Yolov8魔改–加入GiraffeDet模型提高小目标效果
VX搜索晓理紫关注并回复有yolov8-GiraffeDet获取代码
[晓理紫]
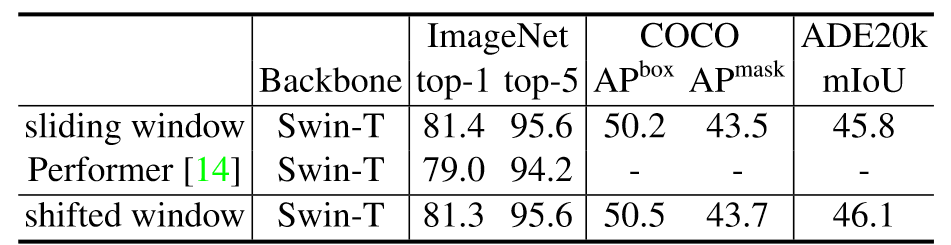
1 GiraffeDet模型
GiraffeDet是一种新颖的粗颈范例,一种类似长颈鹿的网络,用于高效的目标检测。 GiraffeDet 使用极其轻量的主干和非常深且大的颈部模块,鼓励不同空间尺度以及不同级别的潜在语义同时进行密集的信息交换。 这种设计范式使得检测器即使在网络的早期阶段也可以以相同的优先级处理高层语义信息和低层空间信息,使其在检测任务中更加有效。 对多个流行目标检测基准的数值评估表明,GiraffeDet 在各种资源限制下始终优于以前的 SOTA 模型。网络源码

2 yolov8引入GiraffeDet
为了提高yolov8对小目标的检测效果,可以在yolov8中引入GiraffeDet网络,在大部分数据集中可以有不错的效果。引入方法如下。
2.1 加入GiraffeDet模型
在ultralytics/nn/modules/中创建module_GiraffeDet.py,并把下面代码写入
import torch
import torch.nn as nn
import torch.nn.functional as F
__all__ = 'RepConv', 'Swish', 'ConvBNAct', 'BasicBlock_3x3_Reverse', 'SPP','CSPStage'
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
'''Basic cell for rep-style block, including conv and bn'''
result = nn.Sequential()
result.add_module(
'conv',
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepConv(nn.Module):
'''RepConv is a basic rep-style block, including training and deploy status
Code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
'''
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1,
dilation=1,
groups=1,
padding_mode='zeros',
deploy=False,
act='relu',
norm=None):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
if isinstance(act, str):
self.nonlinearity = get_activation(act)
else:
self.nonlinearity = act
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = None
self.rbr_dense = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=stride,
padding=padding_11,
groups=groups)
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(
self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(
kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3),
dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(
branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(
in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size,
stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding,
dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups,
bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class Swish(nn.Module):
def __init__(self, inplace=True):
super(Swish, self).__init__()
self.inplace = inplace
def forward(self, x):
if self.inplace:
x.mul_(F.sigmoid(x))
return x
else:
return x * F.sigmoid(x)
def get_activation(name='silu', inplace=True):
if name is None:
return nn.Identity()
if isinstance(name, str):
if name == 'silu':
module = nn.SiLU(inplace=inplace)
elif name == 'relu':
module = nn.ReLU(inplace=inplace)
elif name == 'lrelu':
module = nn.LeakyReLU(0.1, inplace=inplace)
elif name == 'swish':
module = Swish(inplace=inplace)
elif name == 'hardsigmoid':
module = nn.Hardsigmoid(inplace=inplace)
elif name == 'identity':
module = nn.Identity()
else:
raise AttributeError('Unsupported act type: {}'.format(name))
return module
elif isinstance(name, nn.Module):
return name
else:
raise AttributeError('Unsupported act type: {}'.format(name))
def get_norm(name, out_channels, inplace=True):
if name == 'bn':
module = nn.BatchNorm2d(out_channels)
else:
raise NotImplementedError
return module
class ConvBNAct(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self,
in_channels,
out_channels,
ksize,
stride=1,
groups=1,
bias=False,
act='silu',
norm='bn',
reparam=False,
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
if norm is not None:
self.bn = get_norm(norm, out_channels, inplace=True)
if act is not None:
self.act = get_activation(act, inplace=True)
self.with_norm = norm is not None
self.with_act = act is not None
def forward(self, x):
x = self.conv(x)
if self.with_norm:
x = self.bn(x)
if self.with_act:
x = self.act(x)
return x
def fuseforward(self, x):
return self.act(self.conv(x))
class BasicBlock_3x3_Reverse(nn.Module):
