笔记上部分请看【Datawhale】AI夏令营第三期——基于论文摘要的文本分类笔记(上)
文章目录
- 一、深度学习Topline
- 1.1 数据预处理
- 1.2 模型训练
- 1.3 评估模型
- 1.4 测试集推理
- 1.5 后续改进
- 二、大模型Topline
- 2.1 大模型介绍
- 2.2 大模型是什么?
- 2.3 大模型的原理
- 2.4 大模型可以做什么?
- 2.5 大模型是如何训练的?
- 2.6 Prompt
- 2.7 大模型微调介绍
- 2.7.1 什么是大模型微调
- 2.7.2 微调方法介绍
- 2.7.3 大模型微调都可以做什么呢?
- 2.8 建立数据集
- 2.9 微调,跑起来!(code)
一、深度学习Topline
Topline方法:预训练微调+特征融合+后处理
若是追求高分数,可以优先考虑模型集成的方法。 在代码中,我们提供了一个模型集成的整体流程框架,可以直接训练并推理多个模型的~
但实际上,只需将单个模型进行微调便能达到满分的表现。
与常规的预训练模型接分类器不同,Topline对网络结构进行了更进一步的改进,具体细节如下:
在模型结构上使用了以下两个特征:
①特征1:MeanPooling(768维) -> fc(128维)
②特征2:Last_hidden (768维) -> fc(128维)
其中,特征1指的是将Roberta所输出的全部序列分词的表征向量先进行一个平均池化再接一个全连接层(fc,Fully Connected Layer);特征2指的是将Roberta的pooled_output接一个全连接层(fc,Fully Connected Layer)。(pooled_output = [CLS]的表征向量接入一个全连接层,再输入至Tanh激活函数)。
然后,将这两个特征进行加权并相加即可输进分类器进行训练。(在代码中,仅是将它们进行等权相加。后续当然也可以尝试分配不同的权重,看能否获得更好的性能)(Dropout层其实并不是一个必要项,可加可不加~)。
最后,将训练好的模型用于推理测试集,并根据标签数目的反馈,对预测阈值进行调整。(后处理)。

在代码部分中,主要分为四个模块:1.数据处理 2.模型训练 3.模型评估 4.测试集推理
以下是代码文件的目录结构:
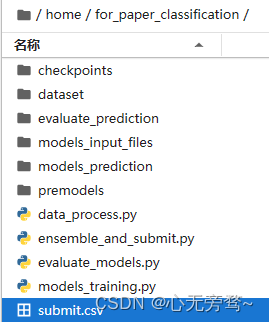

1.1 数据预处理
from transformers import AutoTokenizer # 导入AutoTokenizer类,用于文本分词
import pandas as pd # 导入pandas库,用于处理数据表格
import numpy as np # 导入numpy库,用于科学计算
from tqdm import tqdm # 导入tqdm库,用于显示进度条
import torch # 导入torch库,用于深度学习任务
from torch.nn.utils.rnn import pad_sequence # 导入pad_sequence函数,用于填充序列,保证向量中各序列维度的大小一样
MAX_LENGTH = 128 # 定义最大序列长度为128
def get_train(model_name, model_dict):
model_index = model_dict[model_name] # 获取模型索引
train = pd.read_csv('./dataset/train.csv') # 从CSV文件中读取训练数据
train['content'] = train['title'] + train['author'] + train['abstract'] # 将标题、作者和摘要拼接为训练内容
tokenizer = AutoTokenizer.from_pretrained(model_name, max_length=MAX_LENGTH, cache_dir=f'./premodels/{model_name}_saved') # 实例化分词器对象
# 通过分词器对训练数据进行分词,并获取输入ID、注意力掩码和标记类型ID(这个可有可无)
input_ids_list, attention_mask_list, token_type_ids_list = [], [], []
y_train = [] # 存储训练数据的标签
for i in tqdm(range(len(train['content']))): # 遍历训练数据
sample = train['content'][i] # 获取样本内容
tokenized = tokenizer(sample, truncation='longest_first') # 分词处理,使用最长优先方式截断
input_ids, attention_mask = tokenized['input_ids'], tokenized['attention_mask'] # 获取输入ID和注意力掩码
input_ids, attention_mask = torch.tensor(input_ids), torch.tensor(attention_mask) # 转换为PyTorch张量
try:
token_type_ids = tokenized['token_type_ids'] # 获取标记类型ID
token_type_ids = torch.tensor(token_type_ids) # 转换为PyTorch张量
except:
token_type_ids = input_ids
input_ids_list.append(input_ids) # 将输入ID添加到列表中
attention_mask_list.append(attention_mask) # 将注意力掩码添加到列表中
token_type_ids_list.append(token_type_ids) # 将标记类型ID添加到列表中
y_train.append(train['label'][i]) # 将训练数据的标签添加到列表中
# 保存
input_ids_tensor = pad_sequence(input_ids_list, batch_first=True, padding_value=0) # 对输入ID进行填充,保证向量中各序列维度的大小一样,生成张量
attention_mask_tensor = pad_sequence(attention_mask_list, batch_first=True, padding_value=0) # 对注意力掩码进行填充,保证向量中各序列维度的大小一样,生成张量
token_type_ids_tensor = pad_sequence(token_type_ids_list, batch_first=True, padding_value=0) # 对标记类型ID进行填充,保证向量中各序列维度的大小一样,生成张量
x_train = torch.stack([input_ids_tensor, attention_mask_tensor, token_type_ids_tensor], dim=1) # 将输入张量堆叠为一个张量
x_train = x_train.numpy() # 转换为NumPy数组
np.save(f'./models_input_files/x_train{model_index}.npy', x_train) # 保存训练数据
y_train = np.array(y_train) # 将标签列表转换为NumPy数组
np.save(f'./models_input_files/y_train{model_index}.npy', y_train) # 保存标签数据
def get_test(model_name, model_dict):
model_index = model_dict[model_name] # 获取模型索引
test = pd.read_csv('./dataset/testB.csv') # 从CSV文件中读取测试数据
test['content'] = test['title'] + ' ' + test['author'] + ' ' + test['abstract'] # 将标题、作者和摘要拼接为测试内容
tokenizer = AutoTokenizer.from_pretrained(model_name, max_length=MAX_LENGTH,cache_dir=f'./premodels/{model_name}_saved') # 实例化分词器对象
# 通过分词器对测试数据进行分词,并获取输入ID、注意力掩码和标记类型ID(可有可无)
input_ids_list, attention_mask_list, token_type_ids_list = [], [], []
for i in tqdm(range(len(test['content']))): # 遍历测试数据
sample = test['content'][i] # 获取样本内容
tokenized = tokenizer(sample, truncation='longest_first') # 分词处理,使用最长优先方式截断
input_ids, attention_mask = tokenized['input_ids'], tokenized['attention_mask'] # 获取输入ID和注意力掩码
input_ids, attention_mask = torch.tensor(input_ids), torch.tensor(attention_mask) # 转换为PyTorch张量
try:
token_type_ids = tokenized['token_type_ids'] # 获取标记类型ID
token_type_ids = torch.tensor(token_type_ids) # 转换为PyTorch张量
except:
token_type_ids = input_ids
input_ids_list.append(input_ids) # 将输入ID添加到列表中
attention_mask_list.append(attention_mask) # 将注意力掩码添加到列表中
token_type_ids_list.append(token_type_ids) # 将标记类型ID添加到列表中
# 保存
input_ids_tensor = pad_sequence(input_ids_list, batch_first=True, padding_value=0) # 对输入ID进行填充,保证向量中各序列维度的大小一样,生成张量
attention_mask_tensor = pad_sequence(attention_mask_list, batch_first=True, padding_value=0) # 对注意力掩码进行填充,保证向量中各序列维度的大小一样,生成张量
token_type_ids_tensor = pad_sequence(token_type_ids_list, batch_first=True, padding_value=0) # 对标记类型ID进行填充,保证向量中各序列维度的大小一样,生成张量
x_test = torch.stack([input_ids_tensor, attention_mask_tensor, token_type_ids_tensor], dim=1) # 将输入张量堆叠为一个张量
x_test = x_test.numpy() # 转换为NumPy数组
