TOPIC_EXPIRY_MS = 5 * 60 * 1000;
private static final long TOPIC_EXPIRY_NEEDS_UPDATE = -1L;
private final long refreshBackoffMs; // metadata 更新失败时,为避免频繁更新 meta,最小的间隔时间,默认 100ms
private final long metadataExpireMs; // metadata 的过期时间, 默认 60,000ms
private int version; // 每更新成功1次,version自增1,主要是用于判断 metadata 是否更新
private long lastRefreshMs; // 最近一次更新时的时间(包含更新失败的情况)
private long lastSuccessfulRefreshMs; // 最近一次成功更新的时间(如果每次都成功的话,与前面的值相等, 否则,lastSuccessulRefreshMs < lastRefreshMs)
private Cluster cluster; // 集群中一些 topic 的信息
private boolean needUpdate; // 是都需要更新 metadata
/* Topics with expiry time */
private final Map<String, Long> topics; // topic 与其过期时间的对应关系
private final List<Listener> listeners; // 事件监控者
private final ClusterResourceListeners clusterResourceListeners; //当接收到 metadata 更新时, ClusterResourceListeners的列表
private boolean needMetadataForAllTopics; // 是否强制更新所有的 metadata
private final boolean topicExpiryEnabled; // 默认为 true, Producer 会定时移除过期的 topic,consumer 则不会移除
}
关于 topic 的详细信息(leader 所在节点、replica 所在节点、isr 列表)都是在 Cluster 实例中保存的。
// 并不是一个全集,metadata的主要组成部分
public final class Cluster {
// 从命名直接就看出了各个变量的用途
private final boolean isBootstrapConfigured;
private final List<Node> nodes; // node 列表
private final Set<String> unauthorizedTopics; // 未认证的 topic 列表
private final Set<String> internalTopics; // 内置的 topic 列表
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition; // partition 的详细信息
private final Map<String, List<PartitionInfo>> partitionsByTopic; // topic 与 partition 的对应关系
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic; // 可用(leader 不为 null)的 topic 与 partition 的对应关系
private final Map<Integer, List<PartitionInfo>> partitionsByNode; // node 与 partition 的对应关系
private final Map<Integer, Node> nodesById; // node 与 id 的对应关系
private final ClusterResource clusterResource;
}
// org.apache.kafka.common.PartitionInfo
// topic-partition: 包含 topic、partition、leader、replicas、isr
public class PartitionInfo {
private final String topic;
private final int partition;
private final Node leader;
private final Node[] replicas;
private final Node[] inSyncReplicas;
}
Cluster 实例主要是保存:
broker.id与node的对应关系;topic与partition (PartitionInfo)的对应关系;node与partition (PartitionInfo)的对应关系。
4.2 Producer 的 Metadata 更新流程
Producer 在调用 dosend() 方法时,第一步就是通过 waitOnMetadata 方法获取该 topic 的 metadata 信息.
// 等待 metadata 的更新
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
metadata.add(topic);// 在 metadata 中添加 topic 后,如果 metadata 中没有这个 topic 的 meta,那么 metadata 的更新标志设置为了 true
Cluster cluster = metadata.fetch();
Integer partitionsCount = cluster.partitionCountForTopic(topic);// 如果 topic 已经存在 meta 中,则返回该 topic 的 partition 数,否则返回 null
// 当前 metadata 中如果已经有这个 topic 的 meta 的话,就直接返回
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
long elapsed;
// 发送 metadata 请求,直到获取了这个 topic 的 metadata 或者请求超时
do {
log.trace("Requesting metadata update for topic {}.", topic);
int version = metadata.requestUpdate();// 返回当前版本号,初始值为0,每次更新时会自增,并将 needUpdate 设置为 true
sender.wakeup();// 唤起 sender,发送 metadata 请求
try {
metadata.awaitUpdate(version, remainingWaitMs);// 等待 metadata 的更新
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
}
cluster = metadata.fetch();
elapsed = time.milliseconds() - begin;
if (elapsed >= maxWaitMs)
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");// 超时
if (cluster.unauthorizedTopics().contains(topic))// 认证失败,对当前 topic 没有 Write 权限
throw new TopicAuthorizationException(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null);// 不停循环,直到 partitionsCount 不为 null(即直到 metadata 中已经包含了这个 topic 的相关信息)
if (partition != null && partition >= partitionsCount) {
throw new KafkaException(
String.format("Invalid partition given with record: %d is not in the range [0...%d).", partition, partitionsCount));
}
return new ClusterAndWaitTime(cluster, elapsed);
}
如果 metadata 中不存在这个 topic 的 metadata,那么就请求更新 metadata,如果 metadata 没有更新的话,方法就一直处在 do ... while 的循环之中,在循环之中,主要做以下操作:
metadata.requestUpdate()将 metadata 的needUpdate变量设置为 true(强制更新),并返回当前的版本号(version),通过版本号来判断 metadata 是否完成更新;sender.wakeup()唤醒 sender 线程,sender 线程又会去唤醒NetworkClient线程,NetworkClient线程进行一些实际的操作(后面详细介绍);metadata.awaitUpdate(version, remainingWaitMs)等待 metadata 的更新。
// 更新 metadata 信息(根据当前 version 值来判断)
public synchronized void awaitUpdate(final int lastVersion, final long maxWaitMs) throws InterruptedException {
if (maxWaitMs < 0) {
throw new IllegalArgumentException("Max time to wait for metadata updates should not be < 0 milli seconds");
}
long begin = System.currentTimeMillis();
long remainingWaitMs = maxWaitMs;
while (this.version <= lastVersion) {// 不断循环,直到 metadata 更新成功,version 自增
if (remainingWaitMs != 0)
wait(remainingWaitMs);// 阻塞线程,等待 metadata 的更新
long elapsed = System.currentTimeMillis() - begin;
if (elapsed >= maxWaitMs)// timeout
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
remainingWaitMs = maxWaitMs - elapsed;
}
}
在 Metadata.awaitUpdate() 方法中,线程会阻塞在 while 循环中,直到 metadata 更新成功或者 timeout。
从前面可以看出,此时 Producer 线程会阻塞在两个 while循环中,直到 metadata 信息更新,那么 metadata 是如何更新的呢?如果有印象的话,前面应该已经介绍过了,主要是通过 sender.wakeup() 来唤醒 sender 线程,间接唤醒 NetworkClient 线程,NetworkClient 线程来负责发送 Metadata 请求,并处理 Server 端的响应。
在 介绍 Producer 发送模型时,在第五步 sender线程会调用 NetworkClient.poll() 方法进行实际的操作,其源码如下:
public List<ClientResponse> poll(long timeout, long now) {
long metadataTimeout = metadataUpdater.maybeUpdate(now);// 判断是否需要更新 meta,如果需要就更新(请求更新 metadata 的地方)
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
handleCompletedSends(responses, updatedNow);// 通过 selector 中获取 Server 端的 response
handleCompletedReceives(responses, updatedNow);// 在返回的 handler 中,会处理 metadata 的更新
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutRequests(responses, updatedNow);
// invoke callbacks
for (ClientResponse response : responses) {
try {
response.onComplete();
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
return responses;
}
在这个方法中,主要会以下操作:
metadataUpdater.maybeUpdate(now):判断是否需要更新 Metadata,如果需要更新的话,先与 Broker 建立连接,然后发送更新 metadata 的请求;- 处理 Server 端的一些响应,这里主要讨论的是
handleCompletedReceives(responses, updatedNow)方法,它会处理 Server 端返回的 Metadata 结果。
先看一下 metadataUpdater.maybeUpdate() 的具体实现:
public long maybeUpdate(long now) {
// should we update our metadata?
