对动作捕捉的几篇论文感兴趣,想复现一下,需要caffe环境就折腾了下!转模型需要python 2.7环境,我顺便也弄了!!!
1. 环境
Windows10
RTX2080TI 11G
Anaconda Python2.7
visual studio 2013
cuda 11.1
cudnn 8.2.0
cmake 3.26.1
git
2. 具体步骤
2.1 安装cuda和cudnn
略 这部分看其他博客
cuda_11.1.0_456.43_win10.exe
cudnn-11.3-windows-x64-v8.2.0.53.zip
2.2 安装caffe
1.下载源码
git clone https://github.com/BVLC/caffe.git
cd caffe
git checkout windows
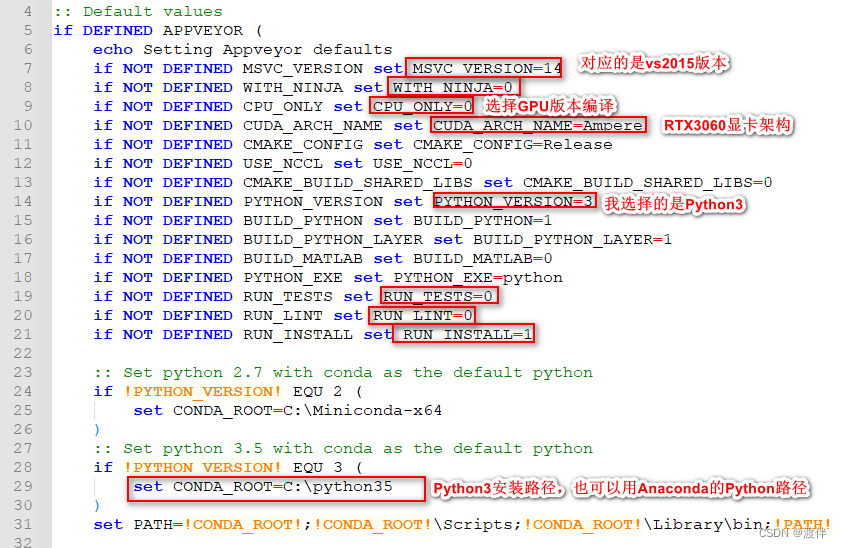
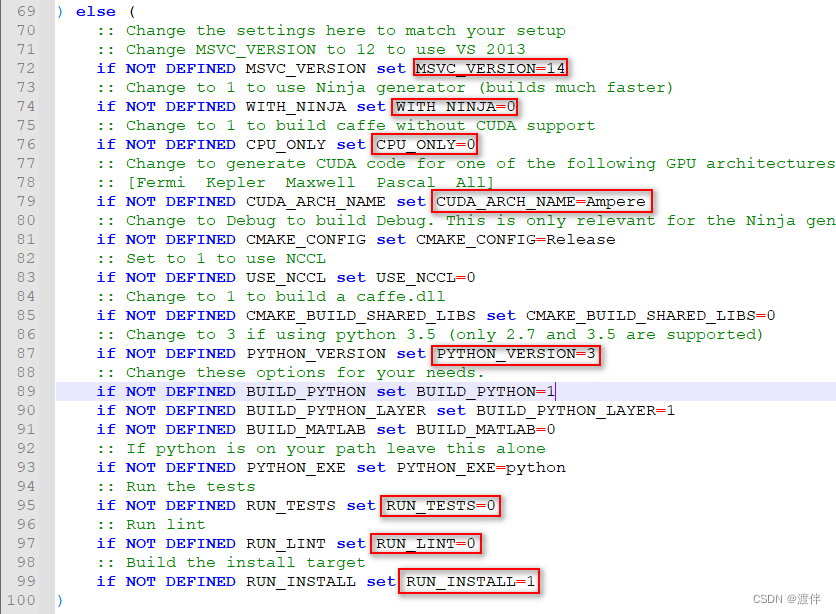
2.修改build_win.cmd 这一步决定着后面能不能编译成功
path/caffe/scripts/build_win.cmd
a.需要确定visual studio的版本
