配置环境
装conda
wget https://repo.anaconda.com/archive/Anaconda3-5.3.0-Linux-x86_64.sh
chmod +x Anaconda3-5.3.0-Linux-x86_64.sh
./Anaconda3-5.3.0-Linux-x86_64.sh
export PATH=~/anaconda3/bin:$PATH # 或者写到环境保护变量
# 不会弄看这吧 https://blog.csdn.net/wyf2017/article/details/118676765
- Clone this repository and navigate to LLaVA folder
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
- Install Package
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
- Install additional packages for training cases
pip install ninja
pip install flash-attn==1.0.8 --no-build-isolation
配置拉模型的工具
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
apt-get install git-lfs
git lfs install
下载llama模型
模型选择:
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | LLaVA-Bench-Conv | LLaVA-Bench-Detail | LLaVA-Bench-Complex | LLaVA-Bench-Overall | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| Vicuna-13B-v1.3 | CLIP-L-336px | LCS-558K | 1e | LLaVA-Instruct-80K | proj-1e, lora-1e | 64.3 | 55.9 | 81.7 | 70.1 | LoRA LoRA-Merged |
| LLaMA-2-13B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | 56.7 | 58.6 | 80.0 | 67.9 | ckpt |
| LLaMA-2-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | lora-1e | 51.2 | 58.9 | 71.6 | 62.8 | LoRA |
下载LLaMA-2-13B-Chat示例:
git lfs clone https://huggingface.co/liuhaotian/llava-llama-2-13b-chat-lightning-preview
下载Projector权重
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
--mm_use_im_start_end False
--mm_use_im_patch_token False
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|---|---|---|---|---|
| LLaMA-2-13B-Chat | CLIP-L-336px | LCS-558K | 1e | projector |
| LLaMA-2-7B-Chat | CLIP-L-336px | LCS-558K | 1e | projector |
| LLaMA-2-13B-Chat | CLIP-L | LCS-558K | 1e | projector |
| LLaMA-2-7B-Chat | CLIP-L | LCS-558K | 1e | projector |
| Vicuna-13B-v1.3 | CLIP-L-336px | LCS-558K | 1e | projector |
| Vicuna-7B-v1.3 | CLIP-L-336px | LCS-558K | 1e | projector |
| Vicuna-13B-v1.3 | CLIP-L | LCS-558K | 1e | projector |
| Vicuna-7B-v1.3 | CLIP-L | LCS-558K | 1e | projector |
git lfs clone https://huggingface.co/liuhaotian/llava-pretrain-llama-2-13b-chat
下载完的结构
./llava-llama-2-13b-chat-lightning-preview
├── config.json
├── generation_config.json
├── LICENSE
├── mm_projector.bin
├── pytorch_model-00001-of-00003.bin
├── pytorch_model-00002-of-00003.bin
├── pytorch_model-00003-of-00003.bin
├── pytorch_model.bin.index.json
├── README.md
├── special_tokens_map.json
├── tokenizer_config.json
└── tokenizer.model
./llava-pretrain-llama-2-13b-chat
├── config.json
├── mm_projector.bin
└── README.md
测试demo
# 第一个终端运行
python3 -m llava.serve.controller --host 0.0.0.0 --port 10000
# 第二个终端运行
python3 -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --share