np.save(f'./models_input_files/x_test{model_index}.npy', x_test) # 保存测试数据
def split_train(model_name, model_dict):
# 处理样本内容
model_index = model_dict[model_name] # 获取模型索引
train = np.load(f'./models_input_files/x_train{model_index}.npy') # 加载训练数据
state = np.random.get_state() # 获取随机数状态,保证样本间的随机是可重复的
np.random.shuffle(train) # 随机打乱训练数据
# 训练集:验证集 = 9 : 1
val = train[int(train.shape[0] * 0.90):] # 划分验证集
train = train[:int(train.shape[0] * 0.90)] # 划分训练集
np.save(f'./models_input_files/x_train{model_index}.npy', train) # 保存训练集
np.save(f'./models_input_files/x_val{model_index}.npy', val) # 保存验证集
train = np.load(f'./models_input_files/y_train{model_index}.npy') # 加载标签数据
# 处理样本标签
np.random.set_state(state) # 恢复随机数状态,让样本标签的随机可重复
np.random.shuffle(train) # 随机打乱标签数据
# 训练集:验证集 = 9 : 1
val = train[int(train.shape[0] * 0.90):] # 划分验证集
train = train[:int(train.shape[0] * 0.90)] # 划分训练集
np.save(f'./models_input_files/y_train{model_index}.npy', train) # 保存训练集标签
np.save(f'./models_input_files/y_val{model_index}.npy', val) # 保存验证集标签
print('split done.')
if __name__ == '__main__':
model_dict = {'xlm-roberta-base':1, 'roberta-base':2, 'bert-base-uncased':3,
'microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext':4, 'dmis-lab/biobert-base-cased-v1.2':5, 'marieke93/MiniLM-evidence-types':6,
'microsoft/MiniLM-L12-H384-uncased':7, 'cambridgeltl/SapBERT-from-PubMedBERT-fulltext':8,'microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract':9,
'microsoft/BiomedNLP-PubMedBERT-large-uncased-abstract':10}
model_name = 'roberta-base'
get_train(model_name, model_dict)
get_test(model_name, model_dict)
split_train(model_name, model_dict)
1.2 模型训练
# 导入需要的库
import numpy as np # 导入numpy库,用于科学计算
import torch # 导入torch库,用于深度学习任务
import torch.nn as nn # 导入torch.nn模块,用于神经网络相关操作
from sklearn import metrics # 导入sklearn库,用于评估指标计算
import os # 导入os库,用于操作系统相关功能
import time # 导入time库,用于时间相关操作
from transformers import AutoModel, AutoConfig # 导入AutoModel和AutoConfig类,用于加载预训练模型
from tqdm import tqdm # 导入tqdm库,用于显示进度条
# 超参数类 - 可修改的所有超参数都在这里~
class opt:
seed = 42 # 随机种子
batch_size = 16 # 批处理大小
set_epoch = 5 # 训练轮数
early_stop = 5 # 提前停止epoch数
learning_rate = 1e-5 # 学习率
weight_decay = 2e-6 # 权重衰减,L2正则化
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 选择设备,GPU或CPU
gpu_num = 1 # GPU个数
use_BCE = False # 是否使用BCE损失函数
models = ['xlm-roberta-base', 'roberta-base', 'bert-base-uncased',
'microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext', 'dmis-lab/biobert-base-cased-v1.2', 'marieke93/MiniLM-evidence-types',
'microsoft/MiniLM-L12-H384-uncased','cambridgeltl/SapBERT-from-PubMedBERT-fulltext', 'microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract',
'microsoft/BiomedNLP-PubMedBERT-large-uncased-abstract'] # 模型名称列表
model_index = 2 # 根据上面选择使用的模型,这里填对应的模型索引
model_name = models[model_index-1] # 使用的模型名称
continue_train = False # 是否继续训练
show_val = False # 是否显示验证过程
# 定义模型
class MODEL(nn.Module):
def __init__(self, model_index):
super(MODEL, self).__init__()
# 若是第一次下载权重,则下载至同级目录的./premodels/内,以防占主目录的存储空间
self.model = AutoModel.from_pretrained(opt.models[model_index-1], cache_dir='./premodels/'+opt.models[model_index-1]+'_saved', from_tf=False) # 加载预训练语言模型
# 加载模型配置,可以直接获得模型最后一层的维度,而不需要手动修改
config = AutoConfig.from_pretrained(opt.models[model_index-1], cache_dir='./premodels/'+opt.models[model_index-1]+'_saved') # 获取配置
last_dim = config.hidden_size # 最后一层的维度
if opt.use_BCE:out_size = 1 # 损失函数如果使用BCE,则输出大小为1
else :out_size = 2 # 否则则使用CE,输出大小为2
feature_size = 128 # 设置特征的维度大小
self.fc1 = nn.Linear(last_dim, feature_size) # 全连接层1
self.fc2 = nn.Linear(last_dim, feature_size) # 全连接层2
self.classifier = nn.Linear(feature_size, out_size) # 分类器
self.dropout = nn.Dropout(0.3) # Dropout层
def forward(self, x):
input_ids, attention_mask, token_type_ids = x[:,0],x[:,1],x[:,2] # 获取输入
x = self.model(input_ids, attention_mask) # 通过模型
all_token = x[0] # 全部序列分词的表征向量
pooled_output = x[1] # [CLS]的表征向量+一个全连接层+Tanh激活函数
feature1 = all_token.mean(dim=1) # 对全部序列分词的表征向量取均值
feature1 = self.fc1(feature1) # 再输入进全连接层,得到feature1
feature2 = pooled_output # [CLS]的表征向量+一个全连接层+Tanh激活函数
feature2 = self.fc2(feature2) # 再输入进全连接层,得到feature2
feature = 0.5*feature1 + 0.5*feature2 # 加权融合特征
feature = self.dropout(feature) # Dropout
x = self.classifier(feature) # 分类
return x
# 数据加载
def load_data():
train_data_path = f'models_input_files/x_train{model_index}.npy' # 训练集输入路径
train_label_path = f'models_input_files/y_train{model_index}.npy' # 训练集标签路径
val_data_path = f'models_input_files/x_val{model_index}.npy' # 验证集输入路径
val_label_path = f'models_input_files/y_val{model_index}.npy' # 验证集标签路径
test_data_path = f'models_input_files/x_test{model_index}.npy' # 测试集输入路径
train_data = torch.tensor(np.load(train_data_path , allow_pickle=True).tolist()) # 载入训练集数据
train_label = torch.tensor(np.load(train_label_path , allow_pickle=True).tolist()).long() # 载入训练集标签
val_data = torch.tensor(np.load(val_data_path , allow_pickle=True).tolist()) # 载入验证集数据
val_label = torch.tensor(np.load(val_label_path , allow_pickle=True).tolist()).long() # 载入验证集标签
