转载至 https://www.cnblogs.com/king-lps/p/10748535.html
为避免原文丢失,因此原文转载作者【三年一梦】的帖子
前言
相信不少同学和我一样,在刚学完数据结构后开始刷算法题时,遇到递归的问题总是很头疼,而一看解答,却发现大佬们几行递归代码就优雅的解决了问题。从我自己的学习经历来看,刚开始理解递归思路都很困难,更别说自己写了。
我一直觉得刷算法题和应试一样,既然是应试就一定有套路存在。在刷题中,我总结出了一套解决递归问题的模版思路与解法,用这个思路可以秒解很多递归问题。
递归解题三部曲
何为递归?程序反复调用自身即是递归。
我自己在刚开始解决递归问题的时候,总是会去纠结这一层函数做了什么,它调用自身后的下一层函数又做了什么…然后就会觉得实现一个递归解法十分复杂,根本就无从下手。
相信很多初学者和我一样,这是一个思维误区,一定要走出来。既然递归是一个反复调用自身的过程,这就说明它每一级的功能都是一样的,因此我们只需要关注一级递归的解决过程即可。
实在没学过啥绘图的软件,就灵魂手绘了一波,哈哈哈勿喷。
如上图所示,我们需要关心的主要是以下三点:
-
整个递归的终止条件。
-
一级递归需要做什么?
-
应该返回给上一级的返回值是什么?
因此,也就有了我们解递归题的三部曲:
-
找整个递归的终止条件:递归应该在什么时候结束?
-
找返回值:应该给上一级返回什么信息?
-
本级递归应该做什么:在这一级递归中,应该完成什么任务?
一定要理解这3步,这就是以后递归秒杀算法题的依据和思路。
但这么说好像很空,我们来以题目作为例子,看看怎么套这个模版,相信3道题下来,你就能慢慢理解这个模版。之后再解这种套路递归题都能直接秒了。
例1:求二叉树的最大深度
先看一道简单的Leetcode题目: Leetcode 104. 二叉树的最大深度
题目很简单,求二叉树的最大深度,那么直接套递归解题三部曲模版:
-
找终止条件。 什么情况下递归结束?当然是树为空的时候,此时树的深度为0,递归就结束了。
-
找返回值。 应该返回什么?题目求的是树的最大深度,我们需要从每一级得到的信息自然是当前这一级对应的树的最大深度,因此我们的返回值应该是当前树的最大深度,这一步可以结合第三步来看。
-
本级递归应该做什么。 首先,还是强调要走出之前的思维误区,递归后我们眼里的树一定是这个样子的,看下图。此时就三个节点:root、root.left、root.right,其中根据第二步,root.left和root.right分别记录的是root的左右子树的最大深度。那么本级递归应该做什么就很明确了,自然就是在root的左右子树中选择较大的一个,再加上1就是以root为根的子树的最大深度了,然后再返回这个深度即可。

具体Java代码如下:
![]()
class Solution {
public int maxDepth(TreeNode root) {
//终止条件:当树为空时结束递归,并返回当前深度0
if(root == null){
return 0;
}
//root的左、右子树的最大深度
int leftDepth = maxDepth(root.left);
int rightDepth = maxDepth(root.right);
//返回的是左右子树的最大深度+1
return Math.max(leftDepth, rightDepth) + 1;
}
}
![]()
当足够熟练后,也可以和Leetcode评论区一样,很骚的几行代码搞定问题,让之后的新手看的一脸懵逼(这道题也是我第一次一行代码搞定一道Leetcode题):
class Solution {
public int maxDepth(TreeNode root) {
return root == null ? 0 : Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}
例2:两两交换链表中的节点
看了一道递归套路解决二叉树的问题后,有点套路搞定递归的感觉了吗?我们再来看一道Leetcode中等难度的链表的问题,掌握套路后这种中等难度的问题真的就是秒:Leetcode 24. 两两交换链表中的节点
