Ceph存储架构
Ceph 存储集群由几个不同的daemon组成,每个daemon负责Ceph 的一个独特功能并。每个守护进程是彼此独立的。

下面将简要介绍每个Ceph组件的功能:
RADOS(Reliable Autonomic Distributed Object Store, RADOS)
RADOS是Ceph 存储集群的基础。Ceph 中的一切都以对象的形式存储,而RADOS 就负责存储这些对象,而不考虑它们的数据类型。RADOS 层确保数据一致性和可靠性。对于数据一致性,它执行数据复制、故障检测和恢复。还包括数据在集群节点间的recovery。
OSD
实际存储数据的进程。通常一个OSD daemon绑定一个物理磁盘。Client write/read 数据最终都会走到OSD去执行write/read操作。
MON(monitor)
Monitor在Ceph集群中扮演者管理者的角色,维护了整个集群的状态,是Ceph集群中最重要的组件。
Mon保证集群的相关组件在同一时刻能够达成一致,相当于集群的领导层,负责收集、更新和发布集群信息。为了规避单点故障,在实际的Ceph部署环境中会部署多个Mon,同样会引来多个Mon之前如何协同工作的问题。在一个标准的Ceph环境中,Monitor的功能可以分为以下两点
管好自己
多个monitor之间如何协同工作,怎么同步数据;
管理集群信息
数据的存储,保证数据存储的正确性等等。
Librados
简化访问RADOS的一种方法,目前支持PHP、Ruby、Java、Python、C和C++语言。它提供了Ceph 存储集群的一个本地接口RADOS ,并且是其他服务(如RBD 、RGW) 的基础,以及为CephFS 提供POSIX 接口。librados API 支持直接访问RADOS ,使得开发者能够创建自己的接口来访问Ceph 集群存储。
RBD
Ceph块设备。对外提供块存储。可以像磁盘一样被映射、格式化已经挂载到服务器上。支持snapshot。
RGW
Ceph对象网关,提供了一个兼容S3和Swift的restful API接口。RGW还支持多租户和Openstack的keyston身份验证服务。
MDS
Ceph元数据服务器,跟踪文件层次结构并存储只供CephFS使用的元数据。Ceph块设备和RADOS网关不需要元数据。MDS不直接给client提供数据服务。
CephFS
提供了一个任意大小且兼容POSlX的分布式文件系统。CephFS 依赖Ceph MDS 来跟踪文件层次结构,即元数据。
Ceph RADOS
RADOS 是Ceph 存储系统的核心,也称为Ceph 存储集群。Ceph 的所有优秀特性都是由RADOS 提供的,包括分布式对象存储、高可用性、高可靠性、没有单点故障、向我修复以及自我管理等。RADOS 层在Ceph 存储架构中扮演着举足轻重的角色。Ceph 的数据访问方法(如RBD 、CephFS 、RADOS GW 和librados ) 的所有操作都是在RADOS 层之上构建的。
当Ceph 集群接收到来向客户端的写请求时,CRUSH 算法首先计算出存储位置,以此决定应该将数据写入什么地方。然后这些信息传递到队DOS 层进行进一步处理。基于CRUSH 规则集,RADOS 以小对象的形式将数据分发到集群内的所有节点。最后,将这些对象存储在OSD 中。
当配置的复制数大于1时,队DOS 负责数据的可靠性。同时,它复制对象,创建副本,并将它们存储在不同的故障区域中,换言之,同一个对象的副本不会存放在同一个故障区域中。然而,如果有更多个性化需求和更高的可靠性,就需要根据实际需求和基础架构来优化CRUSH 规则集。RADOS 能够保证在一个RADOS 集群中的对象副本总是不少于一个,只要你有足够的设备。
除了跨集群存储和复制对象之外,RADOS 也确保对象状态的一致性。在对象不一致的情况下,将会利用剩下的副本执行恢复操作。这个操作自动执行,对于用户而言是透明的,从而为Ceph 提供了自我管理和自我修复的能力。如果仔细分析Ceph 的架构图,你会发现它有两部分: RADOS 在最下部,它完全处于Ceph集群的内部,没有提供给客户端直接接口;另一部分就是在RADOS 之上的面向所有客户端的接口。
Ceph 对象存储设备
Ceph 的OSD 是Ceph 存储集群中最重要的一个基础组件,它负责将实际的数据以对象的形式存储在每一个集群节点的物理磁盘驱动器中。Ceph 集群中的大部分工作是由OSD 守护进程完成的。存储用户数据是真正最耗时的部分。
