前言:之前介绍了CUDA入门知识,对CUDA编程有了一个基本了解,但是实际写起来还是遇到很多问题,例如cpp文件该怎么调用cuda文件、cpu和gpu之间内存数据怎么交换、如何编写.cu和.cuh文件之类的。本篇文章将会以一个实现向量相加的代码实例,来搞懂前面的这些问题。
CUDA实例:向量相加
- 项目创建和配置
- 新建.cu和.cuh文件
- 编写.cu文件
- 编写.cuh文件
- 编写cpp文件
项目创建和配置
如果cuda还没有安装,可以参考我之前的博客“CUDA安装和配置”。
我安装的是CUDA 11.4版本,配置中所有给出的地址是CUDA安装的默认地址。如果你安装的不是默认地址,或者版本不同,请根据自己的需要去更改。
- 创建了一个C++控制台程序,也可以根据自己需求创建不同的C++项目。
- 配置CUDA的lib。
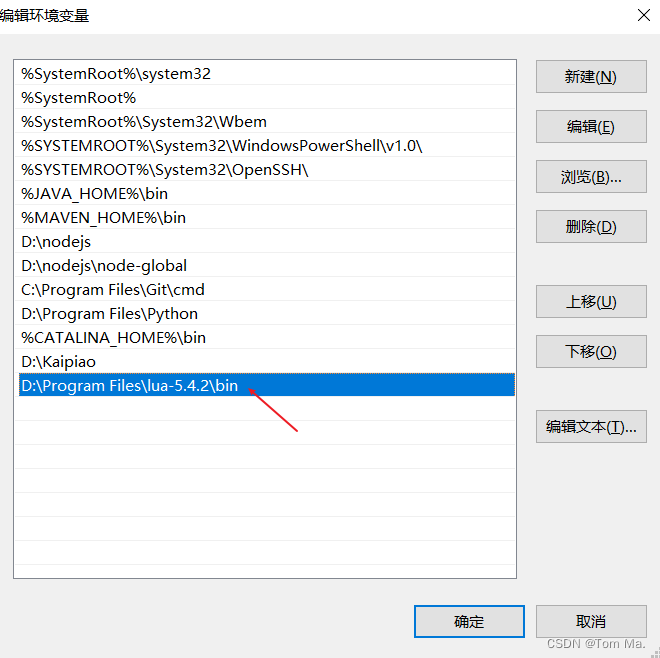
项目-属性-连接器-常规-附加库目录,补上cuda.lib所在的地址“C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib\x64”。
项目-属性-连接器-输入,补上cuda.lib。 - 配置CUDA的include。
项目-属性-VC++目录-包含目录,补上CUDA的include文件地址“C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\include”。 - 配置项目依赖项。
项目-生成依赖项-生成自定义-勾选CUDA选项。
新建.cu和.cuh文件
添加->新建项,选择新建cuh和cu文件。
头文件中新建cuda.cuh,源文件中新建cuda.cu。

编写.cu文件
先理解一下GPU内存管理的流程。
首先,CPU和GPU之间的数据是不共享的,所以要让GPU处理数据,除了要在GPU中分配内存,还需要把CPU的数据先传递到GPU。GPU数据处理完之后,需要把处理完的数据先传递回CPU,最后释放GPU分配的内存。
所以GPU内存管理的重要的功能就有四个:cudaMalloc(内存分配)、cudaMemcpy(数据传递)、cudaMemset(数据初始化)以及cudaFree(内存释放)。
目标是写一个GPU多线程运行的向量加法,一个线程负责一个向量维度的数相加。
#include"cuda.cuh"
#include <cuda_runtime.h>
#include<device_launch_parameters.h>
#include <stdio.h>
// 核函数:单独计算向量某一维的加法
__global__ void vecAdd(int *A,int *B,int *C) {
int tid=threadIdx.x;// 获取线程所在一维block的id,作为向量维度的索引
C[tid]=A[tid] + B[tid];
}
// 供CPP调用函数:GPU内存管理,调用核函数实现向量相加
void vecAddFun(int n,int* inA, int* inB,int *outC){
// n是向量维度
// A和B是两个输入向量,C是向量相加的结果
int* A, *B,*C;
// GPU开辟空间
cudaMalloc((void**)&A,n*sizeof(int));
cudaMalloc((void**)&B, n * sizeof(int));
cudaMalloc((void**)&C, n * sizeof(int));
// 把CPU数据拷贝到GPU
cudaMemcpy(A,inA, n * sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(B, inB, n * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(C, outC, n * sizeof(int), cudaMemcpyHostToDevice);
// GPU运行核函数
vecAdd<<< 1, n >>>(A, B, C);// n维向量,所以开1个block和n个线程
// 让CPU等GPU运行完
cudaDeviceSynchronize();
// 把GPU数据拷贝回CPU
cudaMemcpy(outC, C, n * sizeof(int), cudaMemcpyDeviceToHost);
// 释放GPU内存
cudaFree(A);
cudaFree(B);
cudaFree(C);
return;
}
编写.cuh文件
这个文件主要目的是为了方便cpp文件调用.cu文件的功能。
// ifndef的作用是为了防止头文件的重复包含和编译
#ifndef CUDA_H
#define CUDA_H
void vecAddFun(int n, int* inA, int* inB, int* outC);
#endif
编写cpp文件
cpp文件里面写了主函数,调用cuda文件。
效果,输入向量维度n,然后输入两个向量,最后会输出两个向量相加的结果。
#include <iostream>
#include "cuda.cuh"// 调用cuda头文件
using namespace std;
int main()
{
// n是向量的维度
// A和B是两个输入向量,C是向量相加的结果
int* A, * B, * C;
int n;
cin >> n;
A = (int*)malloc(n * sizeof(int));
B = (int*)malloc(n * sizeof(int));
C = (int*)malloc(n * sizeof(int));
for (int i = 0; i < n; i++) {
cin >> A[i];
}
for (int i = 0; i < n; i++) {
cin >> B[i];
}
vecAddFun(n, A, B, C);//调用cuda函数,进行向量相加
for (int i = 0; i < n; i++) {
cout << C[i] << " ";
}
cout << endl;
return 0;
}
结果: