目录
一、概述
1.作用
2.为什么使用?
二、组件
1.elasticsearch
1.1 作用
1.2 特点
2.logstash
2.1 作用
2.2 工作过程
2.3 INPUT
2.4 FILETER
2.5 OUTPUTS
3.kibana
三、架构类型
1.ELK
2.ELKK
3.ELFK
4.ELFKK
四、案例 - 构建ELK集群
1.环境配置
2.安装node1与node2节点的elasticsearch
2.1 安装
2.2 配置
2.3 启动elasticsearch服务
2.4 查看节点信息
3.在node1安装elasticsearch-head插件
3.1 安装node
3.2 拷贝命令
3.3 安装elasticsearch-head
3.4 修改elasticsearch配置文件
3.5 启动elasticsearch-head
3.6 访问
3.7 在node1的终端中输入:
4.node1服务器安装logstash
5.ogstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
编辑
6.node1节点安装kibana
7.企业案例
一、概述
ELK由三个组件构成
1.作用
- 日志收集
- 日志分析
- 日志可视化
2.为什么使用?
- 日志对于分析系统、应用的状态十分重要,但一般日志的量会比较大,并且比较分散。
- 如果管理的服务器或者程序比较少的情况我们还可以逐一登录到各个服务器去查看、分析。但如果服务器或者程序的数量比较多了之后这种方法就显得力不从心。基于此,一些集中式的日志系统也就应用而生。目前比较有名成熟的有,Splunk(商业)、FaceBook 的Scribe、Apache的Chukwa Cloudera的Fluentd、还有ELK等等。
二、组件
1.elasticsearch
1.1 作用
- 日志分析
- 开源的日志收集、分析、存储程序
1.2 特点
- 分布式
- 零配置
- 自动发现
- 索引自动分片
- 索引副本机制
- Restful风格接口
- 多数据源
- 自动搜索负载
2.logstash
2.1 作用
- 日志收集
- 搜集、分析、过滤日志的工具
2.2 工作过程
- 一般工作方式为c/s架构,Client端安装在需要收集日志的服务器上,Server端负责将收到的各节点日志进行过滤、修改等操作,再一并发往Elasticsearch上去
- Inputs → Filters → Outputs
- 输入-->过滤-->输出
2.3 INPUT
- File:从文件系统的文件中读取,类似于tail -f命令
- Syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
- Redis:从redis service中读取
- Beats:从filebeat中读取
2.4 FILETER
- Grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
- 官方提供的grok表达式:logstash-patterns-core/patterns at main · logstash-plugins/logstash-patterns-core · GitHub
- Grok在线调试:Grok Debugger
- Mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
- Drop:丢弃一部分Events不进行处理。
- Clone:拷贝Event,这个过程中也可以添加或移除字段。
- Geoip:添加地理信息(为前台kibana图形化展示使用)
2.5 OUTPUTS
- Elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
- File:将Event数据保存到文件中。
- Graphite:将Event数据发送到图形化组件中,踏实一个当前较流行的开源存储图形化展示的组件。
3.kibana
- 日志可视化
- 为Logstash和ElasticSearch在收集、存储的日志基础上进行分析时友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
三、架构类型
1.ELK
es
logstash
kibana
2.ELKK
es
logstash
kafka
kibana
3.ELFK
es
logstash 重量级、占用系统资源较多
filebeat 轻量级、占用系统资源较少
kibana
4.ELFKK
es
logstash
filebeat
kafka
kibana
四、案例 - 构建ELK集群
1.环境配置
设置各个主机的IP地址为拓扑中的静态IP,在两个节点中修改主机名为node1和node2并设置hosts文件
node1:
hostnamectl set-hostname node1
bash
vim /etc/hosts
192.168.42.3 node1
192.168.42.4 node2

node2:
hostnamectl set-hostname node2
bash
vim /etc/hosts
192.168.42.3 node1
192.168.42.4 node2