MSVC版本号对应关系 我在这边踩了坑,因为我看的那个博客这边弄错了。这个链接没问题。MSVC_VERSION = 12表示VS2013,MSVC_VERSION = 14表示VS2015
b.确定GPU的显卡架构 架构表 一定要看

下面开始修改文件:
1.修改caffe源码中./scripts/build_win.cmd
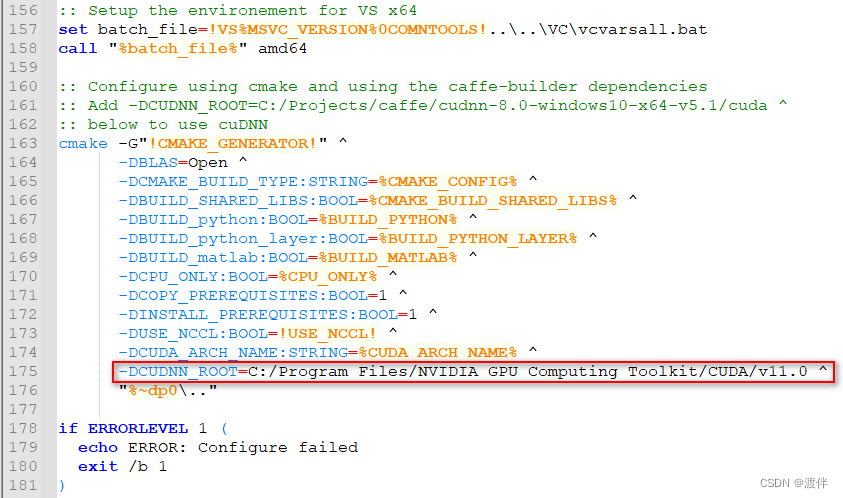
修改caffe源码中./cmake/Cuda.cmake:


我的显卡是2080ti,对应着75,我只要保证有75就行!

这里的80需要根据我的显卡情况改成75


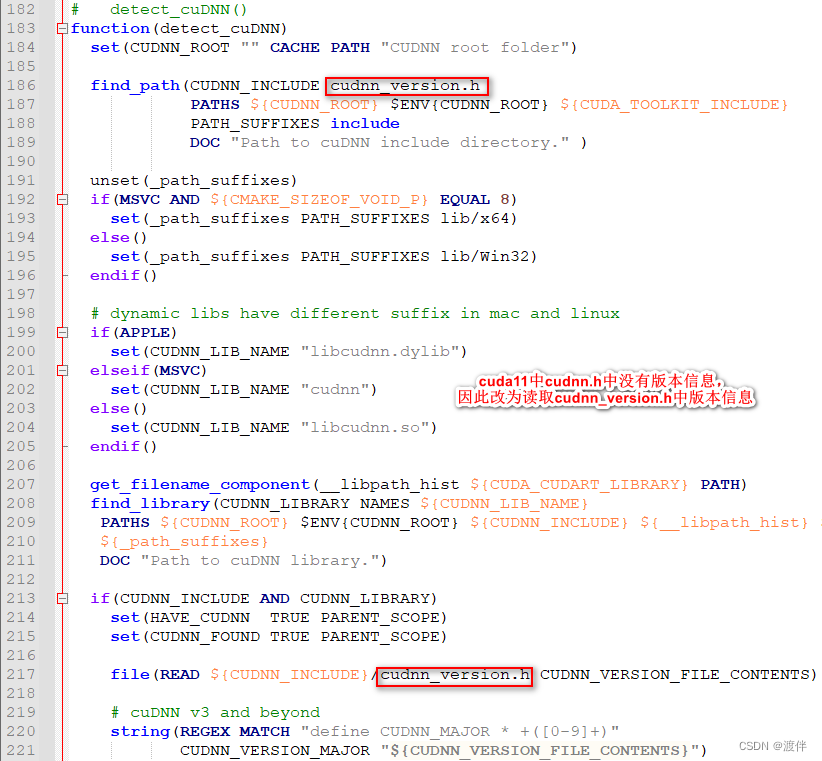
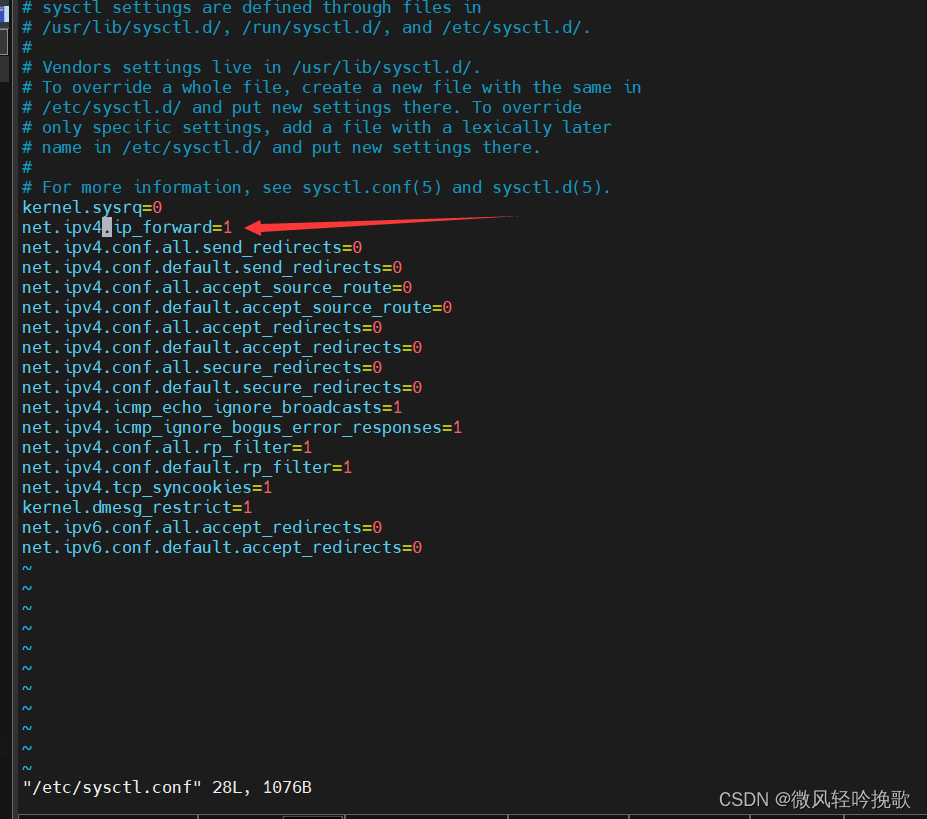
这里面是一定要改的,不然找不到cudnn!因为caffe之类的代码很久不更新了,只支持到了使用cudnn7.x,在使用了cudnn8的环境下编译caffe时,会在src/caffe/layers/cudnn_conv_layer.cpp等文件里出错!
报错信息是这样的:
error: identifier "CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT" is undefined
error: identifier "cudnnGetConvolutionForwardAlgorithm" is undefined
这是因为cudnn8里没有cudnnGetConvolutionForwardAlgorithm()这个函数了,改成了cudnnGetConvolutionForwardAlgorithm_v7(),也没了CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT这个宏定义,这些都是API不兼容,但是NVIDIA声明cudnn8不支持了,caffe的代码也没人去更新了,所以不能指望NVIDIA或者berkeley,只能自行修改。将cudnn_conv_layer.cpp文件替换成如下:
#ifdef USE_CUDNN
#include <algorithm>
#include <vector>
#include "caffe/layers/cudnn_conv_layer.hpp"
namespace caffe {
// Set to three for the benefit of the backward pass, which
// can use separate streams for calculating the gradient w.r.t.