// metadata 是否应该更新
long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);// metadata 下次更新的时间(需要判断是强制更新还是 metadata 过期更新,前者是立马更新,后者是计算 metadata 的过期时间)
// 如果一条 metadata 的 fetch 请求还未从 server 收到恢复,那么时间设置为 waitForMetadataFetch(默认30s)
long waitForMetadataFetch = this.metadataFetchInProgress ? requestTimeoutMs : 0;
long metadataTimeout = Math.max(timeToNextMetadataUpdate, waitForMetadataFetch);
if (metadataTimeout > 0) {// 时间未到时,直接返回下次应该更新的时间
return metadataTimeout;
}
Node node = leastLoadedNode(now);// 选择一个连接数最小的节点
if (node == null) {
log.debug("Give up sending metadata request since no node is available");
return reconnectBackoffMs;
}
return maybeUpdate(now, node); // 可以发送 metadata 请求的话,就发送 metadata 请求
}
/**
* Add a metadata request to the list of sends if we can make one
*/
// 判断是否可以发送请求,可以的话将 metadata 请求加入到发送列表中
private long maybeUpdate(long now, Node node) {
String nodeConnectionId = node.idString();
if (canSendRequest(nodeConnectionId)) {// 通道已经 ready 并且支持发送更多的请求
this.metadataFetchInProgress = true; // 准备开始发送数据,将 metadataFetchInProgress 置为 true
MetadataRequest.Builder metadataRequest; // 创建 metadata 请求
if (metadata.needMetadataForAllTopics())// 强制更新所有 topic 的 metadata(虽然默认不会更新所有 topic 的 metadata 信息,但是每个 Broker 会保存所有 topic 的 meta 信息)
metadataRequest = MetadataRequest.Builder.allTopics();
else // 只更新 metadata 中的 topics 列表(列表中的 topics 由 metadata.add() 得到)
metadataRequest = new MetadataRequest.Builder(new ArrayList<>(metadata.topics()));
log.debug("Sending metadata request {} to node {}", metadataRequest, node.id());
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);// 发送 metadata 请求
return requestTimeoutMs;
}
// If there's any connection establishment underway, wait until it completes. This prevents
// the client from unnecessarily connecting to additional nodes while a previous connection
// attempt has not been completed.
if (isAnyNodeConnecting()) {// 如果 client 正在与任何一个 node 的连接状态是 connecting,那么就进行等待
// Strictly the timeout we should return here is "connect timeout", but as we don't
// have such application level configuration, using reconnect backoff instead.
return reconnectBackoffMs;
}
if (connectionStates.canConnect(nodeConnectionId, now)) {// 如果没有连接这个 node,那就初始化连接
// we don't have a connection to this node right now, make one
log.debug("Initialize connection to node {} for sending metadata request", node.id());
initiateConnect(node, now);// 初始化连接
return reconnectBackoffMs;
}
return Long.MAX_VALUE;
}
// 发送 Metadata 请求
private void sendInternalMetadataRequest(MetadataRequest.Builder builder,
String nodeConnectionId, long now) {
ClientRequest clientRequest = newClientRequest(nodeConnectionId, builder, now, true);// 创建 metadata 请求
doSend(clientRequest, true, now);
}
所以,每次 Producer 请求更新 metadata 时,会有以下几种情况:
- 如果 node 可以发送请求,则直接发送请求;
- 如果该 node 正在建立连接,则直接返回;
- 如果该 node 还没建立连接,则向 broker 初始化链接。
而 KafkaProducer 线程之前是一直阻塞在两个 while 循环中,直到 metadata 更新
- sender 线程第一次调用
poll()方法时,初始化与node的连接; - sender 线程第二次调用
poll()方法时,发送Metadata请求; - sender 线程第三次调用
poll()方法时,获取metadataResponse,并更新 metadata。
经过上述 sender 线程三次调用 poll()方法,所请求的 metadata 信息才会得到更新,此时 Producer 线程也不会再阻塞,开始发送消息。
NetworkClient 接收到 Server 端对 Metadata 请求的响应后,更新 Metadata 信息。
// 处理任何已经完成的接收响应
private void handleCompletedReceives(List<ClientResponse> responses, long now) {
for (NetworkReceive receive : this.selector.completedReceives()) {
String source = receive.source();
InFlightRequest req = inFlightRequests.completeNext(source);
AbstractResponse body = parseResponse(receive.payload(), req.header);
log.trace("Completed receive from node {}, for key {}, received {}", req.destination, req.header.apiKey(), body);
if (req.isInternalRequest && body instanceof MetadataResponse)// 如果是 meta 响应
metadataUpdater.handleCompletedMetadataResponse(req.header, now, (MetadataResponse) body);
else if (req.isInternalRequest && body instanceof ApiVersionsResponse)
handleApiVersionsResponse(responses, req, now, (ApiVersionsResponse) body); // 如果是其他响应
else
responses.add(req.completed(body, now));
}
}
// 处理 Server 端对 Metadata 请求处理后的 response
public void handleCompletedMetadataResponse(RequestHeader requestHeader, long now, MetadataResponse response) {
this.metadataFetchInProgress = false;
Cluster cluster = response.cluster();
// check if any topics metadata failed to get updated
Map<String, Errors> errors = response.errors();
if (!errors.isEmpty())
log.warn("Error while fetching metadata with correlation id {} : {}", requestHeader.correlationId(), errors);
// don't update the cluster if there are no valid nodes...the topic we want may still be in the process of being
// created which means we will get errors and no nodes until it exists
if (cluster.nodes().size() > 0) {
this.metadata.update(cluster, now);// 更新 meta 信息
} else {// 如果 metadata 中 node 信息无效,则不更新 metadata 信息
log.trace("Ignoring empty metadata response with correlation id {}.", requestHeader.correlationId());
this.metadata.failedUpdate(now);
}
}
4.3 Producer Metadata 的更新策略
Metadata 会在下面两种情况下进行更新
KafkaProducer第一次发送消息时强制更新,其他时间周期性更新,它会通过Metadata的lastRefreshMs,lastSuccessfulRefreshMs这2个字段来实现;- 强制更新: 调用
Metadata.requestUpdate()将needUpdate置成了 true 来强制更新。
在 NetworkClient 的 poll() 方法调用时,就会去检查这两种更新机制,只要达到其中一种,就行触发更新操作。
Metadata 的强制更新会在以下几种情况下进行:
initConnect方法调用时,初始化连接;poll()方法中对handleDisconnections()方法调用来处理连接断开的情况,这时会触发强制更新;poll()方法中对handleTimedOutRequests()来处理请求超时时;- 发送消息时,如果无法找到 partition 的 leader;
- 处理
Producer响应(handleProduceResponse),如果返回关于 Metadata 过期的异常,比如:没有 topic-partition 的相关 meta 或者 client 没有权限获取其 metadata。
强制更新主要是用于处理各种异常情况。
五.Sender线程流程
5.1 Producer 的网络模型
KafkaProducer 通过 Sender 进行相应的 IO 操作,而 Sender 又调用 NetworkClient 来进行 IO 操作,NetworkClient 底层是对 Java NIO 进行相应的封装,其网络模型如下图所示
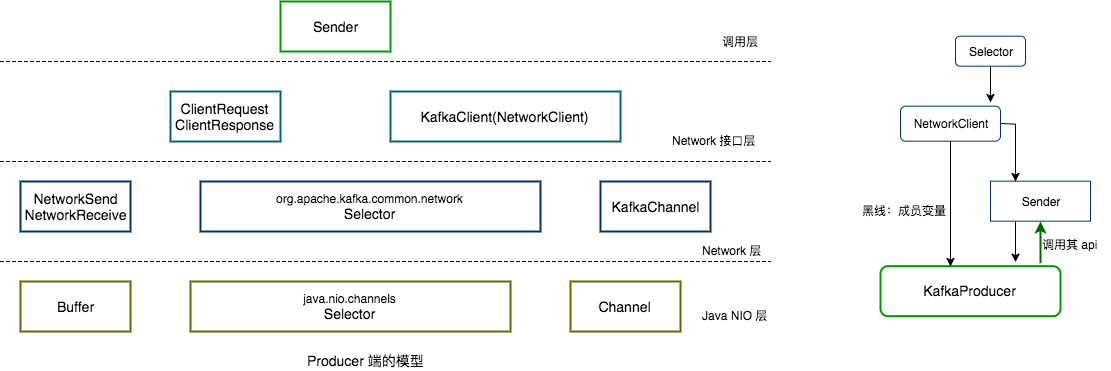
从图中可以看出,Sender 为最上层的接口,即调用层,Sender 调用 NetworkClient,NetworkClient 调用 Selector,而 Selector 底层封装了 Java NIO 的相关接口,从右边的图也可以看出它们之间的关系。
5.2 RecordAccumulator 类
我们看下RecordAccumulator中方法,在Producer的send流程中已经提到过了,我们在Sender的流程中,会提到read()与drain()方法

5.2 Producer 整体流程
有了对 Producer 网络模型的大概框架认识之后,下面再深入进去,看一下它们之间的调用关系以及 Producer 是如何调用 Java NIO 的相关接口,Producer 端的整体流程如下图所示。

这里涉及到的主要方法是:
KafkaProducer.dosend();–上面已经讲过Sender.run();NetworkClient.poll()(NetworkClient.dosend());Selector.poll();
下面会结合上图,对这几个方法做详细的讲解,本文下面的内容都是结合上图进行讲解。
5.3 Sender.run()
将缓存的消息发送给 Kafka 集群,这一过程由 Sender 线程负责执行,前面的分析中曾多次唤醒过该线程,下面来看一下其实现,位于 Sender 类中,该类实现了 java.lang.Runnable 接口,其 Sender#run 方法实现如下:
public void run() {
// 主循环,一直运行直到 KafkaProducer 被关闭
while (running) {
try {
this.run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
/* 如果 KafkaProducer 被关闭,尝试发送剩余的消息 */
while (!forceClose // 不是强制关闭
// 存在未发送或已发送待响应的请求
&& (this.accumulator.hasUnsent() || this.client.inFlightRequestCount() > 0)) {
try {
this.run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
// 如果是强制关闭,忽略所有未发送和已发送待响应的请求
if (forceClose) {
// 丢弃所有未发送完成的消息
this.accumulator.abortIncompleteBatches();
}
try {
// 关闭网络连接
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
}
sender作为一个线程,是在后台不断运行的,如果线程被停止,可能RecordAccumulator中还有数据没有发送出去,所以要优雅地停止。run()方法调用的是this.run(long now)方法,如下:
void run(long now) {
if (transactionManager != null) {
try {
if (transactionManager.shouldResetProducerStateAfterResolvingSequences())
// Check if the previous run expired batches which requires a reset of the producer state.