test_data = torch.tensor(np.load(test_data_path , allow_pickle=True).tolist()) # 载入测试集数据
train_dataset = torch.utils.data.TensorDataset(train_data , train_label) # 构造训练集Dataset
val_dataset = torch.utils.data.TensorDataset(val_data , val_label) # 构造验证集Dataset
test_dataset = torch.utils.data.TensorDataset(test_data) # 构造测试集Dataset
return train_dataset, val_dataset, test_dataset # 返回数据集
# 模型预训练
def model_pretrain(model_index, train_loader, val_loader):
# 超参数设置
set_epoch = opt.set_epoch # 训练轮数
early_stop = opt.early_stop # 提前停止epoch数
learning_rate = opt.learning_rate # 学习率
weight_decay = opt.weight_decay # 权重衰减
device = opt.device # 设备
gpu_num = opt.gpu_num # GPU个数
continue_train = opt.continue_train # 是否继续训练
model_save_dir = 'checkpoints' # 模型保存路径
# 是否要继续训练,若是,则加载模型进行训练;若否,则跳过训练,直接对测试集进行推理
if not continue_train:
# 判断最佳模型是否已经存在,若存在则直接读取,若不存在则进行训练
if os.path.exists(f'checkpoints/best_model{model_index}.pth'):
best_model = MODEL(model_index)
best_model.load_state_dict(torch.load(f'checkpoints/best_model{model_index}.pth')) # 加载模型
return best_model
else:
pass
# 模型初始化
model = MODEL(model_index).to(device)
if continue_train:
model.load_state_dict(torch.load(f'checkpoints/best_model{model_index}.pth')) # 继续训练加载模型
# 优化器初始化
if device != 'cpu' and gpu_num > 1: # 多张显卡
optimizer = torch.optim.AdamW(model.module.parameters(), lr=learning_rate, weight_decay=weight_decay)
optimizer = torch.nn.DataParallel(optimizer, device_ids=list(range(gpu_num))) # 多GPU
else: # 单张显卡
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) # 单GPU
# 损失函数初始化
if opt.use_BCE:
loss_func = nn.BCEWithLogitsLoss() # BCE损失
else:
loss_func = nn.CrossEntropyLoss() # 交叉熵损失(CE)
# 模型训练
best_epoch = 0 # 最佳epoch
best_train_loss = 100000 # 最佳训练损失
train_acc_list = [] # 训练准确率列表
train_loss_list = [] # 训练损失列表
val_acc_list = [] # 验证准确率列表
val_loss_list = [] # 验证损失列表
start_time = time.time() # 训练开始时间
for epoch in range(set_epoch): # 轮数
model.train() # 模型切换到训练模式
train_loss = 0 # 训练损失
train_acc = 0 # 训练准确率
for x, y in tqdm(train_loader): # 遍历训练集
# 训练前先将数据放到GPU上
x = x.to(device)
y = y.to(device)
outputs = model(x) # 前向传播
if opt.use_BCE: # BCE损失
loss = loss_func(outputs, y.float().unsqueeze(1))
else: # 交叉熵损失
loss = loss_func(outputs, y)
train_loss += loss.item() # 累加训练损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
if device != 'cpu' and gpu_num > 1: # 多GPU更新
optimizer.module.step()
else:
optimizer.step() # 单GPU更新
if not opt.use_BCE: # 非BCE损失
_, predicted = torch.max(outputs.data, 1) # 预测结果
else:
predicted = (outputs > 0.5).int() # 预测结果
predicted = predicted.squeeze(1)
train_acc += (predicted == y).sum().item() # 计算训练准确率
average_mode = 'binary'
train_f1 = metrics.f1_score(y.cpu(), predicted.cpu(), average=average_mode) # 计算F1
train_pre = metrics.precision_score(y.cpu(), predicted.cpu(), average=average_mode) # 计算精确率
train_recall = metrics.recall_score(y.cpu(), predicted.cpu(), average=average_mode) # 计算召回率
train_loss /= len(train_loader) # 平均所有步数的训练损失作为一个epoch的训练损失
train_acc /= len(train_loader.dataset) # 平均所有步数训练准确率作为一个epoch的准确率
train_acc_list.append(train_acc) # 添加训练准确率
train_loss_list.append(train_loss) # 添加训练损失
print('-'*50)
print('Epoch [{}/{}]\n Train Loss: {:.4f}, Train Acc: {:.4f}'.format(epoch + 1, set_epoch, train_loss, train_acc))
print('Train-f1: {:.4f}, Train-precision: {:.4f} Train-recall: {:.4f}'.format(train_f1, train_pre, train_recall))
if opt.show_val: # 显示验证过程
# 验证
model.eval() # 模型切换到评估模式
val_loss = 0 # 验证损失
val_acc = 0 # 验证准确率
for x, y in tqdm(val_loader): # 遍历验证集
# 训练前先将数据放到GPU上
x = x.to(device)
y = y.to(device)
outputs = model(x) # 前向传播
if opt.use_BCE: # BCE损失
loss = loss_func(outputs, y.float().unsqueeze(1))
else: # 交叉熵损失
loss = loss_func(outputs, y)
val_loss += loss.item() # 累加验证损失
if not opt.use_BCE: # 非BCE损失
_, predicted = torch.max(outputs.data, 1)
else:
predicted = (outputs > 0.5).int() # 预测结果
predicted = predicted.squeeze(1)
val_acc += (predicted == y).sum().item() # 计算验证准确率
val_f1 = metrics.f1_score(y.cpu(), predicted.cpu(), average=average_mode) # 计算F1
val_pre = metrics.precision_score(y.cpu(), predicted.cpu(), average=average_mode) # 计算精确率
val_recall = metrics.recall_score(y.cpu(), predicted.cpu(), average=average_mode) # 计算召回率
val_loss /= len(val_loader) # 平均验证损失
val_acc /= len(val_loader.dataset) # 平均验证准确率
val_acc_list.append(val_acc) # 添加验证准确率
val_loss_list.append(val_loss) # 添加验证损失
print('\nVal Loss: {:.4f}, Val Acc: {:.4f}'.format(val_loss, val_acc))
print('Val-f1: {:.4f}, Val-precision: {:.4f} Val-recall: {:.4f}'.format(val_f1, val_pre, val_recall))
if train_loss < best_train_loss: # 更新最佳训练损失
best_train_loss = train_loss
best_epoch = epoch + 1
if device == 'cuda' and gpu_num > 1: # 多GPU保存模型
torch.save(model.module.state_dict(), f'{model_save_dir}/best_model{model_index}.pth')
else:
torch.save(model.state_dict(), f'{model_save_dir}/best_model{model_index}.pth') # 单GPU保存模型
# 提前停止判断
if epoch+1 - best_epoch == early_stop:
print(f'{early_stop} epochs later, the loss of the validation set no longer continues to decrease, so the training is stopped early.')
