🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
个人主页:beixi@
本文章收录于专栏(点击传送):【大数据学习】
💓💓持续更新中,感谢各位前辈朋友们支持学习~
文章目录
- 1.Sqoop组件介绍
- 2.环境介绍
- 3.搭建步骤
1.Sqoop组件介绍
Sqoop是一个用于在Apache Hadoop和关系型数据库(如MySQL、Oracle等)之间进行数据传输的工具。它提供了简单易用的命令行界面,可以将结构化数据从关系型数据库导入到Hadoop中的分布式文件系统(如HDFS),或者将数据从Hadoop导出到关系型数据库。
Sqoop由以下组件构成:
Sqoop核心组件(Core):Sqoop核心组件包括连接管理器(Connection Manager)、作业调度(Job Scheduling)、任务划分(Task Partitioning)和执行引擎(Execution Engine)等。它们一起协调Sqoop的数据传输过程。
连接管理器(Connection Manager):连接管理器负责与关系型数据库建立连接,并管理数据库连接信息。Sqoop支持多种关系型数据库,每种数据库都有对应的连接管理器。
作业调度(Job Scheduling):作业调度模块负责管理和调度Sqoop的数据传输作业。它可以按照预定的时间表执行作业,也可以手动触发作业的执行。
任务划分(Task Partitioning):任务划分模块将数据导入或导出过程划分为多个任务,并将这些任务分配给可用的计算资源执行。任务划分考虑了数据的并行性和负载均衡性,以提高数据传输的效率。
执行引擎(Execution Engine):执行引擎是Sqoop的核心组件之一,它负责实际执行数据传输作业。Sqoop支持多种执行引擎,包括MapReduce、YARN和Spark等。根据Hadoop集群的配置和需求,可以选择合适的执行引擎。
导入器(Importer)和导出器(Exporter):导入器和导出器是Sqoop的两个关键模块。导入器用于将关系型数据库中的数据导入到Hadoop中,导出器用于将Hadoop中的数据导出到关系型数据库。
元数据存储(Metastore):元数据存储用于存储Sqoop的元数据信息,如连接信息、作业信息、导入导出的数据信息等。Sqoop支持多种元数据存储方式,包括关系型数据库(如MySQL、PostgreSQL)和Hadoop的分布式文件系统(如HDFS)。

2.环境介绍
本次实验使用到的环境有:
(1)Oracle Linux 7.4
(2)Hadoop 2.7.4
(3)Sqoop1.4.6
3.搭建步骤
1.软件Sqoop1.4.6版本下载链接:
http://archive.apache.org/dist/sqoop/1.4.6
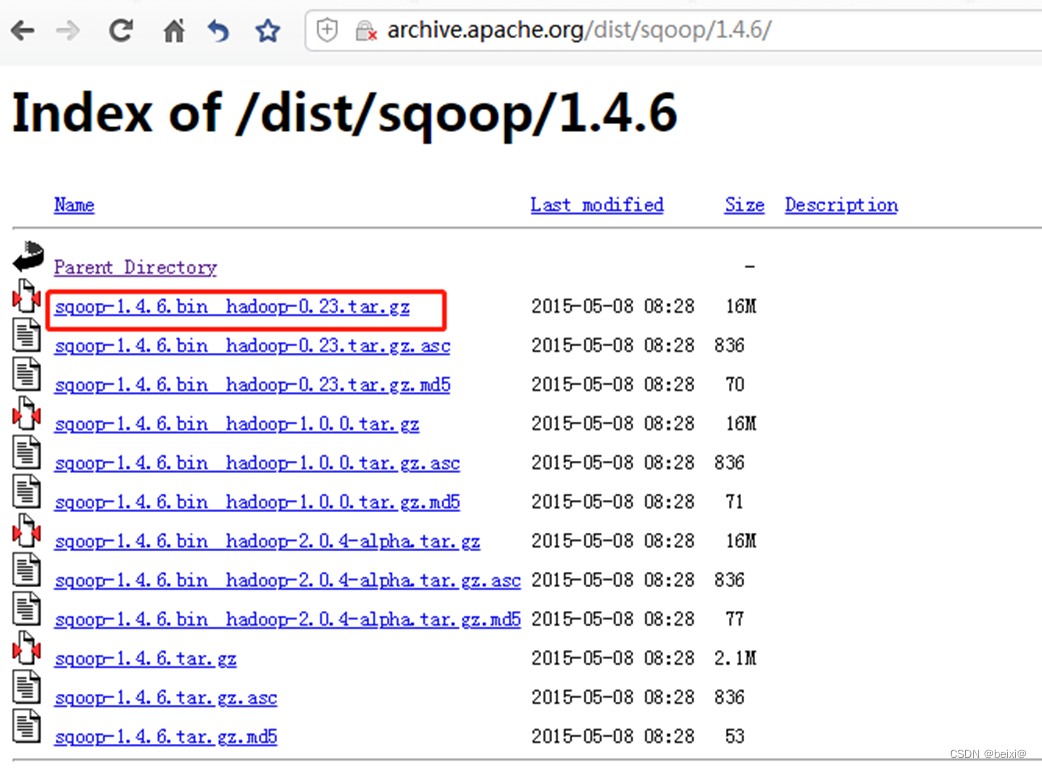
2.解压文件到/opt目录下。
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/sqoop