直接上三部曲模版:
-
找终止条件。 什么情况下递归终止?没得交换的时候,递归就终止了呗。因此当链表只剩一个节点或者没有节点的时候,自然递归就终止了。
-
找返回值。 我们希望向上一级递归返回什么信息?由于我们的目的是两两交换链表中相邻的节点,因此自然希望交换给上一级递归的是已经完成交换处理,即已经处理好的链表。
-
本级递归应该做什么。 结合第二步,看下图!由于只考虑本级递归,所以这个链表在我们眼里其实也就三个节点:head、head.next、已处理完的链表部分。而本级递归的任务也就是交换这3个节点中的前两个节点,就很easy了。

附上Java代码:
![]()
class Solution {
public ListNode swapPairs(ListNode head) {
//终止条件:链表只剩一个节点或者没节点了,没得交换了。返回的是已经处理好的链表
if(head == null || head.next == null){
return head;
}
//一共三个节点:head, next, swapPairs(next.next)
//下面的任务便是交换这3个节点中的前两个节点
ListNode next = head.next;
head.next = swapPairs(next.next);
next.next = head;
//根据第二步:返回给上一级的是当前已经完成交换后,即处理好了的链表部分
return next;
}
}
![]()
例3:平衡二叉树
相信经过以上2道题,你已经大概理解了这个模版的解题流程了。
那么请你先不看以下部分,尝试解决一下这道easy难度的Leetcode题(个人觉得此题比上面的medium难度要难):Leetcode 110. 平衡二叉树
我觉得这个题真的是集合了模版的精髓所在,下面套三部曲模版:
-
找终止条件。 什么情况下递归应该终止?自然是子树为空的时候,空树自然是平衡二叉树了。
-
应该返回什么信息:
为什么我说这个题是集合了模版精髓?正是因为此题的返回值。要知道我们搞这么多花里胡哨的,都是为了能写出正确的递归函数,因此在解这个题的时候,我们就需要思考,我们到底希望返回什么值?
何为平衡二叉树?平衡二叉树即左右两棵子树高度差不大于1的二叉树。而对于一颗树,它是一个平衡二叉树需要满足三个条件:它的左子树是平衡二叉树,它的右子树是平衡二叉树,它的左右子树的高度差不大于1。换句话说:如果它的左子树或右子树不是平衡二叉树,或者它的左右子树高度差大于1,那么它就不是平衡二叉树。
而在我们眼里,这颗二叉树就3个节点:root、left、right。那么我们应该返回什么呢?如果返回一个当前树是否是平衡二叉树的boolean类型的值,那么我只知道left和right这两棵树是否是平衡二叉树,无法得出left和right的高度差是否不大于1,自然也就无法得出root这棵树是否是平衡二叉树了。而如果我返回的是一个平衡二叉树的高度的int类型的值,那么我就只知道两棵树的高度,但无法知道这两棵树是不是平衡二叉树,自然也就没法判断root这棵树是不是平衡二叉树了。
因此,这里我们返回的信息应该是既包含子树的深度的int类型的值,又包含子树是否是平衡二叉树的boolean类型的值。可以单独定义一个ReturnNode类,如下:

class ReturnNode{ boolean isB; int depth; //构造方法 public ReturnNode(boolean isB, int depth){ this.isB = isB; this.depth = depth; } }
-
本级递归应该做什么。 知道了第二步的返回值后,这一步就很简单了。目前树有三个节点:root,left,right。我们首先判断left子树和right子树是否是平衡二叉树,如果不是则直接返回false。再判断两树高度差是否不大于1,如果大于1也直接返回false。否则说明以root为节点的子树是平衡二叉树,那么就返回true和它的高度。
具体的Java代码如下:
![]()
class Solution {