transactionManager.resetProducerId();
if (!transactionManager.isTransactional()) {
// this is an idempotent producer, so make sure we have a producer id
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
transactionManager.transitionToFatalError(new KafkaException("The client hasn't received acknowledgment for " +
"some previously sent messages and can no longer retry them. It isn't safe to continue."));
} else if (transactionManager.hasInFlightTransactionalRequest() || maybeSendTransactionalRequest(now)) {
// as long as there are outstanding transactional requests, we simply wait for them to return
client.poll(retryBackoffMs, now);
return;
}
// do not continue sending if the transaction manager is in a failed state or if there
// is no producer id (for the idempotent case).
if (transactionManager.hasFatalError() || !transactionManager.hasProducerId()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, now);
return;
} else if (transactionManager.hasAbortableError()) {
accumulator.abortUndrainedBatches(transactionManager.lastError());
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request: {}", e);
transactionManager.authenticationFailed(e);
}
}
//note: 如果有 partition 可以立马发送数据,那么 pollTimeout 为0.
long pollTimeout = sendProducerData(now);
//note: 如果有 partition 可以立马发送数据,那么 pollTimeout 为0.
//note: Step5 关于 socket 的一些实际的读写操作
client.poll(pollTimeout, now);
}
最主要的两个方法是sender#sendProducerData(long now);与NetworkClient#poll(long timeout, long now)
我们进入sender#sendProducerData(long now)方法中看一下
5.4 sender#sendProducerData(long now)
private long sendProducerData(long now) {
// 获取 kafka 集群信息
Cluster cluster = metadata.fetch();
//note: Step1 获取那些已经可以发送的 RecordBatch 对应的 nodes
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//note: Step2 如果有 topic-partition 的 leader 是未知的,就强制 metadata 更新
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
//note: 遍历处理待发送请求的目标节点,基于网络 IO 检查对应节点是否可用,对于不可用的节点则剔除
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) { //note: 没有建立连接的 broker,这里会与其建立连接
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
//note: Step3 返回该 node 对应的所有可以发送的 RecordBatch 组成的 batches(key 是 node.id,这些 batches 将会在一个 request 中发送)
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
//note: 保证一个 tp 只有一个 RecordBatch 在发送,保证有序性
//note: max.in.flight.requests.per.connection 设置为1时会保证
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
//note:Step4 将由于元数据不可用而导致发送超时的 RecordBatch,或者获取超时的batch数据
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(this.requestTimeout, now);
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
//note:Step5 将由于元数据不可用而导致发送超时的 RecordBatch 移除
failBatch(expiredBatch, -1, NO_TIMESTAMP, expiredBatch.timeoutException(), false);
if (transactionManager != null && expiredBatch.inRetry()) {
// This ensures that no new batches are drained until the current in flight batches are fully resolved.
transactionManager.markSequenceUnresolved(expiredBatch.topicPartition);
}
}
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
pollTimeout = 0;
}
//note: Step6 发送 RecordBatch
sendProduceRequests(batches, now);
return pollTimeout;
}
sendProduceRequests() 的大概流程总共有以下几步:
accumulator.ready():遍历所有的 tp(topic-partition),如果其对应的 RecordBatch 可以发送(大小达到batch.size大小或时间达到linger.ms),就将其对应的 leader 选出来,最后会返回一个可以发送 Produce request 的Set<Node>(实际返回的是ReadyCheckResult实例,不过Set<Node>是最主要的成员变量);- 如果发现有 tp 没有 leader,那么这里就调用
requestUpdate()方法更新 metadata,实际上还是在第一步对 tp 的遍历中,遇到没有 leader 的 tp 就将其加入到一个叫做unknownLeaderTopics的 set 中,然后会请求这个 tp 的 meta accumulator.drain():遍历每个 leader (第一步中选出)上的所有 tp,如果该 tp 对应的 RecordBatch 不在 backoff 期间(没有重试过,或者重试了但是间隔已经达到了 retryBackoffMs ),并且加上这个 RecordBatch 其大小不超过 maxSize(一个 request 的最大限制,默认为 1MB),那么就把这个 RecordBatch 添加 list 中,最终返回的类型为Map<Integer, List<RecordBatch>>,key 为 leader.id,value 为要发送的 RecordBatch 的列表;abortExpiredBatches:获取超时的producerBatchfailBatch:处理失败的批次sendProduceRequests:发送批次
我们一次查看每个方法的具体是做什么的。
5.4.1 RecordAccumulator#ready
ready() 是在 Sender 线程中调用的,其作用选择那些可以发送的 node,也就是说,如果这个 tp 对应的 batch 可以发送(达到时间或大小要求),就把 tp 对应的 leader 选出来。
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
// 用于记录接收请求的节点
Set<Node> readyNodes = new HashSet<>();
// 记录下次执行 ready 判断的时间间隔
long nextReadyCheckDelayMs = Long.MAX_VALUE;
// 记录找不到 leader 副本的分区对应的 topic 集合
Set<String> unknownLeaderTopics = new HashSet<>();
// 是否有线程在等待 BufferPool 分配空间
boolean exhausted = this.free.queued() > 0;
// 遍历每个 topic 分区及其 RecordBatch 队列,对每个分区的 leader 副本所在的节点执行判定
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<RecordBatch> deque = entry.getValue();
// 获取当前 topic 分区 leader 副本所在的节点
Node leader = cluster.leaderFor(part);
synchronized (deque) {
// 当前分区 leader 副本未知,但存在发往该分区的消息
if (leader == null && !deque.isEmpty()) {
unknownLeaderTopics.add(part.topic());
}
// 如果需要保证消息顺序性,则不应该存在多个发往该 leader 副本节点且未完成的消息
else if (!readyNodes.contains(leader) && !muted.contains(part)) {
RecordBatch batch = deque.peekFirst();
if (batch != null) {
// 当前为重试操作,且重试时间间隔未达到阈值时间
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
long waitedTimeMs = nowMs - batch.lastAttemptMs; // 重试等待的时间
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
boolean full = deque.size() > 1 || batch.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
// 标记当前节点是否可以接收请求
boolean sendable = full // 1. 队列中有多个 RecordBatch,或第一个 RecordBatch 已满
|| expired // 2. 当前等待重试的时间过长
|| exhausted // 3. 有其他线程在等待 BufferPool 分配空间,即本地消息缓存已满
|| closed // 4. producer 已经关闭
|| flushInProgress(); // 5. 有线程正在等待 flush 操作完成
if (sendable && !backingOff) {
// 允许发送消息,且当前为首次发送,或者重试等待时间已经较长,则记录目标 leader 副本所在节点
readyNodes.add(leader);
} else {
// 更新下次执行 ready 判定的时间间隔
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
// 封装结果返回
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