// bias, filter weights, and bottom data for each group independently
#define CUDNN_STREAMS_PER_GROUP 3
/**
* TODO(dox) explain cuDNN interface
*/
template <typename Dtype>
void CuDNNConvolutionLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
ConvolutionLayer<Dtype>::LayerSetUp(bottom, top);
// Initialize CUDA streams and cuDNN.
stream_ = new cudaStream_t[this->group_ * CUDNN_STREAMS_PER_GROUP];
handle_ = new cudnnHandle_t[this->group_ * CUDNN_STREAMS_PER_GROUP];
// Initialize algorithm arrays
fwd_algo_ = new cudnnConvolutionFwdAlgo_t[bottom.size()];
bwd_filter_algo_= new cudnnConvolutionBwdFilterAlgo_t[bottom.size()];
bwd_data_algo_ = new cudnnConvolutionBwdDataAlgo_t[bottom.size()];
// initialize size arrays
workspace_fwd_sizes_ = new size_t[bottom.size()];
workspace_bwd_filter_sizes_ = new size_t[bottom.size()];
workspace_bwd_data_sizes_ = new size_t[bottom.size()];
// workspace data
workspaceSizeInBytes = 0;
workspaceData = NULL;
workspace = new void*[this->group_ * CUDNN_STREAMS_PER_GROUP];
for (size_t i = 0; i < bottom.size(); ++i) {
// initialize all to default algorithms
fwd_algo_[i] = (cudnnConvolutionFwdAlgo_t)0;
bwd_filter_algo_[i] = (cudnnConvolutionBwdFilterAlgo_t)0;
bwd_data_algo_[i] = (cudnnConvolutionBwdDataAlgo_t)0;
// default algorithms don't require workspace
workspace_fwd_sizes_[i] = 0;
workspace_bwd_data_sizes_[i] = 0;
workspace_bwd_filter_sizes_[i] = 0;
}
for (int g = 0; g < this->group_ * CUDNN_STREAMS_PER_GROUP; g++) {
CUDA_CHECK(cudaStreamCreate(&stream_[g]));
CUDNN_CHECK(cudnnCreate(&handle_[g]));
CUDNN_CHECK(cudnnSetStream(handle_[g], stream_[g]));
workspace[g] = NULL;
}
// Set the indexing parameters.
bias_offset_ = (this->num_output_ / this->group_);
// Create filter descriptor.
const int* kernel_shape_data = this->kernel_shape_.cpu_data();
const int kernel_h = kernel_shape_data[0];
const int kernel_w = kernel_shape_data[1];
cudnn::createFilterDesc<Dtype>(&filter_desc_,
this->num_output_ / this->group_, this->channels_ / this->group_,
kernel_h, kernel_w);
// Create tensor descriptor(s) for data and corresponding convolution(s).
for (int i = 0; i < bottom.size(); i++) {
cudnnTensorDescriptor_t bottom_desc;
cudnn::createTensor4dDesc<Dtype>(&bottom_desc);
bottom_descs_.push_back(bottom_desc);
cudnnTensorDescriptor_t top_desc;
cudnn::createTensor4dDesc<Dtype>(&top_desc);
top_descs_.push_back(top_desc);
cudnnConvolutionDescriptor_t conv_desc;
cudnn::createConvolutionDesc<Dtype>(&conv_desc);
conv_descs_.push_back(conv_desc);
}
// Tensor descriptor for bias.
