1、概述
kubernetes的监控指标分为两种:
-
Core metrics(核心指标):从 Kubelet、cAdvisor 等获取度量数据,再由metrics-server提供给 kube-scheduler、HPA、 控制器等使用。
-
Custom Metrics(自定义指标):由Prometheus Adapter提供API custom.metrics.k8s.io,由此可支持任意Prometheus采集到的指标。
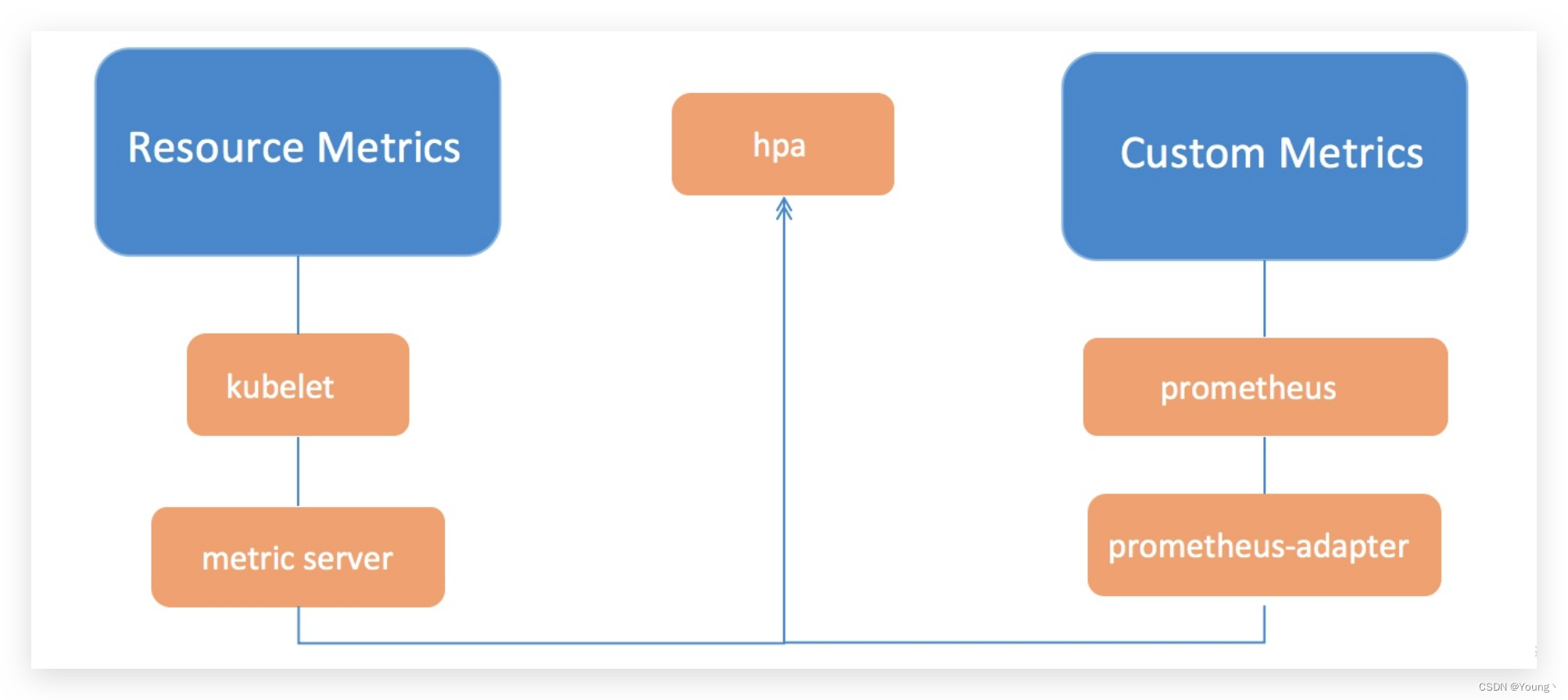
核心指标只包含node和pod的cpu、内存,一般来说,核心指标作HPA已经足够,但如果想根据自定义指标:如请求qps/5xx错误数来实现HPA,就需要使用自定义指标了,目前Kubernetes中自定义指标一般由Prometheus来提供,再利用prometheus-adpater(自定义apiserver)聚合到原生kubernetes apiserver,实现和核心指标(metric-server)同样的效果。聚合自定义apiserver请参考Kubernetes核心指标监控——Metrics Server 这篇博文,本文不再赘余。
2、部署prometheus-adpater
Prometheus可以采集其它各种指标,但是prometheus采集到的metrics并不能直接给kubernetes用,因为两者数据格式不兼容,因此还需要另外一个组件(kube-state-metrics),将prometheus的metrics数据格式转换成k8s API接口能识别的格式,转换以后,因为是自定义API,所以还需要用Kubernetes aggregator在主API服务器中注册,以便直接通过/apis/来访问。
文件清单:
