文章目录
- 一、意义
- 二、修改源码获取
- 三、自动标注前期准备
- 四、开始自动标注
- 五、可视化标注效果
- 六、XML转换TXT
一、意义
通过界面化操作YOLOv5完成数据集的自动标注的意义在于简化数据标注的流程,提高标注的效率和准确性。
传统的数据集标注通常需要手动绘制边界框或标记关键点,这个过程费时费力且容易出错。而通过界面化操作YOLOv5完成数据集的自动标注,可以实现自动识别目标并生成标注结果,极大地减轻了标注人员的工作负担。
界面化操作YOLOv5完成数据集的自动标注还可以提高标注的准确性。由于YOLOv5是一种基于深度学习的目标检测算法,其具有较高的检测准确率和鲁棒性。通过使用YOLOv5进行自动标注,可以减少人为因素对标注结果的影响,提高标注的一致性和准确性。
此外,界面化操作YOLOv5完成数据集的自动标注还可以加速标注的速度。YOLOv5可以快速地对图像进行目标检测,自动生成标注结果。相比于手动标注,自动标注可以大大减少标注的时间成本,提高数据集的制作效率。
总的来说,通过界面化操作YOLOv5完成数据集的自动标注可以简化标注流程、提高标注准确性和加速标注速度,对于大规模数据集的制作和实时应用具有重要意义。
二、修改源码获取
获取链接下载:点击
三、自动标注前期准备
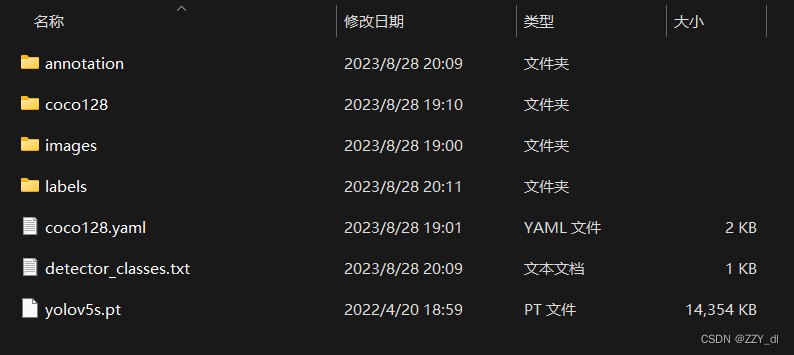
- annotions:里面为空,用于存放标注后的标签文件
- coco128:通过下载coco128数据集并将其转换为YOLO可运行的文件夹
- images
- train2017:用于存放coco128的图片文件
- labels
- train2017:用于存放coco128的TXT标签文件
- images
- images:存放想要标注的图片文件