if (this->bias_term_) {
cudnn::createTensor4dDesc<Dtype>(&bias_desc_);
}
handles_setup_ = true;
}
template <typename Dtype>
void CuDNNConvolutionLayer<Dtype>::Reshape(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
ConvolutionLayer<Dtype>::Reshape(bottom, top);
CHECK_EQ(2, this->num_spatial_axes_)
<< "CuDNNConvolution input must have 2 spatial axes "
<< "(e.g., height and width). "
<< "Use 'engine: CAFFE' for general ND convolution.";
bottom_offset_ = this->bottom_dim_ / this->group_;
top_offset_ = this->top_dim_ / this->group_;
const int height = bottom[0]->shape(this->channel_axis_ + 1);
const int width = bottom[0]->shape(this->channel_axis_ + 2);
const int height_out = top[0]->shape(this->channel_axis_ + 1);
const int width_out = top[0]->shape(this->channel_axis_ + 2);
const int* pad_data = this->pad_.cpu_data();
const int pad_h = pad_data[0];
const int pad_w = pad_data[1];
const int* stride_data = this->stride_.cpu_data();
const int stride_h = stride_data[0];
const int stride_w = stride_data[1];
#if CUDNN_VERSION_MIN(8, 0, 0)
int RetCnt;
bool found_conv_algorithm;
size_t free_memory, total_memory;
cudnnConvolutionFwdAlgoPerf_t fwd_algo_pref_[4];
cudnnConvolutionBwdDataAlgoPerf_t bwd_data_algo_pref_[4];
//get memory sizes
cudaMemGetInfo(&free_memory, &total_memory);
#else
// Specify workspace limit for kernels directly until we have a
// planning strategy and a rewrite of Caffe's GPU memory mangagement
size_t workspace_limit_bytes = 8*1024*1024;
#endif
for (int i = 0; i < bottom.size(); i++) {
cudnn::setTensor4dDesc<Dtype>(&bottom_descs_[i],
this->num_,
this->channels_ / this->group_, height, width,
this->channels_ * height * width,
height * width, width, 1);
cudnn::setTensor4dDesc<Dtype>(&top_descs_[i],
this->num_,
this->num_output_ / this->group_, height_out, width_out,
this->num_output_ * this->out_spatial_dim_,
this->out_spatial_dim_, width_out, 1);
cudnn::setConvolutionDesc<Dtype>(&conv_descs_[i], bottom_descs_[i],
filter_desc_, pad_h, pad_w,
stride_h, stride_w);
#if CUDNN_VERSION_MIN(8, 0, 0)
// choose forward algorithm for filter
// in forward filter the CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED is not implemented in cuDNN 8
CUDNN_CHECK(cudnnGetConvolutionForwardAlgorithm_v7(handle_[0],
bottom_descs_[i],
filter_desc_,
conv_descs_[i],
top_descs_[i],
4,
&RetCnt,
fwd_algo_pref_));
found_conv_algorithm = false;
for(int n=0;n<RetCnt;n++){
if (fwd_algo_pref_[n].status == CUDNN_STATUS_SUCCESS &&
fwd_algo_pref_[n].algo != CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED &&
fwd_algo_pref_[n].memory < free_memory){
found_conv_algorithm = true;
fwd_algo_[i] = fwd_algo_pref_[n].algo;
workspace_fwd_sizes_[i] = fwd_algo_pref_[n].memory;
break;
}
}
if(!found_conv_algorithm) LOG(ERROR) << "cuDNN did not return a suitable algorithm for convolution.";
else{
// choose backward algorithm for filter
// for better or worse, just a fixed constant due to the missing
// cudnnGetConvolutionBackwardFilterAlgorithm in cuDNN version 8.0
bwd_filter_algo_[i] = CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0;
//twice the amount of the forward search to be save
workspace_bwd_filter_sizes_[i] = 2*workspace_fwd_sizes_[i];
}
// choose backward algo for data
CUDNN_CHECK(cudnnGetConvolutionBackwardDataAlgorithm_v7(handle_[0],
filter_desc_,
top_descs_[i],
conv_descs_[i],
bottom_descs_[i],
4,
&RetCnt,
bwd_data_algo_pref_));
found_conv_algorithm = false;
for(int n=0;n<RetCnt;n++){
if (bwd_data_algo_pref_[n].status == CUDNN_STATUS_SUCCESS &&
bwd_data_algo_pref_[n].algo != CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD &&
bwd_data_algo_pref_[n].algo != CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD_NONFUSED &&
bwd_data_algo_pref_[n].memory < free_memory){