- node-exporter:prometheus的exporter,收集Node级别的监控数据
- prometheus:监控服务端,从node-exporter拉数据并存储为时序数据。
- kube-state-metrics:将prometheus中可以用PromQL查询到的指标数据转换成k8s对应的数据。
- prometheus-adpater:聚合进apiserver,即一种custom-metrics-apiserver实现
- 开启Kubernetes aggregator功能(开启方法可以参考官方社区的文档)
快速方便部署prometheus 可以参考这个 Prometheus Operator 极简配置方式在k8s一条龙安装Prometheus 监控
k8s-prometheus-adapter的部署文件:
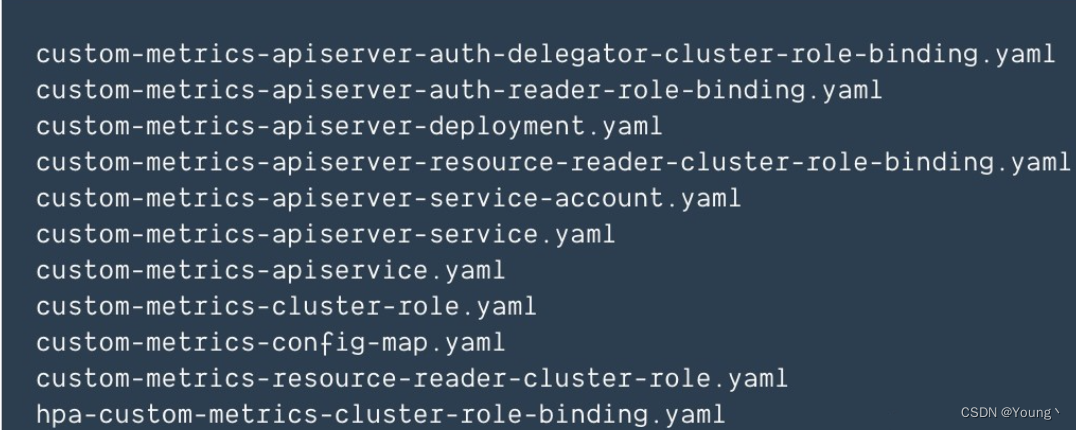
其中创建了一个叫做cm-adapter-serving-certs的secret,包含两个值: serving.crt和serving.key,这是由apiserver信任的证书。kube-prometheus项目中的gencerts.sh和deploy.sh脚本可以创建这个secret。包括secret的所有资源,都在custom-metrics命名空间下,因此需要kubectl create namespace custom-metrics。
以上组件均部署成功后,可以通过url获取指标
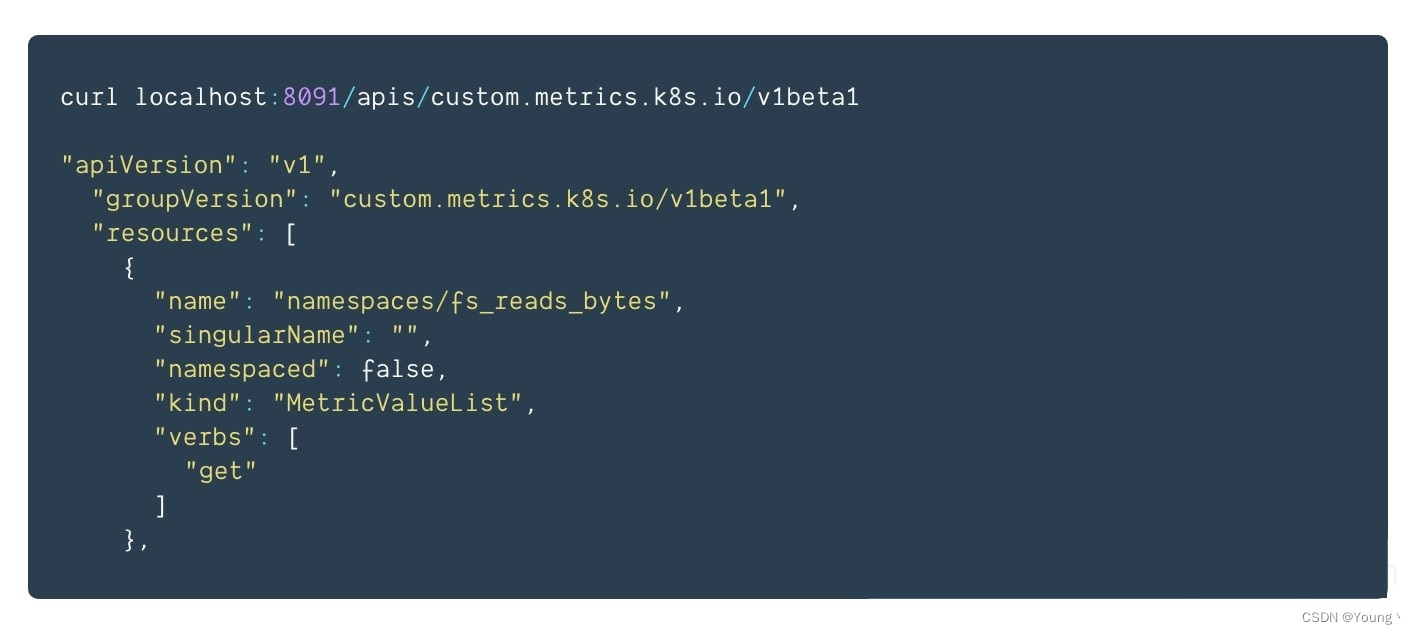 3、基于自定义指标的HPA
3、基于自定义指标的HPA
使用prometheus后,pod有一些自定义指标,如http_request请求数
