目录
1.算法描述
2.仿真效果预览
3.MATLAB核心程序
4.完整MATLAB
1.算法描述
OCR(Optical Character Recognition)即光学字符识别技术,是通过扫描仪把印刷体或手写体文稿扫描成图像,然后识别成相应的计算机可直接处理的字符。OCR是模式识别的一个分支,按字体分类主要分为印刷体识别和手写体识别两大类。对于印刷体识别又可以分成单一字体单一字号和多种字体多种字号几类。而手写体识别又可分为受限手写体和不受限手写体两类;按识别方式可分为在线识别和脱机识别两类。
字符识别处理的信息可分为两大类:一类是文字信息,处理的主要是用各国家、各民族的文字(如:汉字,英文等)书写或印刷的文本信息,目前在印刷体和联机手写方面技术已趋向成熟,并推出了很多应用系统;另一类是数据信息,主要是由阿拉伯数字及少量特殊符号组成的各种编号和统计数据,如:邮政编码、统计报表、财务报表、银行票据等等,处理这类信息的核心技术是手写数字识别。
在整个OCR领域中,最为困难的就是脱机自由手写字符的识别。到目前为止,尽管人们在脱机手写英文、汉字识别的研究中已取得很多可喜成就,但距离实用还有一定距离。而在手写数字识别这个方向上,经过多年研究,研究工作者已经开始把它向各种实际应用推广,为手写数据的高速自动输入提供了一种解决方案。
手写数字识别有着极为广泛的应用前景,这也正是它受到世界各国的研究工作者重视的一个主要原因。下面将介绍一些以手写数字识别技术为基础的典型应用。
(一)手写数字识别在大规模数据统计中的应用
在大规模的数据统计[12](如:行业年鉴、人口普查等)中,需要输入大量的数据,以前需要手工输入,需要耗费大量的人力和物力。近年来在这类工作中采用OCR技术已成为一种趋势。因为在这种应用中,数据的录入是集中组织的,所以往往可以通过专门设计表格和对书写施加限制以便于机器的自动识别。
目前国内的大多数实用系统都要求用户按指定规范在方格内填写。另外,这些系统往往采用合适的用户界面对识别结果做全面的检查,最终保证结果正确无误[4]。可以看出,这是一类相对容易的应用,对识别核心算法的要求比较低,是目前国内很多单位应用开发的热点。
(二)手写数字识别在财务、税务、金融领域中的应用
财务、税务、金融是手写数字识别大有可为的又一领域。随着我国经济的迅速发展,每天等待处理的财务、税务报表、支票、付款单等越来越多。如果能把它们用计算机自动处理,无疑可以节约大量的时间、金钱和劳力。与上面提到的大规模数据统计处理相比,在这个领域的应用难度更大,原因有:
1、对识别的精度要求更高;
2、处理的表格通常不止一种,所以一个系统应具有智能地同时处理若干种表格的能力;
3、由于处理贯穿于整个日常工作之中,书写应尽量按一般习惯(如:不对书写者的写法做限定,书写时允许写连续的字串,而不是在固定的方格内书写),这样对识别及预处理的核心算法要求也提高了。
对待识别数字的预处理进行了介绍,包括二值化、噪声处理、图像分割、归一化、细化等图像处理方法;其次,探讨了数字字符特征向量的提取;最后采用了bp神经网络算法,并以MATLAB作为编程工具实现了具有友好的图形用户界面的自由手写体数字识别系统。
————————————————
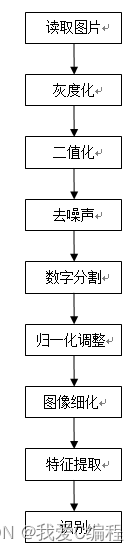
2.仿真效果预览
matlab2022a仿真结果如下:
3.MATLAB核心程序
% 数字识别
% 生成输入向量和目标向量
clear all;
'LOADING......'
