学习资源
有一套配套的学习资料,才能让我们的学习事半功倍。
yolov1论文原址:You Only Look Once: Unified, Real-Time Object Detection
代码地址:darknet: Convolutional Neural Networks (github.com)
深度学习经典检测方法
- one-stage(单阶段):YOLO系列
最核心的优势:速度非常快,适合做实时检测任务! 但是缺点也是有的,效果通常情况下不会太好!
- two-stage(两阶段):Faster-rcnn Mask-Rcnn系列
速度通常较慢(5FPS),但是效果通常还是不错的! 非常实用的通用框架MaskRcnn,可以去学习一下。
应用:
二者算法流程不同,一阶段检测一步到位,直接预测类别和坐标。两阶段检测会先生成建议框,再进行分类和回归。所以两阶段更适合对精度要求高的场景,如工业质检;而单阶段更适合要求速度的场景,如视频监控。
YOLO 核心思想
YOLO采用直接回归的思路,将目标定位和目标类别预测整合于在单个神经网络模型中。

由于不像Faster-rcnn那样提取region proposal,YOLOv1的检测流程很简单:
- Resize image:将输入图片resize到448x448。
- Run ConvNet:使用CNN提取特征,FC层输出分类和回归结果。
- Non-max Suppression:非极大值抑制筛选出最终的结果。
目标检测逻辑
这个部分是一个难点,就是我没有建议框,那要怎么定位那些包含目标的区域并固定输出呢?
YOLOv1就将图像分成SxS个网格,每个网格预测B个边界框。这样就利用网格划分了空间,使每个网格单元负责预测自己所包含的目标。
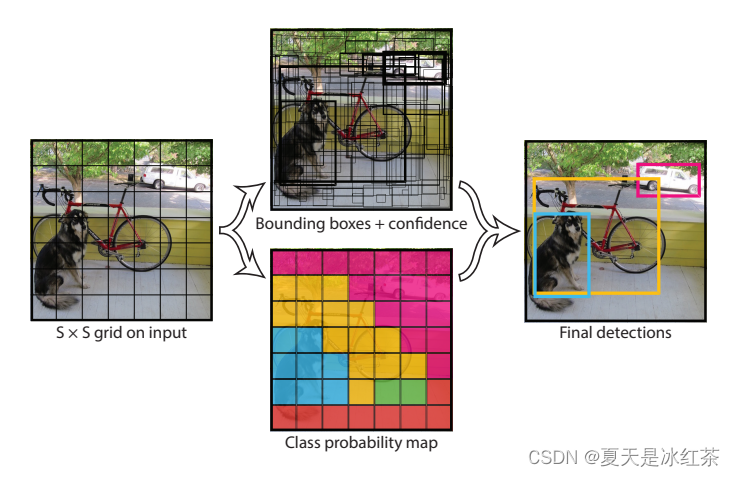
这里的S x S我们就按照如图所示认为是7 x 7,每个网格预测B个Bbox(边界框) ,以及每个边界框的confidence值,confidence就是置信度。 所以每个边界框对应5个参数:[x,y,w,h,c]。
