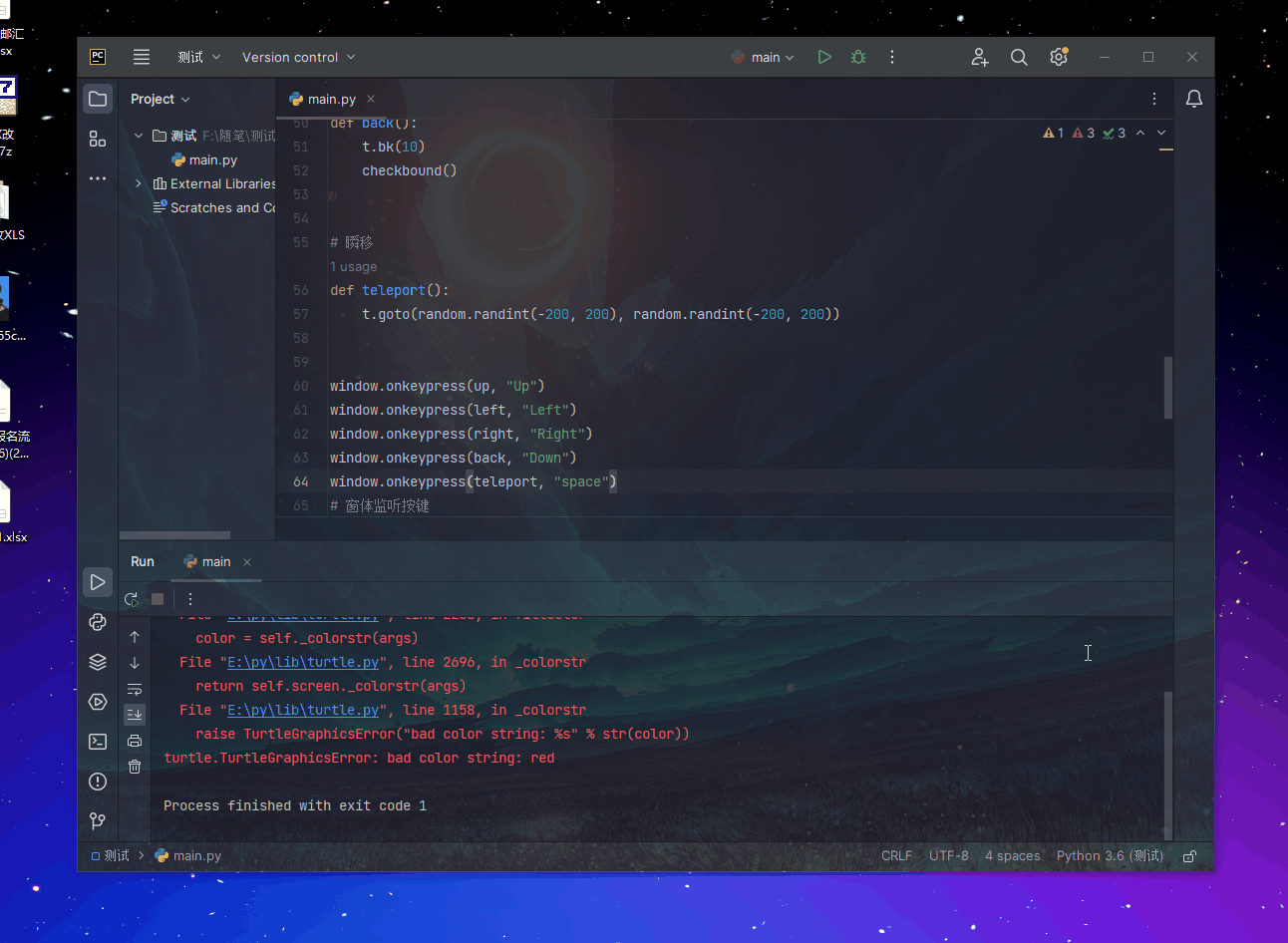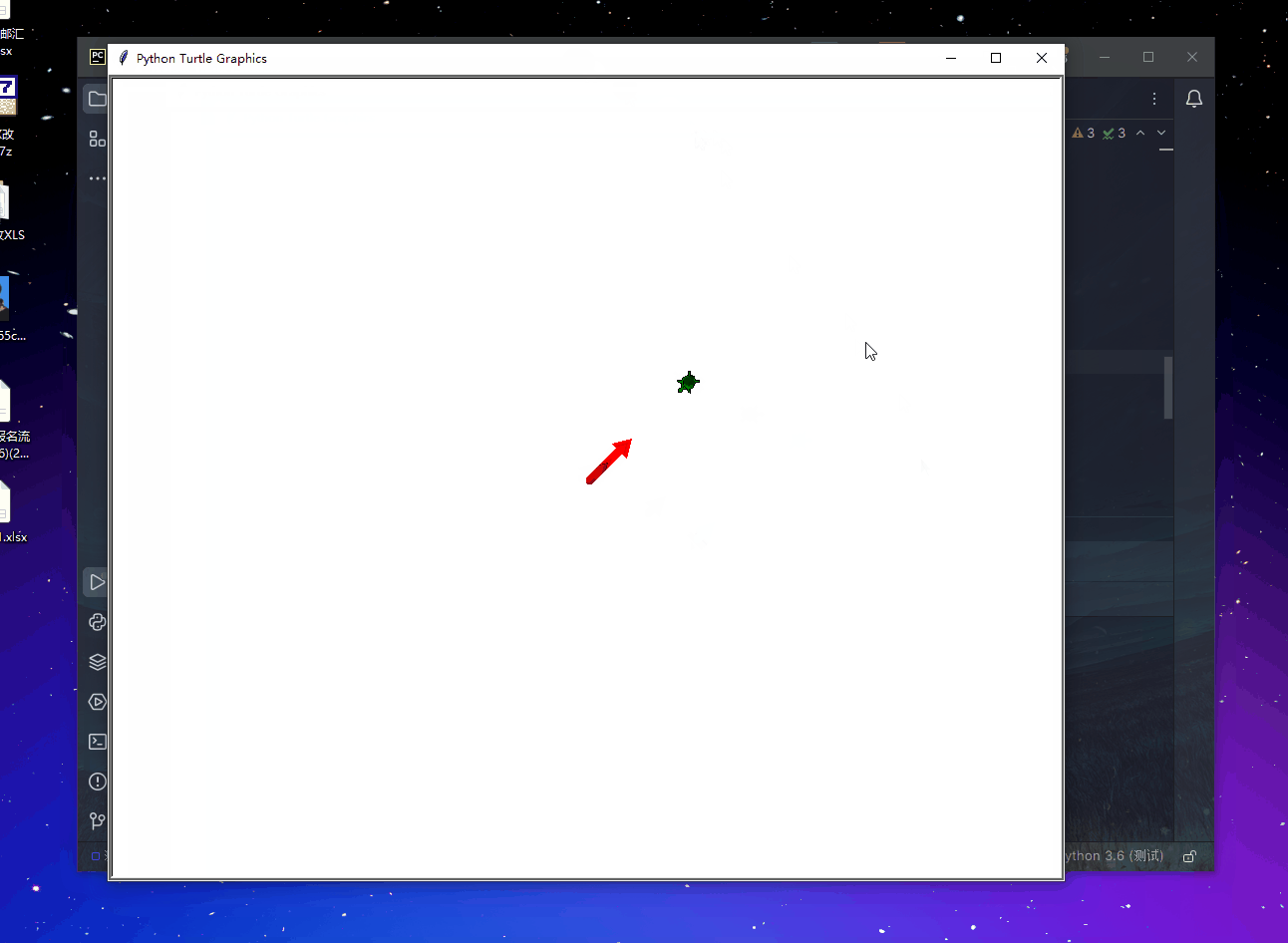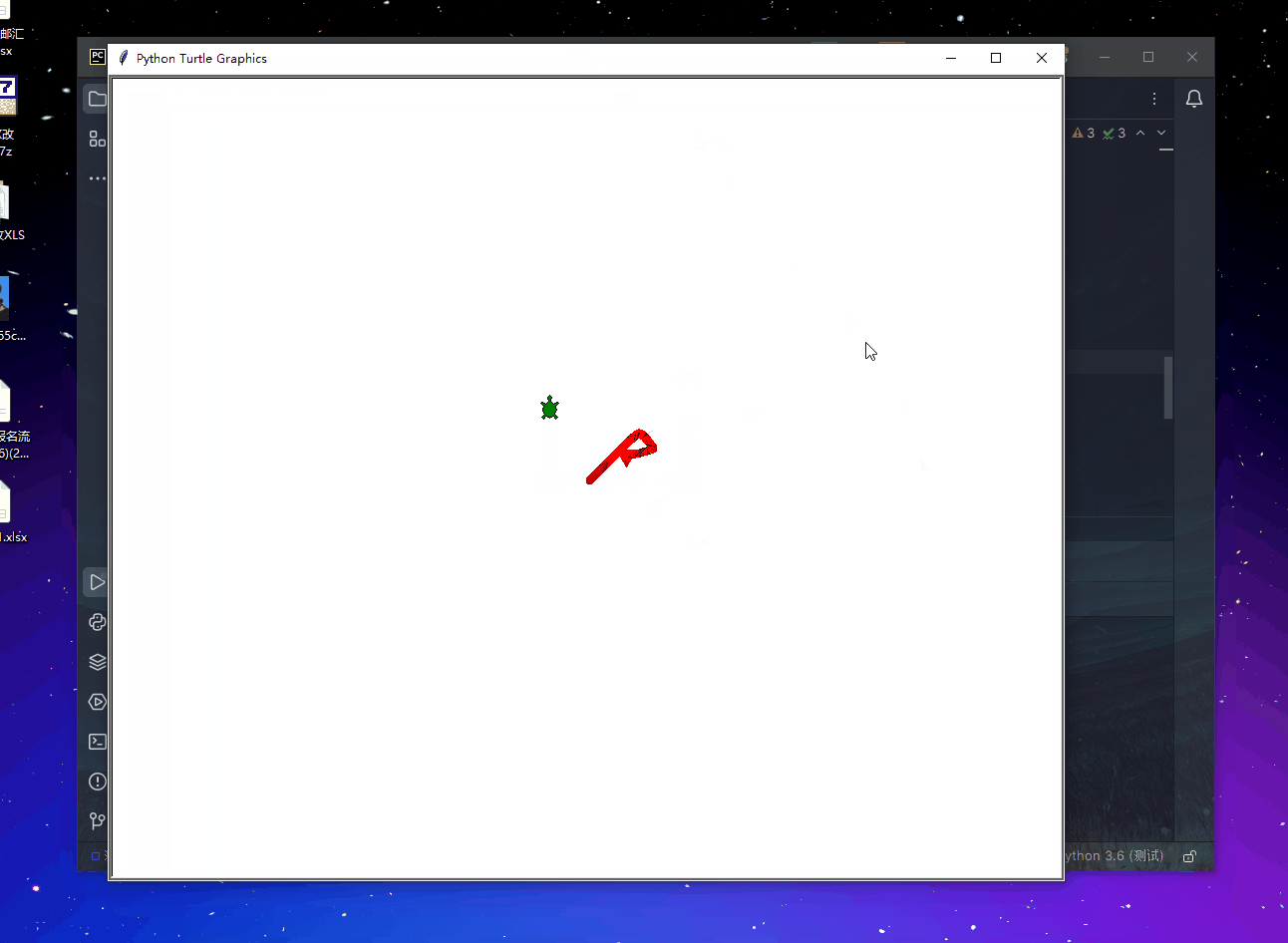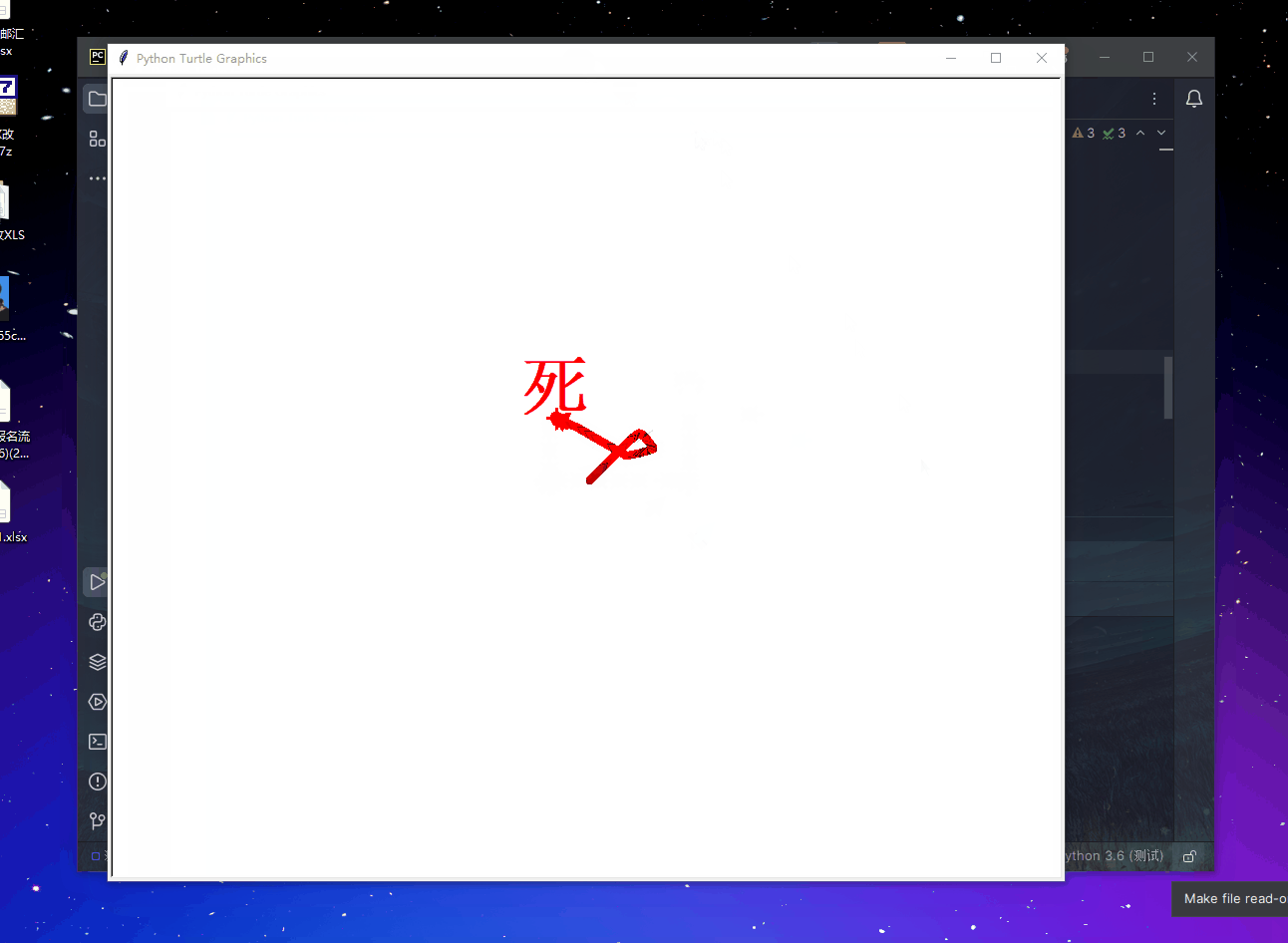
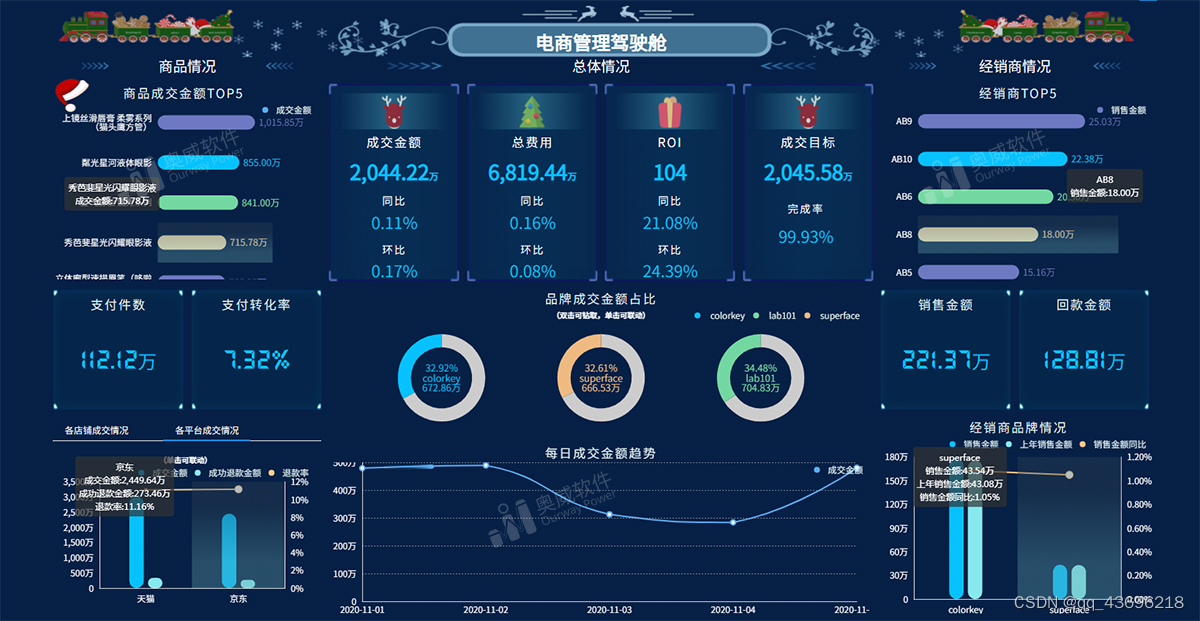
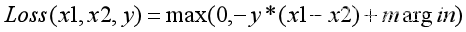Hive的安装部署
注意hive就是
一个构建数据仓库的工具,只需要在一台服务器上安装就可以了,不需要在多台服务器上安装。此处以安装到node03为例;
请大家保持统一使用
hadoop普通用户操作
1.1 先决条件
- 搭建好三节点Hadoop集群;
- node03上先安装好MySQL服务;
1.2 准备安装包
-
下载hive的安装包
- http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.14.2.tar.gz
-
规划安装目录
- /opt/install
-