整个计算的逻辑就是遍历我们之前缓存到收集器 RecordAccumulator 中的消息集合,并按照下面 5 个条件进行判定,如果满足其中一个则认为需要往目标节点投递消息:
- 当前 topic 名下的消息队列持有多个 RecordBatch,或者第 1 个 RecordBatch 已满。
- 当前 topic 分区等待重试的时间过长,如果是首次发送则无需校验重试等待时间。
- 当前 topic 分区下有其他线程在等待 BufferPool 分配空间,即本地缓存已满。
- Producer 被关闭,需要立即投递剩余未完成的消息。
- 有线程正在等待 flush 操作完成,则需要立即投递消息,避免线程等待时间过长。
如果遍历过程中发现某个 topic 分区对应的 Leader 副本所在节点失效(对应的 topic 分区正在执行 Leader 副本选举,或者对应的 topic 已经失效),但是本地又缓存了发往该分区的消息,则需要标记当前本地缓存的集群元数据需要更新。上面获取目标 broker 节点的过程是站在收集器 RecordAccumulator 的角度看的,对于一个节点是否可用,还需要从网络 I/O 的角度检查其连通性,这也是this.client.ready(node, now) 所要做的工作,这一步基于 KafkaClient#ready 方法检查目标节点的是否连通,如果目标节点并未准备好接收请求,则需要从待请求节点集合中剔除。
5.4.2 RecordAccumulator#drain
drain() 是用来遍历可发送请求的 node,然后再遍历在这个 node 上所有 tp,如果 tp 对应的 deque 有数据,将会被选择出来直到超过一个请求的最大长度(max.request.size)为止,也就说说即使 RecordBatch 没有达到条件,但为了保证每个 request 尽快多地发送数据提高发送效率,这个 RecordBatch 依然会被提前选出来并进行发送。
public Map<Integer, List<RecordBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) {
if (nodes.isEmpty()) {
return Collections.emptyMap();
}
// 记录转换后的结果,key 是目标节点 ID
Map<Integer, List<RecordBatch>> batches = new HashMap<>();
for (Node node : nodes) {
int size = 0;
// 获取当前节点上的分区信息
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
// 记录待发往当前节点的 RecordBatch 集合
List<RecordBatch> ready = new ArrayList<>();
/*
* drainIndex 用于记录上次发送停止的位置,本次继续从当前位置开始发送,
* 如果每次都是从 0 位置开始,可能会导致排在后面的分区饿死,可以看做是一个简单的负载均衡策略
*/
int start = drainIndex = drainIndex % parts.size();
do {
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
// 如果需要保证消息强顺序性,则不应该同时存在多个发往目标分区的消息
if (!muted.contains(tp)) {
// 获取当前分区对应的 RecordBatch 集合
Deque<RecordBatch> deque = this.getDeque(new TopicPartition(part.topic(), part.partition()));
if (deque != null) {
synchronized (deque) {
RecordBatch first = deque.peekFirst();
if (first != null) {
// 重试 && 重试时间间隔未达到阈值时间
boolean backoff = first.attempts > 0 && first.lastAttemptMs + retryBackoffMs > now;
// 仅发送第一次发送,或重试等待时间较长的消息
if (!backoff) {
if (size + first.sizeInBytes() > maxSize && !ready.isEmpty()) {
// 单次消息数据量已达到上限,结束循环,一般对应一个请求的大小,防止请求消息过大
break;
} else {
// 每次仅获取第一个 RecordBatch,并放入 read 列表中,这样给每个分区一个机会,保证公平,防止饥饿
RecordBatch batch = deque.pollFirst();
// 将当前 RecordBatch 设置为只读
batch.close();
size += batch.sizeInBytes();
ready.add(batch);
batch.drainedMs = now;
}
}
}
}
}
}
// 更新 drainIndex
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex);
batches.put(node.id(), ready);
}
return batches;
}
上述方法的返回类型是 Map<Integer, List>,其中 key 是目标节点的 ID,value 是本次待发往该节点的消息集合。为了防止饥饿,方法会轮询从当前 topic 的每个分区队列对头取数据,并记录每次轮询的偏移量,下次轮询即从该偏移量位置开始,以保证尽量的公平。
5.4.3 RecordAccumulator#abortExpiredBatches
abortExpiredBatches是判断RecordBatch消息是否超时,并返回将超时的RecordBatch列表
public List<RecordBatch> abortExpiredBatches(int requestTimeout, long now) {
List<RecordBatch> expiredBatches = new ArrayList<>();
int count = 0;
/**
* 遍历batchs里面的所有partition
*/
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
Deque<RecordBatch> dq = entry.getValue();
TopicPartition tp = entry.getKey();
// We only check if the batch should be expired if the partition does not have a batch in flight.
// This is to prevent later batches from being expired while an earlier batch is still in progress.
// Note that `muted` is only ever populated if `max.in.flight.request.per.connection=1` so this protection
// is only active in this case. Otherwise the expiration order is not guaranteed.
if (!muted.contains(tp)) {
synchronized (dq) {
// iterate over the batches and expire them if they have been in the accumulator for more than requestTimeOut
RecordBatch lastBatch = dq.peekLast();
//获取partition队列里面的所有batch
Iterator<RecordBatch> batchIterator = dq.iterator();
//遍历每个batch
while (batchIterator.hasNext()) {
RecordBatch batch = batchIterator.next();
boolean isFull = batch != lastBatch || batch.records.isFull();
// TODO 对每个batch检测是否超时
if (batch.maybeExpire(requestTimeout, retryBackoffMs, now, this.lingerMs, isFull)) {
//把超时的batch添加到超时的数据结构作为返回值返回去。
expiredBatches.add(batch);
count++;
batchIterator.remove();
//如果超时了释放内存
deallocate(batch);
} else {
// Stop at the first batch that has not expired.
break;
}
}
}
}
}
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", count);
return expiredBatches;
}
我们重点看一下判断是否超时的方法:
/**
* 这个方法是判断batch是否超时的
* @param requestTimeoutMs 超时的时间,默认是30秒
* @param retryBackoffMs
* @param now
* @param lingerMs
* @param isFull
* @return
*/
public boolean maybeExpire(int requestTimeoutMs, long retryBackoffMs, long now, long lingerMs, boolean isFull) {
boolean expire = false;
String errorMessage = null;
/**
* (1)如果当前时间 减去 这个批次加入队列的时候已经超过30秒了,那么就已经超时了。
*/
if (!this.inRetry() && isFull && requestTimeoutMs < (now - this.lastAppendTime)) {
expire = true;
errorMessage = (now - this.lastAppendTime) + " ms has passed since last append";
/**
* (2)当前时间减去创建批次的时间和批次应该发送的时间间隔大于30秒
* 那么说明已经超时了
*/
} else if (!this.inRetry() && requestTimeoutMs < (now - (this.createdMs + lingerMs))) {
expire = true;
errorMessage = (now - (this.createdMs + lingerMs)) + " ms has passed since batch creation plus linger time";
/**
* (3)如果当前batch是重试的,并且当前时间减去上一次重试的时间和重试时间间隔 大于30秒
* 那么说明已经超时了。
*/
} else if (this.inRetry() && requestTimeoutMs < (now - (this.lastAttemptMs + retryBackoffMs))) {
expire = true;
errorMessage = (now - (this.lastAttemptMs + retryBackoffMs)) + " ms has passed since last attempt plus backoff time";
}
boolean expired = expiryErrorMessage != null;
if (expired)
abortRecordAppends();
return expired;
}
那我们获取到了超时的producerBatch后,在expiredBatches方法后会进行处理
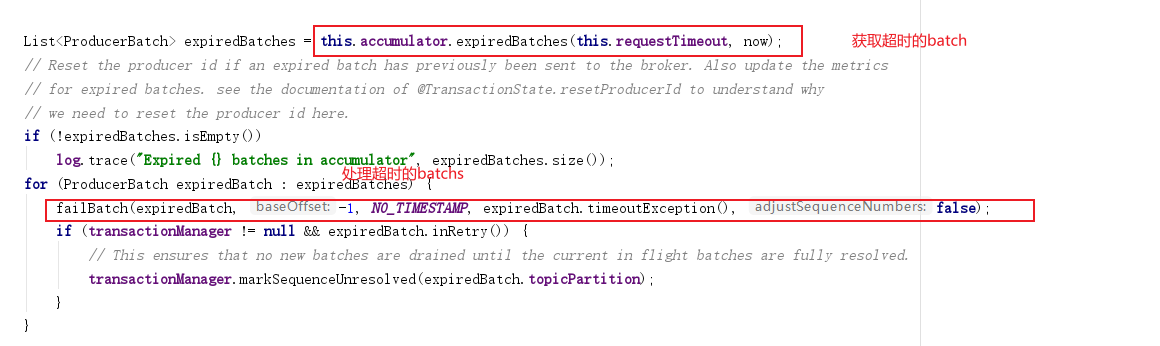
我们看下failBatch方法
5.4.4 Sender#failBatch
private void failBatch(ProducerBatch batch, long baseOffset, long logAppendTime, RuntimeException exception, boolean adjustSequenceNumbers) {
...