end_time = time.time()
print(f'Total time is {end_time - start_time}s.')
break
best_model = MODEL(model_index) # 初始化最佳模型
best_model.load_state_dict(torch.load(f'checkpoints/best_model{model_index}.pth')) # 加载模型参数
return best_model # 返回最佳模型
# 模型推理
def model_predict(model, model_index, test_loader):
device = 'cuda'
model.to(device) # 模型到GPU
model.eval() # 切换到评估模式
test_outputs = None
with torch.no_grad(): # 禁用梯度计算
for i, data in enumerate(tqdm(test_loader)):
data = data[0].to(device) # 测试数据到GPU
outputs = model(data) # 前向传播
if i == 0:
test_outputs = outputs # 第一个batch直接赋值
else:
test_outputs = torch.cat([test_outputs, outputs], dim=0) # 其余batch拼接
del data, outputs # 释放不再需要的Tensor
# 保存预测结果
if not opt.use_BCE:
test_outputs = torch.softmax(test_outputs, dim=1) # 转换为概率
torch.save(test_outputs, f'./models_prediction/{model_index}_prob.pth') # 保存概率
def run(model_index):
# 固定随机种子
seed = opt.seed
torch.seed = seed
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
train_dataset, val_dataset, test_dataset = load_data() # 加载数据集
# 打印数据集信息
print('-数据集信息:')
print(f'-训练集样本数:{len(train_dataset)},测试集样本数:{len(test_dataset)}')
train_labels = len(set(train_dataset.tensors[1].numpy()))
# 查看训练样本类别均衡状况
print(f'-训练集的标签种类个数为:{train_labels}')
numbers = [0] * train_labels
for i in train_dataset.tensors[1].numpy():
numbers[i] += 1
print(f'-训练集各种类样本的个数:')
for i in range(train_labels):
print(f'-{i}的样本个数为:{numbers[i]}')
batch_size = opt.batch_size # 批处理大小
# 构建DataLoader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
best_model = model_pretrain(model_index, train_loader, val_loader)
# 使用验证集评估模型
model_predict(best_model, model_index, test_loader) # 模型推理
if __name__ == '__main__':
model_index = opt.model_index # 获取模型索引
run(model_index) # 运行程序
1.3 评估模型
import torch # 导入torch库,用于深度学习任务
import pandas as pd # 导入pandas库,用于处理数据表格
from models_training import MODEL # 从本地文件models_training.py中导入MODEL类
import torch # 导入torch库,用于深度学习任务
from tqdm import tqdm # 导入tqdm库,用于显示进度条
from sklearn.metrics import classification_report # 从sklearn.metrics模块导入classification_report函数,用于输出分类报告,看各标签的F1值
import numpy as np # 导入numpy库,用于科学计算
# 推理
def inference(model_indexs, use_BCE):
device = 'cuda' # 设备选择为cuda
for model_index in model_indexs:
# 加载模型
model = MODEL(model_index).to(device) # 创建MODEL类的实例,并将模型移至设备(device)
model.load_state_dict(torch.load(f'checkpoints/best_model{model_index}.pth')) # 加载模型的权重参数
model.eval() # 切换到评估模式
# 加载val数据
val_data_path = f'models_input_files/x_val{model_index}.npy' # val数据的路径
val_data = torch.tensor(np.load(val_data_path, allow_pickle=True).tolist()) # 加载val数据,并转换为Tensor格式
val_dataset = torch.utils.data.TensorDataset(val_data) # 创建val数据集
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=32, shuffle=False) # 创建val数据的数据加载器
val_outputs = None # 初始化val_outputs变量
with torch.no_grad(): # 禁用梯度计算
for i, data in enumerate(tqdm(val_loader)): # 遍历val_loader,显示进度条
data = data[0].to(device) # 将数据移至GPU
outputs = model(data) # 模型推理,获取输出
if i == 0:
val_outputs = outputs # 若为第一次迭代,直接赋值给val_outputs
else:
val_outputs = torch.cat([val_outputs, outputs], dim=0) # 否则在dim=0上拼接val_outputs和outputs
del data, outputs # 释放不再需要的Tensor对象
# 输出预测概率
if not use_BCE:
val_outputs = torch.softmax(val_outputs, dim=1) # 对val_outputs进行softmax操作
torch.save(val_outputs, f'evaluate_prediction/{model_index}_prob.pth') # 保存预测概率结果
def run(model_indexs, use_BCE):
# 读取所有的model_prob.pth,并全加在一起
avg_pred = None # 初始化avg_pred变量
for i in model_indexs:
pred = torch.load(f'evaluate_prediction/{i}_prob.pth').data # 加载预测概率结果
if use_BCE:
# 选取大于0.5的作为预测结果
pred = (pred > 0.5).int() # 将大于0.5的值转换为整数(0或1)
