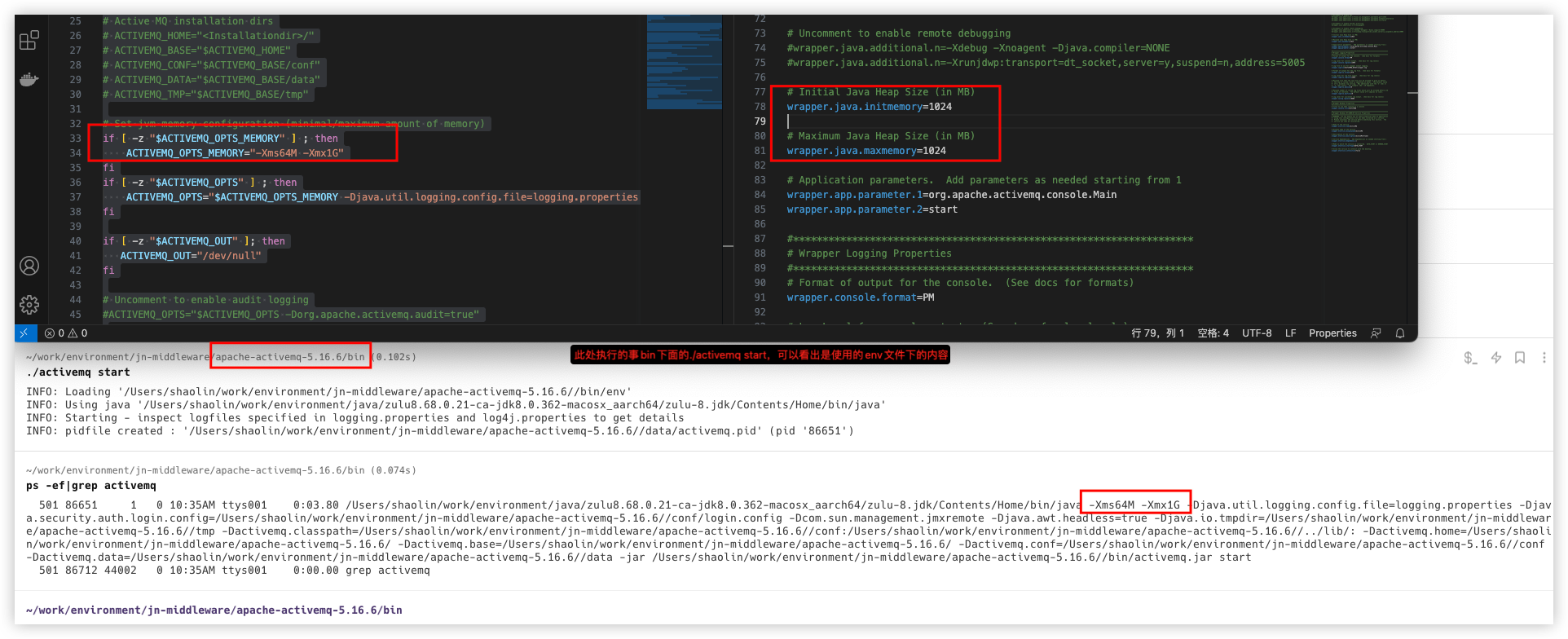
在 web 自动化测试当中, selenium 架构应该是很难绕过的,很多宣称要超 selenium 的下一代 web 自动化测试框架最终都败下阵来。 不过, selenium 的 api 确实比较复杂,所以也有很多库尝试对他进行上层封装,splinter 是其中发展得最好的一个。 这篇文章,我们介绍 splinter 的简单入门,如果你觉得 selenium 已经足够好用,也可以参考 splinter 的设计,对 selenium 二次封装。
快速使用
# 导入浏览器
from splinter import Browser
# 开启 chrome 浏览器
browser = Browser("chrome")
# 访问网址
browser.visit('http://www.baidu.com')
浏览器会自动开启:

安装
- pip install splinter
- 安装浏览器驱动,驱动和浏览器型号版本要对应。
驱动下载步骤:
- 打开下载地址:https://npm.taobao.org/mirrors/chromedriver
- 选择驱动版本。 比如使用的是 chrome 浏览器 v78, 则对应可以下载 78 版本的驱动
- 解压 chromedriver.exe 文件,放到环境变量中(比如 python 根目录下)。
浏览器选项
from splinter import Browser
from selenium import webdriver
# 添加浏览器选项
options = webdriver.ChromeOptions()
options.add_argument('--start-maximized')
options.add_argument('--disable-notifications')
# 无头浏览器选项,开启之后,不会再有界面出现
browser = Browser('chrome', options=options, headless=True)
browser.visit("http://www.baidu.com")
元素查找
元素查找的方式基本上沿用了 selenium:
- id
- name
- css 选择器
- xpath
# 通过id查找
input_element = browser.find_by_id('kw')
# 通过css选择器查找
browser.find_by_css('h1')
# 通过id查找
browser.find_by_xpath('//h1')
browser.find_by_tag('h1')
browser.find_by_name('name')
browser.find_by_text('Hello World!')