...
this.sensors.recordErrors(batch.topicPartition.topic(), batch.recordCount);
//处理batch
if (batch.done(baseOffset, logAppendTime, exception))
//释放空间
this.accumulator.deallocate(batch);
}
我们看下Producer#done方法
public boolean done(long baseOffset, long logAppendTime, RuntimeException exception) {
final FinalState finalState;
if (exception == null) {
log.trace("Successfully produced messages to {} with base offset {}.", topicPartition, baseOffset);
finalState = FinalState.SUCCEEDED;
} else {
log.trace("Failed to produce messages to {}.", topicPartition, exception);
finalState = FinalState.FAILED;
}
if (!this.finalState.compareAndSet(null, finalState)) {
if (this.finalState.get() == FinalState.ABORTED) {
log.debug("ProduceResponse returned for {} after batch had already been aborted.", topicPartition);
return false;
} else {
throw new IllegalStateException("Batch has already been completed in final state " + this.finalState.get());
}
}
//处理回调
completeFutureAndFireCallbacks(baseOffset, logAppendTime, exception);
return true;
}
我们再进去看下ProducerBatch#completeFutureAndFireCallbacks方法
public void completeFutureAndFireCallbacks(long baseOffset, long timestamp, RuntimeException exception) {
log.trace("Produced messages to topic-partition {} with base offset offset {} and error: {}.",
topicPartition,
baseOffset,
exception);
// execute callbacks
//一个thunks就代表一个消息
for (int i = 0; i < this.thunks.size(); i++) {
try {
Thunk thunk = this.thunks.get(i);
if (exception == null) {
// If the timestamp returned by server is NoTimestamp, that means CreateTime is used. Otherwise LogAppendTime is used.
RecordMetadata metadata = new RecordMetadata(this.topicPartition, baseOffset, thunk.future.relativeOffset(),
timestamp == Record.NO_TIMESTAMP ? thunk.future.timestamp() : timestamp,
thunk.future.checksum(),
thunk.future.serializedKeySize(),
thunk.future.serializedValueSize());
//TODO 调用每个消息的回调函数
//这儿的这个回调函数就是我们写代码的时候自己设置的那个回调函数。
thunk.callback.onCompletion(metadata, null);
} else {
//如果响应里有异常,那么就把异常也传给回调函数。
thunk.callback.onCompletion(null, exception);
}
} catch (Exception e) {
log.error("Error executing user-provided callback on message for topic-partition {}:", topicPartition, e);
}
}
this.produceFuture.done(topicPartition, baseOffset, exception);
}
综上所述,我们发现如果KafkaProducer端检测到batchs超时了,那么就会释放对应内存,最终也会调用消息的回调函数,把超时异常带过去。
5.4.5 Sender#sendProduceRequests
此处是消息发送过程,看代码
private void sendProduceRequests(Map<Integer, List<RecordBatch>> collated, long now) {
// 遍历处理待发送消息集合,key 是目标节点 ID
for (Map.Entry<Integer, List<RecordBatch>> entry : collated.entrySet())
this.sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
if (batches.isEmpty())
return;
遍历 RecordBatch 集合,整理成 produceRecordsByPartition 和 recordsByPartition
Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());
final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
byte minUsedMagic = apiVersions.maxUsableProduceMagic();
for (ProducerBatch batch : batches) {
if (batch.magic() < minUsedMagic)
minUsedMagic = batch.magic();
}
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
produceRecordsByPartition.put(tp, records);
recordsByPartition.put(tp, batch);
}
String transactionalId = null;
if (transactionManager != null && transactionManager.isTransactional()) {
transactionalId = transactionManager.transactionalId();
}
// 创建 ProduceRequest 请求构造器
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
produceRecordsByPartition, transactionalId);
// 当客户端请求完成后, 会触发回调函数的执行!!!!!!!!!!!!!!!!
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
// 创建 ClientRequest 请求对象,如果 acks 不等于 0 则表示期望获取服务端响应
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
// 缓存 ClientRequest 请求对象到 InFlightRequests 中
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
由上可知传递给requtestBuilder的参数produceRecordsByPartition已经时Map<TopicPartition, MemoryRecords>。MemoryRecords对象最重要的成员变量为ByteBuffer,保存该RecordBatch内的所有消息。
下面我们来看下client.send方法
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
...
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
String nodeId = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
if (log.isDebugEnabled()) {
int latestClientVersion = clientRequest.apiKey().latestVersion();
if (header.apiVersion() == latestClientVersion) {
log.trace("Sending {} {} with correlation id {} to node {}", clientRequest.apiKey(), request,
clientRequest.correlationId(), nodeId);
} else {
log.debug("Using older server API v{} to send {} {} with correlation id {} to node {}",
header.apiVersion(), clientRequest.apiKey(), request, clientRequest.correlationId(), nodeId);
}
}
// Send是一个接口,这里返回的是NetworkSend,而NetworkSend继承ByteBufferSend
Send send = request.toSend(nodeId, header);
// 表示正在发送的请求
InFlightRequest inFlightRequest = new InFlightRequest(
header,
clientRequest.createdTimeMs(),
clientRequest.destination(),
clientRequest.callback(),
clientRequest.expectResponse(),
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
// 将send和对应kafkaChannel绑定起来,并开启该kafkaChannel底层socket的写事件
selector.send(inFlightRequest.send);
}
doSend方法内部先是将clientRequest转换为ProduceRequest,然后调用ProduceRequest.toSend方法将消息封装成NetworkSend类型,该类型继承ByteBufferSend,最主要成员有一个size=2的ByteBuffer数组,第一个ByteBuffer存储所有消息的size,另一个ByteBuffer存储所有消息。
在发送请求之前需要把该请求添加到inFlightRequests队列中,表示正在发送还没收到ack的请求,当收到kafka server的ack之后,kafka producer将该消息从inFlightRequest中删除。(成功与失败都会在inFlightRequest中将消息删除)
最后调用selector.send(inFlightRequest.send)将该NetworkSend与KafkaChannel绑定起来,并为KafkaChannel底层的socket开启可写事件。下面来看下selector#send方法
//将RequestSend对象缓存到KafkaChannel的send字段中
public void setSend(Send send) {
//如果此KafkaChannel的send字段上还保存这一个未完全发送成功的RequestSend请求,为了防止覆盖数据,则会抛出异常
//也就是说,每个KafkaChannel一次poll过程中只能发送一个Send请求
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