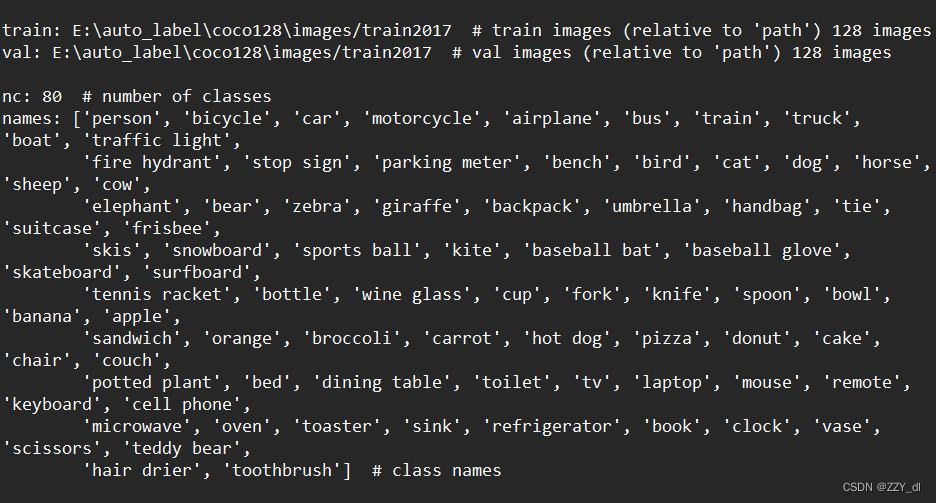
- coco128.yaml:
- detector_classes.txt:用于存放想要打标签的类别信息

- yolov5s.pt: 官方下载的对应YOLOv5的权重文件,可根据自己实际情况进行更换
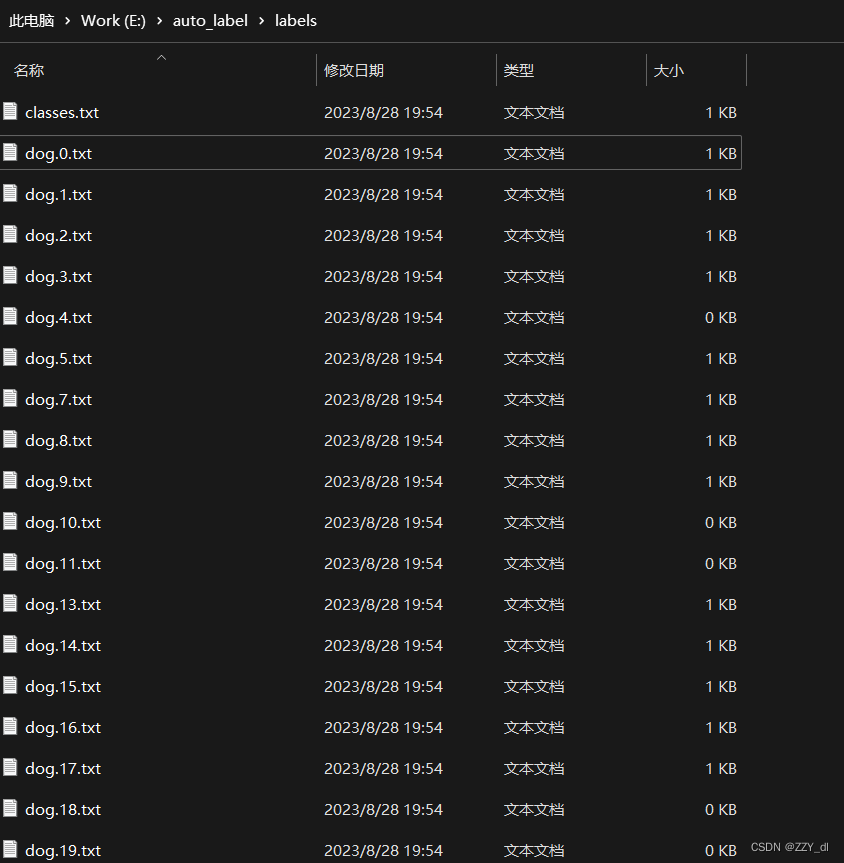
- labels:用与存放将XML转换成TXT的文件
四、开始自动标注
第一步:下载修改后源码,通过Pycharm打开
第二步:通过Anaconda配置好YOLOv5的依赖环境
第三步:运行detect_auto.py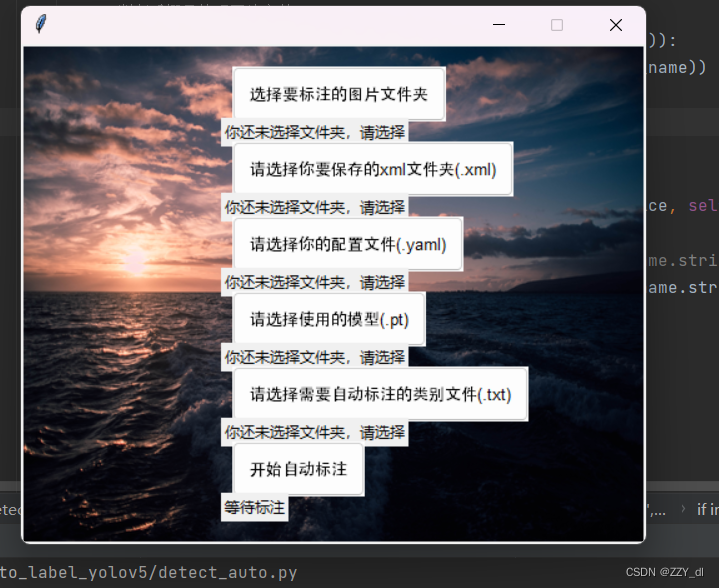
第四步:选择好对应的文件路径,一步一步点击,选择好的界面如下
第五步:点击开始自动标注,如果看到以下界面说明是没问题的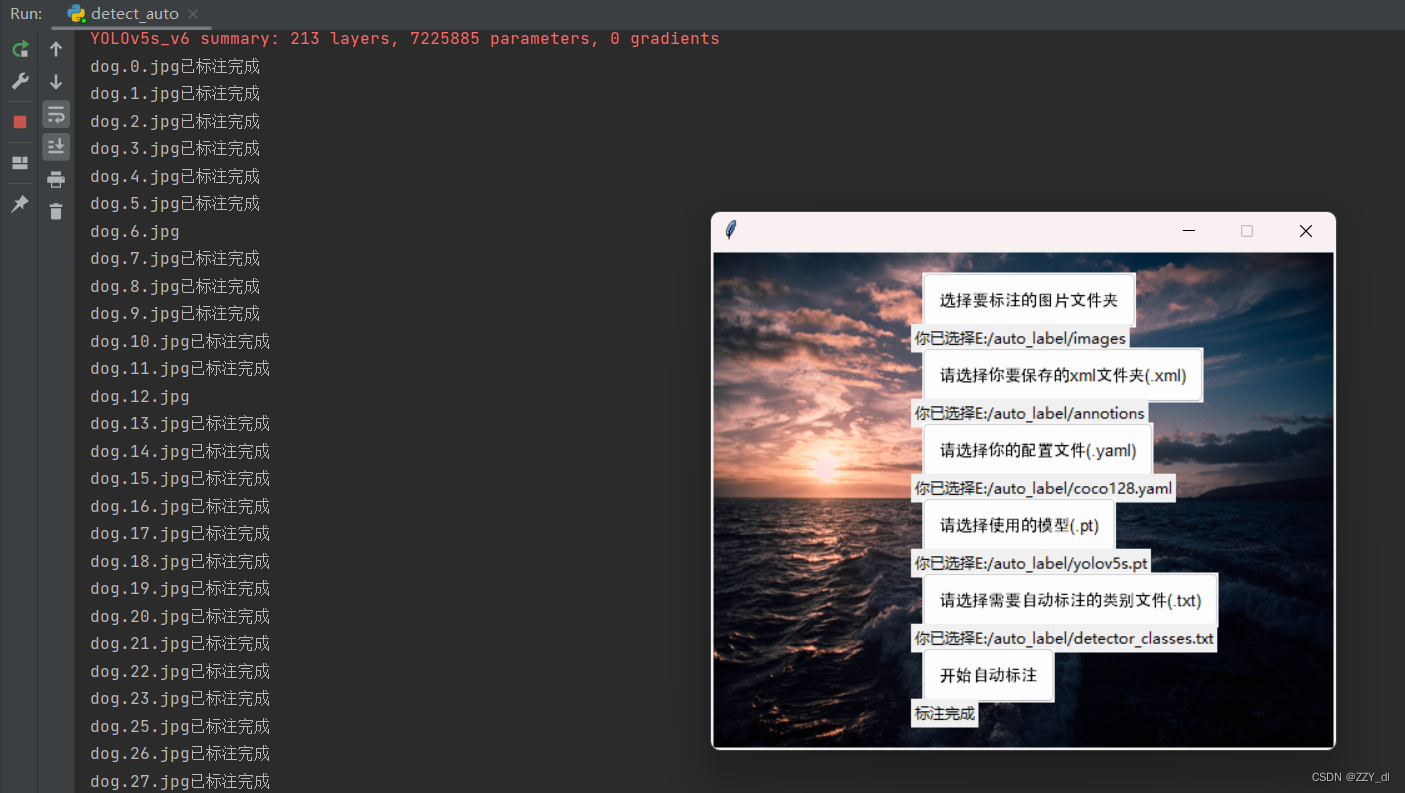
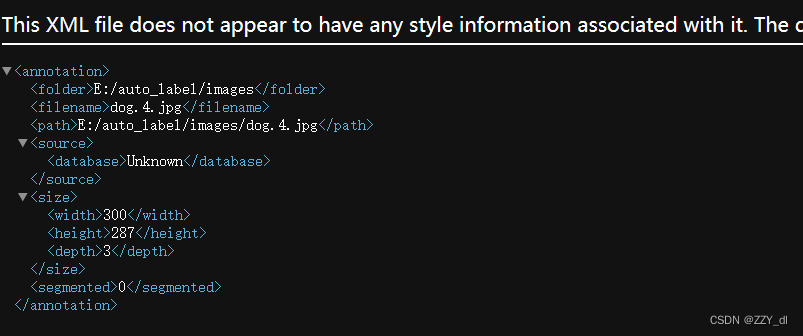
第六步:检查对应标签文件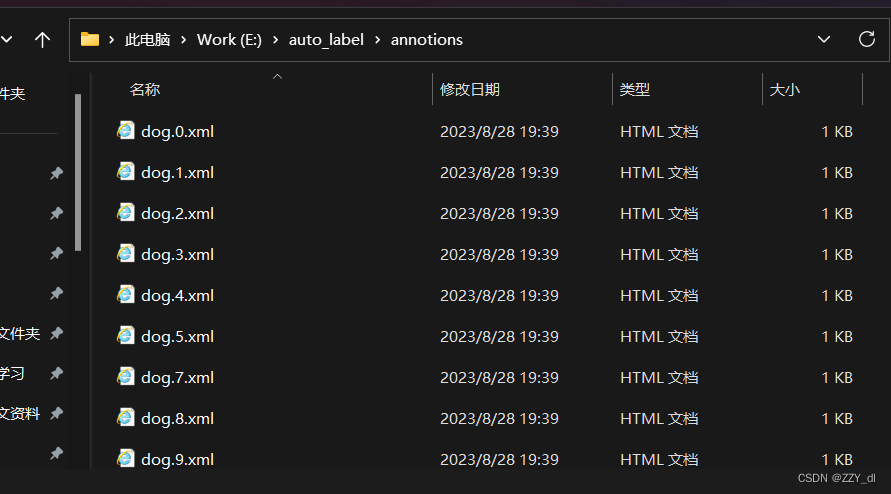
五、可视化标注效果
第一步:通过cmd输入labelImg,打开标注界面
第二步:把TXT标注文件和拷贝到图像所在文件夹下,把classes.txt也拷过来.然后在labelimg里opendir,labelimg里显示看到当时标注的矩形框了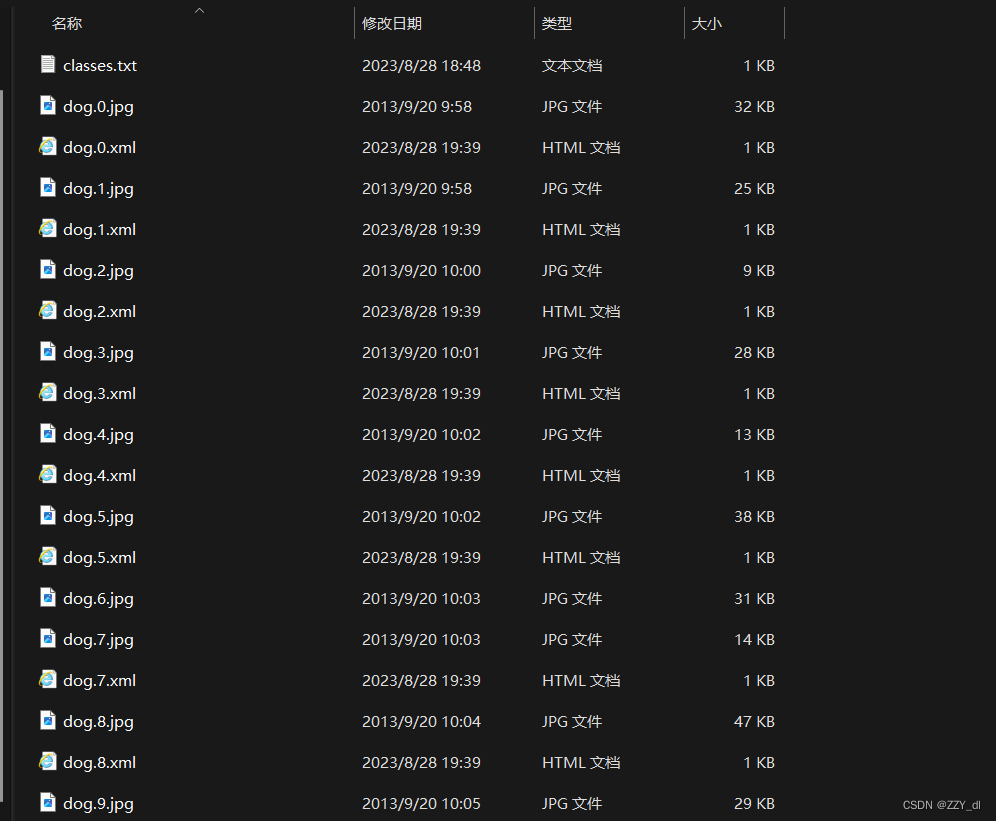

六、XML转换TXT
将我们标注后的XML文件以及结合原图片,将其转换为可用于YOLO训练的TXT文件,后续可更方便调用数据集来进行训练。