- (x,y) 表示边界框中心相对于网格的坐标;
- w,h 表示边界框相对于整张图像的宽和高(意思是边界框的中心坐标必须在网格内,但其宽和高不受网格限制、可以随意超过网格大小);
- c即为confidence,其定义为:当预测的边界框内不存在目标时,置信度(Confidence)应该置为0。当预测的边界框内存在目标时,置信度应该置为该预测边界框和真值框的IoU(Intersection over Union,交并比)。
每个网格还会预测C个条件类别概率值,它表示当有目标的中心位置“落入”该网格中时,这一目标属于C个类别的概率分布。
网络结构设计
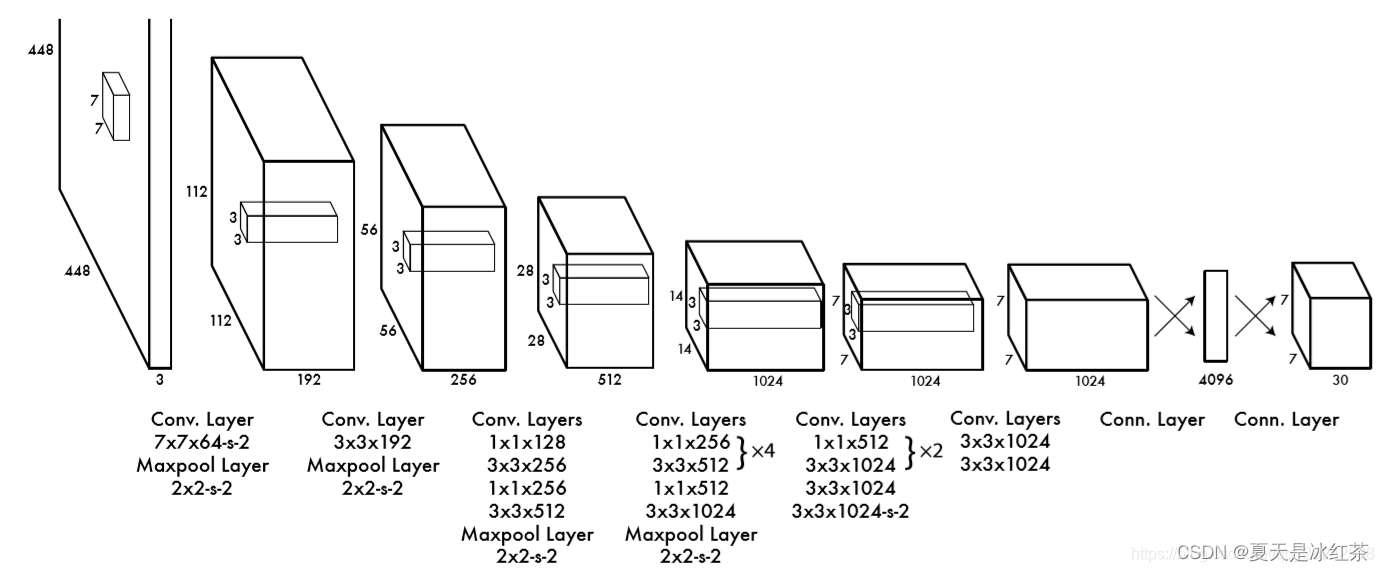
YOLOv1的网络结构很简单,借鉴了GooLeNet设计,共包含24个卷积层,2个全链接层(前20层中用1×1 reduction layers 紧跟 3×3 convolutional layers 取代GooLeNet的 inception modules)。
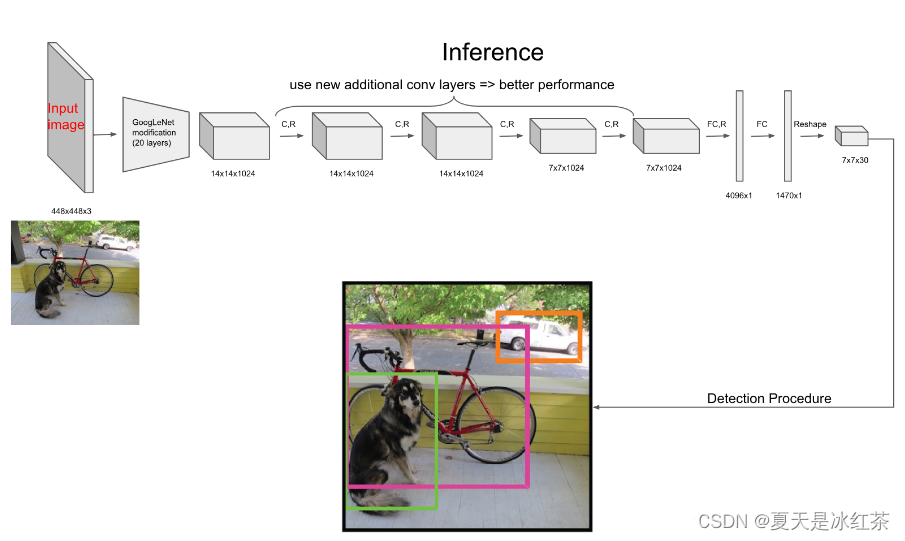
- 输入:448 x 448 x 3,由于网络的最后需要接入两个全连接层,全连接层需要固定尺寸的输入,故需要将输入resize。
- Conv + FC:主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:
,最后一层采用线性激活函数。
- 输出:最后一个FC层得到一个1470 x 1的输出,将这个输出reshap一下,得到 7 x 7 x 30 的一个tensor,即最终每个单元格都有一个30维的输出,代表预测结果。
YOLO输入图像的尺寸为448 × 448,经过24个卷积层和2个全连接层,最后在reshape操作,输出的特征图大小为7 × 7 × 30,那这个值是怎么得出来的呢?