上传安装包到node03服务器中的/opt/soft路径下
1.3 解压
- 解压安装包到指定的规划目录/opt/install
[hadoop@node03 ~]$ cd /opt/soft/
[hadoop@node03 soft]$ tar -xzvf hive-1.1.0-cdh5.14.2.tar.gz -C /opt/install/
1.4 修改配置文件
-
修改
配置文件hive-env.sh- 进入到Hive的安装目录下的conf文件夹中
[hadoop@node03 soft]$ cd /opt/install/hive-1.1.0-cdh5.14.2/conf/- 重命名hive-env.sh.template
[hadoop@node03 conf]$ mv hive-env.sh.template hive-env.sh- 修改hive-env.sh
[hadoop@node03 conf]$ vim hive-env.sh- 如下,修改此文件中HADOOP_HOME、HIVE_CONF_DIR的值(根据自己机器的实际情况配置)
#配置HADOOP_HOME路径 export HADOOP_HOME=/opt/install/hadoop-2.6.0-cdh5.14.2/ #配置HIVE_CONF_DIR路径 export HIVE_CONF_DIR=/opt/install/hive-1.1.0-cdh5.14.2/conf注意:HADOOP_HOME前要手动加上export关键字
-
修改
配置文件hive-site.xml- conf目录下默认没有此文件,vim创建即可
[hadoop@node03 conf]$ vim hive-site.xml- 文件内容如下
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&characterEncoding=latin1&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>node03</value> </property> </configuration>-
修改
日志配置文件hive-log4j.properties- 创建hive日志存储目录
[hadoop@node03 conf]$ mkdir -p /opt/install/hive-1.1.0-cdh5.14.2/logs/- 重命名生成文件hive-log4j.properties