found_conv_algorithm = true;
bwd_data_algo_[i] = bwd_data_algo_pref_[n].algo;
workspace_bwd_data_sizes_[i] = bwd_data_algo_pref_[n].memory;
break;
}
}
if(!found_conv_algorithm) LOG(ERROR) << "cuDNN did not return a suitable algorithm for convolution.";
#else
// choose forward and backward algorithms + workspace(s)
CUDNN_CHECK(cudnnGetConvolutionForwardAlgorithm(handle_[0],
bottom_descs_[i],
filter_desc_,
conv_descs_[i],
top_descs_[i],
CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT,
workspace_limit_bytes,
&fwd_algo_[i]));
CUDNN_CHECK(cudnnGetConvolutionForwardWorkspaceSize(handle_[0],
bottom_descs_[i],
filter_desc_,
conv_descs_[i],
top_descs_[i],
fwd_algo_[i],
&(workspace_fwd_sizes_[i])));
// choose backward algorithm for filter
CUDNN_CHECK(cudnnGetConvolutionBackwardFilterAlgorithm(handle_[0],
bottom_descs_[i], top_descs_[i], conv_descs_[i], filter_desc_,
CUDNN_CONVOLUTION_BWD_FILTER_SPECIFY_WORKSPACE_LIMIT,
workspace_limit_bytes, &bwd_filter_algo_[i]) );
// get workspace for backwards filter algorithm
CUDNN_CHECK(cudnnGetConvolutionBackwardFilterWorkspaceSize(handle_[0],
bottom_descs_[i], top_descs_[i], conv_descs_[i], filter_desc_,
bwd_filter_algo_[i], &workspace_bwd_filter_sizes_[i]));
// choose backward algo for data
CUDNN_CHECK(cudnnGetConvolutionBackwardDataAlgorithm(handle_[0],
filter_desc_, top_descs_[i], conv_descs_[i], bottom_descs_[i],
CUDNN_CONVOLUTION_BWD_DATA_SPECIFY_WORKSPACE_LIMIT,
workspace_limit_bytes, &bwd_data_algo_[i]));
// get workspace size
CUDNN_CHECK(cudnnGetConvolutionBackwardDataWorkspaceSize(handle_[0],
filter_desc_, top_descs_[i], conv_descs_[i], bottom_descs_[i],
bwd_data_algo_[i], &workspace_bwd_data_sizes_[i]) );
#endif
}
// reduce over all workspace sizes to get a maximum to allocate / reallocate
size_t total_workspace_fwd = 0;
size_t total_workspace_bwd_data = 0;
size_t total_workspace_bwd_filter = 0;
for (size_t i = 0; i < bottom.size(); i++) {
total_workspace_fwd = std::max(total_workspace_fwd,
workspace_fwd_sizes_[i]);
total_workspace_bwd_data = std::max(total_workspace_bwd_data,
workspace_bwd_data_sizes_[i]);
total_workspace_bwd_filter = std::max(total_workspace_bwd_filter,
workspace_bwd_filter_sizes_[i]);
}
// get max over all operations
size_t max_workspace = std::max(total_workspace_fwd,
total_workspace_bwd_data);
max_workspace = std::max(max_workspace, total_workspace_bwd_filter);
// ensure all groups have enough workspace
size_t total_max_workspace = max_workspace *
(this->group_ * CUDNN_STREAMS_PER_GROUP);
// this is the total amount of storage needed over all groups + streams
if (total_max_workspace > workspaceSizeInBytes) {
DLOG(INFO) << "Reallocating workspace storage: " << total_max_workspace;
workspaceSizeInBytes = total_max_workspace;
// free the existing workspace and allocate a new (larger) one
cudaFree(this->workspaceData);
cudaError_t err = cudaMalloc(&(this->workspaceData), workspaceSizeInBytes);
if (err != cudaSuccess) {
// force zero memory path
for (int i = 0; i < bottom.size(); i++) {
workspace_fwd_sizes_[i] = 0;
workspace_bwd_filter_sizes_[i] = 0;
workspace_bwd_data_sizes_[i] = 0;
fwd_algo_[i] = CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMM;
bwd_filter_algo_[i] = CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0;
bwd_data_algo_[i] = CUDNN_CONVOLUTION_BWD_DATA_ALGO_0;
}
// NULL out all workspace pointers
for (int g = 0; g < (this->group_ * CUDNN_STREAMS_PER_GROUP); g++) {
workspace[g] = NULL;
}
// NULL out underlying data
workspaceData = NULL;
workspaceSizeInBytes = 0;
}
// if we succeed in the allocation, set pointer aliases for workspaces
for (int g = 0; g < (this->group_ * CUDNN_STREAMS_PER_GROUP); g++) {
workspace[g] = reinterpret_cast<char *>(workspaceData) + g*max_workspace;
}
}
// Tensor descriptor for bias.