filename =dir('nums\*.bmp');
for kk = 0:99
p1=zeros(16,16); %建立全为1的样本矩阵
m=strcat('nums\',filename(kk+1).name);
x=imread(m,'bmp'); %循环读入0-99个样本数字文件
if(length(size(x))==3)
x = rgb2gray(x); %将图像转灰度
end
% figure,imshow(x);title('原始黑白图像');
bw=im2bw(x,0.5);
% grd=edge(x,'canny');%用canny算子识别强度图像中的边界
% figure,imshow(grd);
[l,r]=size(bw);
bw1=bw;
for i=1:l
for j=1:r
if bw1(i,j)==0
bw1(i,j)=1;
else
bw1(i,j)=0;
end
end
end
%figure,imshow(bw1);
[i,j]=find(bw1==1);
imin=min(i);
imax=max(i);
jmin=min(j);
jmax=max(j);
bw2=bw1(imin:imax,jmin:jmax); %截取是入图像中的数字部分
%figure,imshow(bw2);
rate=16/max(size(bw2));
bw2=imresize(bw2,rate); %对输入文件变尺寸处理
[i,j]=size(bw2);
i1=round((16-i)/2);
j1=round((16-j)/2);
p1(i1+1:i1+i,j1+1:j1+j)=bw2; %建立起16*16的矩阵
%figure,imshow(p1);
p1 = bwmorph(p1,'thin',inf);%图像细化
% figure,imshow(p1);
for m=0:15
if(0<=m&&m<=3)
mm=(m+1)*4;
p(m+1,kk+1)=length(find(p1(1:4,mm-3:mm)==1));%第一到第四块方格内像素值为1的总数
end
if(4<=m&&m<=7)
mm=(m-3)*4;
p(m+1,kk+1)=length(find(p1(5:8,mm-3:mm)==1));%第五到第八块方格内像素值为1的总数
end
if(8<=m&&m<=11)
mm=(m-7)*4;
p(m+1,kk+1)=length(find(p1(9:12,mm-3:mm)==1));%第九到第十二块方格内像素值为1的总数
end
if(12<=m&&m<=15)
mm=(m-11)*4;
p(m+1,kk+1)=length(find(p1(13:16,mm-3:mm)==1));%第十三到十六块方格内像素值为1的总数
end
end
p(17,kk+1)=length(find(p1(4 ,1:16)==1));%第四行线上像素值为1的总数
p(18,kk+1)=length(find(p1(8 ,1:16)==1));%第八行线上像素值为1的总数
p(19,kk+1)=length(find(p1(12,1:16)==1));%第十二行线上像素值为1的总数
p(20,kk+1)=length(find(p1(1:16, 4)==1));%第四列线上像素值为1的总数
p(21,kk+1)=length(find(p1(1:16, 8)==1));%第八列线上像素值为1的总数
p(22,kk+1)=length(find(p1(1:16,12)==1));%第十二列线上像素值为1的总数
s1=0;
for zz=1:16
xx=17-zz;
s1=p1(zz,xx)+s1;
p(23,kk+1)=s1;%y=x线上像素值为1的总数
end
s2=0;
for zz=1:16
s2=p1(zz,zz)+s2;
p(24,kk+1)=s2;%y=-x线上像素值为1的总数
end
%将处理的源样本输入供神经网络训练的样本 pcolum是样本数循环变量
switch kk
case{0,1,2,3,4,5,6,7,8,9}
t(1:4,kk+1)=[0.01,0.01,0.01,0.01]; %数字0
case{10,11,12,13,14,15,16,17,18,19}
t(1:4,kk+1)=[0.01,0.01,0.01,0.99]; %数字1
case{20,21,22,23,24,25,26,27,28,29}
t(1:4,kk+1)=[0.01,0.01,0.99,0.01]; %数字2
case{30,31,32,33,34,35,36,37,38,39}
t(1:4,kk+1)=[0.01,0.01,0.99,0.99]; %数字3
case{40,41,42,43,44,45,46,47,48,49}
t(1:4,kk+1)=[0.01,0.99,0.01,0.01]; %数字4
case{50,51,52,53,54,55,56,57,58,59}
t(1:4,kk+1)=[0.01,0.99,0.01,0.99]; %数字5
case{60,61,62,63,64,65,66,67,68,69}
t(1:4,kk+1)=[0.01,0.99,0.99,0.01]; %数字6
case{70,71,72,73,74,75,76,77,78,79}
t(1:4,kk+1)=[0.01,0.99,0.99,0.99]; %数字7
case{80,81,82,83,84,85,86,87,88,89}
t(1:4,kk+1)=[0.99,0.01,0.01,0.01]; %数字8
case{90,91,92,93,94,95,96,97,98,99}
t(1:4,kk+1)=[0.99,0.01,0.01,0.99]; %数字9
end
end %建立与训练样本对应的输出值t
'LOAD OK.'