[hadoop@node03 conf]$ pwd /opt/install/hive-1.1.0-cdh5.14.2/conf [hadoop@node03 conf]$ mv hive-log4j.properties.template hive-log4j.properties [hadoop@node03 conf]$ vim hive-log4j.properties # 修改文件- 修改此文件的hive.log.dir属性的值
#更改以下内容,设置我们的hive的日志文件存放的路径,便于排查问题
hive.log.dir=/opt/install/hive-1.1.0-cdh5.14.2/logs/
1.5 拷贝mysql驱动包
-
上传mysql驱动包,如
mysql-connector-java-5.1.38.jar到/opt/soft目录中 -
由于运行hive时,需要向mysql数据库中读写元数据,所以
需要将mysql的驱动包上传到hive的lib目录下
[hadoop@node03 ~]$ cd /opt/soft/
[hadoop@node03 soft]$ cp mysql-connector-java-5.1.38.jar /opt/install/hive-1.1.0-cdh5.14.2/lib/
1.6 配置Hive环境变量
- 切换到root用户下
[hadoop@node03 soft]$ su root
Password:
- 打开
/etc/profile文件
[root@node03 soft]# vim /etc/profile
- 末尾添加如下内容
export HIVE_HOME=/opt/install/hive-1.1.0-cdh5.14.2
export PATH=$PATH:$HIVE_HOME/bin
- 切换回hadoop用户,并source
[root@node03 soft]# su hadoop
[hadoop@node03 soft]$ source /etc/profile
1.7 验证安装
hadoop集群已启动mysql服务已启动- 在node03上任意目录启动hive cli命令行客户端
[hadoop@node03 ~]$ hive
- 查看有哪些数据库
show databases;

- 说明hive安装成功
- 退出cli
quit;