if (this->bias_term_) {
cudnn::setTensor4dDesc<Dtype>(&bias_desc_,
1, this->num_output_ / this->group_, 1, 1);
}
}
template <typename Dtype>
CuDNNConvolutionLayer<Dtype>::~CuDNNConvolutionLayer() {
// Check that handles have been setup before destroying.
if (!handles_setup_) { return; }
for (int i = 0; i < bottom_descs_.size(); i++) {
cudnnDestroyTensorDescriptor(bottom_descs_[i]);
cudnnDestroyTensorDescriptor(top_descs_[i]);
cudnnDestroyConvolutionDescriptor(conv_descs_[i]);
}
if (this->bias_term_) {
cudnnDestroyTensorDescriptor(bias_desc_);
}
cudnnDestroyFilterDescriptor(filter_desc_);
for (int g = 0; g < this->group_ * CUDNN_STREAMS_PER_GROUP; g++) {
cudaStreamDestroy(stream_[g]);
cudnnDestroy(handle_[g]);
}
cudaFree(workspaceData);
delete [] stream_;
delete [] handle_;
delete [] fwd_algo_;
delete [] bwd_filter_algo_;
delete [] bwd_data_algo_;
delete [] workspace_fwd_sizes_;
delete [] workspace_bwd_data_sizes_;