def __init__(self,
ch_in,
ch_hidden_ratio,
ch_out,
act='relu',
shortcut=True):
super(BasicBlock_3x3_Reverse, self).__init__()
assert ch_in == ch_out
ch_hidden = int(ch_in * ch_hidden_ratio)
self.conv1 = ConvBNAct(ch_hidden, ch_out, 3, stride=1, act=act)
self.conv2 = RepConv(ch_in, ch_hidden, 3, stride=1, act=act)
self.shortcut = shortcut
def forward(self, x):
y = self.conv2(x)
y = self.conv1(y)
if self.shortcut:
return x + y
else:
return y
class SPP(nn.Module):
def __init__(
self,
ch_in,
ch_out,
k,
pool_size,
act='swish',
):
super(SPP, self).__init__()
self.pool = []
for i, size in enumerate(pool_size):
pool = nn.MaxPool2d(kernel_size=size,
stride=1,
padding=size // 2,
ceil_mode=False)
self.add_module('pool{}'.format(i), pool)
self.pool.append(pool)
self.conv = ConvBNAct(ch_in, ch_out, k, act=act)
def forward(self, x):
outs = [x]
for pool in self.pool:
outs.append(pool(x))
y = torch.cat(outs, axis=1)
y = self.conv(y)
return y
class CSPStage(nn.Module):
def __init__(self,
ch_in,
ch_out,
n=1,
block_fn='BasicBlock_3x3_Reverse',
ch_hidden_ratio=1.0,
act='silu',
spp=False):
super(CSPStage, self).__init__()
split_ratio = 2
ch_first = int(ch_out // split_ratio)
ch_mid = int(ch_out - ch_first)
self.conv1 = ConvBNAct(ch_in, ch_first, 1, act=act)
self.conv2 = ConvBNAct(ch_in, ch_mid, 1, act=act)
self.convs = nn.Sequential()
next_ch_in = ch_mid
for i in range(n):
if block_fn == 'BasicBlock_3x3_Reverse':
self.convs.add_module(
str(i),
BasicBlock_3x3_Reverse(next_ch_in,
ch_hidden_ratio,
ch_mid,
act=act,
shortcut=True))
else:
raise NotImplementedError
if i == (n - 1) // 2 and spp:
self.convs.add_module(
'spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13], act=act))
next_ch_in = ch_mid
self.conv3 = ConvBNAct(ch_mid * n + ch_first, ch_out, 1, act=act)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
mid_out = [y1]
for conv in self.convs:
y2 = conv(y2)
mid_out.append(y2)
y = torch.cat(mid_out, axis=1)
y = self.conv3(y)
return y
2.2 修改ultralytics/nn/modules/_init_.py文件
from .module_GiraffeDet import(CSPStage)
__all__ = ('Conv', 'Conv2', 'LightConv', 'RepConv', 'DWConv', 'DWConvTranspose2d', 'ConvTranspose', 'Focus',
'GhostConv', 'ChannelAttention', 'SpatialAttention', 'CBAM', 'Concat', 'TransformerLayer',
'TransformerBlock', 'MLPBlock', 'LayerNorm2d', 'DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3',
'C2f', 'C3x', 'C3TR', 'C3Ghost', 'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'Detect',
'Segment', 'Pose', 'Classify', 'TransformerEncoderLayer', 'RepC3', 'RTDETRDecoder', 'AIFI',
'DeformableTransformerDecoder', 'DeformableTransformerDecoderLayer', 'MSDeformAttn', 'MLP','CSPStage')
2.3 tasks.py注册(ultralytics/nn/tasks.py)
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,
Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus,
GhostBottleneck, GhostConv, Segment, CSPStage
)
`
在tasks.py的parse_model函数666行由
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3):
变为
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, CSPStage):
2.4 4、修改yolov8_GFPN.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, CSPStage, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, CSPStage, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, CSPStage, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, CSPStage, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
3 训练
3.1 环境配置
创建虚拟环境重新编译ultralytics并安装
pip3 install -r requirements.txt
python3 setup.py install
3.2 开始训练
yolo task=detect mode=train model=./ultralytics/cfg/models/v8/yolov8-GFPN.yaml pretrained=yolov8x.pt data=./ultralytics/cfg/datasets/data.yaml batch=36 epochs=1000 imgsz=640 workers=16 device=0 nbs=4
4 代码获取方式
VX搜索晓理紫关注并回复有yolov8-GiraffeDet获取代码
{晓理紫}喜分享,也很需要你的支持,喜欢留下痕迹哦!