browser.find_by_id('firstheader')
但是也新增了一些用得比较多的方式:
- text 文本
- href 属性
- value 属性
browser.find_by_text()
browser.find_link_by_href()
browser.find_by_value('query')
查找方式有很多,但是其实作用不大,反而造成了框架代码的紊乱,不如就直接保留 xpath 和 css 就够了。
其实元素查找有更精简的 __call__ 方式来实现,有时间再说,这里就不深入了。
等待
相比于 selenium 的等待,splinter 的友好性要好很多。你可以在初始化浏览器的时候就设置一个全局等待时间,接下来所有的元素查找都会根据这个超时时间进行元素查找:
browser = Browser('chrome', wait_time=4)
判断和匹配:
用过 selenium 的可能会对显示等待的使用方式很苦恼,实在是难用,splinter 的 matcher 机制类似于显示等待,当然,更好用一些:
# 当 h1 元素出现
#返回 True or False
browser.is_element_present_by_css('h1', wait_time=6)
虽然更加容易使用,但是这种方式还是和元素查找存在同样的问题:api 太庞杂,一看源码直接晕了。小伙伴们,你们能想到精简办法吗?:

input 元素输入
browser.visit("http://www.baidu.com")
# 通过 name 直接输入
browser.fill('wd', )
窗口管理和切换
窗口管理和切换是 splinter 最值得使用的地方,因为 selenium 管理窗口的方式非常原始,不自己封装几乎无法正常使用。
splinter 用一个专门的 Window 类来管理窗口:
# 列举所有窗口,得到 Windows 对象
browser.windows
# 通过索引获取某个 Window 对象
browser.windows[0]
# 通过窗口名称获取某个 Window 对象
browser.windows[window_name]
# 获取当前窗口
browser.windows.current
# 设置当前窗口
browser.windows.current = browser.windows[3]
# 判断某一个窗口是否是当前窗口
window.is_current
# 打开下一个窗口
window.next
# 打开上一个窗口
window.prev
splinter 对于窗口管理的实现非常有意思,对 python 魔术方法和描述符了解的同学可以去看下源码。 iframe 切换用到了上下文管理器,你只需要这样就可以完成 iframe 切换,并且每次执行完会自动退出:
with get_iframe('iframe_name') as frame:
frame.find_by_id('id_value')
总结
- splinter 相比 selenium 更加容易使用,但是由于只是在 selenium 的外面套一层壳,整个架构和流程并没有发生变化;
- splinter 的 api 管理比较庞杂,对于一些很少用到的方法, 不管就行了;
- splinter 对于浏览器的一些复杂操作做了很好的封装: windows 管理 iframe 切换 select 选择器处理 鼠标操作 尤其是表单和 input 的输入更加精简
- 缺乏对文件上传的处理
- 元素查找和管理还有待优化