delete [] workspace_bwd_filter_sizes_;
}
INSTANTIATE_CLASS(CuDNNConvolutionLayer);
} // namespace caffe
#endif
在命令行窗口运行 scripts/build_win.cmd,会下载libraries_v120_x64_py27_1.1.0.tar.bz2文件,最好挂个梯子,我这边下的很快。这个文件是caffe相关的依赖库,此过程中编译的时候会报一个boost相关的错误,对C:\Users\qiao\.caffe\dependencies\libraries_v120_x64_py27_1.1.0\libraries\include\boost-1_61\boost\config\compiler路径下的 nvcc.hpp 作如下修改,因为RTX2080ti的编译器nvcc版本大于7.5:

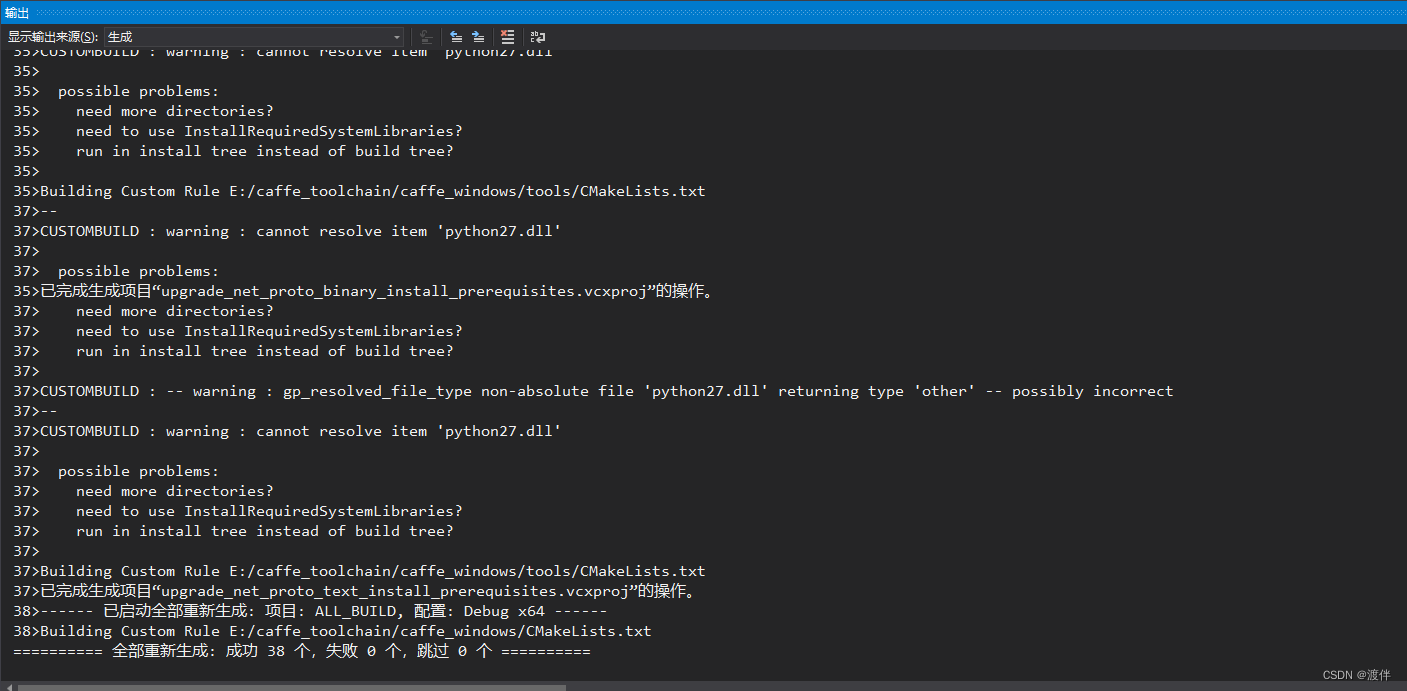
之后删除之前编译的build文件夹,重新编译一次,编译过程中会出现较多警告可以不用理会,稍等一段时间后,最终会出现:
最后在build文件夹下找到Caffe.sln文件,用VS2013打开,然后右键ALL_BUILD进行生成,等几分钟后编译完,
release版本

debug版本
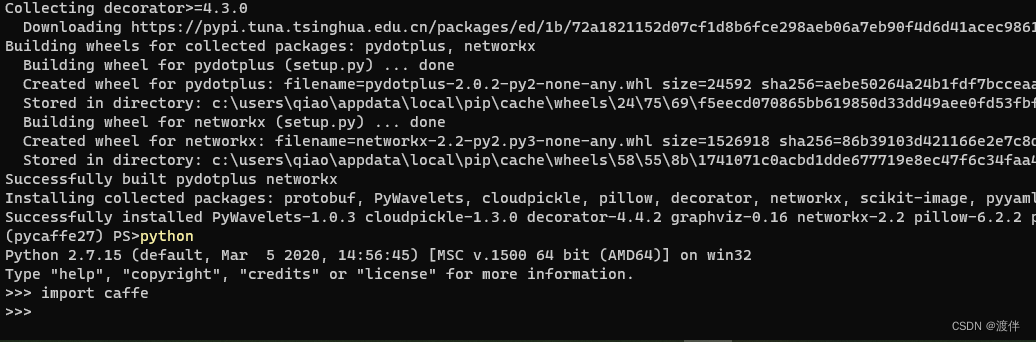
将caffe源码下中python中的caffe文件夹粘贴到上面配置的python路径中D:\Anaconda3\envs\pycaffe27\Lib\site-packages再将E:\caffe\build\install\bin路径添加到环境变量中,在终端中测试一下caffe命令是否正常,然后pip安装一些必要的库
pip install numpy scipy protobuf six scikit-image pyyaml pydotplus graphviz
最后打开python,测试一下
参考文献:
Windows10 下RTX30系列Caffe安装教程
Windows10下搭建caffe过程记录