pred = pred.reshape(-1) # 将预测结果进行形状重塑
else:
# 选取最大的概率作为预测结果
pred = torch.argmax(pred, dim=1) # 获取最大概率的索引作为预测结果
pred = pred.cpu().numpy() # 将预测结果转移到CPU上,并转换为NumPy数组
# to_evaluate
# 读取真实标签
val_label_path = f'models_input_files/y_val{i}.npy' # 真实标签的路径
y_true = np.load(val_label_path) # 加载真实标签
# 分类报告
print(f'model_index = {i}:')
print(classification_report(y_true, pred, digits=4)) # 打印分类报告,包括精确度、召回率等指标
zero_acc = 0; one_acc = 0 # 初始化0类和1类的准确率
zero_num = 0; one_num= 0 # 初始化0类和1类的样本数量
for i in range(pred.shape[0]):
if y_true[i] == 0:
zero_num += 1 # 统计0类的样本数量
elif y_true[i] == 1:
one_num += 1 # 统计1类的样本数量
if pred[i] == y_true[i]:
if pred[i] == 0:
zero_acc += 1 # 统计0类的正确预测数量
elif pred[i] == 1:
one_acc += 1 # 统计1类的正确预测数量
zero = np.sum(pred == 0) / pred.shape[0] # 计算预测为0类的样本占比
zero_acc /= zero_num # 计算0类的正确率
print(f'预测0类占比:{zero} 0类正确率:{zero_acc}')
one = np.sum(pred == 1) / pred.shape[0] # 计算预测为1类的样本占比
one_acc /= one_num # 计算1类的正确率
print(f'预测1类占比:{one} 1类正确率:{one_acc}')
print('-' * 80)
if __name__ == '__main__':
use_BCE = False # 是否使用BCE损失函数的标志,这里我只用交叉熵CE,所以是False
inference([2], use_BCE=use_BCE) # 进行推理,传入模型索引和use_BCE标志
model_indexs = [2] # 模型索引列表
run(model_indexs, use_BCE=use_BCE) # 进行运行,传入模型索引和use_BCE标志
1.4 测试集推理
import torch
import pandas as pd
import warnings # 过滤警告
warnings.filterwarnings('ignore')
def run(model_indexs, use_BCE):
# 记录模型数量
model_num = len(model_indexs)
# 读取所有的model_prob.pth,并全加在一起
for i in model_indexs:
# 加载模型在训练完成后对测试集推理所得的预测文件
pred = torch.load(f'./models_prediction/{i}_prob.pth', map_location='cpu').data
# 这里的操作是将每个模型对测试集推理的概率全加在一起
if i == model_indexs[0]:
avg_pred = pred
else:
avg_pred += pred
# 取平均
avg_pred /= model_num # 使用全加在一起的预测概率除以模型数量
if use_BCE:
# 选取概率大于0.5的作为预测结果
pred = (avg_pred > 0.5).int()
pred = pred.reshape(-1)
else:
# 后处理 - 根据标签数目的反馈,对预测阈值进行调整
pred[:, 0][pred[:, 0]>0.001] = 1
pred[:, 1][pred[:, 1]>0.999] = 1.2
# 选取最大的概率作为预测结果
pred = torch.argmax(avg_pred, dim=1)
pred = pred.cpu().numpy()
# to_submit
# 读取test.csv文件
test = pd.read_csv('./dataset/testB_submit_exsample.csv')
# 开始写入预测结果
for i in range(len(pred)):
test['label'][i] = pred[i]
print(test['label'].value_counts())
# 保存为提交文件
test.to_csv(f'submit.csv',index=False)
if __name__ == '__main__':
run([2], use_BCE=False)
# run([1,2,3,4,5,6,7,8,9,10], use_BCE=False)
1.5 后续改进
还可继续优化/探索的地方(进阶/高阶玩法)
- ①调整超参数
包括学习率、Batch_size、正则化系数等,可以使用网格搜索的方法(Grid search)来寻找模型更好的超参数组合。 - ②调整最大序列长度
在数据处理阶段中,调整最大序列长度MAX_LEN。 - ③更改损失函数
一般分类任务中,最常使用的损失函数是交叉熵(CE, Cross-Entropy),但最简单的也可以换成BCE。 - ④冻结模型部分参数
如feature1在模型训练的前期,相对feature2而言可能并不能带来太好的表征,所以第一个epoch可以先将它的参数进行冻结(又或者将该特征对应全连接层的学习率调小),然后等到第二个epoch后再正常训练。 - ⑤融合更多特征
融合更多特征,如考虑加入Glove、Word2Vec、Fasttext结合TextCNN、BiLSTM、LSTM+Attention等特征提取器所提取的文本特征。 - ⑥模型集成
使用一或多个与本文模型能够互补优劣的模型,并进行集成。 - ⑦对比学习
设计代理任务,加入对比损失函数,在训练阶段中获得更好的嵌入表示,提高模型性能。 - ⑧提示学习
在预训练模型的基础上使用提示学习范式,通过硬提示/软提示的方法提高模型性能。 - ⑨…
二、大模型Topline
2.1 大模型介绍
自 20 世纪 50 年代图灵测试提出以来,人们始终在探索机器处理语言智能的能力。语言本质上是一个错综复杂的人类表达系统,受到语法规则的约束。因此,开发能够理解和精通语言的强大 AI 算法面临着巨大挑战。过去二十年,语言建模方法被广泛用于语言理解和生成,包括统计语言模型和神经语言模型。
近些年,研究人员通过在大规模语料库上预训练 Transformer 模型产生了预训练语言模型(PLMs),并在解决各类 NLP 任务上展现出了强大的能力。并且研究人员发现模型缩放可以带来性能提升,因此他们通过将模型规模增大进一步研究缩放的效果。有趣的是,当参数规模超过一定水平时,这个更大的语言模型实现了显著的性能提升,并出现了小模型中不存在的能力,比如上下文学习。为了区别于 PLM,这类模型被称为大型语言模型(LLMs)。
从 2019 年的谷歌 T5 到 OpenAI GPT 系列,参数量爆炸的大模型不断涌现。可以说,LLMs 的研究在学界和业界都得到了很大的推进,尤其去年 11 月底对话大模型 ChatGPT 的出现更是引起了社会各界的广泛关注。LLMs 的技术进展对整个 AI 社区产生了重要影响,并将彻底改变人们开发和使用 AI 算法的方式。
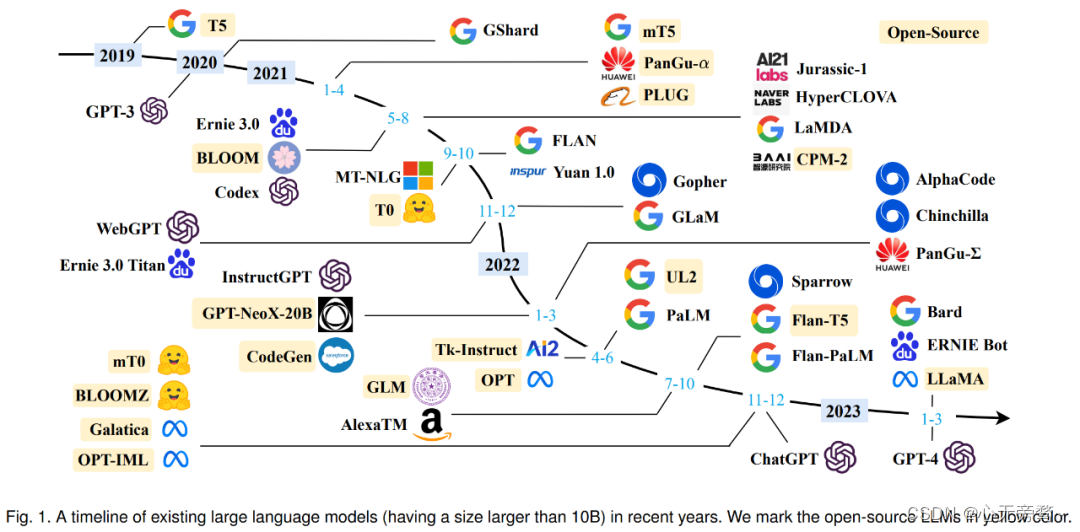
2019 年以来出现的各种大语言模型(百亿参数以上)时间轴,其中标黄的大模型已开源。(2023.04)
(开源大语言模型排行榜地址:Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4)
2.2 大模型是什么?