修改两个路径:xml文件地址和创建保存txt文件的地址
import os
import xml.etree.ElementTree as ET
# xml文件存放目录(修改成自己的文件名)
input_dir = r'E:\auto_label\annotation'
# 输出txt文件目录(自己创建的文件夹)
out_dir = r'E:\auto_label\labels'
class_list = []
# 获取目录所有xml文件
def file_name(input_dir):
F = []
for root, dirs, files in os.walk(input_dir):
for file in files:
# print file.decode('gbk') #文件名中有中文字符时转码
if os.path.splitext(file)[1] == '.xml':
t = os.path.splitext(file)[0]
F.append(t) # 将所有的文件名添加到L列表中
return F # 返回L列表
# 获取所有分类
def get_class(filelist):
for i in filelist:
f_dir = input_dir + "\\" + i + ".xml"
in_file = open(f_dir, encoding='UTF-8')
filetree = ET.parse(in_file)
in_file.close()
root = filetree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in class_list:
class_list.append(cls)
def ConverCoordinate(imgshape, bbox):
# 将xml像素坐标转换为txt归一化后的坐标
xmin, xmax, ymin, ymax = bbox
width = imgshape[0]
height = imgshape[1]
dw = 1. / width
dh = 1. / height
x = (xmin + xmax) / 2.0
y = (ymin + ymax) / 2.0
w = xmax - xmin
h = ymax - ymin
# 归一化
x = x * dw
y = y * dh
w = w * dw
h = h * dh
return x, y, w, h
def readxml(i):
f_dir = input_dir + "\\" + i + ".xml"
txtresult = ''
outfile = open(f_dir, encoding='UTF-8')
filetree = ET.parse(outfile)
outfile.close()
root = filetree.getroot()
# 获取图片大小
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
imgshape = (width, height)
# 转化为yolov5的格式
for obj in root.findall('object'):
# 获取类别名
obj_name = obj.find('name').text
obj_id = class_list.index(obj_name)
# 获取每个obj的bbox框的左上和右下坐标
bbox = obj.find('bndbox')
xmin = float(bbox.find('xmin').text)
xmax = float(bbox.find('xmax').text)
ymin = float(bbox.find('ymin').text)
ymax = float(bbox.find('ymax').text)
bbox_coor = (xmin, xmax, ymin, ymax)
x, y, w, h = ConverCoordinate(imgshape, bbox_coor)
txt = '{} {} {} {} {}\n'.format(obj_id, x, y, w, h)
txtresult = txtresult + txt
# print(txtresult)
f = open(out_dir + "\\" + i + ".txt", 'a')
f.write(txtresult)
f.close()
# 获取文件夹下的所有文件
filelist = file_name(input_dir)
# 获取所有分类
get_class(filelist)
# 打印class
print(class_list)
# xml转txt
for i in filelist:
readxml(i)
# 在out_dir下生成一个class文件
f = open(out_dir + "\\classes.txt", 'a')
classresult = ''
for i in class_list:
classresult = classresult + i + "\n"
f.write(classresult)
f.close()


![[蓝桥复盘] 算法赛内测赛2 20230831](https://img-blog.csdnimg.cn/c6028a3fcb144c28aedf8f657d6ec321.png)