save numberPT p t;
% 创建和训练BP网络
clear all;
load numberPT p t; %加载样本
%创建BP网络
net=newff(minmax(p),[14 4],{'logsig' 'purelin'}, 'traingdx', 'learngdm');
% 当前输入层权值和阈值
inputWeights=net.IW{1,1}
inputbias=net.b{1}
% 当前网络层权值和阈值
layerWeights=net.LW{2,1}
layerbias=net.b{2}
net.trainParam.epochs=25000; %设置训练步数
net.trainParam.goal=0.001; %设置训练目标
net.trainParam.show=10; %设置训练显示格数
net.trainParam.lr=0.05; %设置训练学习率 w
[net,tr]=train(net,p,t); %训练BP网络
'TRAIN OK.'
save numbernet net;
% 识别
for times=0:99
clear all;
p1=ones(16,16);
load numbernet net;
test=input('FileName:', 's');
x=imread(test,'bmp');
bw=im2bw(x,0.5);
[i,j]=find(bw==0);
imin=min(i);
imax=max(i);
jmin=min(j);
jmax=max(j);
bw1=bw(imin:imax,jmin:jmax); %截取是入图像中的数字部分
rate=16/max(size(bw1));
bw1=imresize(bw1,rate); %对输入文件变尺寸处理
[i,j]=size(bw1);
i1=round((16-i)/2);
j1=round((16-j)/2);
p1(i1+1:i1+i,j1+1:j1+j)=bw1; %建立起16*16的矩阵
p1=-1.*p1+ones(16,16);%反色处理
p1 = bwmorph(p1,'thin',inf);
for m=0:15
if(0<=m&&m<=3)
mm=(m+1)*4;
p(m+1,1)=length(find(p1(1:4,mm-3:mm)==1));
end
if(4<=m&&m<=7)
mm=(m-3)*4;
p(m+1,1)=length(find(p1(5:8,mm-3:mm)==1));
end
if(8<=m&&m<=11)
mm=(m-7)*4;
p(m+1,1)=length(find(p1(9:12,mm-3:mm)==1));
end
if(12<=m&&m<=15)
mm=(m-11)*4;
p(m+1,1)=length(find(p1(13:16,mm-3:mm)==1));
end
end
p(17,1)=length(find(p1(4 ,1:16)==1));
p(18,1)=length(find(p1(8 ,1:16)==1));
p(19,1)=length(find(p1(12,1:16)==1));
p(20,1)=length(find(p1(1:16, 4)==1));
p(21,1)=length(find(p1(1:16, 8)==1));
p(22,1)=length(find(p1(1:16,12)==1));
s1=0;
for zz=1:16
xx=17-zz;
s1=p1(zz,xx)+s1;
p(23,1)=s1;
end
s2=0;
for zz=1:16
s2=p1(zz,zz)+s2;
p(24,1)=s2;
end
[a,Pf,Af]=sim(net,p); %测试网络
imshow(p1);
a=round(a);
a=a(1,1)*8+a(2,1)*4+a(3,1)*2+a(4,1)%输出网络识别结果
end
A1224.完整MATLAB
V






![[附源码]Node.js计算机毕业设计高校迎新管理系统Express](https://img-blog.csdnimg.cn/99a919287aa54d9e8de02a2d53c788d3.png)