实际上输出的是的tensor张量,刚刚也说了要有B个预测框,每个预测框包括了5个信息[x,y,w,h,c],C表示分类预测(通常是20类左右)。
- SxS为7x7网格
- B=2,也就是每个格子有2个预测框
- C=20,PASCAL VOC数据集有20个分类
损失函数
位置误差
主要是计算bbox的和对应的ground truth box的
之间的sum-squared error,需要注意的是并不是所有的bbox都参与loss的计算,首先必须是第i个单元格中存在object,并且该单元格中的第j个bbox和ground truth box有最大的IoU值,那么这个bbox才参与loss的计算,其他的不满足条件的bbox不参与。此外,因为误差在小的box上体现的更明显,就是一点点小的位置上的偏差可能对大的box影响不是很大,但是对小的box的影响就比较明显了,所以为了给不同size的box的位置loss赋予不同的‘权重’,需要对w和h开方后才进行计算。
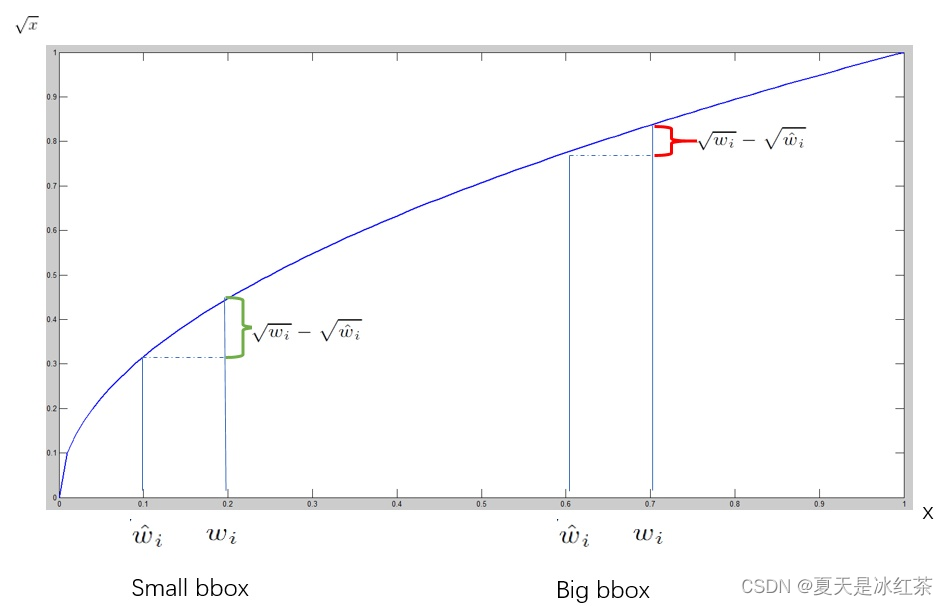
我们知道,当x较小时,x的一点小的变化都会导致y大的变化,而当x较大的时候,x的一点儿小的变化不会让y的变化太大。这个方法只能减弱这个问题,并不能彻底解决这个问题。
置信度误差
置信度分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0。第二项代表预测框box和真实标记的box之间的IoU。值越大则box越接近真实位置。
分类误差
当作回归误差来计算,使用sum-squared error来计算分类误差,需要注意的是只有包含object的单元格才参与分类loss的计算,即有object中心点落入的单元格才进行分类loss的计算,而这个单元格的ground truth label就是该物体的label。
总的来说就是:
对于有目标的单元格(cell):
- 计算单元格的分类误差,即目标类别的预测误差。
- 计算单元格中两个边界框(bbox)的置信度误差,即预测的边界框是否包含目标的置信度误差。
- 找到与单元格中的ground truth box(真实边界框)具有最大IoU的边界框,并计算其位置误差,即边界框的坐标和尺寸误差。
对于没有目标的单元格:
- 仅计算单元格中两个边界框的置信度误差,因为没有目标存在。
这个目标检测过程中的误差计算主要用于训练过程中的损失函数计算,以便通过反向传播来更新模型的参数,使其能够更好地预测目标的位置和类别。
YOLOv1算法的缺点
YOLOv1算法存在一些缺陷,这些缺陷在原文中进行了讨论。
-
目标数量限制:YOLOv1每个网格只能预测2个边界框和1个类别。这限制了对于相近目标的检测数量,尤其是在包含大量小物体的场景中(如鸟群)。这可能导致YOLOv1在这些情况下的检测结果不够准确。
-
泛化能力有限:由于YOLOv1是通过从数据中学习来进行目标检测的,它的泛化能力可能受到一些限制。特别是在面对具有不寻常长宽比或配置的目标时,模型可能无法很好地适应。这可能导致YOLOv1在这些情况下的检测性能下降。
-
损失函数设计:YOLOv1使用的损失函数在一些方面可能不够合理,特别是在处理定位误差和大小物体时。由于YOLOv1将边界框的位置和大小信息与类别预测结合在一起进行训练,误差的影响可能不够平衡,尤其是对于小物体的处理。这可能导致YOLOv1在定位小物体时的性能较差。
这些缺陷是YOLOv1算法的一些局限性,随后的YOLO版本(如YOLOv2、YOLOv3等)对这些问题进行了改进和优化,以提高检测性能和泛化能力。
参考文章
【0】 You Only Look Once: Unified, Real-Time Object Detection
【1】【目标检测】YOLO系列——YOLOv1详解_yolov1网络结构图详解_本初-ben的博客-CSDN博客
【2】 yolov1详解_Fighting_1997的博客-CSDN博客
【3】【目标检测论文阅读】YOLOv1 - 知乎 (zhihu.com)
【4】 搞懂YOLO v1看这篇就够了_yolov1_Antrn的博客-CSDN博客