Ceph OSD 以对象的形式存储所有客户端数据,并在客户端发起数据请求时提供相同的数据。Ceph 集群包含多个OSD 。对于任何读或写操作,客户端首先向monitor 请求集群的map ,然后,它们就可以无须monitor 的干预直接与OSD 进行I/O操作也正是因为产生数据的客户端能够直接写入存储数据的OSD 而没有任何额外的数据处理层,才使得数据事务处理速度如此之快。与其他存储解决方案相比,这种类型的数据存储和取回机制是Ceph 所独有的。
Ceph 的核心特性(比如可靠性、自平衡、自恢复和一致性)都始于OSD 。根据配置的副本数, Ceph通过跨集群节点复制每个对象多次来提供可靠性,同时使其具有高可用性容错性。OSD 上的每个对象都有一个主副本和几个辅副本,辅副本分散在其他OSD 上。由于Ceph 是一个分布式系统且对象分布在多个OSD 上,因此每一个OSD 对于一些对象而言是主副本。但同时对于其他对象而言就是辅副本,存放辅副本的OSD 受主副本OSD 控制;然而,它们也可能又成为主副本OSD 。
Ceph的OSD由一个已经存在Linux 文件系统的物理磁盘驱动器和10SD 服务组成。
Linux文件系统对于OSD 守护进程而言是相当重要的,因为它决定了支持哪些扩展属性( XATTR) 。这些文件系统扩展属性能够为OSD 守护进程提供内部对象的状态、快照、元数据和ACL 等信息.这有助于数据管理。
OSD在拥有有效Linux 分区的物理磁盘驱动器上进行操作。Linux 分区可以是Btrfs (B树文件系统)、XFS 或ext4。Ceph 集群的性能基准测试的主要标准之一就是文件系统的选择。
- Btrfs
与使用XFS 和ext4 文件系统的OSD 相比,使用Btrfs 文件系统的OSD 能够提供更佳的性能。使用Btrfs 最主要的一个优点是支持写时复制和可写的快照,这对于虑拟机的部署和克隆非常有用。在文件系统中它还支持透明的压缩、普遍的校验和多设备的统一管理。还支持高效的XATTR 、对于小文件的合井,还有SSD上所熟知的集成卷管理,并支持在线fsck 的特性。然而,尽管有如此多的新特性,Btrfs 目前还不具备应用于生产系统的条件,但对于测试而言它是一个很好的选择。
- XFS
这是一个可靠、成熟且非常稳定的文件系统,因此,我们推荐在生产环境的Ceph 集群中使用它。XFS 是Ceph存储中最常用的文件系统.也是推荐OSD 使用的文件系统。然而,从另一个方面来看,XFS 又不如Btrfs。XFS 在元数据扩展性上存在性能问题,XFS 也是一种日志文件系统, 也就是说.每次客户端发送数据以写入Ceph 集群时,肯先需要写人口志空间,然后再写入XFS 文件系统这样的两次写入操作增加了开销从而使得XFS 的性能不如Btrfs,Btrfs 没有使用日志。
- Ext4
ext4 文件系统也是一种日志文件系统,是一个远合生产环境下Ceph OSD 使用的文件系统;然而,它的受欢迎程度不如XFS 。从性能的角度来看,ext4 文件系统也不如Btrfs。
Ceph OSD 使用诸如Btrfs 和XFS 的日志文件系统。在将数据提交到备用存储之前,Ceph 首先将数据写入一个称为日志( journal) 的独立存储区域,日志是相同的机械磁盘(如OSD) 或不同的SSD 磁盘或分区上一小块缓冲区大小的分区,甚至也可以是文件系统上的一个文件。在这种机制中,Ceph 的所有写都是先到日志,然后再到备用存储,如下图所示。

Ceph Monitor
顾名思义,Ceph monitor 负责监控整个集群的健康状况。它们以守护进程的形式存在,这些守护进程通过存储集群的关键信息来维护集群成员状态、对等节点状态,以及集群配置信息。Ceph monitor 通过维护整个集群状态的主副本来完成它的任务。集群map 包括monitor 、OSD 、PG 、CRUSH 和MDS map o 所有这些map 统称为集群map 。让我们简单地浏览一下每个map 的功能。
- monitor map
它维护着monitor 节点间端到端的信息,其中包括Ceph 集群ID 、monitor 主机名、IP 地址及端口号。它还存储着当前map 的创建版本和最后一次修改的信息。可以通过下面的命令检查集群的monitor map:
# ceph mon dump
- OSD map :