//这个ReturnNode是参考我描述的递归套路的第二步:思考返回值是什么
//一棵树是BST等价于它的左、右俩子树都是BST且俩子树高度差不超过1
//因此我认为返回值应该包含当前树是否是BST和当前树的高度这两个信息
private class ReturnNode{
boolean isB;
int depth;
public ReturnNode(int depth, boolean isB){
this.isB = isB;
this.depth = depth;
}
}
//主函数
public boolean isBalanced(TreeNode root) {
return isBST(root).isB;
}
//参考递归套路的第三部:描述单次执行过程是什么样的
//这里的单次执行过程具体如下:
//是否终止?->没终止的话,判断是否满足不平衡的三个条件->返回值
public ReturnNode isBST(TreeNode root){
if(root == null){
return new ReturnNode(0, true);
}
//不平衡的情况有3种:左树不平衡、右树不平衡、左树和右树差的绝对值大于1
ReturnNode left = isBST(root.left);
ReturnNode right = isBST(root.right);
if(left.isB == false || right.isB == false){
return new ReturnNode(0, false);
}
if(Math.abs(left.depth - right.depth) > 1){
return new ReturnNode(0, false);
}
//不满足上面3种情况,说明平衡了,树的深度为左右俩子树最大深度+1
return new ReturnNode(Math.max(left.depth, right.depth) + 1, true);
}
}
![]()
一些可以用这个套路解决的题
暂时就写这么多啦,作为一个高考语文及格分,大学又学了工科的人,表述能力实在差因此啰啰嗦嗦写了一大堆,希望大家能理解这个很好用的套路。
下面我再列举几道我在刷题过程中遇到的也是用这个套路秒的题,真的太多了,大部分链表和树的递归题都能这么秒,因为树和链表天生就是适合递归的结构。
我会随时补充,正好大家可以看了上面三个题后可以拿这些题来练练手,看看自己是否能独立快速准确的写出递归解法了。
Leetcode 101. 对称二叉树
Leetcode 111. 二叉树的最小深度
Leetcode 226. 翻转二叉树:这个题的备注是最骚的。Mac OS下载神器homebrew的大佬作者去面试谷歌,没做出来这道算法题,然后被谷歌面试官怼了:”我们90%的工程师使用您编写的软件(Homebrew),但是您却无法在面试时在白板上写出翻转二叉树这道题,这太糟糕了。”
Leetcode 617. 合并二叉树
Leetcode 654. 最大二叉树
Leetcode 83. 删除排序链表中的重复元素
Leetcode 206. 翻转链表
第二部分 我对递归的理解与解题思路
如果还没有理解这种套路,那我就再通过几道题目来解决它!
在上面的基础上,我将这种套路再重新整理一下:
- 确定终止条件(其实就是考虑最初的情况和特殊情况)
- 当前要做的事情(这个就根据题目来决定了)
- 返回结果(当前的事情做完后返回的结果)
例题1.Leetcode24 Swap Nodes in Pairs
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例:
1->2->3->4
2->1->4->3
ListNode* swapPairs(ListNode* head)
解题1:
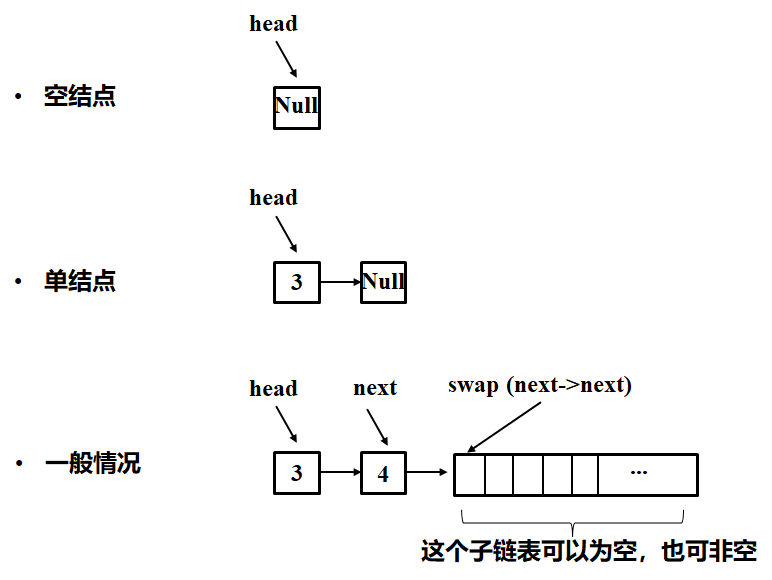
- 确定终止条件。最初情况是空结点,则直接返回本身。若最初情况是只有头节点,则也直接返回本身。若最初情况有两个,此时就需要走第二步了。注意,递归法仅考虑到特殊情况就好了,不需要再往下考虑了!