3.修改系统环境变量配置文件。
vi .bashrc

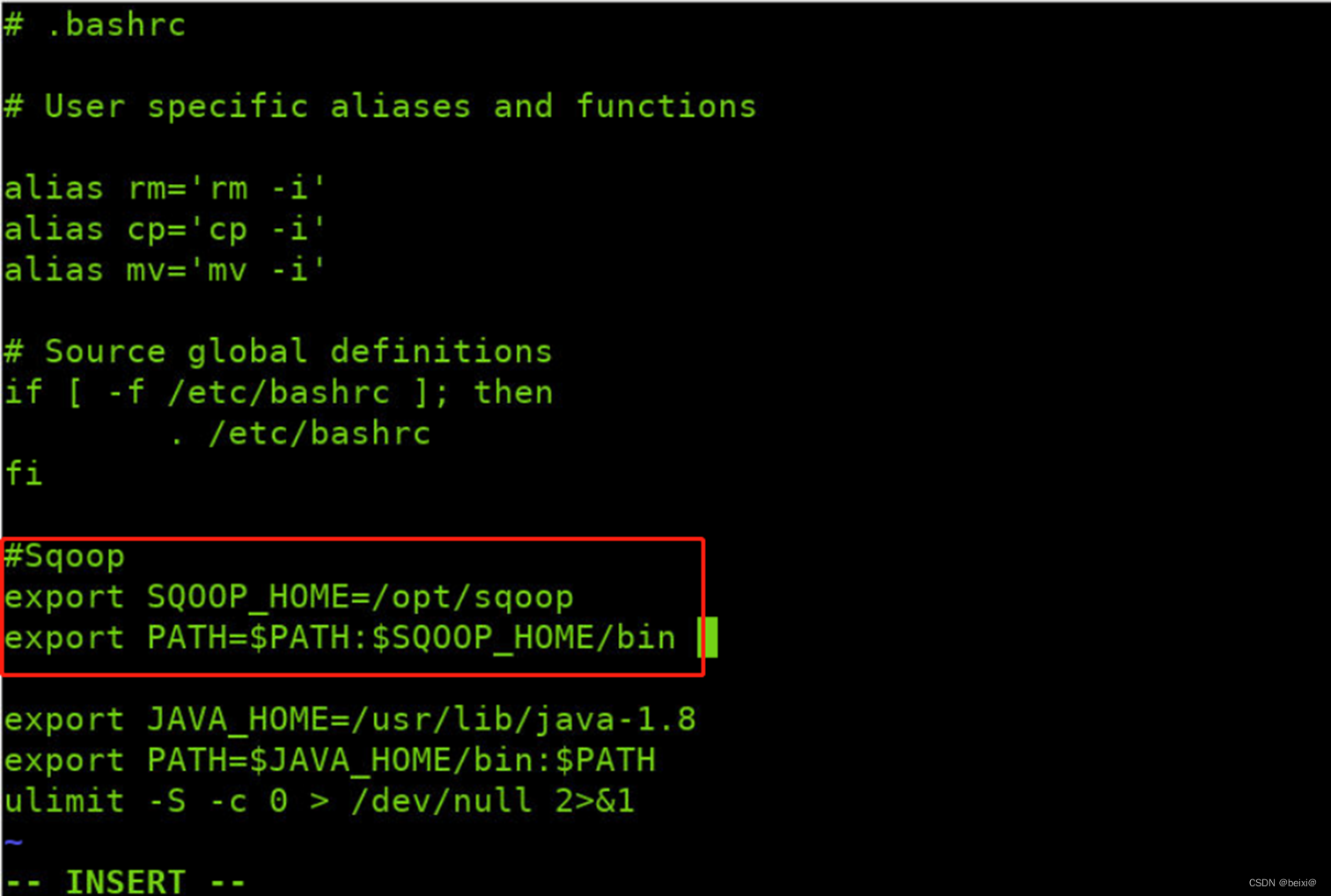
4.配置系统环境变量(按 i 进入编辑模式),保存文件。
#Sqoop
export SQOOP_HOME=/opt/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
5.刷新文件使其立即生效。
source .bashrc

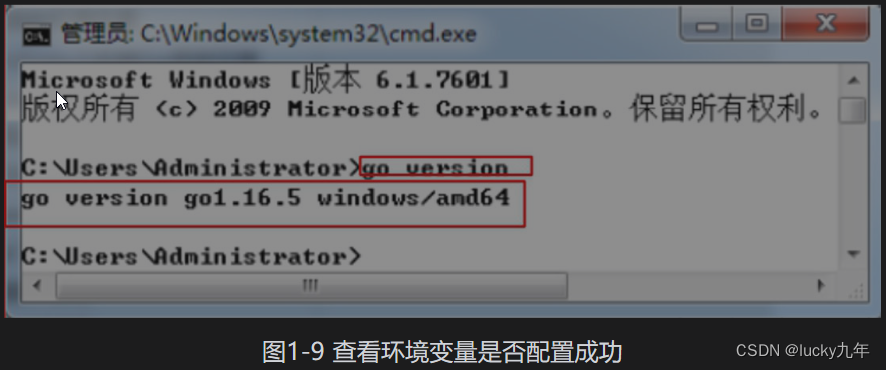
6.验证安装是否成功。
sqoop version

至此Sqoop的安装与验证就结束了,如果本篇文章对你有帮助记得点赞收藏+关注~