它存储着一些常见的信息,如集群ID、OSD map 创建版本和最后一次修改信息,以及与池相关的信息(如池名字、池ID 、类型、副本数和归置组) 。它还存储着OSD 的一些信息,如数目、状态、权重、最近处于clean 状态的间隔以及OSD 主机等信息。可以通过执行以下命令获取集群的OSD map:
# ceph osd dump
PG map :
它存储着归置组的版本、时间戳、最新的OSD map 版本、容量充满的比例以及容量接近充满的比例等信息。它同时也跟踪每个归置组的ID 、对象数、状态状态时间戳、OSD 的叩集合、OSD 的acting 集合,最后还有清洗等信息。要检查集群的PG map ,执行:
# ceph pg dump
- CRUSH map:
它存储着集群的存储设备信息、故障域层次结构以及在故障域中定义如何存储数据的规则。要查看集群的CRUSH map ,执行:
# ceph osd crush dump
- MDS map:
它存储着当前MDS map 的版本,map 的创建和修改时间,数据和元数据池的ID ,集群中MDS 的数目以及MDS 的状态。要查看集群MDS map ,执行:
# ceph mds dump
一个典型的Ceph 集群通常包含多个monitor 节点。多monitor 的Ceph 架构使用了仲
裁( quorum ) ,使用Paxos 算法为集群提供了分布式决策机制。集群中monitor 数目应该是奇数,最低要求是一个monitor 节点,推荐的数是3 。自monitor开始仲裁操作,至少需要保证一半以上的monitor 始终处于可用状态,这样才可以防止其他系统可以看到的脑裂问题。
这就是为什么推荐使用奇数个monitor。在所有的集群monitor 巾,其中有一个是领导者( leader ) 。如果领导者monitor不可用其他monitor 节点也有权成为领导者。生产环境下的集群必须至少有三个monitor节点来提供高可用性。
对于企业级生产环境,建议使用专门的monitor 节点。这样, 一旦你的OSD 节点发生
故障,只要你有足够的monitor 运行在独立的机器上,你仍然可以连接到你的Ceph 集群。在存储的规划阶段,也应该考虑物理机架的布局。你应该将monitor节点分散到所有的故障域中,例如,不同的开关、电源和物理机架。如果你有多个数据中心连接在同一个高速网络,monitor 节点应该放到不同的数据中心。
Ceph块存储
块存储是企业环境中最常见的一种数据存储格式。Ceph 块设备也称为RADOS 块设备(RBD) ;它为物理层的虚拟机监控程序以及虚拟机提供块存储解决方案。Ceph 的RBD 驱动程序已经被集成到Linux 内核( 2.6.39 或更高版本)中,而且已经被QEMU/KVM 支持,它们能无缝地访问Ceph 块设备。
Linux主机能全力支持内核RBD (KRB D ) 并通过librados 映射Ceph 块设备。然后RADOS将Ceph 块设备的对象以分布式模式存储在集群中。一旦Ceph 块设备映射到Linux主机,它也可以当作裸分区或标记为文件系统,然后进行挂载。
Ceph对象网关
Ceph 对象网关,也称做RADOS 网关,它是一个代理,可以将HTTP 请求转换为RADOS ,同时也可以把RADOS 请求转换为HTTP 请求,从而提供RESTful 对象存储,这兼容S3 和Swift。Ceph 对象存储使用Ceph 对象网关守护进程( radosgw) 与librgw 、librados (Ceph 集群)交互。这是使用libfcgi 作为FastCGI的一个模块来实现的,并且可以被任何支持FastCGl的Web 服务器使用。

Ceph文件系统
CephFS 在RADOS 层之上提供了一个兼容POSIX 的文件系统。它使用MDS 作为守护进程,负责管理其元数据并将它和其他数据分开,这有助于降低复杂性并提高可靠性。CephFS 继承了RADOS 的特性并为数据提供了动态再平衡。
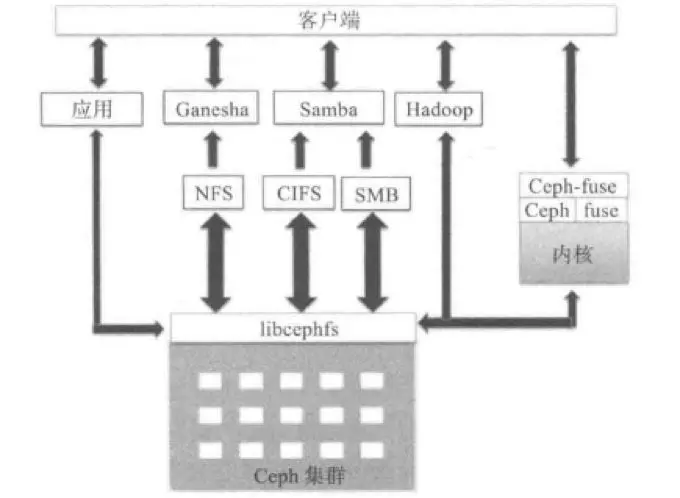
以上是对Ceph的架构和组件做了一些介绍,后续我们将对里面的技术细节进行详细的讨论。









![[深度学习]1. 深度学习知识点汇总](https://img-blog.csdnimg.cn/img_convert/8a62ee9560cf63bbf0142864b909766f.png)