流数据
可以从不同的角度对流进行分类:
- 处理的数据单位不同,可分为:字符流,字节流
2.数据流方向不同,可分为:输入流,输出流
3.功能不同,可分为:节点流,处理流
节点流:节点流从一个特定的数据源读写数据。即节点流是直接操作文件,网络等的流,例如FileInputStream和FileOutputStream,他们直接从文件中读取或往文件中写入字节流。

处理流:“连接”在已存在的流(节点流或处理流)之上通过对数据的处理为程序提供更为强大的读写功能。过滤流是使用一个已经存在的输入流或输出流连接创建的,过滤流就是对节点流进行一系列的包装。例如BufferedInputStream和BufferedOutputStream,使用已经存在的节点流来构造,提供带缓冲的读写,提高了读写的效率,以及DataInputStream和DataOutputStream,使用已经存在的节点流来构造,提供了读写Java中的基本数据类型的功能。他们都属于过滤流。
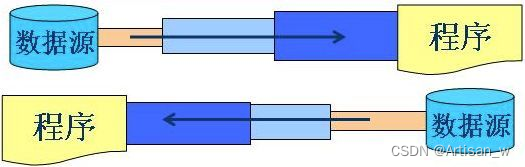
字节流与字符流处理区别
字节流
Java中的字节流处理的最基本单位为单个字节,它通常用来处理二进制数据。Java中最基本的两个字节流类是InputStream和OutputStream,它们分别代表了最基本的输入字节流和输出字节流。InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先,它们都是抽象类。
字节流在默认情况下是不支持缓存的,字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,这意味着每调用一次read方法都会请求操作系统来读取一个字节,这往往会伴随着一次磁盘IO,因此效率会比较低。要使用内存缓冲区以提高读取的效率,我们应该使用BufferedInputStream。
需注意,使用BufferedOutputStream输出数据时如果没有关闭流,数据也是不会输出到文件当中的,即并不是所
字符流
Java中的字符流处理的最基本的单元是Unicode码元(大小2字节),它通常用来处理文本数据,例如字符、字符数组或字符串。Java中的String类型默认就把字符以Unicode规则编码而后存储在内存中。存储在磁盘上的数据通常有着各种各样的编码方式,不同的编码方式最终输出的字节内容是不同的,所以,字节流的读取和写入都要设置相应的编码方式。
由于字符流在输出前实际上是要完成Unicode码元序列到相应编码方式的字节序列的转换,所以它会使用内存缓冲区来存放转换后得到的字节序列,等待都转换完毕再一同写入磁盘文件中。
所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列。
InputStream 类及其子类的对象表示字节输入流,InputStream 类的常用子类如下。
ByteArrayInputStream 类:将字节数组转换为字节输入流,从中读取字节。
FileInputStream 类:从文件中读取数据。
PipedInputStream 类:连接到一个 PipedOutputStream(管道输出流)。
SequenceInputStream 类:将多个字节输入流串联成一个字节输入流。
ObjectInputStream 类:将对象反序列化。
方法名及返回值类型 说明
int read() 从输入流中读取一个 8 位的字节,并把它转换为 0~255 的整数,最后返回整数。如果返回 -1,则表示已经到了输入流的末尾。为了提高 I/O 操作的效率,建议尽量使用 read() 方法的另外两种形式
int read(byte[] b) 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。 该方法返回读取的字节数。如果返回 -1,则表示已经到了输入流的末尾
int read(byte[] b, int off, int len) 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。其中,off 指定在字节数组中开始保存数据的起始下标;len 指定读取的字节数。该方法返回实际读取的字节数。如果返回 -1,则表示已经到了输入流的末尾
void close() 关闭输入流。在读操作完成后,应该关闭输入流,系统将会释放与这个输入流相关的资源。注意,InputStream 类本身的 close() 方法不执行任何操作,但是它的许多子类重写了 close() 方法
int available() 返回可以从输入流中读取的字节数
long skip(long n) 从输入流中跳过参数 n 指定数目的字节。该方法返回跳过的字节数
void mark(int readLimit) 在输入流的当前位置开始设置标记,参数 readLimit 则指定了最多被设置标记的字
节数
boolean markSupported() 判断当前输入流是否允许设置标记,是则返回 true,否则返回 false
void reset() 将输入流的指针返回到设置标记的起始处
字节流和字符流的区别
字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
字节流默认不使用缓冲区;字符流使用缓冲区。
字节流在操作的时候本身是不会用到缓冲区的,是与文件本身直接操作的,所以字节流在操作文件时,即使不关闭资源,文件也能输出;字符流在操作的时候是使用到缓冲区的。如果字符流不调用close或flush方法,则不会输出任何内容。
字节流通常用于处理二进制数据,实际上它可以处理任意类型的数据,但它不支持直接写入或读取Unicode码元;字符流通常处理文本数据,它支持写入及读取Unicode码元。
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
字节流和字符流的转换
字节流是最基本的,所有的InputStream和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的,但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化,这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联。在从字节流转化为字符流时,实际上就是byte[]转化为String时,而在字符流转化为字节流时,实际上是String转化为byte[]时。
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点。所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列。
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
字节流与字符流主要的区别是他们的的处理方式









![java八股文面试[多线程]——线程间通信方式](https://img-blog.csdnimg.cn/78db1c87d3a244fd868a6a0606454b05.png)