this.send = send;
//并开始关注OP_WRITE事件
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
//实际去发送数据
private boolean send(Send send) throws IOException {
//如果send在一次write调用时没有发送完,SelectionKey的OP_WRITE事件没有取消,
//还会继续监听此Channel的OP_WRITE事件,直到整个send请求发送完毕才取消
send.writeTo(transportLayer);
//判断是否完成是通过ByteBuffer中是否还有剩余自己来判断的
if (send.completed())
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
以上是sendProduceRequests()六步主要过程
当以上步骤的执行结束时,接下来即可返回到sender线程类的run()方法的sendProduceRequests(batches, now)方法,该方法执行结束,此时为每个broker的kafkaChannel都绑定了各自的NetworkSend。最后调用this.client.poll(pollTimeout, now);方法将消息发送出去。
现在对于客户端而言,连接、读、写事件都有了(CONNECT、READ、WRITE)。在selector的轮询中可以操作读写事件。

下面我们看下NetworkClient#poll(long timeout, long now)
5.5 NetworkClient#poll(long timeout, long now)
public List<ClientResponse> poll(long timeout, long now) {
if (!abortedSends.isEmpty()) {
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
/*
* 如果距离上次更新超过指定时间,且存在负载小的目标节点,
* 则创建 MetadataRequest 请求更新本地缓存的集群元数据信息,并在下次执行 poll 操作时一并送出
*/
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
/* 发送网络请求 */
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
/* 处理服务端响应 */
long updatedNow = this.time.milliseconds();
// 响应队列
List<ClientResponse> responses = new ArrayList<>();
// 对于发送成功且不期望服务端响应的请求,创建本地的响应对象添加到 responses 队列中
handleCompletedSends(responses, updatedNow);
// 处理那些从 Server 端接收的 Receive,metadata 更新就是在这里处理的
handleCompletedReceives(responses, updatedNow);
// 处理连接断开的请求,构建对应的 ClientResponse 添加到 responses 列表中,并标记需要更新集群元数据信息
handleDisconnections(responses, updatedNow);
// 处理 connections 列表,更新相应节点的连接状态
handleConnections();
// 如果需要更新本地的 API 版本信息,则创建对应的 ApiVersionsRequest 请求,并在下次执行 poll 操作时一并送出
handleInitiateApiVersionRequests(updatedNow);
// 遍历获取 inFlightRequests 中的超时请求,构建对应的 ClientResponse 添加到 responses 列表中,并标记需要更新集群元数据信息
handleTimedOutRequests(responses, updatedNow);
// 本质上就是在调用注册的 RequestCompletionHandler#onComplete 方法
completeResponses(responses);
return responses;
}
这个方法大致分为三步,这里详述讲述一下:
metadataUpdater.maybeUpdate():如果 Metadata 需要更新,那么就选择连接数最小的 node,发送 Metadata 请求,详细流程可以参考之前Metadata更新流程selector.poll():进行 socket IO 相关的操作,下面会详细讲述;process completed actions:在一个select()过程之后的相关处理。handleCompletedSends(responses, updatedNow):处理那些已经完成的 request,如果是那些不需要 response 的 request 的话,这里直接调用request.completed(),标志着这个 request 发送处理完成;handleCompletedReceives(responses, updatedNow):处理那些从 Server 端接收的 Receive,metadata 更新就是在这里处理的(以及ApiVersionsResponse);handleDisconnections(responses, updatedNow):处理连接失败那些连接,重新请求 metadata;handleConnections():处理新建立的那些连接(还不能发送请求,比如:还未认证);handleInitiateApiVersionRequests(updatedNow):对那些新建立的连接,发送 apiVersionRequest(默认情况:第一次建立连接时,需要向 Broker 发送ApiVersionRequest请求);handleTimedOutRequests(responses, updatedNow):处理 timeout 的连接,关闭该连接,并刷新 Metadata。completeResponses(responses):本质上就是在调用注册的RequestCompletionHandler#onComplete方法
5.5.1 DefaultMetadataUpdater#maybeUpdate
首先来看更新本地缓存的集群元数据信息的过程,前面曾多次提及到更新集群元数据的场景,而这些更新操作实际上都是标记集群元数据需要更新,真正执行更新的操作则发生在这里。前面已经分析过了,此处不做赘述
5.5.2 Selector#poll
Selector 类是 Kafka 对 Java NIO 相关接口的封装,socket IO 相关的操作都是这个类中完成的,这里先看一下 poll() 方法,主要的操作都是这个方法中调用的,其代码实现如下:
public void poll(long timeout) throws IOException {
if (timeout < 0)
throw new IllegalArgumentException("timeout should be >= 0");
//note: Step1 清除相关记录
clear();
if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty())
timeout = 0;
/* check ready keys */
//note: Step2 获取就绪事件的数
long startSelect = time.nanoseconds();
int readyKeys = select(timeout);
long endSelect = time.nanoseconds();
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
//note: Step3 处理 io 操作
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
//note: Step4 将处理得到的 stagedReceives 添加到 completedReceives 中
addToCompletedReceives();
long endIo = time.nanoseconds();
this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());
// we use the time at the end of select to ensure that we don't close any connections that
// have just been processed in pollSelectionKeys
//note: 每次 poll 之后会调用一次
//TODO: 连接虽然关闭了,但是 Client 端的缓存依然存在
maybeCloseOldestConnection(endSelect);
}
Selector.poll() 方法会进行四步操作,这里分别来介绍一些。
步骤一:clear()
clear() 方法是在每次 poll() 执行的第一步,它作用的就是清理上一次 poll 过程产生的部分缓存。
//note: 每次 poll 调用前都会清除以下缓存
private void clear() {
this.completedSends.clear();
this.completedReceives.clear();
this.connected.clear();
this.disconnected.clear();
// Remove closed channels after all their staged receives have been processed or if a send was requested
for (Iterator<Map.Entry<String, KafkaChannel>> it = closingChannels.entrySet().iterator(); it.hasNext(); ) {
KafkaChannel channel = it.next().getValue();
Deque<NetworkReceive> deque = this.stagedReceives.get(channel);
boolean sendFailed = failedSends.remove(channel.id());
if (deque == null || deque.isEmpty() || sendFailed) {
doClose(channel, true);
it.remove();
}
}
this.disconnected.addAll(this.failedSends);
this.failedSends.clear();
}
步骤二:select()
Selector 的 select() 方法在实现上底层还是调用 Java NIO 原生的接口,这里的 nioSelector 其实就是 java.nio.channels.Selector 的实例对象,这个方法最坏情况下,会阻塞 ms 的时间,如果在一次轮询,只要有一个 Channel 的事件就绪,它就会立马返回。
private int select(long ms) throws IOException {
if (ms < 0L)
throw new IllegalArgumentException("timeout should be >= 0");
if (ms == 0L)
return this.nioSelector.selectNow();
else
return this.nioSelector.select(ms);
}
步骤三:pollSelectionKeys()
这部分是 socket IO 的主要部分,发送 Send 及接收 Receive 都是在这里完成的,在 poll() 方法中,这个方法会调用两次:
- 第一次调用的目的是:处理已经就绪的事件,进行相应的 IO 操作;
- 第二次调用的目的是:处理新建立的那些连接,添加缓存及传输层(Kafka 又封装了一次)的握手与认证。
//处理I/O操作的核心方法,会处理OP_CONNECT,OP_READ,OP_WRITE事件,并且会检测连接
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
//之前创建连接时,将KafkaChannel注册到Key上,就是为了在这里获取
KafkaChannel channel = channel(key);
// register all per-connection metrics at once
sensors.maybeRegisterConnectionMetrics(channel.id());