- 当前要做的事情。如何要确定当前要做的事呢?当前假设是只有两个节点,其后是空结点或是已经排序好的节点。那么我们所做的无非就是将这两个节点进行交换。(或者这么理解,两个结点以外的事情我们当作子问题来解决:子问题就是调用自身swap()函数后的结果呀!)
- (子问题的)返回结果。当前的事情做完后肯定要有个返回。具体看代码和图解吧
-

class Solution { public: ListNode* swapPairs(ListNode* head) { if ((head==NULL) || (head->next==NULL)) # 终止条件(特殊情况):空结点和单节点 return head; ListNode*next = head->next; # 一般情况 head->next = swapPairs(next->next); # 子问题是swapPairs(next->next). 这时变成了2个节点和一个子问题的反转问题。 next->next = head; return next; }
图解如下,和代码一起看:(下图一般情况,不就变成了三个节点的翻转嘛,很简单)
例题2.Leetcode206 Reverse Linked List
反转一个单链表。
示例:
输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
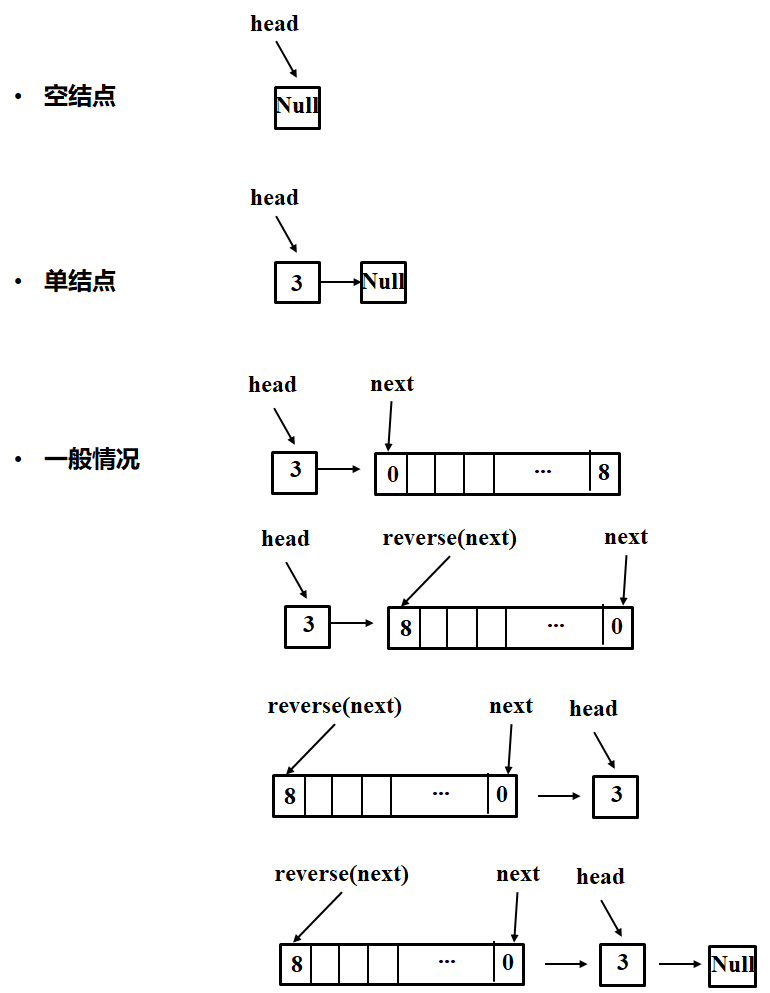
解题2.
