引言
这是DSSM论文的阅读笔记,后续会有一篇文章来复现它并在中文数据集上验证效果。
本文的标题翻译过来就是利用点击数据学习网页搜索中深层结构化语义模型,这篇论文被归类为信息检索,但也可以用来做文本匹配。
这是一篇经典的工作,在DSSM之前,通常使用传统机器学习的方法,比如LSA、LDA来解决。本篇工作使文本匹配进入了深度学习时代。
摘要
在信息检索中要研究的问题是,给定一个查询(query)和一组文档(documents),返回一个基于匹配度的排序(ranking)文档结果。
作者通过使用DNN将查询和文档映射到一个通用的低维(稠密向量)空间,通过计算该空间中的距离来表示它们的相关性。同时利用词哈希技术解决词表过大问题。
模型的优化策略是,最大化正确标签出现的条件概率,即最小化softmax交叉熵损失。通过不断迭代,希望给定一组query和文档的时候,能最大化地匹配到被点击过的文档的概率。
下面我们直接来看模型的结构。
模型结构
计算语义特征的DNN
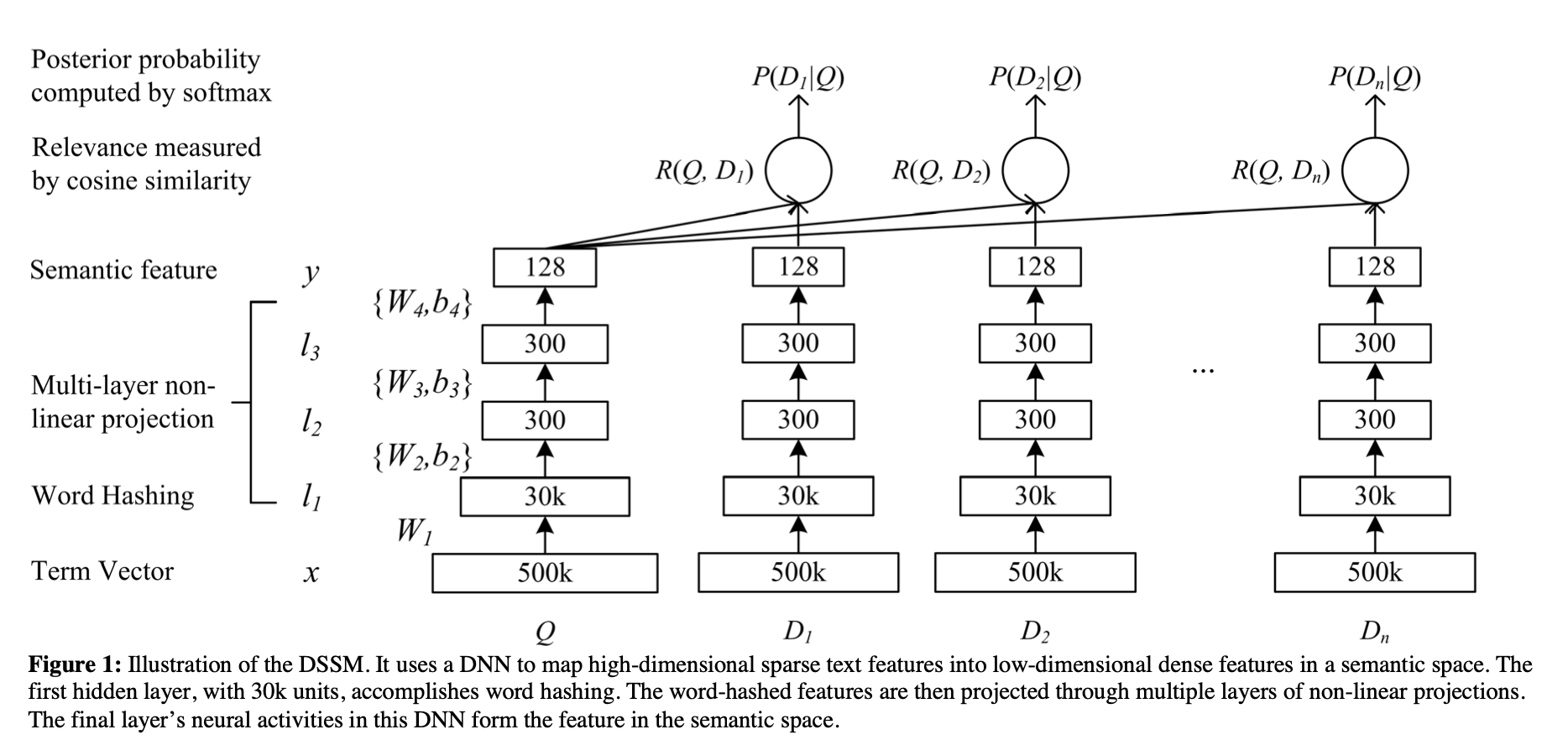
如论文中的图1所示,网络的输入是高维稀疏的文本词袋特征词向量(可以理解为ont-hot向量),比如查询或文档中单词的计数,输出是低维语义空间中的稠密向量。