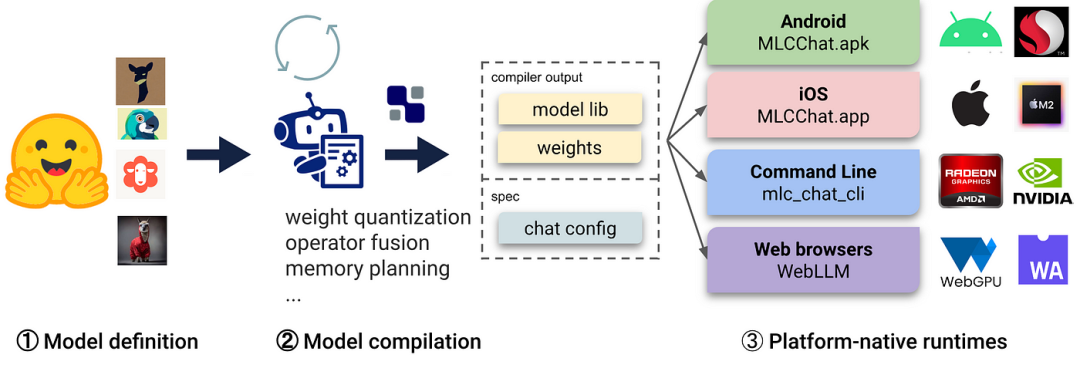
近年来,包括语言模型在内的生成式人工智能模型取得了巨大进步,特别是ChatGPT的发布,让大家看到了大语言模型的魅力。无论是计算机视觉,还是nlp领域的文本描述生成各种图像和视频,到执行机器翻译,文本生成等等大模型上,其都取得了令人意想不到的发展。但音乐与音频上似乎总是有点落后。是否可以使用人工智能技术来合成不同的音乐或者音效?
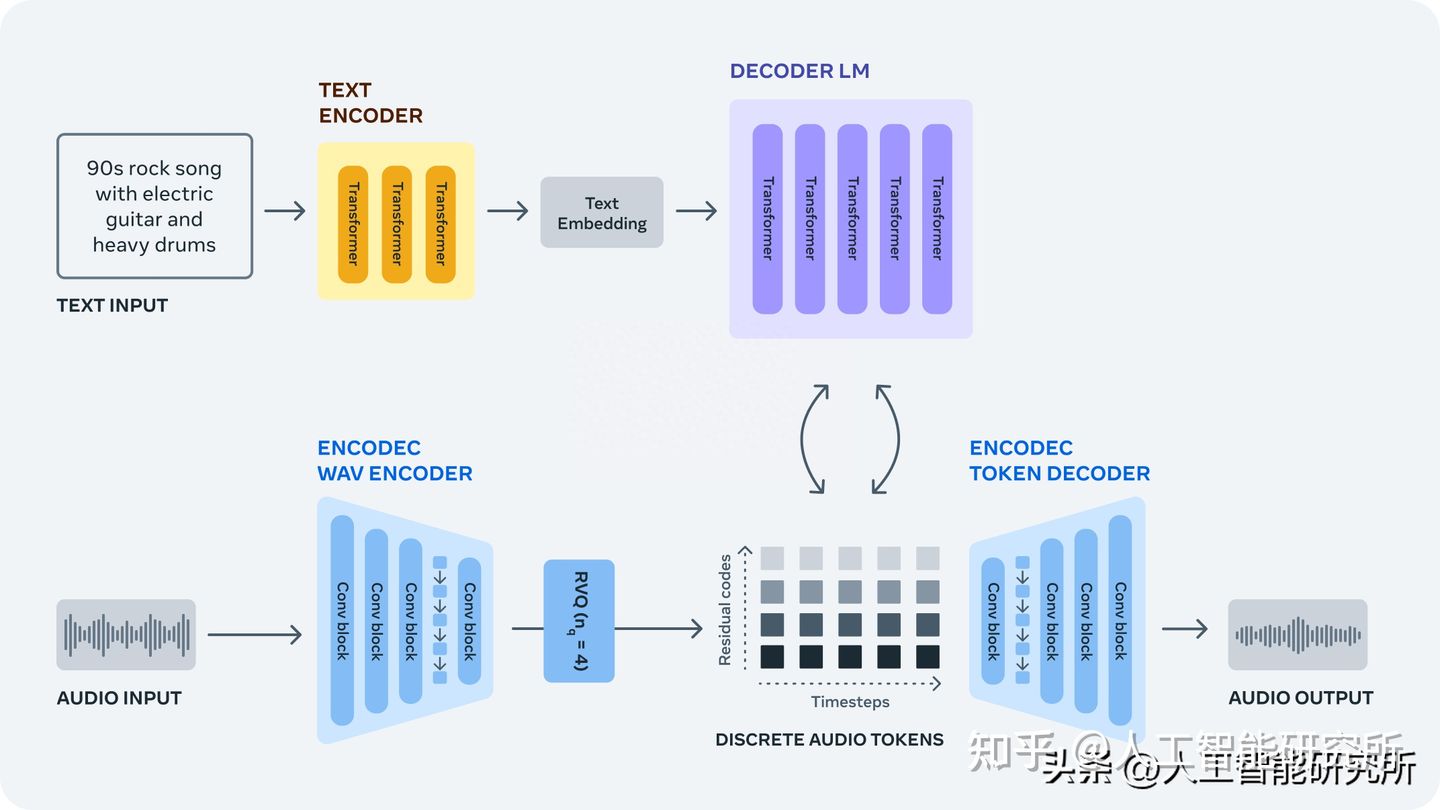