- 确定终止条件。空结点或者单节点直接返回就行
- 当前要做的事情(结合子问题考虑)。等于大于两个节点的翻转问题可以转为单节点和其余节点的子问题。具体来说,子问题就是调用函数本身返回的结果。
- 返回结果。结合代码来看。
-

class Solution { public: ListNode* reverseList(ListNode* head) { if ((head==NULL) || (head->next==NULL)) return head; ListNode* next = head->next; ListNode*newhead = reverseList(next); # 子问题是reverse下一个节点 next->next = head; head->next=NULL; return newhead; } };
上图:
例题3 . *38. Count and Say (之前的博文)
例题4. 46. Permutations
给定一个没有重复数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3] 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
对于这种排列问题,肯定也可以递归。
具体而言,空列表返回空,单元素返回只含该元素的列表(终止条件)。大于等于两个元素的需要额外考虑(当前要做的事情)。下面部分文字摘自:博客
如果只有 1 个数字 [ 1 ],那么很简单,直接返回 [ [ 1 ] ] 就 OK 了。
如果加了 1 个数字 2, [ 1 2 ] 该怎么办呢?我们只需要在上边的情况里,在 1 的空隙,也就是左边右边插入 2 就够了。变成 [ [ 2 1 ], [ 1 2 ] ]。
如果再加 1 个数字 3,[ 1 2 3 ] 该怎么办呢?同样的,我们只需要将 3 挨个插到上面的位置就行啦。例如对于 [ 2 1 ]而言,将3插到 左边,中间,右边 ,变成 3 2 1,2 3 1,2 1 3。同理,对于1 2 在左边,中间,右边插入 3,变成 3 1 2,1 3 2,1 2 3,所以最后的结果就是 [ [ 3 2 1],[ 2 3 1],[ 2 1 3 ], [ 3 1 2 ],[ 1 3 2 ],[ 1 2 3 ] ]。
所以规律很简单,直接看代码解释就ok。
![]()
class Solution:
def permute(self, nums): # 假设输入nums=[1,2,3],那上一级返回的结果应该是[[1,2],[2,1]]
if len(nums) == 0: return []
if len(nums) == 1: return [nums] # 终止条件
results = []
end = len(nums)-1
before = self.permute(nums[0:end]) # 上一级返回的结果[[1,2],[2,1]],下面要做的是将nums[end]=3这个元素挨个插到其中
len_before = len(before) # 上一级的结果
for i in range(len_before): # 在上一级每个列表的基础上
for j in range(len(nums)): # 在该列表的每个位置
temp = before[i].copy() # 提取上一级返回的结果中的每个子列表
temp.insert(j, nums[end]) # 插入到每个空隙里
results.append(temp) # 放到最终结果里
return results
![]()
对于 47. Permutations II , 一模一样,除了加一条语句判断是否重复即可。代码:
![]()
View Code
例题5. 39. Combination Sum (较难理解)
组合总和:给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括
target)都是正整数。 - 解集不能包含重复的组合。
示例 1:
[2,3,6,7],
7
示例 2:
输入: candidates = [2,3,5], target = 8,
所求解集为:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
此题一个不太好理解的地方:递归子函数是放在了一个循环里。前面的题目没有对递归子函数做循环处理。下面详细分析该题的解法:
变量定义:注意数组里的每个元素允许重复使用,先定义一个放临时解的列表temp=[] 和起点start=0。再定义一个存放最终结果的列表的列表results。
对于candidates=[2,3,6,7],target=8的任务,可以看成是总任务是:combinationDFS(candidates,target=8,start=0,temp,results), 则子任务是分别从不同位置开始,将满足target的列表存到results中。对于该总任务,当前要做的事(子任务)如下:
combinationDFS(candidates,6,start=0,temp,results); temp已经存放了start位置的元素2,candidates=[2,3,6,7],target=8-2=6的子任务。子任务完毕,弹出temp顶端的元素。
combinationDFS(candidates,5,start=1,temp,results); temp已经存放了start位置的元素3,candidates=[3,6,7],target=8-3=5的子任务。子任务完毕,弹出temp顶端的元素。
combinationDFS(candidates,2,start=2,temp,results); temp已经存放了start位置的元素6,candidates=[6,7],target=8-6=2的子任务。子任务完毕,弹出temp顶端的元素。
combinationDFS(candidates,1,start=3,temp,results); temp已经存放了start位置的元素7,candidates=[7],target=8-7=1的子任务。子任务完毕,弹出temp顶端的元素。
所以代码如下:
![]()
1 class Solution {
2 public:
3 vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
4 vector<vector<int>> results; # 存放最后结果
5 vector<int> temp;
6 combinationDFS(candidates,target,0,temp,results); # 主任务函数