2.安装node1与node2节点的elasticsearch
2.1 安装
mv elk-apppack elk
cd elk
rpm -ivh elasticsearch-5.5.0.rpm
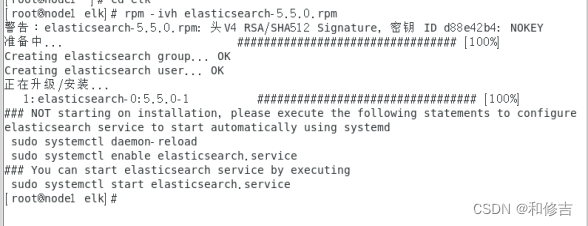
2.2 配置
node1:
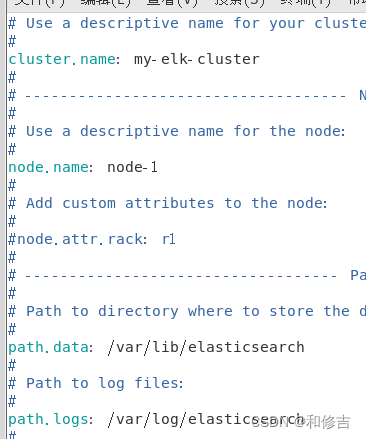
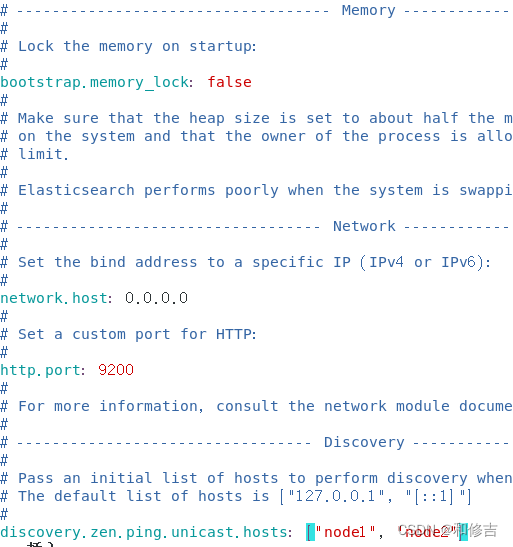
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node1 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
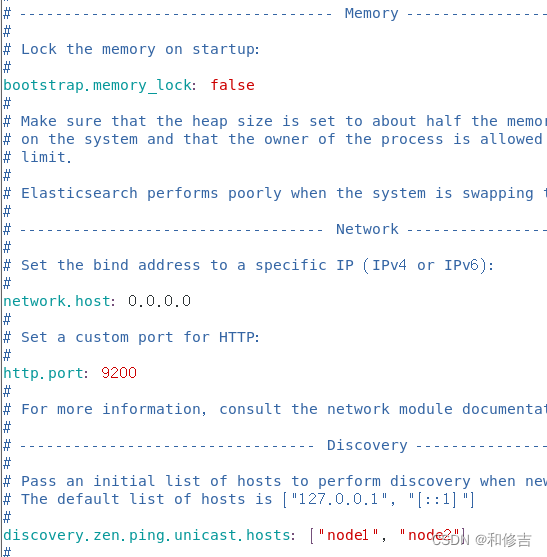
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
node2:
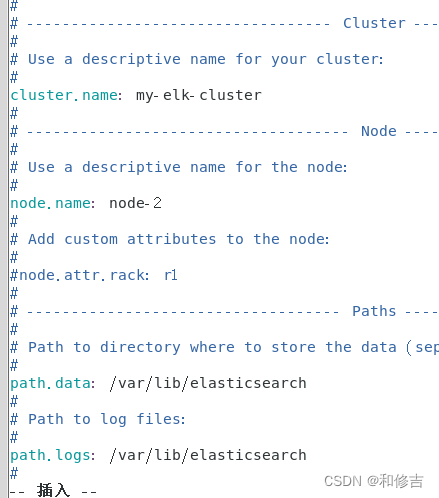
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node2 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
2.3 启动elasticsearch服务
node1和node2
systemctl start elasticsearch
![]()
![]()
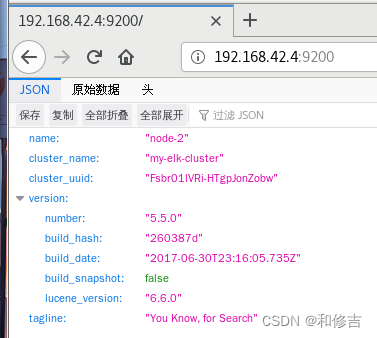
2.4 查看节点信息
http://192.168.42.3:9200
http://192.168.42.4:9200

3.在node1安装elasticsearch-head插件
3.1 安装node
cd elk
ls
tar xf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make && make install
3.2 拷贝命令
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin

3.3 安装elasticsearch-head
cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head

npm install
3.4 修改elasticsearch配置文件
vim /etc/elasticsearch/elasticsearch.yml
# Require explicit names when deleting indices:
#
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin:"*" //跨域访问允许的域名地址

重启服务: systemctl restart elasticsearch
![]()
3.5 启动elasticsearch-head
cd /root/elk/elasticsearch-head
npm run start &
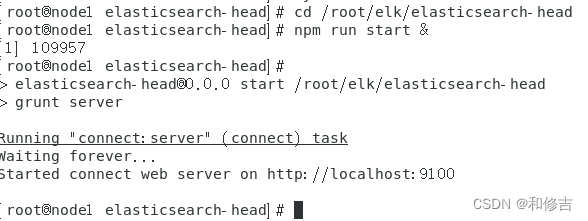
查看监听: netstat -anput | grep :9100

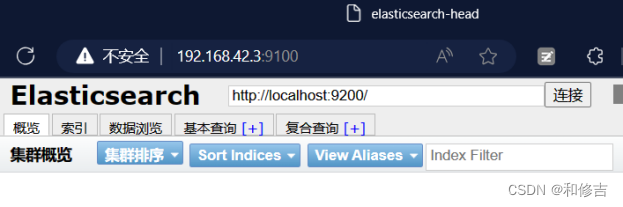
3.6 访问
http://192.168.42.3:9100
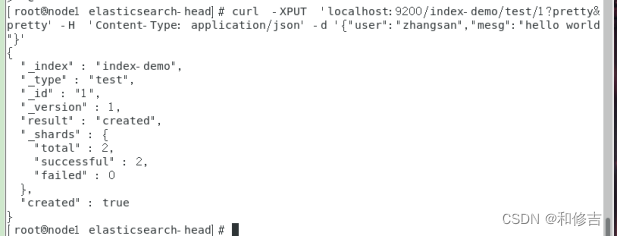
3.7 在node1的终端中输入:
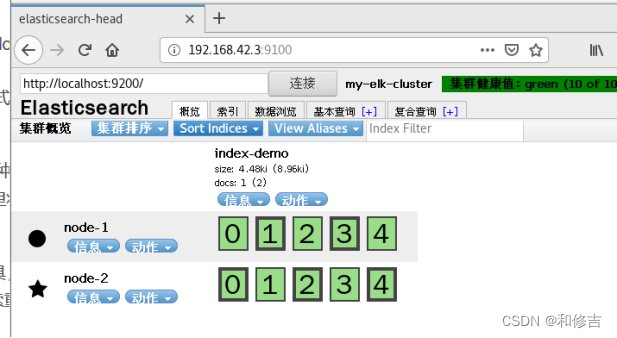
curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
刷新浏览器可以看到对应信息即可
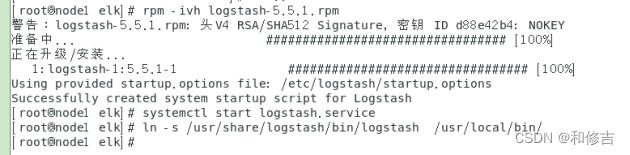
4.node1服务器安装logstash
cd elk
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
In -s /usr/share/logstash/bin/logstash /usr/local/bin/
测试1: 标准输入与输出
logstash -e 'input{ stdin{} }output { stdout{} }'

测试2: 使用rubydebug解码
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'

测试3:输出到elasticsearch
logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>["192.168.42.3:9200"]} }'
查看结果:
http://192.168.42.3:9100

5.ogstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
通过logstash收集系统信息日志
chmod o+r /var/log/messages
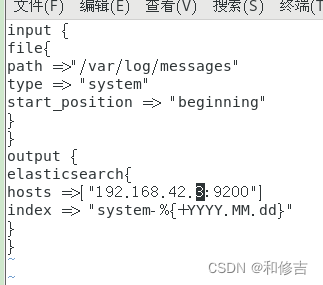
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.42.1:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
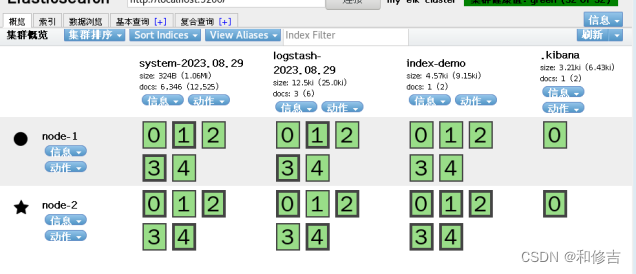
重启日志服务: systemctl restart logstash
查看日志: http://192.168.42.3:9100
6.node1节点安装kibana
cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm

配置kibana
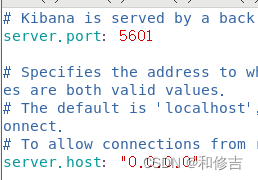
vim /etc/kibana/kibana.yml
server.port:5601 //Kibana打开的端口
server.host:"0.0.0.0" //Kibana侦听的地址
elasticsearch.url: "http://192.168.42.3:9200"
//和Elasticsearch 建立连接
kibana.index:".kibana" //在Elasticsearch中添加.kibana索引

启动kibana
systemctl start kibana
访问kibana :
http://192.168.42.3:5601
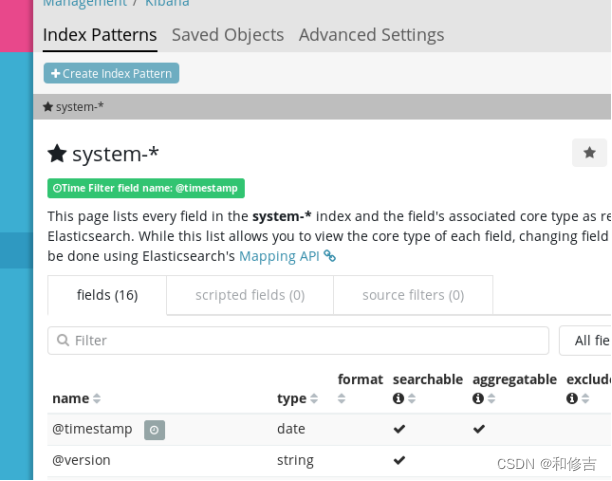
首次访问需要添加索引,我们添加前面已经添加过的索引:system-*
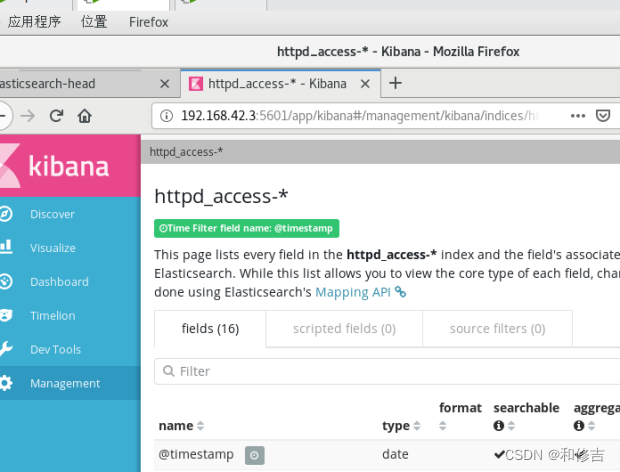
7.企业案例
收集httpd访问日志信息
在httpd服务器上安装logstash,参数上述安装过程,可以不进行测试
logstash在httpd服务器上作为agent(代理),不需要启动
编写httpd日志收集配置文件
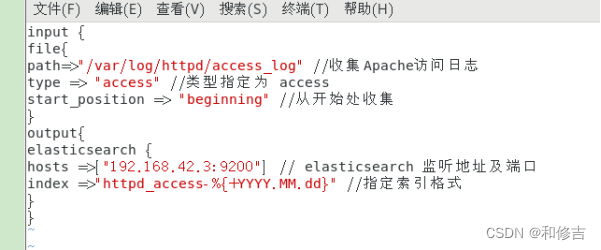
vim /etc/logstash/conf.d/httpd.conf
input {
file{
path=>"/var/log/httpd/access_log" //收集Apache访问日志
type => "access" //类型指定为 access
start_position => "beginning" //从开始处收集
}
output{
elasticsearch {
hosts =>["192.168.42.3:9200"] // elasticsearch 监听地址及端口
index =>"httpd_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
使用logstash命令导入配置:
logstash -f /etc/logstash/conf.d/httpd.conf
使用kibana查看即可! http://192.168.42.3:5601 查看时在mangement选项卡创建索引httpd_access-* 即可!