if (idleExpiryManager != null)
idleExpiryManager.update(channel.id(), currentTimeNanos);
try {
/* complete any connections that have finished their handshake (either normally or immediately) */
//note: 处理一些刚建立 tcp 连接的 channel。对connect方法返回true或OP_CONNECTION事件的处理
if (isImmediatelyConnected || key.isConnectable()) {
//finishConnect方法会先检测socketChannel是否建立完成,建立后,会取消对OP_CONNECT事件关注,开始关注OP_READ事件
if (channel.finishConnect()) {//note: 连接已经建立
//添加到"已连接"的集合中
this.connected.add(channel.id());
this.sensors.connectionCreated.record();
SocketChannel socketChannel = (SocketChannel) key.channel();
log.debug("Created socket with SO_RCVBUF = {}, SO_SNDBUF = {}, SO_TIMEOUT = {} to node {}",
socketChannel.socket().getReceiveBufferSize(),
socketChannel.socket().getSendBufferSize(),
socketChannel.socket().getSoTimeout(),
channel.id());
} else
//连接未完成,则跳过对此Channel的后续处理
continue;
}
/* if channel is not ready finish prepare */
//note: 处理 tcp 连接还未完成的连接,进行传输层的握手及认证
if (channel.isConnected() && !channel.ready())
channel.prepare();
/* if channel is ready read from any connections that have readable data */
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
//OP_READ事件处理
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null)//note: 知道读取一个完整的 Receive,才添加到集合中
//上面channel.read()读取到一个完整的NetworkReceive,则将其添加到stagedReceives中保存
//若读取不到一个完成的NetworkReceive,则返回null,下次处理OP_READ事件时,继续读取,直至读取到一个完整的NetworkReceive
addToStagedReceives(channel, networkReceive);//note: 读取数据
}
/* if channel is ready write to any sockets that have space in their buffer and for which we have data */
//OP_WRITE
if (channel.ready() && key.isWritable()) {
Send send = channel.write();
//上面的channel.write()方法将KafkaChannel.send字段发送出去,如果未完成发送,则返回null,如果发送完成,则返回send
//并添加到completeSends集合中,待后续处理
if (send != null) {
this.completedSends.add(send);//note: 将完成的 send 添加到 list 中
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
/* cancel any defunct sockets */
//note: 取消任何已经废止的scokets
if (!key.isValid())
close(channel, true);
} catch (Exception e) {
//抛出异常,则认为连接关闭,将对应NodeId添加到disconnected集合
String desc = channel.socketDescription();
if (e instanceof IOException)
log.debug("Connection with {} disconnected", desc, e);
else
log.warn("Unexpected error from {}; closing connection", desc, e);
close(channel, true);
}
}
}
addToCompletedReceives()
这个方法的目的是处理接收到的 Receive,由于 Selector 这个类在 Client 和 Server 端都会调用,这里分两种情况讲述一下:
- 应用在 Server 端时,这里简单说一下,Server 为了保证消息的时序性,在 Selector 中提供了两个方法:
mute(String id)和unmute(String id),对该 KafkaChannel 做标记来保证同时只能处理这个 Channel 的一个 request(可以理解为排它锁)。当 Server 端接收到 request 后,先将其放入stagedReceives集合中,此时该 Channel 还未 mute,这个 Receive 会被放入completedReceives集合中。Server 在对completedReceives集合中的 request 进行处理时,会先对该 Channel mute,处理后的 response 发送完成后再对该 Channel unmute,然后才能处理该 Channel 其他的请求; - 应用在 Client 端时,Client 并不会调用 Selector 的
mute()和unmute()方法,client 的时序性而是通过InFlightRequests和RecordAccumulator的mutePartition来保证的(下篇文章会讲述),因此对于 Client 端而言,这里接收到的所有 Receive 都会被放入到completedReceives的集合中等待后续处理。
这个方法只有配合 Server 端的调用才能看明白其作用,它统一 Client 和 Server 调用的 api,使得都可以使用 Selector 这个类。
/**
* checks if there are any staged receives and adds to completedReceives
*/
// 只有在本次轮询中没有读操作了(也没有写了), 在退出轮询时, 将上一步的所有NetworkReceive加到completedReceives
private void addToCompletedReceives() {
if (!this.stagedReceives.isEmpty()) {//note: 处理 stagedReceives
Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this.stagedReceives.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next();
KafkaChannel channel = entry.getKey();
if (!channel.isMute()) {// 当前通道上没有OP_READ事件时
Deque<NetworkReceive> deque = entry.getValue();
addToCompletedReceives(channel, deque);
if (deque.isEmpty())
iter.remove();
}
}
}
}
private void addToCompletedReceives(KafkaChannel channel, Deque<NetworkReceive> stagedDeque) {
NetworkReceive networkReceive = stagedDeque.poll();
this.completedReceives.add(networkReceive); //note: 添加到 completedReceives 中
this.sensors.recordBytesReceived(channel.id(), networkReceive.payload().limit());
}
5.5.3 process completed actions
重点看下handle*()方法的处理逻辑
1)handleCompletedSends(): 我们都知道InFlightRequests中保存的已经发送但是还没有收到响应的请求,CompleteSends保存的是最近一次poll()方法中发送成功的请求,所以CompleteSends列表与InFlightRequests队列中的最后一个请求应该是一致的。
那么这个方法具体是做啥的?答案就是会遍历CompleteSends,把不需要响应的请求从InFlightRequests中去除掉,并向response列表中添加对应的ClientResponse,在ClientResponse中包含一个指向ClientRequest的引用。源码如下
private void handleCompletedSends(List<ClientResponse> responses, long now) {
// if no response is expected then when the send is completed, return it
//遍历completedSends集合
for (Send send : this.selector.completedSends()) {
//获取指定队列的第一个元素
ClientRequest request = this.inFlightRequests.lastSent(send.destination());
//检测请求是否需要响应
if (!request.expectResponse()) {
//将inFlightRequests中对应队列中的第一个请求删除
this.inFlightRequests.completeLastSent(send.destination());
//生成ClientResponse对象,添加到response集合
responses.add(new ClientResponse(request, now, false, null));
}
}
}
2)handleCompletedReceives(): 收到响应是在handleCompletedReceives,这时候才可以调用completeNext删除source对应的ClientRequest,因为我们知道inFlightRequests存的是未收到请求的ClientRequest,现在这个请求已经有响应了,就不需要再其中保存了。
问:inFlightRequests在这里的作用是什么?首先每个节点都有一个正在进行中的请求队列,可以防止请求堆积(流控?)。当请求发送成功,还没有收到响应(对于需要响应的客户端请求而言)的这段时间里,ClientRequest是处于in-flight状态的。同时每个节点的队列有个限制条件是:上一个请求没有发送完毕,下一个请求不能进来。或者队列中的未完成的请求数很多时都会限制。
不需要响应的流程:开始发送请求->添加到inFlightRequests-> 发送请求… ->请求发送成功->从inFlightRequests删除请求
需要响应的流程:开始发送请求->添加到inFlightRequests->发送请求…->请求发送成功->等待接收响应->接收到响应->删除请求
private void handleCompletedReceives(List<ClientResponse> responses, long now) {
//遍历completedReceives
for (NetworkReceive receive : this.selector.completedReceives()) {
//获取返回响应的nodeId
String source = receive.source();
// 接收到完整的响应了, 现在可以删除inFlightRequests中的ClientRequest了.
ClientRequest req = inFlightRequests.completeNext(source);
//解析响应
Struct body = parseResponse(receive.payload(), req.request().header());
//如果是Metadata更新请求的响应
// 那么调用MetadataUpdater.maybeHandleCompleltedReceive()方法处理
// MetadataResponse,其中会更新Metadata中记录的集群元数据,并唤醒所有等待Metadata 更新完成的线程
if (!metadataUpdater.maybeHandleCompletedReceive(req, now, body))
//如果不是MetadataResponse,则创建ClientResponse并添加到responses集合
responses.add(new ClientResponse(req, now, false, body));
}
}
3)handleDisconnections(): 处理已经断开的节点的数据,遍历disconnections列表,将InFlightRequests对应节点的数据清空,并为每个请求都创建ClientResponse添加到response列表中,这里创建ClientResponse会标识为因为连接断开而产生的。源码如下
private void handleDisconnections(List<ClientResponse> responses, long now) {
//更新连接状态,并清理掉InFlightRequests中断开连接的Node对应的ClientRequest
for (String node : this.selector.disconnected()) {
log.debug("Node {} disconnected.", node);
processDisconnection(responses, node, now);
}
// we got a disconnect so we should probably refresh our metadata and see if that broker is dead
if (this.selector.disconnected().size() > 0)
//标识需要更新集群元数据
metadataUpdater.requestUpdate();
}
/** * Post process disconnection of a node * * @param responses The list of responses to update * @param nodeId Id of the node to be disconnected * @param now The current time */
/**
* Post process disconnection of a node
*
* @param responses The list of responses to update
* @param nodeId Id of the node to be disconnected
* @param now The current time
*/
private void processDisconnection(List<ClientResponse> responses, String nodeId, long now) {
connectionStates.disconnected(nodeId, now);//更新连接状态
for (ClientRequest request : this.inFlightRequests.clearAll(nodeId)) {
//调用MetadataUpdater.maybeHandleDisconnection()方法处理MetadataRequest
log.trace("Cancelled request {} due to node {} being disconnected", request, nodeId);
//如果不是MetadataRequest,则创建ClientResponse并添加到responses集合
//注意第三个参数,表示连接是否断开
if (!metadataUpdater.maybeHandleDisconnection(request))
responses.add(new ClientResponse(request, now, true, null));
}
}
4)handleConnections(): 处理连接的节点数据,遍历Connected列表,将ConnectionStates中记录的连接的状态修改为CONNECTED。
5)handleTimedOutRequests(): 处理超时的数据,遍历InFlightRequests队列,获取有超时请求的Node集合,之后处理逻辑与handleDisconnections方法一样。
6)响应处理方法Sender.handleProduceResponse()
经过一系列的handle*()方法后,NetworkClient.poll()方法产生的全部ClientResponse已经被收集到response列表中。之后遍历responses调用每个ClientResponse的回调方法,如果是异常响应,则请求重发,如果是正常响应则调用每个消息自定义的Callback,也就是RequestCompletionHandler对象,其中onComplete()方法最终调用Sender.handleProcudeResponse()方法。
1)断开连接或异常而产生的响应:
遍历ClientRequest中的RecordBatch,尝试将RecordBatch重新加入RecordAccumulator,重新发送。
如果异常类型不允许重试或重试次数达到上限,就执行RecordBatch.done()方法,这个方法会循环调用RecordBatch中每个消息的Callback函数,并将RecordBatch的produceFuture设置为“异常完成”。最后,释放RecordBatch底层的ByteBuffer。
最后,根据异常的类型,决定是否设置更新Metadata标志。
2)服务器正常的响应以及不需要相应的情况:
1.解析响应。
2.遍历对应ClientRequest中的RecordBatch,执行RecordBatch.done()方法。
3.释放RecordBatch底层的ByteBuffer。
源码如下:
private void completeResponses(List<ClientResponse> responses) {
for (ClientResponse response : responses) {
try {
//此处调用的onComplete(),其实调用的是RequestCompletionHandler的回调放啊
response.onComplete();
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
//----------------------------------------------------------------------------
//此方法在之前说过
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
...
...
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
produceRecordsByPartition, transactionalId);
//调用的其实此处里面的onComplete回调方法
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
//----------------------------------------------------------------------------
/**
* Handle a produce response
*/
private void handleProduceResponse(ClientResponse response, Map<TopicPartition, RecordBatch> batches, long now) {
int correlationId = response.request().request().header().correlationId();
/*
对于连接断开而产生的ClientResponse,会重试发送请求,
如果不能重试,则调用其中每条消息回调。
*/
if (response.wasDisconnected()) {
log.trace("Cancelled request {} due to node {} being disconnected", response, response.request()
.request()
.destination());
for (RecordBatch batch : batches.values())
completeBatch(batch, Errors.NETWORK_EXCEPTION, -1L, Record.NO_TIMESTAMP, correlationId, now);
} else {//正常响应
log.trace("Received produce response from node {} with correlation id {}",
response.request().request().destination(),
correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
ProduceResponse produceResponse = new ProduceResponse(response.responseBody());
for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
Errors error = Errors.forCode(partResp.errorCode);
RecordBatch batch = batches.get(tp);
//调用completeBatch()方法处理
completeBatch(batch, error, partResp.baseOffset, partResp.timestamp, correlationId, now);
}
this.sensors.recordLatency(response.request().request().destination(), response.requestLatencyMs());
this.sensors.recordThrottleTime(response.request().request().destination(),
produceResponse.getThrottleTime());
} else {//不需要响应的请求,直接调用completeBatch()方法。
// this is the acks = 0 case, just complete all requests
for (RecordBatch batch : batches.values())
completeBatch(batch, Errors.NONE, -1L, Record.NO_TIMESTAMP, correlationId, now);
}
}
}
/**
* Complete or retry the given batch of records.
*
* @param batch The record batch
* @param error The error (or null if none)
* @param baseOffset The base offset assigned to the records if successful
* @param timestamp The timestamp returned by the broker for this batch
* @param correlationId The correlation id for the request
* @param now The current POSIX time stamp in milliseconds
*/
private void completeBatch(RecordBatch batch, Errors error, long baseOffset, long timestamp, long correlationId, long now) {
// 异常响应,但是允许重试
if (error != Errors.NONE && canRetry(batch, error)) {
// retry
log.warn("Got error produce response with correlation id {} on topic-partition {}, retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts - 1,
error);
//对于可重试的RecordBatch,则重新添加到RecordAccumulator中,等待发送
this.accumulator.reenqueue(batch, now);
this.sensors.recordRetries(batch.topicPartition.topic(), batch.recordCount);
// 正常响应,或不允许重试的异常
} else {
//不能重试,将RecordBatch标记为"异常完成",并释放RecordBatch
RuntimeException exception;
if (error == Errors.TOPIC_AUTHORIZATION_FAILED)
exception = new TopicAuthorizationException(batch.topicPartition.topic());
else
exception = error.exception();
// tell the user the result of their request
//!!! 将响应信息传递给用户,并释放 RecordBatch 占用的空间 !!!!调用producer.send中的回调函数(用户自定义回调函数)
batch.done(baseOffset, timestamp, exception);
this.accumulator.deallocate(batch);//释放空间
if (error != Errors.NONE)
this.sensors.recordErrors(batch.topicPartition.topic(), batch.recordCount);
}
// 如果是集群元数据异常,则标记需要更新集群元数据信息
if (error.exception() instanceof InvalidMetadataException)
metadata.requestUpdate();//表示需要更新Metadata中记录的集群元数据
// 释放已经处理完成的 topic 分区,对于需要保证消息强顺序性,以允许接收下一条消息
if (guaranteeMessageOrder)
this.accumulator.unmutePartition(batch.topicPartition);
}
上述方法会判断当前响应是否异常且可以需要重试,如果是则将 RecordBatch 重新添加到收集器 RecordAccumulator 中,等待再次发送。如果是正常响应或不允许重试,则调用 RecordBatch#done 方法结束本次发送消息的过程,并将响应结果传递给用户,同时释放 RecordBatch 占用的空间。下面来看一下方法 RecordBatch#done 的实现:
public void done(long baseOffset, long logAppendTime, RuntimeException exception) {
log.trace("Produced messages to topic-partition {} with base offset offset {} and error: {}.", topicPartition, baseOffset, exception);
// 标识当前 RecordBatch 已经处理完成
if (completed.getAndSet(true)) {
throw new IllegalStateException("Batch has already been completed");
}
// 设置当前 RecordBatch 发送之后的状态
produceFuture.set(baseOffset, logAppendTime, exception);
// 循环执行每个消息的 Callback 回调
for (Thunk thunk : thunks) {
try {
// 消息处理正常
if (exception == null) {
// RecordMetadata 是服务端返回的
RecordMetadata metadata = thunk.future.value();
//!!!!!调用用户自定义发送完成后的send方法中的回调函数
thunk.callback.onCompletion(metadata, null);
}
// 消息处理异常
else {
thunk.callback.onCompletion(null, exception);
}
} catch (Exception e) {
log.error("Error executing user-provided callback on message for topic-partition '{}'", topicPartition, e);
}
}
// 标记本次请求已经完成(正常响应、超时,以及关闭生产者)
produceFuture.done();
}
前面我们曾分析过在消息追加成功之后,如果在发送消息时指定了 Callback 回调函数,会将其封装成 Thunk 类对象,当时我们猜测 Sender 线程在向集群投递完消息并收到来自集群的响应时会循环遍历 thunks 集合,并应用 Callback 相应的回调方法,而上述方法的实现证实了我们的猜想。
方法中的变量 produceFuture 是一个 ProduceRequestResult 类型的对象,用于表示一次消息生产过程是否完成,该类基于 CountDownLatch 实现了类似 Future 的功能,在构造 ProduceRequestResult 对象时会创建一个大小为 1 的 CountDownLatch 对象,并在调用 ProduceRequestResult#done 方法时执行 CountDownLatch#countDown 操作,而 ProduceRequestResult#completed 方法判定消息发送是否完成的依据就是判定CountDownLatch 对象值是否等于 0。