AudioCraft 包含三个模型:MusicGen、AudioGen和EnCodec。
MusicGen:使用 Meta 拥有且专门授权的音乐进行训练,根据用户输入的文本生成音乐。

AudioGen 使用公共音效进行训练,根据用户输入的文本生成音频音效。
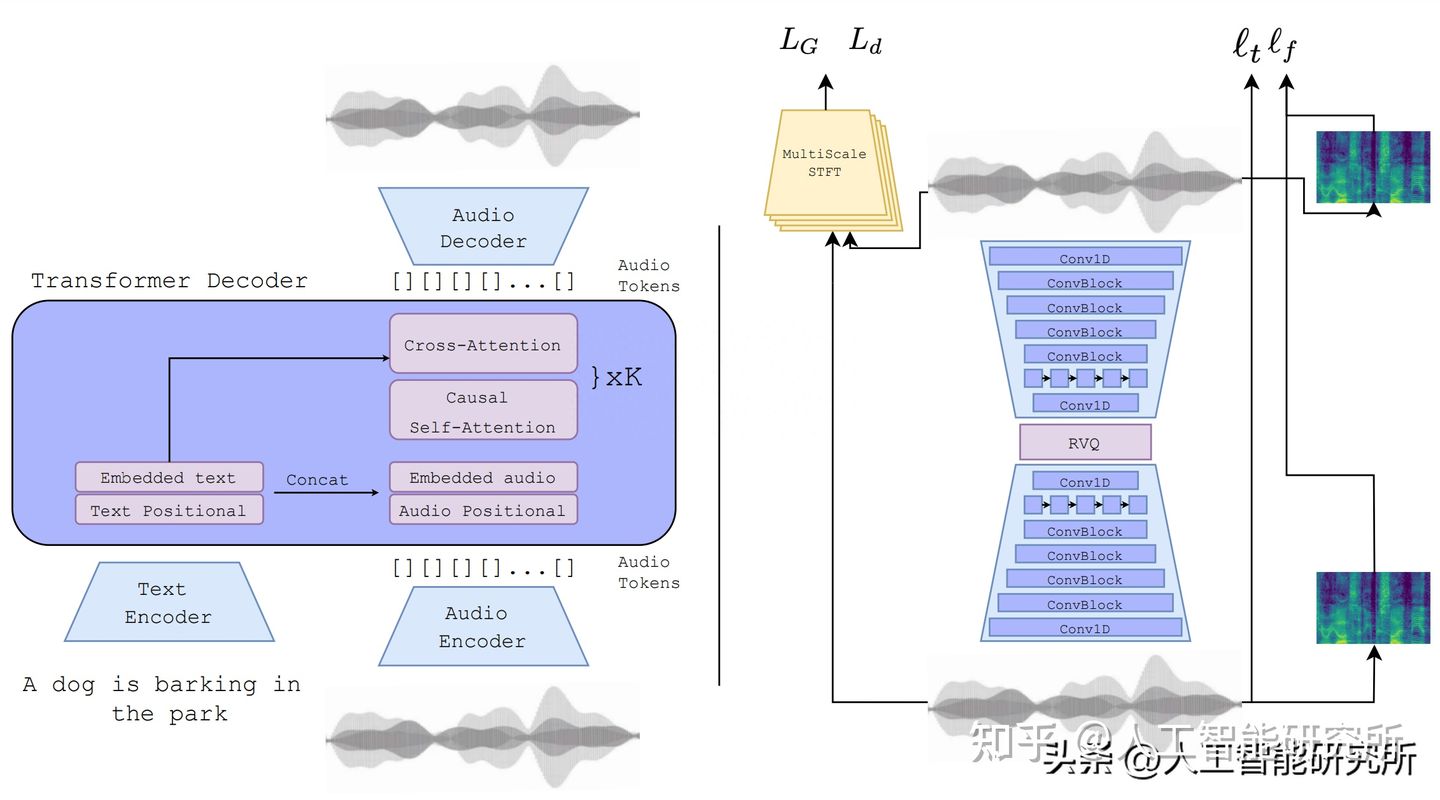
EnCodec 解码器,它可以用更少的音损生成更高质量的音乐,类似音频压缩技术。EnCodec 是一种有损神经编解码器,经过专门训练,可以压缩任何类型的音