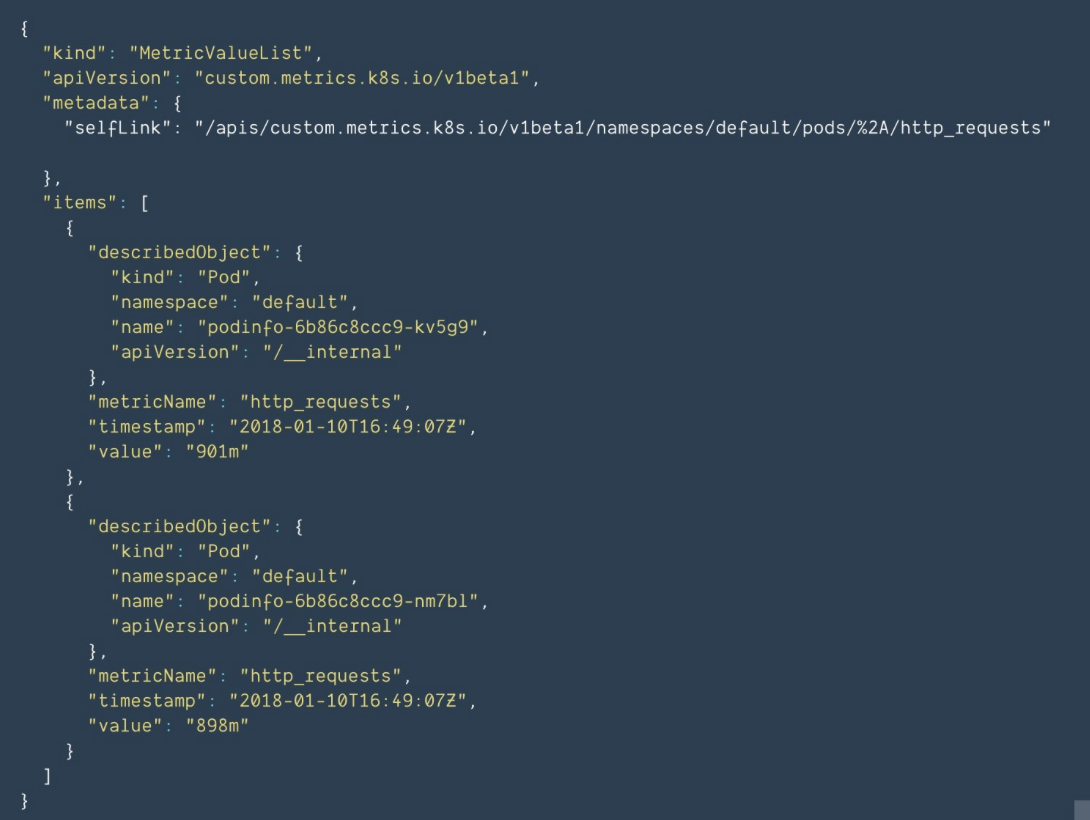
创建一个HPA,当请求数超过每秒10次时进行自动扩容
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests
targetAverageValue: 10
查看HPA:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 899m / 10 2 10 2 1m
对Pod试压:
#install hey
$ go get -u github.com/rakyll/hey<br>
#do 10K requests rate limited at 25 QPS
$ hey -n 10000 -q 5 -c 5 http://PODINFO_SVC_IP:9898/healthz
HPA发挥作用:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
4、关于prometheus-adapter
其实prometheus-adapter既包含自定义指标,又包含核心指标,即如果安装了prometheus,且指标都采集完整,k8s-prometheus-adapter可以替代metrics server。
在1.6以上的集群中,prometheus-adapter可以适配autoscaling/v2的HPA。
因为一般是部署在集群内,所以prometheus-adapter默认情况下,使用in-cluster的认证方式,以下是主要参数:
- lister-kubeconfig: 默认使用in-cluster方式
- metrics-relist-interval: 更新metric缓存值的间隔,最好大于等于Prometheus 的scrape interval,不然数据会为空
- prometheus-url: 对应连接的prometheus地址
- config: 一个yaml文件,配置如何从prometheus获取数据,并与k8s的资源做对应,以及如何在api接口中展示。
5、总结
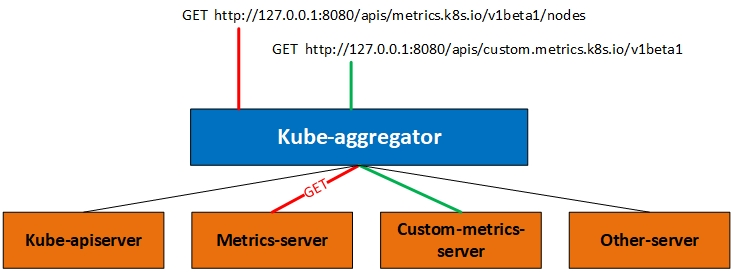
kubernetes自定义监控指标prometheus-adapter一般通过Prometheus来提供监控指标数据(其他自定义监控指标采集工具还包括Microsoft Azure Adapter、Google Stackdriver等),一般来说,核心指标作HPA已经足够,但如果想根据自定义指标:如请求qps/5xx错误数来实现HPA,这时候就需要在集群中部署prometheus-adapter了,通过将prometheus-adpater(自定义apiserver)聚合到原生kubernetes apiserver,实现和核心指标(metric-server)同样的效果。
参考:https://yasongxu.gitbook.io/container-monitor/yi-.-kai-yuan-fang-an/di-1-zhang-cai-ji/custom-metrics
参考:https://www.shouxicto.com/article/897.html
参考:Prometheus Operator 极简配置方式在k8s一条龙安装Prometheus 监控






![[附源码]Node.js计算机毕业设计高校线上教学系统Express](https://img-blog.csdnimg.cn/7c8d456cff614d8e910fad6b3b424ce2.png)