通常,大型语言模型(LLM)是指包含数千亿(或更多)参数的语言模型,这些参数是在大量文本数据上训练的,例如模型 GPT-3、PaLM、Galactica 和 LLaMA。具体来说,LLM 建立在 Transformer 架构之上,其中多头注意力层堆叠在一个非常深的神经网络中。现有的 LLM 主要采用与小语言模型类似的模型架构(即 Transformer)和预训练目标(即语言建模)。作为主要区别,LLM 在很大程度上扩展了模型大小、预训练数据和总计算量(扩大倍数)。他们可以更好地理解自然语言,并根据给定的上下文(例如 prompt)生成高质量的文本。这种容量改进可以用标度律进行部分地描述,其中性能大致遵循模型大小的大幅增加而增加。然而根据标度律,某些能力(例如,上下文学习)是不可预测的,只有当模型大小超过某个水平时才能观察到。
像chatgpt、claude AI、文心一言、讯飞星火和通义千问一样的,这种模型通过对大量的文本数据进行学习,可以理解和生成人类的自然语言,甚至可以编程、写数学题。
2.3 大模型的原理
大语言模型的语言生成的原理叫做自回归模型,是统计上一种处理时间序列的方法。例如现在有一个句子:“我早上去了星巴克”,将其拆分为“我”、“早上”、“去了”、“星巴克”这四个词(我们叫做 token)。大语言模型是这样去学习的:第一个单词是,输入到模型中。经过了一个Transformer模块后,它输出希望被训练成第一个字,也就是“我”。
在第二个位置,它的输入是“我”,它的输出是“早上”,第三个位置输入是“早上”,输出是“去了”,这样不断地一轮一轮迭代,每个细胞能够根据我现在的这个单词,去预测下一个单词。最后这个模型就能够学到,“我早上去了星巴克”的下一句话应该是“星巴克里的咖啡很好喝”,它认为生成“星巴克里的咖啡很好喝”比“我明天要去乘飞机”这样一句话合理得多。
自回归模型的关键是根据你前面已经出现过的内容,来推测它的下一个字,下一句话应该是怎样生成的,在这样不断的迭代过程中,它就能学会如何去生成一句话、一个段落,以及一篇文章。
总的来说,LLM可以理解为大规模的语言模型。从历史的角度来看,前面说的BERT和GPT并没有达到足够大的规模。直到GPT-2、GPT-3出现了,它们才达到了较大的量级。大家发现语言模型爆炸式增长,从一个细胞长成一个脑子,这种程度上的增长才带来了LLMs。所以我们一般理解LLMs,这个语言模型规模大到了至少到GPT-1或2阶段,它的参数量能够突破1亿或者10亿阶段才能称之为大模型。
2.4 大模型可以做什么?
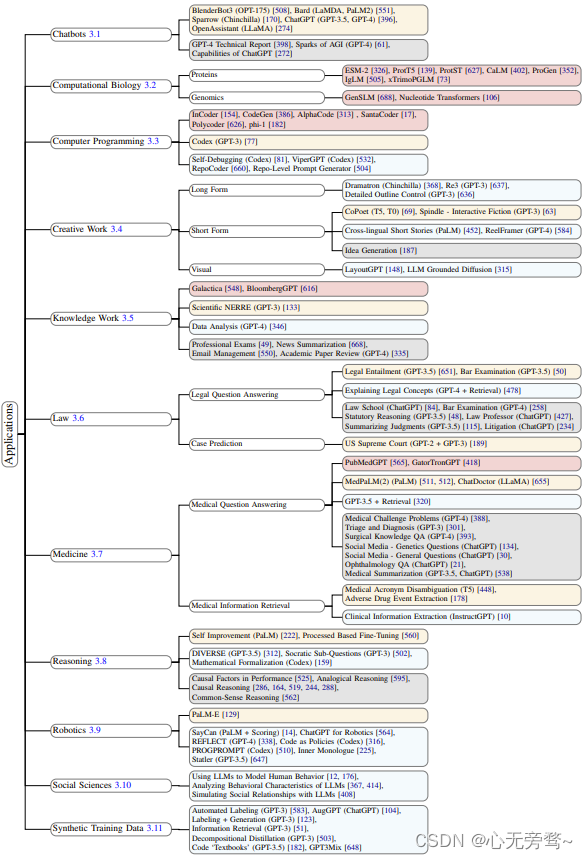
LLM 应用概况。不同颜色表示不同的模型适应程度,包括预训练、微调、提示策略、评估。
聊天机器人、计算生物学、计算机编程(https://codeium.com/)、创意工作、知识工作、法律(https://github.com/PKU-YuanGroup/ChatLaw)、医学(https://github.com/X-D-Lab/Sunsimiao)、推理、机器人和具身智能体、社会科学和心理学、生成合成数据等多个不同领域有不同程度的应用。
2.5 大模型是如何训练的?