# 第三个终端运行
python3 -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path ./checkpoints/LLaVA-13B-v0
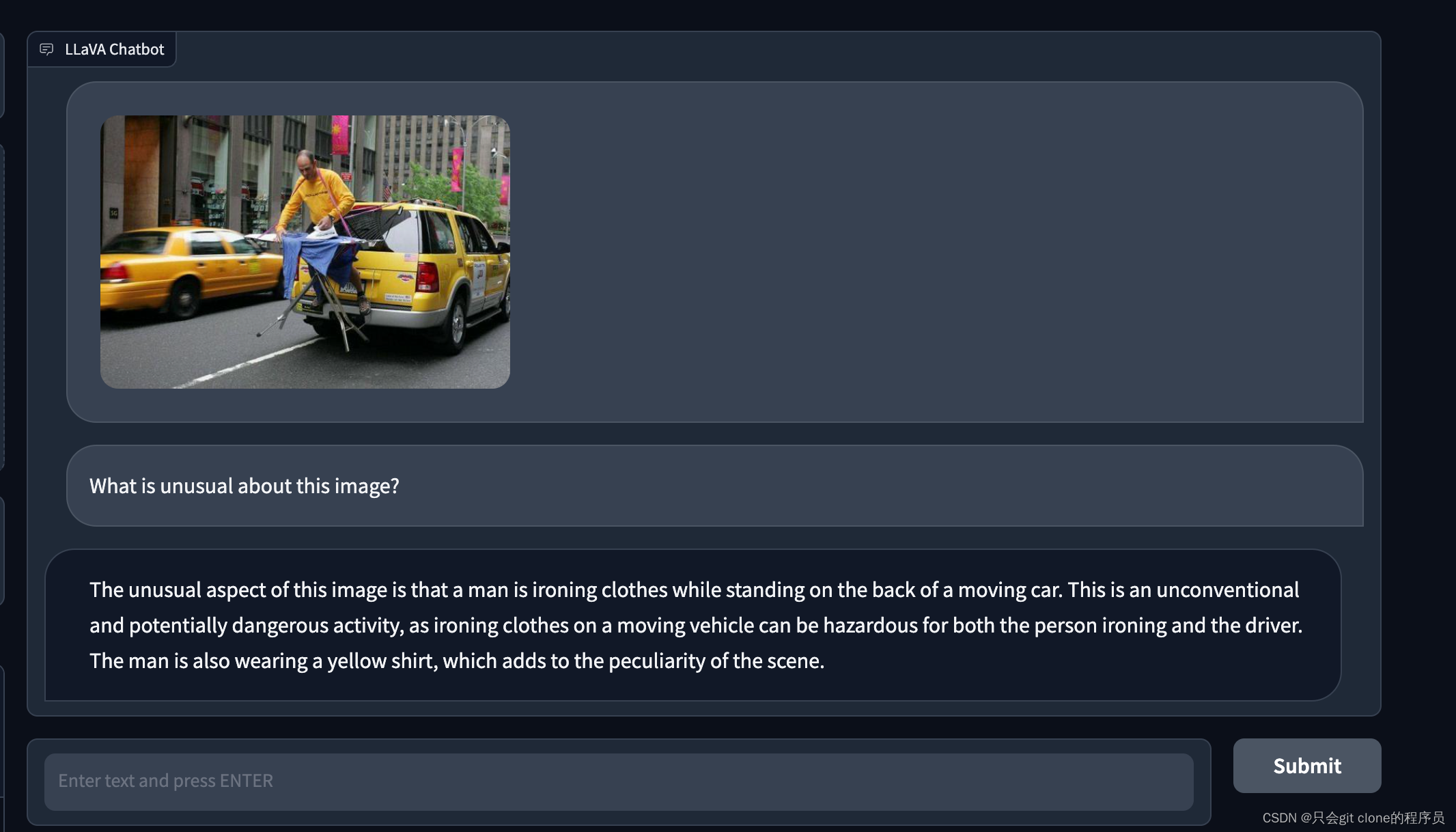
测试结果

选择刚才加载的模型后,随便问就行了。
训练
预训练就不跑了,直接拿他训好的权重finetune就是了,所以跑下finetune
下载标注文件:
git lfs clone https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
下载训练数据:
wget http://images.cocodataset.org/zips/train2017.zip
训练数据格式:
外层是list,里面其中一条长这样
{
"id": "000000379143",
"image": "000000379143.jpg",
"conversations": [
{
"from": "human",
"value": "What is the man doing in the back of the pickup truck?\n<image>"
},
{
"from": "gpt",
"value": "The man is sitting on top of piled objects or belongings loaded into the back of a pickup truck."
},
{
"from": "human",
"value": "Is the man holding anything in his hands?"
},
{
"from": "gpt",
"value": "Yes, the man is holding a beer in his hand while sitting on top of the objects in the back of the pickup truck."
},
{
"from": "human",
"value": "What color is the pickup truck?"
},
{
"from": "gpt",
"value": "The pickup truck is white."
},
{
"from": "human",
"value": "Is the man sitting or standing?"
},
{
"from": "gpt",
"value": "The man is sitting on top of the piled objects in the back of the pickup truck."
},
{
"from": "human",
"value": "What could be the possible reasons for the man sitting on top of the possessions in the back of the pickup truck?"
},
{
"from": "gpt",
"value": "There could be several reasons for the man sitting on top of his possessions in the back of the pickup truck:\n\n1. Moving: The man might be moving to a new location and needed to transport his items in a pickup truck, utilizing available space efficiently. By sitting on top of the belongings, he could be helping to stabilize and secure the items during the move, preventing them from falling or shifting during transportation.\n\n2. Lack of seating: If the cab of the pickup truck is already at full capacity or there isn't enough space for him to sit inside, the man may have chosen to sit on his possessions as an alternative seating arrangement.\n\n3. Road trip or outing: The man might be on a road trip or a casual outing with friends or family, where he is using the back of the pickup truck as an open-air seating area. By sitting on top of the loaded items, he may be enjoying the journey while savoring his beer.\n\n4. Keeping an eye on belongings: The man could be safeguarding his possessions by staying close to them, ensuring that no items are lost, stolen or damaged during the journey.\n\nRegardless of the specific reason, the image shows a person making the most of their situation, adding a touch of lightheartedness or adventure to an otherwise mundane scene."
}
]
},