7 return results;
8 }
9 void combinationDFS(vector<int>&candidates, int target, int pos,vector<int> &temp, vector<vector<int>> &results){
10 if (target<0){ # 题目中数组全为正数,不可能有目标<0,所以如果目标小于0,就返回空。
11 return;
12 }
13 if (target==0){ # 目标为0,两种情况:主任务要求target=0,不存在结果,将temp直接返回;子任务要求target=0,说明找到了一组解
14 results.push_back(temp);
15 return;} # 以上为终止条件,下面为当前要做的事。
16 for (int i=pos;i<candidates.size();i++){ # 对于主任务,要先将当前的元素放到临时解里,再执行后面的子任务
17 temp.push_back(candidates[i]); # 将当前位置的元素放到临时解temp里
18 combinationDFS(candidates,target-candidates[i],i,temp,results); # 执行子任务
19 temp.pop_back(); # 这句话最不好理解。可以这么想,上面那句话找到了一个解后,就将临时解的顶部元素弹出,考虑下一可能解
20 }
21
22 }
23 };
![]()
关于子任务循坏,还是要看当前总任务的需求。前面的题目中,当前总任务只与上一次子任务相关。而这道题当前总任务与一堆子任务相关,所以需要循环。
这道题下一题是很类似,只不过要求变了。数组中有重复的元素,并且每个数只允许用一次:
40. Combination Sum II
![]()
1 class Solution {
2 public:
3 vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
4 vector<vector<int>> results;
5 vector<int> temp;
6 sort(candidates.begin(), candidates.end());
7 combinationDFS(candidates,target,0,temp,results);
8 return results;
9 }
10 void combinationDFS(vector<int>&candidates, int target, int pos,vector<int> &temp, vector<vector<int>> &results){
11 if (target<0){
12 return;
13 }
14 if (target==0){
15 results.push_back(temp);
16 return;}
17 for (int i=pos;i<candidates.size();i++){
18 if(i>pos && candidates[i]==candidates[i-1]) # 结果去重
19 continue;
20
21 temp.push_back(candidates[i]);
22 combinationDFS(candidates,target-candidates[i],i+1,temp,results); # i+1,即从当前的下一个元素起
23 temp.pop_back();
24 }
25
26 }
27 };
![]()
22. 括号生成
给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合。
例如,给出 n = 3,生成结果为:
[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
思路参考于此:该问题解的个数就是卡特兰数。非常易于理解。具体实现如下:
针对一个长度为2n的合法排列,第1到2n个位置都满足这个规则:左括号的个数大于等于右括号的个数。所以,我们就可以按照这个规则去打印括号:假设在位置k我们还剩余left个左括号和right个右括号:
- 如果left>0,则我们可以直接打印左括号,而不违背规则。
- 如果left>=right,则我们不能打印右括号,因为打印会违背合法排列的规则,否则可以打印右括号。
- 如果left和right均为零,则说明我们已经完成一个合法排列,可以将其打印出来
![]()
class Solution:
def generateParenthesis(self, n: int):
def helper(leftnum, rightnum, s, res):
if leftnum==0 and rightnum==0:
res.append(s)
if leftnum>0:
helper(leftnum-1, rightnum, s+'(', res)
if rightnum>0 and leftnum<rightnum:
helper(leftnum, rightnum-1, s+')', res)
return res
temp,res = '',[]
res = helper(n,n,temp,res) # 初始时,待n个左括号和n个右括号来组合。在组合过程中,这个数目逐渐减小,都减为0时,即构成一个结果
return res
![]()
395. 至少有K个重复字符的最长子串
分治+递归。
核心思想:如果某个字符 x 在整个字符串中出现的次数 <k,那么 x 不可能出现在最终要求的子串中。因此,可以将原字符串截断为:
x 左侧字符子串 + x + x 右侧字符子串
![]()
class Solution:
def longestSubstring(self, s: str, k: int) -> int:
if len(s)<k:
return 0
c = min(set(s), key=lambda x:s.count(x))
if s.count(c)>=k:
return len(s)
return max(self.longestSubstring(t,k) for t in s.split(c))
![]()
或者再优化一下:
![]()
View Code
其他递归例子:
397. 整数替换

![八路参考文献:[八一新书]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022.](https://img-blog.csdnimg.cn/6d7d4ae959e24fd2bbee95c897fc7549.jpeg#pic_center)