OpenAI 开发 ChatGPT 的三个主要步骤:大尺寸预训练+指令微调+RLHF
- 大尺寸预训练: 在这个阶段,模型在大规模的文本数据集上进行预训练。这是一个非监督学习的过程,模型需要预测在给定的文本序列中下一个词是什么。预训练的目标是让模型学会理解和生成人类语言的基本模式。
- 指令微调: 在预训练之后,模型会在一个更小但专门针对特定任务的数据集上进行微调。这个数据集通常由人工生成,包含了模型需要学会的任务的特定指令。例如,如果我们想要让模型学会如何进行数学计算,我们就需要提供一些包含数学问题和对应解答的数据。
- RLHF(Reinforcement Learning from Human Feedback):这是一个强化学习过程,模型会根据人类提供的反馈进行学习和优化。首先,我们会收集一些模型的预测结果,并让人类评估这些结果的好坏。然后,我们会使用这些评估结果作为奖励,训练模型优化其预测性能。通过这种方式,模型可以学会生成更符合人类期望的结果。
通过这三个步骤,模型能够在理解和生成人类语言的基础上,更好地完成特定任务,更好地符合人类的期望。
2.6 Prompt
Prompt顾名思义表示「提示」,比如在高中时代,英语考试中的完形填空,有 4 个提示选项,我们只需要在 4 个里面选择合适的一个作为答案即可。在大语言模型中,提示模型输出我们想要的答案,这里就需要Prompt。(相关课程链接:https://github.com/datawhalechina/prompt-engineering-for-developers)
2.7 大模型微调介绍
2.7.1 什么是大模型微调
将预训练好的语言模型(LM)在下游任务上进行微调已成为处理 NLP 任务的一种范式。与使用开箱即用的预训练 LLM (例如:零样本推理) 相比,在下游数据集上微调这些预训练 LLM 会带来巨大的性能提升。
但是,随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调(full fine-tuning)变得不可行。
此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型(调整模型的所有参数)与原始预训练模型的大小相同。
因此,近年来研究者们提出了各种各样的参数高效迁移学习方法(Parameter-efficient Transfer Learning),即固定住Pretrain Language model(PLM)的大部分参数,仅调整模型的一小部分参数来达到与全部参数的微调接近的效果(调整的可以是模型自有的参数,也可以是额外加入的一些参数)。
2.7.2 微调方法介绍
- 参考:https://blog.csdn.net/sinat_39620217/article/details/131751780
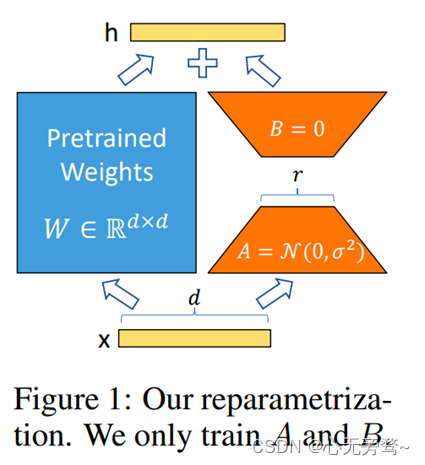
- LoRA(Low-Rank Adaptation):它的基本思想是对模型的一部分进行低秩适应,即找到并优化那些对特定任务最重要的部分。也就是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型微调类似的效果。这种方法可以有效地减少模型的复杂性,同时保持模型在特定任务上的表现。对 Transformer 的每一层结构都采用 LoRA 微调的方式,最终可以使得模型微调参数量大大减少。当部署到生产环境中时,只需要计算和存储W=W0+BA,并像往常一样执行推理。与其它方法相比,没有额外的延迟,因为不需要附加更多的层。
- P-tuning v2:P-tuning v2是一种新的微调方法,也是chatglm官方仓库使用的微调方法。它的基本思想是在原有的大型语言模型上添加一些新的参数,这些新的参数可以帮助模型更好地理解和处理特定的任务。具体来说,P-tuning v2首先确定模型在处理特定任务时需要的新的参数(这些参数通常是模型的某些特性或功能),然后在模型中添加这些新的参数,以提高模型在特定任务上的表现。
P-tuning v2 官方介绍:https://www.bilibili.com/video/BV1fd4y1Z7Y5
2.7.3 大模型微调都可以做什么呢?
- 训练垂领域的大模型,比如北大团队开发的ChatLaw法律大模型,还有医疗领域大模型和银行大模型等等。
- 也有我们小组训练的个性化AI模型—huanhuan-chat(Chat-嬛嬛)
2.8 建立数据集
目前所称的大语言模型,一般指指令微调大模型,即经过预训练——指令微调——人类反馈强化学习全过程训练的大模型,对人类指令具备较强的理解和执行能力,而不是进行简单的文本生成。例如,当你询问“中国的首都是什么?”时,你的指令即你的问题,通用模型将会简单地对你的问题进行最大概率预测地生成,例如回答“中国的首都是什么?这是一个人尽皆知的问题…”而指令微调大模型会理解你的指令,知道你想要模型对你的问题给出答案,从而回答“北京”。ChatGPT 与 GPT-3 就是鲜明的例子。GPT-3 是通用大模型,因此对你的输入只能进行最大概率预测地输出;而 ChatGPT 是指令微调大模型,可以理解并执行你的指令,例如帮助你写代码,帮助你判断问题等。
正如其名,指令微调大模型与通用大模型最大的区别在于进行了指令微调,即训练模型理解并执行指令的能力。指令微调一般会给模型特定的指令及执行指令后的输出,要求模型学习遵循指令的能力。这里的指令可以有很多种类型,包括回答问题、续写、创作等。具体而言,指令微调时通常有两个输入,一个是你要求模型执行的指令,另一个是执行该指令所必须的输入。例如,当你要求模型执行指令“续写我的话”,那么你还需要输入该指令中指代的话,例如“今天天气很好,我们去”。而指令微调的输出一般是模型执行该指令后的输出,例如对于上述示例,输出应该为“郊游吧”。
本任务中,我们所要对大模型进行的即是指令微调。通过训练模型在特定指令(在本任务中,即要求其判断文献是否医学领域文献)下的指令执行能力,来使用大模型完成本任务。我们也需要按照指令微调的格式进行数据集的建立。使用 LoRA 进行指令微调时,数据集一般有三个元素:instruction,input,output。instruction 即指令,即上文中我们所提到的第一个输入——要求模型执行的指令。input 即上文中我们提到的第二个输入——执行该指令所必须的输入。output 即指令微调的输出。
对于各种下游任务,只需要对应去构造特定的指令与输入即可。例如,在本次任务中,我们需要让大模型实现文本分类任务,那我们构造的指令、输入与输出应该为:
- instruction: 指令,Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title and abstract -->
- “–>”: 加上一个箭头就是让大模型明白,下次再遇到这种问题,就是我们想让大模型进行二分类任务。
- input: prompt。对于这个任务来说那就是 title+abstract+author 拼接成的字符串了。
- output: response,即大模型的回答,0 or 1。
如果是对于任务二的关键词生成,那么我们应该将指令修改为要求模型根据给定文献的标题、摘要生成关键词,输入不变,输出更改为文献的关键词:
- instruction: 指令,Please extract keywords from the given paper title and abstract in the text below, separated by commas -->
- “–>”: 加上一个箭头就是让大模型明白,下次再遇到这种问题,就是我们想让大模型进行关键词抽取任务。
- input: prompt。对于这个任务来说那就是 title+abstract+author 拼接成的字符串了。
- output: response,即大模型的回答,具体抽取出的关键词。
再例如在我们的项目 Chat-嬛嬛中,我们仅需要模型能够对用户输入进行模仿甄嬛语气的回答,因此可以将指令退化为简单的问答,所以在构造数据集时,我们的指令为对话集的上文,输出是甄嬛的回答,不需要额外的输入:
{
"instruction": "小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——",
"input": "",
"output": "嘘——都说许愿说破是不灵的。"
}
- 最后在data目录下的data_info.json文件内添加数据集。
"数据集名称": {
"file_name": "data目录下数据集文件的名称",
}
2.9 微调,跑起来!(code)
- 首先阅读文档:阿里云机器学习Pai-DSW服务器部署教程 ,配置好阿里云DSW服务器。
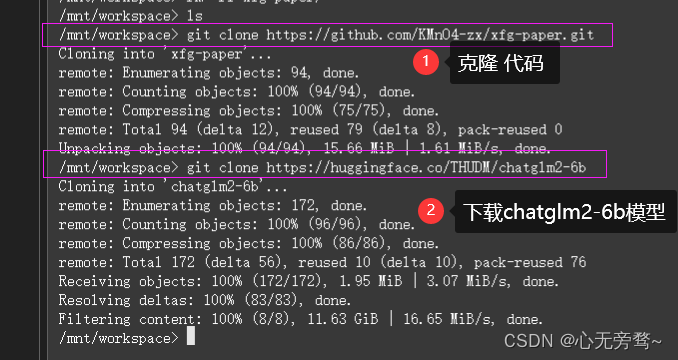
- clone微调脚本:
git clone https://github.com/KMnO4-zx/xfg-paper.git - 下载chatglm2-6b模型:
git clone https://huggingface.co/THUDM/chatglm2-6b,这行命令可能会失败,没关系多试几次!模型下载时间需要十几分钟,大家耐心等待哦~
(如果卡在中间也可以在确保
git clone https://huggingface.co/THUDM/chatglm2-6b执行成功但无反应后,进入’‘chatglm2-6b’'文件下,用如下命令下载模型【慎用】)
此命令只用于下载模型文件,py文件不会下载。
wget https://cloud.tsinghua.edu.cn/seafhttp/files/f3e22aa1-83d1-4f83-917e-cf0d19ad550f/pytorch_model-00001-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/0b6a3645-0fb7-4931-812e-46bd2e8d8325/pytorch_model-00002-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/f61456cb-5283-4529-a7bc-400355140e4b/pytorch_model-00003-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/1a1f68c5-1a7d-489a-8f16-8432a099d782/pytorch_model-00004-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/6357afba-bb40-4348-bc33-f08c1fcc2936/pytorch_model-00005-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/ebec3ae2-5ae4-432c-83e4-df4b147026bb/pytorch_model-00006-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/7d1aab8a-d255-47f7-87c9-4c0593379ee9/pytorch_model-00007-of-00007.bin https://cloud.tsinghua.edu.cn/seafhttp/files/4daca87e-0d34-4cff-bd43-5a40fcdf4ab1/tokenizer.model
进入目录安装环境:cd ./xfg-paper;pip install -r requirements.txt
- 将脚本中的model_name_or_path更换为你本地的chatglm2-6b模型路径,然后运行脚本:sh xfg_train.sh
- 微调过程大概需要两个小时(我使用阿里云A10-24G运行了两个小时左右),微调过程需要15G的显存,推荐使用16G、24G显存的显卡,比如3090,4090等。
- 当然,我们已经把训练好的lora权重放在了仓库里,您可以直接运行下面的代码。
- 也可以选择运行仓库内的jupyter notebook文件
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--model_name_or_path chatglm2-6b \ 本地模型的目录
--stage sft \ 微调方法
--use_v2 \ 使用glm2模型微调,默认值true
--do_train \ 是否训练,默认值true
--dataset paper_label \ 数据集名字
--finetuning_type lora \
--lora_rank 8 \ LoRA 微调中的秩大小
--output_dir ./output/label_xfg \ 输出lora权重存放目录
--per_device_train_batch_size 4 \ 用于训练的批处理大小
--gradient_accumulation_steps 4 \ 梯度累加次数
--lr_scheduler_type cosine \
--logging_steps 10 \ 日志输出间隔
--save_steps 1000 \ 断点保存间隔
--learning_rate 5e-5 \ 学习率
--num_train_epochs 4.0 \ 训练轮数
--fp16 是否使用 fp16 半精度 默认值:False
导入数据
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 读取训练集和测试集
train_df = pd.read_csv('./csv_data/train.csv')
testB_df = pd.read_csv('./csv_data/testB.csv')
制作数据集
# 创建一个空列表来存储数据样本
res = []
# 遍历训练数据的每一行
for i in range(len(train_df)):
# 获取当前行的数据
paper_item = train_df.loc[i]
# 创建一个字典,包含指令、输入和输出信息
tmp = {
"instruction": "Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title and abstract -->",
"input": f"title:{paper_item[1]},abstract:{paper_item[3]}",
"output": str(paper_item[5])
}
# 将字典添加到结果列表中
res.append(tmp)
# 导入json包,用于保存数据集
import json
# 将制作好的数据集保存到data目录下
with open('./data/paper_label.json', mode='w', encoding='utf-8') as f:
json.dump(res, f, ensure_ascii=False, indent=4)
修改data_info
{
"paper_label": {
"file_name": "paper_label.json"
}
}
加载训练好的LoRA权重,进行预测
# 导入所需的库和模块
from peft import PeftModel
from transformers import AutoTokenizer, AutoModel, GenerationConfig, AutoModelForCausalLM
# 定义预训练模型的路径
model_path = "../chatglm2-6b"
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 加载 label lora权重
model = PeftModel.from_pretrained(model, './output/label_xfg').half()
model = model.eval()
# 使用加载的模型和分词器进行聊天,生成回复
response, history = model.chat(tokenizer, "你好", history=[])
response
# 预测函数
def predict(text):
# 使用加载的模型和分词器进行聊天,生成回复
response, history = model.chat(tokenizer, f"Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title and abstract -->{text}", history=[],
temperature=0.01)
return response
制作submit
# 预测测试集
# 导入tqdm包,在预测过程中有个进度条
from tqdm import tqdm
# 建立一个label列表,用于存储预测结果
label = []
# 遍历测试集中的每一条样本
for i in tqdm(range(len(testB_df))):
# 测试集中的每一条样本
test_item = testB_df.loc[i]
# 构建预测函数的输入:prompt
test_input = f"title:{test_item[1]},author:{test_item[2]},abstract:{test_item[3]}"
# 将预测结果存入lable列表
label.append(int(predict(test_input)))
# 把label列表赋予testB_df
testB_df['label'] = label
# task1虽然只需要label,但需要有一个keywords列,用个随意的字符串代替
testB_df['Keywords'] = ['tmp' for _ in range(2000)]
# 制作submit,提交submit
submit = testB_df[['uuid', 'Keywords', 'label']]
submit.to_csv('submit.csv', index=False)
本文章旨在记录学习,相关参考:
https://tvq27xqm30o.feishu.cn/docx/U1fzdqdE0o6SWnxixyrc3gnLnJg
https://vj6fpcxa05.feishu.cn/docx/DIged2HfIojIYlxWP9Hc2x0UnVd